向量数据库,是专门为向量检索设计的中间件!
高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库
一、向量数据库是什么有什么用?
向量数据库是一种专门用于高效存储和检索高维向量数据的系统。它通过嵌入模型将各类非结构化数据(包括文本、图像、音频等)转化为向量表示,并借助优化的索引结构和搜索算法实现快速查询。该数据库的核心功能在于执行相似性搜索:通过计算向量间的距离度量(如欧几里得距离或余弦相似度),精准定位与目标向量最相似的数据点。这种特性使其在处理非结构化数据方面表现出色,广泛应用于语义搜索、内容推荐等需要深度理解数据语义的场景。
| 功能类别 | 描述 |
|---|---|
| 向量存储 | 高效存储和管理高维向量数据 |
| 相似性度量 | 精准计算向量间的相似度(余弦相似度、欧氏距离和曼哈顿距离) |
| 相似性搜索 | 快速检索与目标向量最相似的条目 |
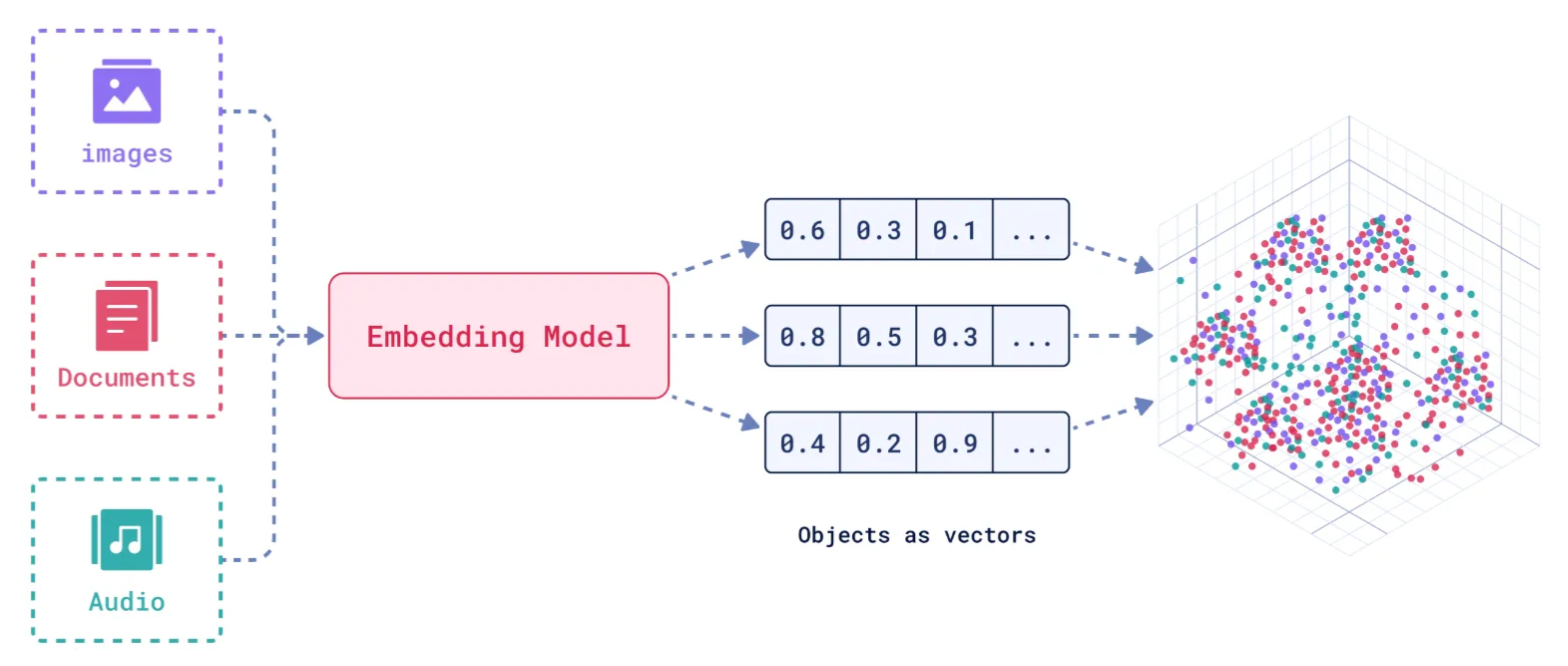
二、如何存储和检索嵌入向量
如何存储:向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
如何检索:通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。比如,FAISS和Milvus等数据库通过高效的索引结构加速检索。
三、向量数据库与传统数据库对比
| 传统数据库 | 向量数据库 | |
|---|---|---|
| 数据类型 | 存储结构化数据(如表格、行、列) | 存储高维向量数据,适合非结构化数据(如文本、图像、音频等) |
| 存储结构 | 基于关系模型或键值对等结构 | 基于向量空间模型,支持高维向量的高效存储 |
| 查询方式 | 使用 SQL 等语言进行精确匹配查询(如=、<、>) | 基于相似度或距离度量(如余弦相似度、欧氏距离)进行模糊匹配 |
| 索引机制 | B树、哈希索引等用于快速查找 | 使用 HNSW、IVF-PQ、Faiss 等专有索引加速近似最近邻搜索 |
| 性能特点 | 擅长处理小规模、结构化数据的精确查询 | 面对大规模、高维数据时仍能保持高效的相似性检索 |
| 应用场景 | 事务系统、报表、CRM、ERP 等结构化数据管理场景 | 语义搜索、图像识别、推荐系统、AI 相似性分析等需要向量化处理的场景 |
【注】向量数据库的核心价值在于高效检索,其本身并不生成向量,而是依赖于Embedding模型进行向量化处理。与传统数据库相比,向量数据库并非替代关系,而是形成互补。在实际应用场景中,二者往往根据具体需求协同使用,共同构建更完善的数据处理体系。
四、主流向量数据库功能对比
| 名称 | Web GUI | GPU 支持 | 远程支持 (HTTP/gRPC) | 云原生 | 开源 | 元数据(混合搜索) |
|---|---|---|---|---|---|---|
| FAISS | 不支持 | 支持 | 不支持 | 不支持 | 支持 | 不支持 |
| Milvus | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| Qdrant | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| Chroma | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
MilvusMilvus is an open-source vector database built for GenAI applications. Install with pip, perform high-speed searches, and scale to tens of billions of vectors.![]() https://milvus.io/ QdrantQdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
https://milvus.io/ QdrantQdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.![]() https://qdrant.tech/
https://qdrant.tech/