本篇内容中,我们主要分享一些爬虫的前置知识,主要知识点有:
- 爬虫的概念和作用
- 爬虫的流程【重要】
- http相关的复习
- http和https概念和区别
- 浏览器访问一个网址的过程
- 爬虫中常用的请求头、响应头
- 常见的响应状态码
- 浏览器自带开发者工具的使用
爬虫概述
知识点:
- 了解 爬虫的概念
- 了解 爬虫的分类
- 掌握 爬虫的流程
1. 爬虫的概念
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
- 原则上,只要是浏览器(客户端)能做的事情,爬虫都能做。
- 爬虫只能获取到浏览器(客户端)所展示出来的数据。
简而言之:爬虫就是模拟浏览器,发送请求,获取响应。
2. 爬虫的作用
- 12306抢票
- 给喜欢的明星点赞、投票
- 新闻聚合网站: 百度新闻
- 搜索引擎
- 抓取微博评论(机器学习舆情分析)
- 抓取招聘网站的招聘数据(数据分析、挖掘)
3. 爬虫的分类
3.1 根据被爬取的网站数量,可以分为:
- 通用爬虫:通常指的是搜索引擎爬虫。
- 聚焦爬虫:针对某一网站或者某一类网站数据,如 12306 抢票。
3.2 根据是否以获取数据为目的,可以分为:
- 功能性爬虫,给你喜欢的明星投票、点赞
- 数据增量爬虫,比如招聘信息
3.3 根据 url 地址和对应的页面内容是否改变,数据增量爬虫可以分为:
- 基于 url 地址变化、内容也随之变化的数据增量爬虫
- url 地址不变、内容变化的数据增量爬虫
4. 爬虫的流程
爬虫流程如下图所示:
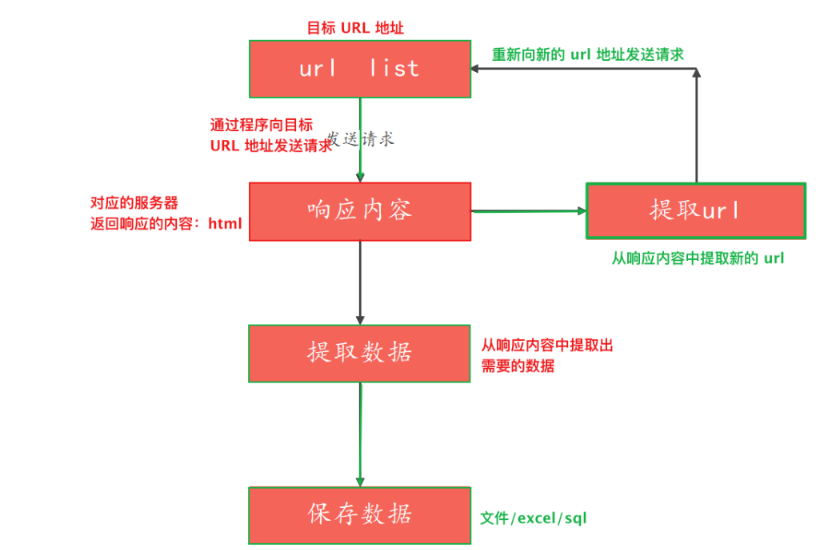
- 向起始的 url 地址发送请求,并获取响应数据(需要 http 协议)。
- 对响应进行提取。
- 如果提取 url,则继续发送请求获取响应。
- 如果提取数据,将数据进行保存。
总结
爬虫的概念: 模拟浏览器(客户端)发送网络请求,获取响应,只要是浏览器(客户端)能做的事,爬虫都能做。
爬虫的分类: 通用爬虫、聚焦爬虫。
爬虫的流程:
- 对起始页 url 地址发送请求,并获取到响应。
- 解析响应数据。
- 如果解析的是新的 url 地址,则继续发送请求、获取响应。
- 如果解析的是数据,则将数据进行保存
HTTP 与 HTTPS 协议
知识点:
- 了解 Http 的概念
- 掌握 Http 请求的过程
- 了解 用户访问网页背后发生了什么
- 掌握 Http 请求的格式
- 掌握 Http 响应格式
- 掌握 Http 常见请求头
- 掌握 Http 常见的响应状态码
1. HTTP 以及 HTTPS 的概念和区别
- HTTP:超文本传输协议,默认端口号是 80。
- 超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件。
- 传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容。
- HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协议,默认端口号:443。
- SSL 对传输的内容(超文本,也就是请求体或响应体)进行加密。
HTTPS比HTTP更安全,但是性能更低
2. HTTP 请求过程
2.1 HTTP 单次请求过程

2.2 浏览器请求过程
- 浏览器通过域名解析服务器(DNS)获取IP地址
- 浏览器先向IP发起请求,并获取响应
- 在返回的响应内容(html)中,可能会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
- 浏览器每获取一个响应就对展示出的结果进行添加(加载),js、css等内容可能会修改页面的内容,js也可以重新发送请求,获取响应
- 从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改------------这个过程叫做浏览器的渲染
2.3 注意
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)
浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,是因为爬虫不具备渲染的能力(当然后续课程中我们会借助其它工具或包来帮助爬虫对响应内容进行渲染)
- 浏览器最终展示的结果是由多个url地址分别发送的多次请求对应的多次响应共同渲染的结果
- 所以在爬虫中,需要以发送请求的一个url地址对应的响应为准来进行数据的提取
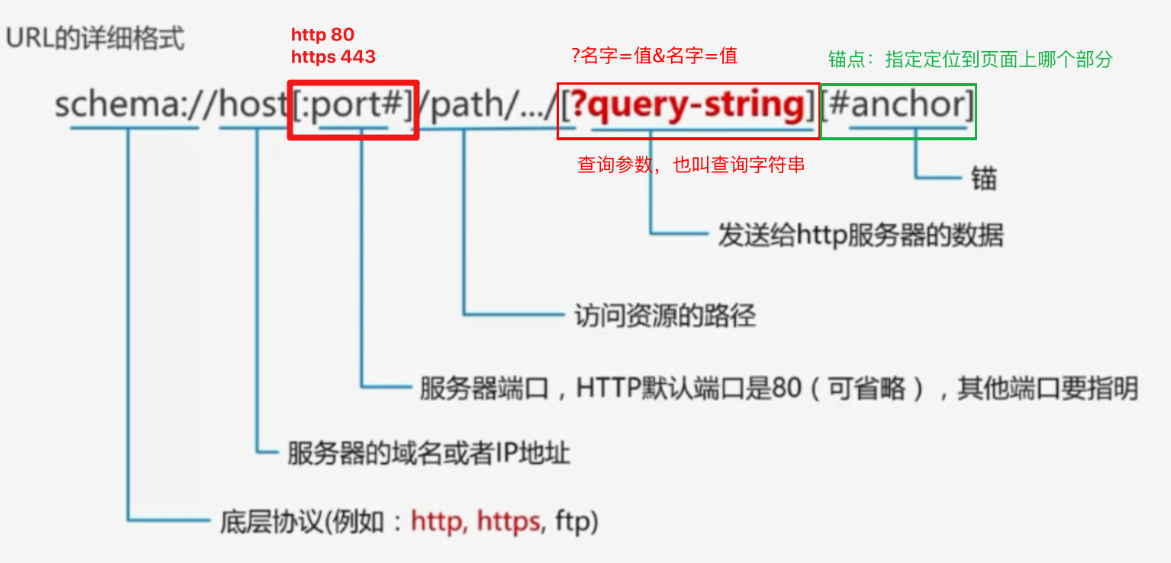
3. url 地址的格式
python
https://news.baidu.com/
http://www.chinanews.com/gn/shipin/cns-d/2021/06-30/news893297.shtml
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E4%BC%A0%E6%99%BA&fenlei=256&rsv_pq=a022b40d0004b304&rsv_t=2694IiGer%2F3sERQbCKrfdfhb3mxsAJMY5glCVPCKnYM8CXsrv9o65b3YEiU&rqlang=cn&rsv_enter=0&rsv_dl=tb&rsv_sug3=7&rsv_sug1=9&rsv_sug7=100&rsv_btype=i&inputT=16193&rsv_sug4=16194
http://mp-meiduo-python.itheima.net/4. HTTP 请求报文格式
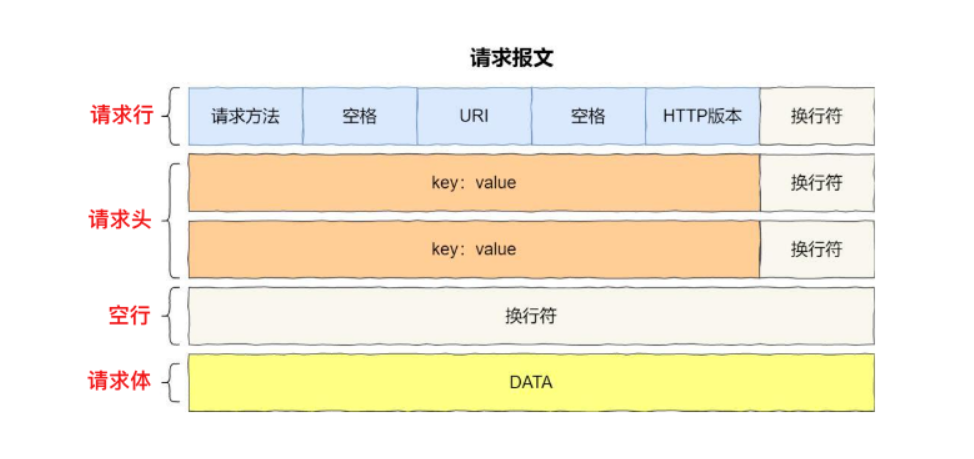
请求报文有四部分组成: 请求行、请求头、空行(回车符+换行符)、请求体
请求方式
- 根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
- HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
- HTTP1.1 新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
| 请求方式 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
注意:上面四种请求方式中,GET 请求时不能携带请求体
常见请求头
| 请求头 | 作用 |
|---|---|
| Cookie | Cookie状态保持数据 |
| User-Agent | 浏览器名称和信息 |
| Referer | 页面跳转处 |
| Host | 主机和端口号 |
| Connection | 连接类型 |
| Accept | 指定客户端能够接收的内容类型 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型 |
| X-requested-with:XMLHttpRequest | ajax请求 |
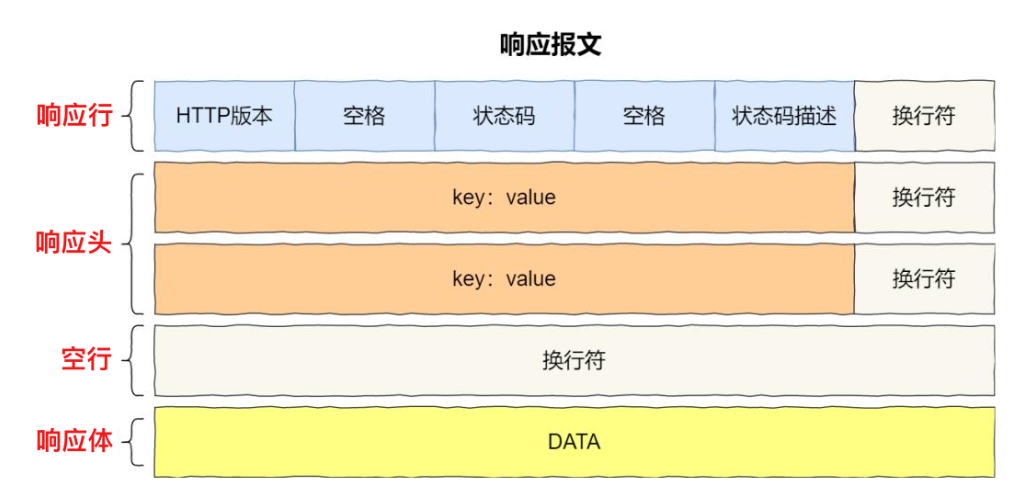
5. HTTP 响应报文格式
响应报文有四部分组成: 响应行、响应头、空行(回车符+换行符)、响应体(响应数据)
| 响应头 | 作用 |
|---|---|
| Location | 这个头配合302状态码使用,告诉用户端找谁。 |
| Set-Cookie | 设置和页面关联的Cookie |
| Content-Type | 服务器通过这个头,回送数据的类型 |
| Server | 服务器通过这个头,告诉浏览器服务器的类型 |
| Content-Length | 服务器通过这个头,告诉浏览器回送数据的长度。 |
| Connection | 服务器通过这个头,响应完是保持链接还是关闭链接。 |
6. 常见的响应状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP 状态码的英文为 HTTP Status Code。
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP 状态码共分为5种类型
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
常见的服务器响应状态码:
| 状态码 | 描述信息 |
|---|---|
| 200 | 请求成功 |
| 302 | 跳转,重定向,新的url地址会在响应头Location中给出 |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
| 404 | 找不到页面 |
| 500 | 服务器内部错误 |
| 503 | 服务器由于维护或者负载过重未能应答,在响应中可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码 |
7. 状态保持机制
HTTP 协议无状态性
HTTP 协议是一个无状态的协议,所谓的无状态,就是指客户端和 Web 服务器每次请求-响应的过程都是独立的,下一次的请求-响应不知道上一次的请求-响应所做的操作。
`A(客户端):你吃饭了吗?
B(服务器):我吃过了
A(客户端):你吃饭了吗?
B(服务器):我吃过了
A(客户端):你吃饭了吗?
B(服务器):我吃过了
...
`但是在我们实际的 Web 应用程序开发中,经常需要实现一些有状态的操作,比如:记住用户名、记住用户的登录状态等。要实现这些有状态的操作,常见的解决方案有两种:cookie机制和 session机制。
Cookie 机制
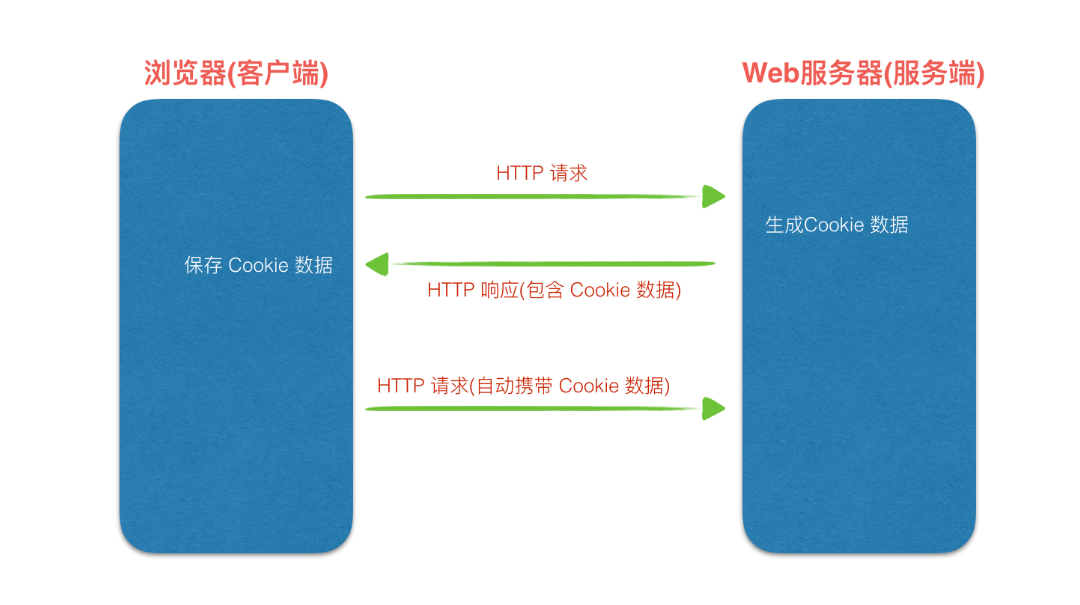
Cookie,有时也称 Cookies,指的是由服务端生成,保存在客户端的一种数据存储形式。服务器可以利用 Cookie 包含信息的任意性来筛选并经常性维护这些信息,以判断在 HTTP 传输中的状态。
过程图示:
特点说明:
-
Cookie 数据保存在客户端,以 key/value 形式进行存储,value大小有限制(最大为4kb),数据相对来说不安全
-
Cookie 是基于域名安全的,所属不同域名的 Cookie 是不能互相访问的
-
Cookie 是自动传递的,当浏览器访问一个域名时,会自动将这个域名所属的 Cookie 数据传递给对应的 Web 服务器
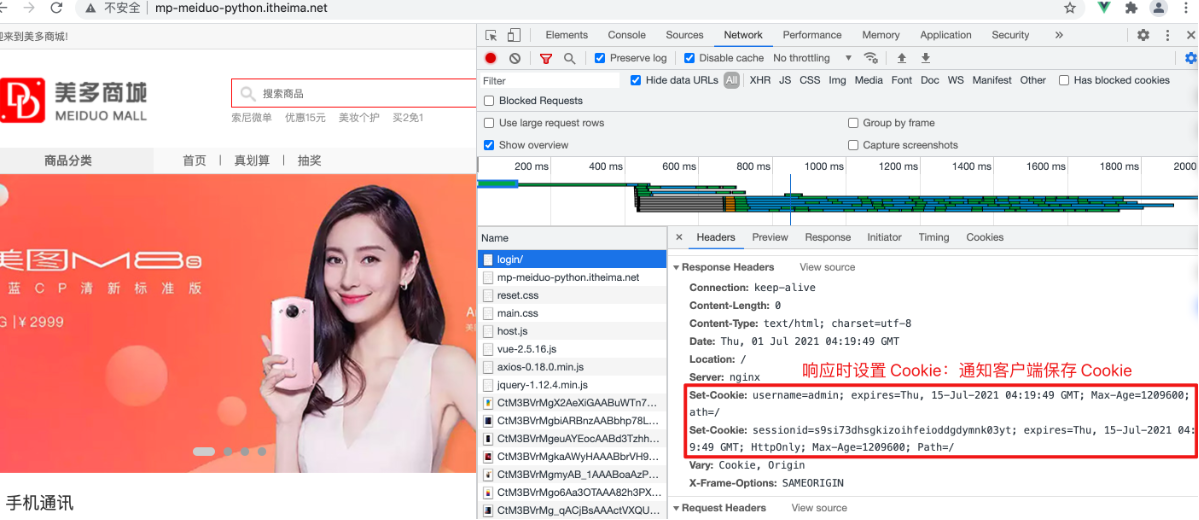
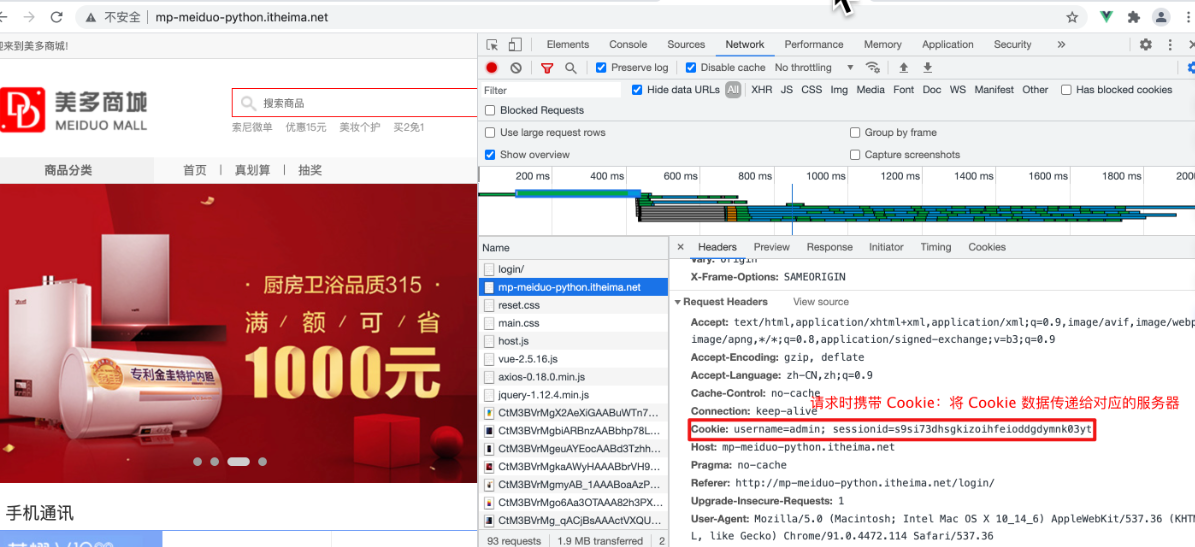
注意:Cookie 数据通过 Cookie 请求头进行携带,通过 Set-Cookie 响应头进行设置
应用案例:
Session 机制
Session,是一种会话控制方式。由服务端创建,并且保存在服务端的数据存储形式。Session 最典型应用:
记住登录用户状态
过程图示:
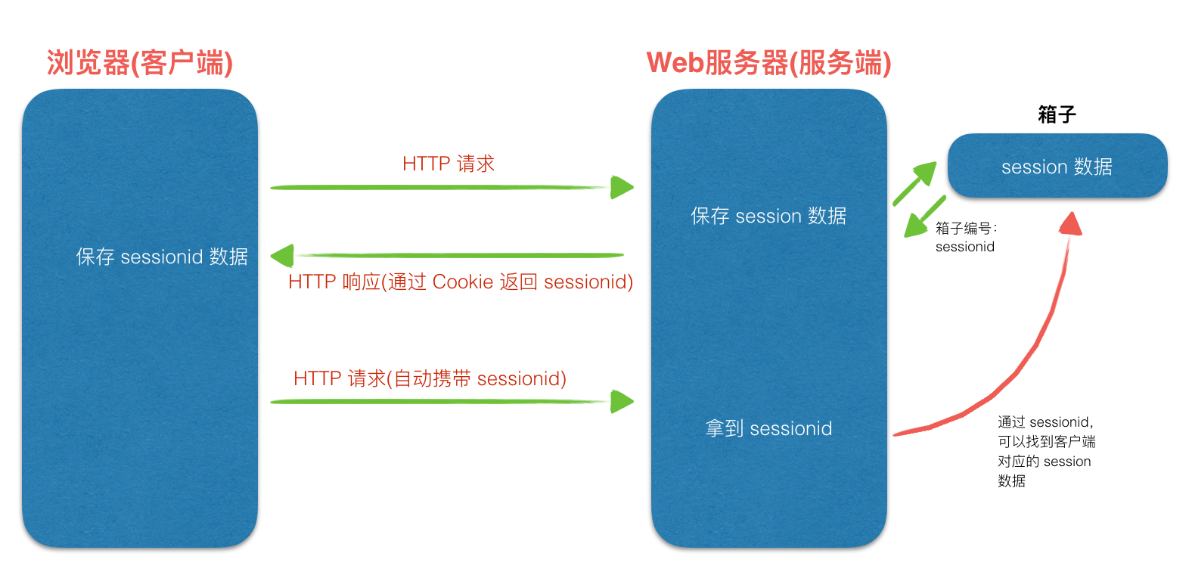
特点说明:
1)Session 数据保存的服务端,以key/value的形式进行存储,相对 Cookie 来说更加安全,可以存储一些敏感数据
2)Session 依赖于 Cookie,每个客户端对应的 Session 信息的标识,保存在客户端存储的 Cookie 中
3)每次客户端发送请求时,将 Session 信息标识的 Cookie 传递给对应的服务器,服务器就可以根据该标识取到对应客户端的 Session 数据
应用案例:
总结
- http: 超文本传输协议,默认端口号是 80。
- https:超文本传输协议 + SSL(安全套接字层),默认端口是 443
- 浏览器请求过程:用户输入网址 --> DNS 域名解析服务器,将域名解析为真是IP --> 浏览器拿到服务器真实 IP,去请求 --> 服务器接收到请求,处理请求,构造响应数据,返回 --> 浏览器接收到服务器响应数据,渲染,展示。
- url 地址的格式:协议://域名:端口号/资源路径/?数据#锚点
- HTTP 请求报文:
- 请求报文有四部分组成: 请求行、请求体、空行(回车符+换行符)、请求正文
- 常见请求头:
- cookie
- User-Agent
- Referer
- HTTP 响应报文:
- 响应报文有四部分组成: 响应行、响应体、空行(回车符+换行符)、响应主体(响应数据)
- 常见的响应头
- Location
- Set-Cookie
- 常见的响应状态码:200、302、403、404、500、503
- 状态保存机制:Cookie 和 Session
浏览器开发者工具(重点)
知识点
- 了解 如何打开浏览器开发者工具
- 了解 浏览器开发者工具菜单功能
- 了解 新建隐身窗口的目的
- 了解 Network 如何抓包
1.浏览器开发者工具介绍:
浏览器开发者工具就是给专业的Web应用和网站开发人员使用的工具,作用在于:
- 帮助开发人员对网页进行布局,比如HTML+CSS
- 帮助前端工程师更好的调试脚本(JavaScript、jQuery)代码
- 还可以使用该工具查看网页加载过程,获取网页请求(这个过程也叫做抓包)等
打开浏览器开发者工具的方式:
- 快捷键:F12
- 快捷键: Ctrl + Shift +I
- 直接使用鼠标在页面上 右键,选择检查
2.功能菜单
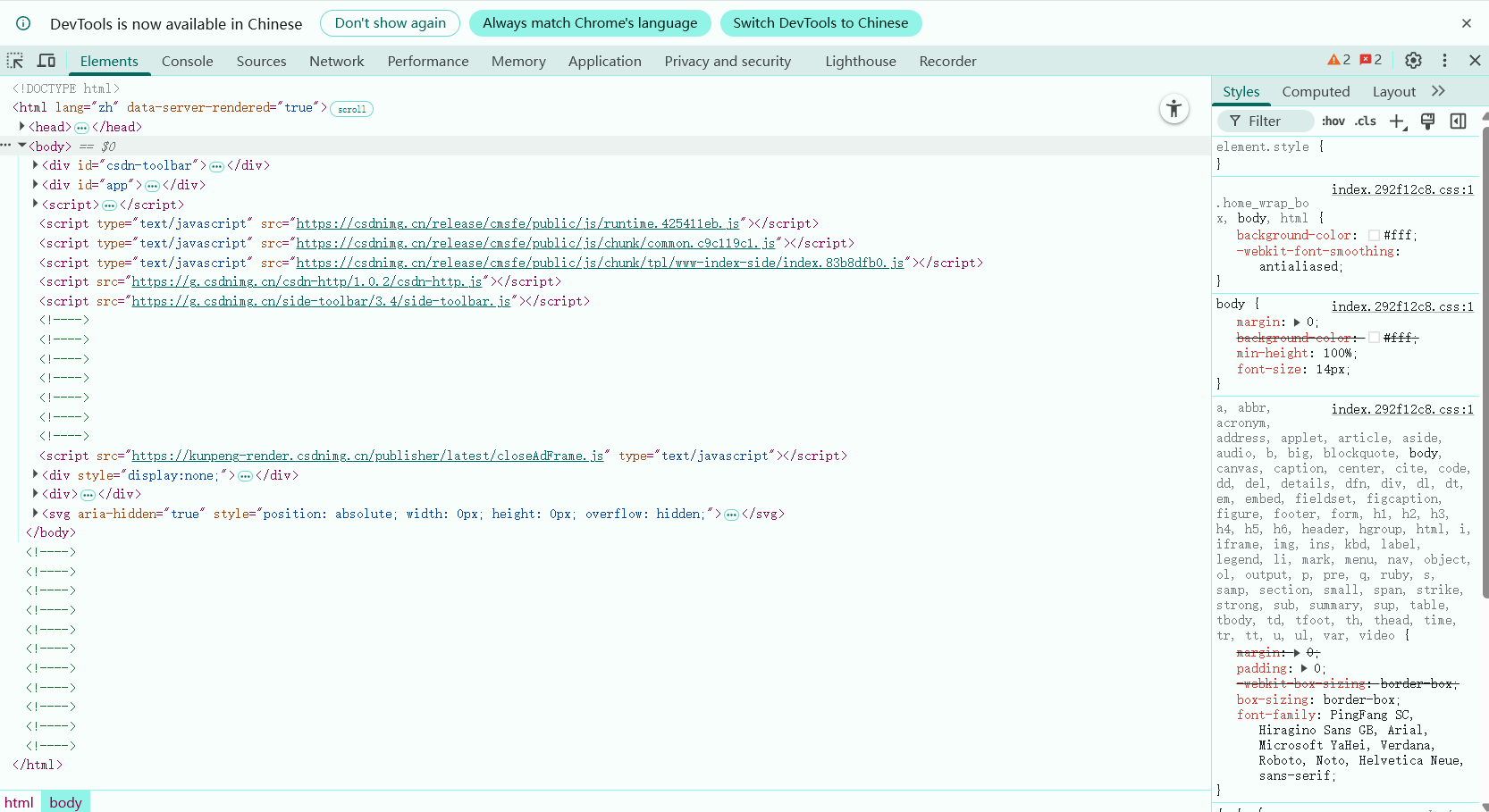
Chrome开发者工具最常用的四个功能模块:元素(Elements)、控制台(Console)、源代码(Sources)、网络(Network)。
- 元素(Elements):用于查看或修改HTML元素的属性、CSS属性、监听事件、断点等。css可以即时修改,即时显示。大大方便了开发者调试页面
- 控制台(Console):控制台一般用于执行一次性代码,查看JavaScript对象,查看调试日志信息或异常信息。还可以当作Javascript API查看用。例如我想查看console都有哪些方法和属性,我可以直接在Console中输入"console"并执行。
- 源代码(Sources):该页面用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码,此外最重要的是可以调试JavaScript源代码,可以给JS代码添加断点等。
- 网络(Network):网络页面主要用于查看header等与网络连接相关的信息。
3.浏览器无痕浏览模式:
查看第一次请求某个地址时,请求保存中包含的信息和响应时包含的信息。
浏览器中直接打开网站,会自动带上之前网站时保存的cookie,但是在爬虫中首次获取页面是没有携带cookie的,这种情况如何解决呢?
使用无痕窗口,首次打开网站,不会带上cookie,能够观察页面的获取情况,包括对方服务器如何设置cookie在本地。