以下是 Kafka 生产者工作流程的清晰分步解释,结合关键机制与用户数据:
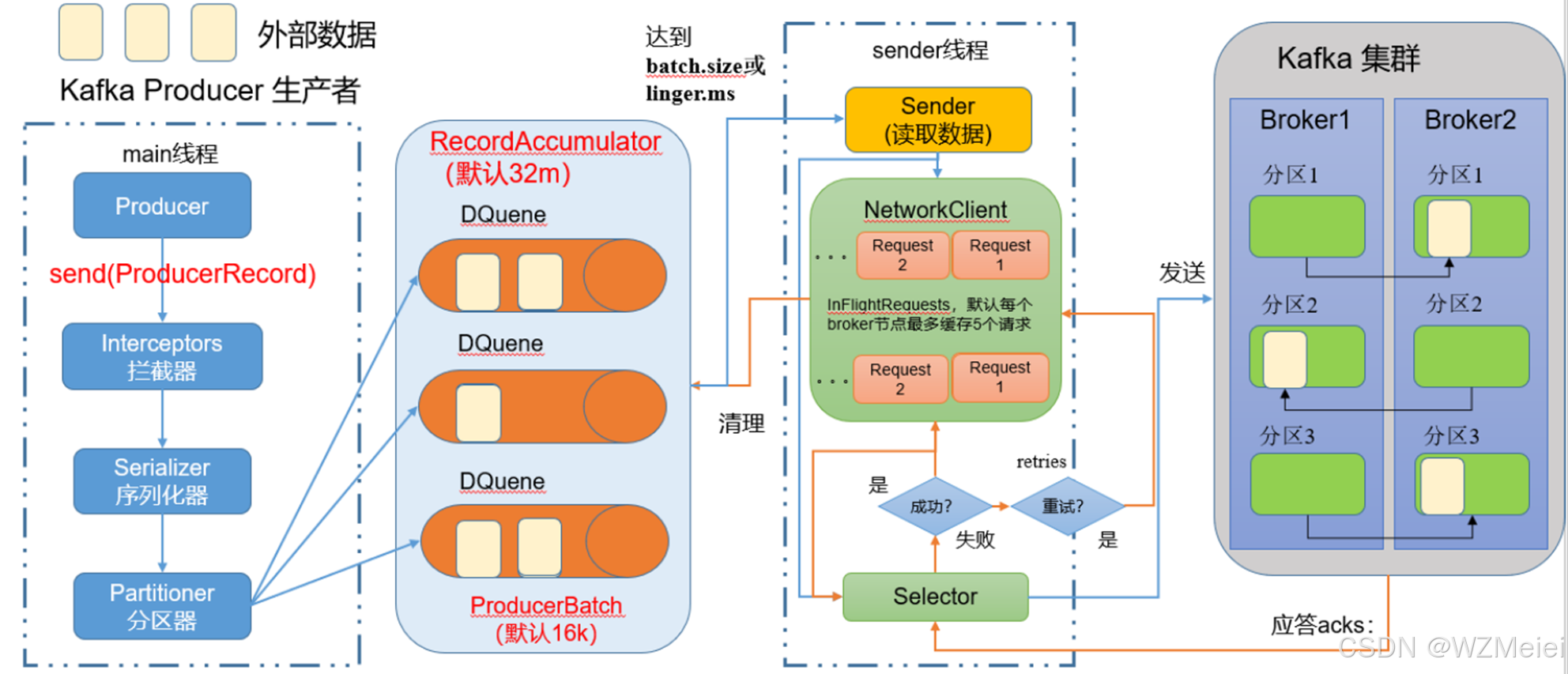
1. 生产者初始化与数据发送
-
主线程 创建生产者对象,调用
send(ProducerRecord)发送消息。- 拦截器(可选):可添加自定义逻辑(如日志、过滤),但默认不启用。
2. 数据预处理
-
序列化(Serializer)
将消息的 Key 和 Value 转换为字节流(如使用
StringSerializer或自定义序列化器)。java
javaproducer.send(new ProducerRecord<>("topic", "key", "value")); -
分区器(Partitioner)
决定消息写入 Topic 的哪个分区:
-
规则:若指定 Key,按 Key 哈希值分配分区;若未指定 Key,采用轮询或粘性分区策略(Kafka 2.4+ 默认粘性)。
-
目的:确保相同 Key 的消息进入同一分区,支持顺序消费。
-
3. 数据缓存(RecordAccumulator)
-
核心组件
-
双端队列(Deque) :每个分区对应一个队列,存放
ProducerBatch(批次)。 -
批次(ProducerBatch) :默认 16KB(
batch.size),装满后立即发送;若未满,等待linger.ms(默认 0ms,立即发送)。 -
总缓存大小 :默认 32MB(
buffer.memory),若缓存满则阻塞发送线程。
-
4. Sender 线程发送数据
-
Sender 线程 独立运行,从
RecordAccumulator拉取就绪批次。 -
网络请求封装:
-
NetworkClient 将批次按 Broker 分组,封装为 ProducerRequest。
-
InFlight Requests 控制 :每个 Broker 最多允许 5 个未确认请求(max.in.flight.requests.per.connection)。
-
作用:防止生产者压垮 Broker,保证网络负载均衡。
-
示例:若向 Broker1 发送的 5 个请求未收到 ACK,后续请求需等待。
-
-
5. 请求重试与 ACK 确认
-
ACK 机制 (
acks参数):-
acks=0:不等待确认,吞吐量最高,可能丢失数据。 -
acks=1:Leader 副本写入即成功,平衡可靠性与性能。 -
acks=all:所有 ISR 副本同步成功,可靠性最高,延迟较高。
-
-
重试机制 (
retries参数):- 默认不重试(
retries=0),需根据业务需求配置(如retries=3)。
- 默认不重试(
6. 数据写入 Kafka 集群
-
Broker 处理:
-
将数据写入对应分区的 Leader 副本。
-
若
acks=all,Follower 副本从 Leader 拉取数据完成同步。
-
-
分区分布:
- 一个 Topic 的分区分布在多个 Broker 上(如用户示例的 13 个分区可能分布在 Broker1、Broker2 等)。
关键纠正与易混淆点
-
InFlight Requests 与分区的区别
-
InFlight 限制的是每个 Broker 的未确认请求数,与分区无关。
-
例如:Broker1 有分区1、分区2,但向 Broker1 发送的请求总数不能超过 5。
-
-
分区选择逻辑
-
分区由分区器在发送时确定,不会因 Broker 负载高而自动切换。
-
若某分区的 Leader Broker 请求队列已满,生产者会等待,而不是发送到其他分区。
-
-
批次合并优化
- Sender 线程会合并同一分区的多个小批次,减少网络请求次数,提升吞吐量。
全流程总结图
java
[Main线程]
↓ 创建生产者对象
↓ 调用 send() → 拦截器 → 序列化 → 分区器
↓ 写入 RecordAccumulator(缓存批次)
|
|(批次满或时间到)
↓
[Sender线程]
↓ 拉取批次 → 按 Broker 分组
↓ NetworkClient 封装请求 → 发送至 Broker
|
|(等待 ACK 或重试)
↓
[Kafka集群]
↓ Broker 接收请求 → 写入 Leader 副本
↓ 副本同步(acks=all 时) → 返回 ACK