前言:本篇博客记录PromptStealer复现历程,主要分享环境配置过程中的一些经验。
论文信息:Prompt Stealing Attacks Against Text-to-Image Generation Models. USENIX, 2024.
开源代码:https://github.com/verazuo/prompt-stealing-attack
由于源码中指定了代码运行的环境为cuda toolkit 11.7, python 3.8, pytorch 1.12.0a0+8a1a93a,在多次尝试pytorch其他版本报错未果后,决定按照上述指定的环境配置来操作。
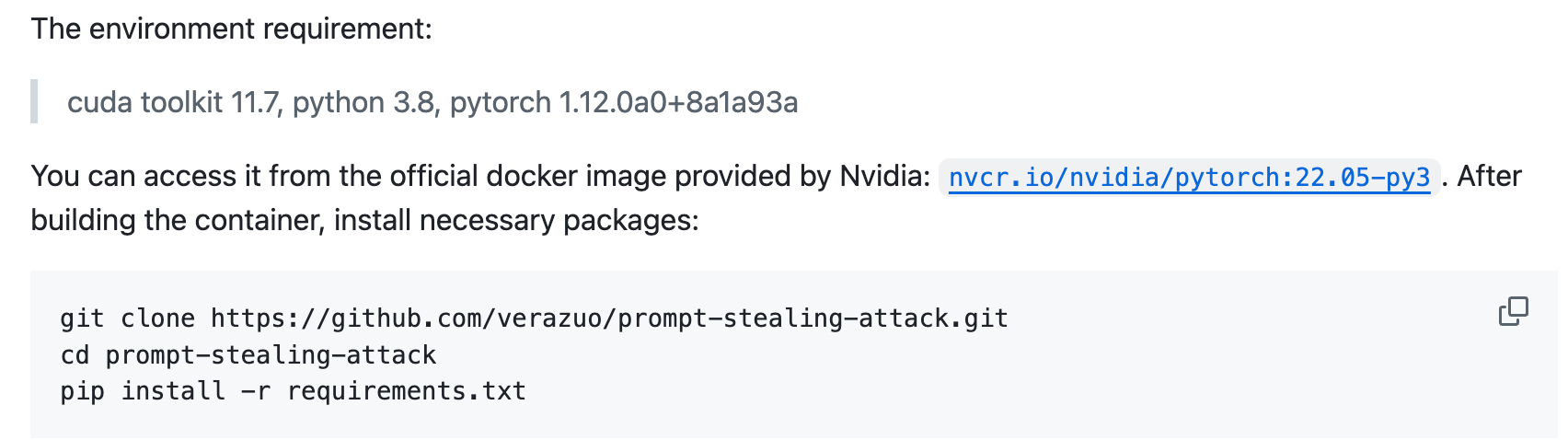
环境配置
1 Docker安装
可以根据此博客中的教程安装docker。
⚠️注意:不要在conda容器中嵌套安装docker,否则可能会报错。
(我使用的账号下已经安装好了docker,通过docker -v命令查看docker版本)
2 镜像拉取
拉取源码中给出的特定版本镜像,生成容器
执行如下命令:
python
docker run --gpus all -it --rm -v /newdata/test:/newdata nvcr.io/nvidia/pytorch:22.05-py3
'''
上述命令各部分的含义为:
- docker run 运行一个新的Docker容器。
- --gpus all 启用所有主机上的可用GPU资源(需要NVIDIA驱动和nvidia-docker支持)。
- -it 以交互模式运行容器,并分配一个伪终端(通常用于进入bash或python交互环境)。
- --rm 容器退出后自动删除该容器(不保留容器历史)。
- -v /newdata/test:/newdata 挂载主机目录/newdata/test到容器内的/newdata。这样容器可以访问主机上的数据。
- nvcr.io/nvidia/pytorch:22.05-py3 使用NVIDIA官方NGC(NVIDIA GPU Cloud)PyTorch容器镜像,版本为22.05,基于Python 3。
'''镜像拉取成功后,该容器下就会包含pytorch 1.12.0a0+8a1a93a特定版本。可在终端使用docker ps命令查看生成的容器。
3 其余库安装
在docker配置的容器下,切换到源码所在目录,运行pip install -r requirements.txt安装代码运行其余所需的库。
requirements.txt的精简版本如下:
python
inplace-abn
fairscale==0.4.4
imagehash
scikit-image
jsons
ftfy
clip==0.2.0
openai-clip==1.0.1
timm==0.4.12
transformers==4.15.0
pycocoevalcap
opencv-python-headless<4.3
opencv-contrib-python-headless<4.3
ruamel.yaml==0.17.32
datasets
pillow==10.4.0如果clip在使用过程中报错,就通过clip源码的方式安装,下载
https://github.com/openai/CLIP后在该目录下运行pip install -e .安装clip库。
这样一来,我们就得到了一个满足代码运行要求的环境。
PS:为避免docker环境的重复配置,可以结合tmux使用,将上述docker环境在tmux窗口下配置,一劳永逸。tmux常用命令:
python
tmux new-window -n demo # 新建窗口
tmux ls # 列举当前全部窗口
tmux attach -t demo # 打开特定窗口
tmux kill-session -t demo # 结束指定窗口数据集下载
由于代码运行过程中会用到论文中自建的lexica_dataset库,为避免在代码运行过程中因网络原因数据集下载失败导致报错,可以使用huggingface镜像预先下载数据集,在终端依次执行如下命令:
- 安装huggingface_hub库:
pip install -U huggingface_hub - 添加镜像:
export HF_ENDPOINT=https://hf-mirror.com - 将数据集下载到指定目录下:
huggingface-cli download --repo-type dataset --resume-download vera365/lexica_dataset --local-dir download_dir(替换成安装目录)
加载上述数据集时,使用如下命令,其中
cache_dir即为数据集的下载目录download_dir。
pythonfrom datasets import load_dataset data = load_dataset("vera365/lexica_dataset", split='test', cache_dir=download_dir)
后记:第一次接触并使用docker,全新的体验,感谢实验室同门的帮助!♥️路虽远,行之将至♥️
相关链接