在语义分割中,ROI(Region of Interest,感兴趣区域)是图像中需要重点关注的部分。其作用包括:提高效率,减少高分辨率图像的计算量;增强分割精度,聚焦关键语义信息;减少背景干扰,提升模型性能;适应特定场景需求,如医学图像中的肿瘤检测或自动驾驶中的行人检测。ROI 提取可通过手动标注、目标检测算法或注意力机制实现,是优化语义分割任务的重要手段。
目录
[ROI Align](#ROI Align)
[RoIWrap Pooling](#RoIWrap Pooling)
[RoIAlign Pooling](#RoIAlign Pooling)
ROI Align
这种 Pooling 方法是在 Faster RCNN 中看到的,该种 Pooling 方法采用的运算方法比较直接。
注意:
网络结构与用途
Faster R - CNN :是一种目标检测算法,主要用于在图像中找出目标物体位置并分类 。它基于 R - CNN 系列发展而来,结构上包含区域提议网络(RPN)、特征提取网络(如 VGG、ResNet 等)、ROI(Region of Interest)池化层以及分类和回归分支。先由 RPN 生成可能包含目标的候选区域,再对候选区域进行特征提取和分类回归。
FCN(Fully Convolutional Networks) :是语义分割算法 。它将传统 CNN 中的全连接层替换为卷积层,可接受任意尺寸图像输入,输出与输入图像尺寸相关的分割结果,对图像每个像素进行分类,确定像素所属类别。
工作原理
Faster R - CNN :通过 RPN 在特征图上滑动窗口生成大量候选区域,根据与真实目标框的 IoU(交并比)等指标筛选正负样本训练 RPN;特征提取网络提取图像特征后,ROI 池化层将不同大小候选区域特征映射到固定大小,最后分类分支判断类别,回归分支微调候选区域坐标。
FCN :对输入图像直接进行卷积操作提取特征,经多次卷积和下采样得到低分辨率高语义信息特征图;之后通过上采样(如反卷积等)操作将特征图恢复到接近输入图像尺寸,每个像素对应一个类别概率,实现像素级分类。
应用场景
Faster R - CNN :常用于目标检测场景,像安防监控中检测行人、车辆;自动驾驶中识别道路标志、车辆、行人等目标。
FCN :主要用于语义分割领域,如医学图像分割,区分器官、病变组织等;卫星图像土地利用分类,区分建筑、农田、森林等。
下面是其计算的流程图
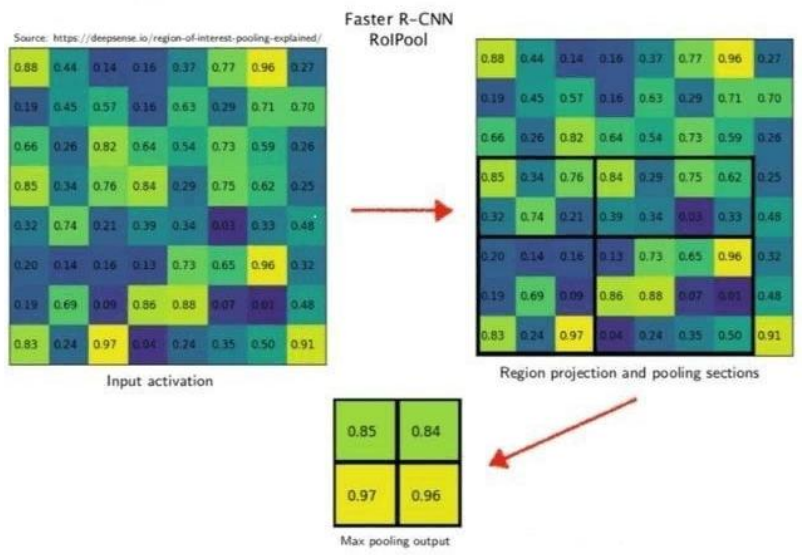
在该网络中假设使用的骨架网络中的 feat stride=16,且测试图像中的一个边界框的大
小为 400∗ 300。
1 ) 首 先 计 算 对 应 feature map 上 图 的 大 小 , 那 么 在 特 征 图 上 的 大 小 就 是 400/16 ∗ 300/16=25∗ 18.75,注意这个时候出现小数了。那么就需要对其进行第一次量化操作,得到的特征图上大小为 25∗ 18。
2)得到 Pooling 结果。最后的 RoI Pooling 的输出是固定的为 7∗ 7,那么就要对这个特征图进行划分,那么划分出来的每一块的大小就是 25/7∗ 18/7=3.57∗ 2.57。又有小数,需要继续取整,这是第二次量化操作,块的区域就变成了 3∗ 2,然后再在这个区域上做 max pooling 得到最后的结果。
所以很大的误差是来自于量化过程,量化误差不断积累就变得很大了。
用一个生活中的例子来理解 RoI Pooling 的过程,就像把一张地图缩小后再划分格子找宝藏一样:
假设你有一张高清地图(原图),但计算机为了方便处理,会先把地图缩小成一张 "缩略图"(特征图)。这里有个缩小比例叫 feat stride=16,意思是缩略图上的 1 个像素,对应原图的 16×16 像素区域。
现在,你在原图上画了一个框(边界框),比如框住了一个 400×300 像素的区域(比如一片森林),你想知道这个区域在缩略图上的位置和大小。
第一步:找缩略图上的框(第一次量化)
计算缩略图上的框大小:
原图框是 400×300 像素,缩小 16 倍后,缩略图上的框应该是:
400÷16=25 像素宽,300÷16=18.75 像素高。
问题:但像素必须是整数,没法有 0.75 个像素,所以只能 "四舍五入" 或直接取整,这里直接取整为 25×18 像素(相当于把森林的缩略图强行压缩成 25 列、18 行的格子)。
类比:就像把一张纸从 A4 缩到 A5,纸上的画也会变小,但边缘可能被裁掉一点(取整导致误差)。
第二步:划分格子做 Pooling(第二次量化)
现在,你需要从这个 25×18 像素的缩略图框里,提取一个固定大小的特征(比如 7×7 的格子),就像把这片森林分成 7 行 7 列的小区域,每个区域找最明显的特征(比如最高的树、最大的石头)。
计算每个小格子的大小:
把 25 列分成 7 份:25÷7≈3.57列 / 格,
把 18 行分成 7 份:18÷7≈2.57行 / 格。
问题:又出现小数了!格子不能有 0.57 列,所以再次取整,变成 3 列 / 格 和 2 行 / 格。
类比:就像把一块蛋糕切成 7 份,但蛋糕尺寸不是 7 的倍数,只能尽量均分,每份大小可能不一样(左边 3 列,右边可能 4 列;上边 2 行,下边可能 3 行)。
每个格子里找最大值(Max Pooling):
现在,每个小格子是 3×2 像素的区域,在这个区域里找像素值最大的点(比如最亮的像素,代表可能有宝藏的位置),作为这个格子的特征值。
最终得到 7×7 的特征矩阵,这样无论原图框多大,输出都是固定尺寸的特征。
为什么会有误差?
第一次取整误差:原图框缩小到缩略图时,小数部分被直接舍弃(比如 0.75 像素没了),相当于把森林的边缘裁掉了一点。
第二次取整误差:划分小格子时,小数部分再次被舍弃,导致每个格子的实际大小和理想值不一致(比如本应 3.57 列的格子,只取了 3 列)。
误差积累:两次取整让框的位置和大小都偏离了真实值,就像两次 "近似裁剪" 后,地图上的森林位置可能和实际差了一块。
RoIWrap Pooling
该 Pooling 方法比前面提到的 Pooling 方法稍微好一些。对于一个选出来的预测框,
它的对应的 RoI 区域可以通过 feat stride 算出来(crop 操作)。
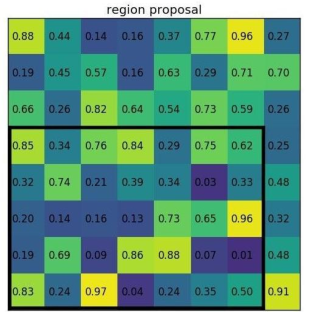
那么该方法与上一个方法的区别是什么呢?主要的区别在于第二步。还是用上面提到的
例子:在该网络中假设使用的骨架网络中的 feat stride=16,且测试图像中的一个边界框的
大小为 400∗ 300。
1)corp 操作。边界框在对应 feature map 上的大小为 400/16∗ 300/16=25∗ 18.75,
注意这个时候出现小数了。那么就需要像之前的方法一样对其进行第一次量化操作,得到的特征图上大小为 25∗ 18。
2)warp 操作。这里使用的是双线性差值算法,使 corp 操作的特征图变化到固定的尺
度上去,比如 14∗ 14,这样再去做 Pooling 得到固定的输出。这里的坐标就是连续的了,不会存在量化误差。
可以看出这里去掉了第二次的量化操作,进而减小了误差,也提升了检测的精度。
可以用 "修图" 的例子来理解 RoIWrap Pooling 的核心改进,它就像用更精细的 "拉伸" 替代 "硬裁剪",减少了变形误差。
背景:问题从何而来?
在目标检测中,我们需要从原图的一个边界框(比如 400×300 像素的 "汽车" 区域)中提取特征,但计算机处理时,会先把原图缩小成一张 "缩略特征图"(缩小比例 feat stride=16)。此时,原图的边界框在特征图上会被缩小为 25×18.75 像素的区域(类似把一张大照片缩小后,汽车的位置可能变成 25 列、18.75 行的格子)。
RoI Pooling 的问题:两次 "硬裁剪"
之前的 RoI Pooling 会做两件事:
第一次裁剪(量化):把 18.75 行强行取整为 18 行(因为像素不能是小数),相当于把汽车的 "尾巴" 裁掉一点。
第二次裁剪(量化):把 25 列 ×18 行的区域分成 7×7 个小格子,但 25÷7≈3.57 列 / 格、18÷7≈2.57 行 / 格,又出现小数,只能再次取整为 3 列 / 格、2 行 / 格,导致每个小格子的大小被 "硬调整"(比如左边 3 列,右边可能 4 列)。
这两次 "硬裁剪" 会让特征区域变形,就像用剪刀强行把照片剪成格子,边缘和比例都会走样。
RoIWrap Pooling 的改进:用 "拉伸" 替代第二次裁剪
RoIWrap Pooling 的核心是第二步用 "双线性插值" 替代 "硬取整",具体分两步:
- 第一步:Crop(裁剪,仍有第一次量化)
和 RoI Pooling 一样,原图的边界框(400×300)在特征图上缩小为 25×18.75 像素的区域。由于像素必须是整数,仍需取整为 25×18 像素(裁掉 0.75 行的尾巴)。
- 第二步:Warp(变形,无第二次量化)
关键区别在这里!RoIWrap 不会强行把 25×18 的区域分成 7×7 个 "硬格子",而是直接用双线性插值把整个 25×18 的区域 "拉伸" 或 "压缩" 成固定尺寸(比如 14×14)。
双线性插值的作用:允许坐标是连续的小数(比如第 3.5 列、第 2.7 行),通过周围像素的加权平均计算新位置的像素值。这样,25 列 ×18 行的区域可以平滑地变成 14 列 ×14 行,不需要把小数部分 "裁掉" 或 "凑整"。
类比:就像用修图软件的 "自由变换" 功能,把一张 25×18 的小照片均匀拉伸成 14×14 的尺寸,虽然整体缩小了,但比例和细节保留得更完整(不会出现左边 3 列、右边 4 列的 "硬分割")。
- 最后:Pooling(取最大值)
拉伸后的 14×14 区域再做 Pooling(比如取最大值),得到固定尺寸的输出(比如 7×7)。
为什么误差更小?
RoIWrap Pooling 只在第一步做了一次 "裁剪"(量化),第二步通过双线性插值 "柔和调整" 尺寸,避免了 RoI Pooling 的第二次 "硬取整"。就像用 "拉伸" 替代 "剪刀剪",减少了区域变形和细节丢失,特征更接近真实值,检测精度自然更高。
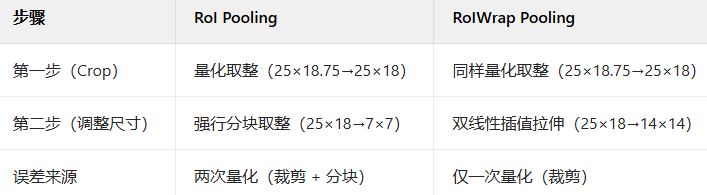
总结:核心区别
RoIAlign Pooling
这种 Pooling 方法是在 Mask RCNN 中被采用的,这相比之前的方法其内部完全去掉
了量化操作,取而代之的线性操作,使得网络特征图中的点都是连续的。从而提升了检测的精确度。
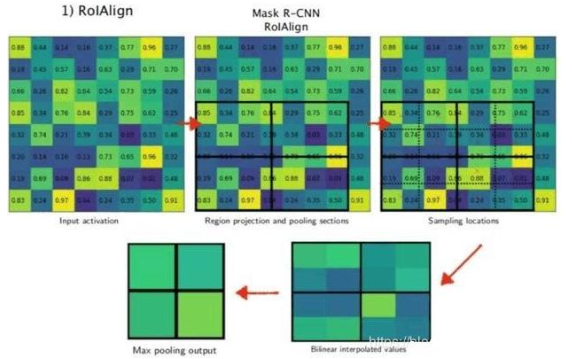
在该网络中假设使用的骨架网络中的 feat stride=16,且测试图像中的一个边界框的大小为 400∗ 300。
1)得到对应 feature map 中对应的区域。这里可以算出对应的区域大小为 400/16∗
300/16=25∗ 18.75,这个通过双线性差值计算的得到。这就是这一部分的结果了,不会对其进行量化操作。
2)得到 Pooling 结果。假设 Pooling 的固定输出为 7∗ 7,那么每个块得到的大小是 25/7∗ 18.75/7=3.57∗ 2.65。对于这样的一个块,假设在其中选择 2∗ 2 个采样点,那么每个采样点的值也是可以通过双线性差值得到,这样也是连续的。
因而相比前面的两个算法,其内部实现并没有存在量化的操作,也就没有因为量化而带
来的误差。这就使得其检测精确度进一步提升。具体的差别有多大?可以看一下 Mask RCNN 中给出的实验数据。
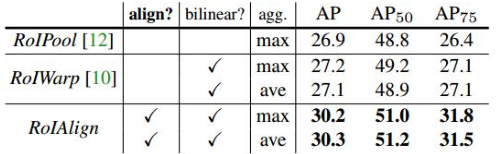
用 "绘制地图" 的比喻来理解 RoIAlign Pooling,像用 "无级缩放" 替代 "像素化裁剪",让每个点都能精准定位,避免误差积累。
核心突破:彻底告别 "取整裁剪"
RoIAlign 的最大特点是全程不进行任何量化取整,所有坐标都允许是小数,通过双线性插值计算连续坐标的像素值。就像在地图上标记位置时,允许用经度纬度的小数(如 123.456°,45.678°)精准定位,而不是强制四舍五入到整数度数。
回到例子:边界框 400×300,feat stride=16


每个采样点的值怎么算?
用双线性插值,根据采样点周围 4 个整数像素的坐标加权平均。例如,采样点(0.893, 0.670)周围的 4 个像素是:
左上:(0, 0),右上:(1, 0),
左下:(0, 1),右下:(1, 1)。通过这 4 个点的值加权计算出采样点的值(权重由采样点到这 4 个点的距离决定)。
- 第三步:Pooling(取最大值或平均值)
计算每个块内所有采样点的值后,取最大值(Max Pooling)或平均值,作为该块的输出。最终得到 7×7 的特征图。
为什么这样更精确?
无量化误差:
RoI Pooling 两次取整(如 18.75→18,3.57→3),导致区域位置和大小偏离真实值,
RoIAlign 全程用小数坐标,就像用 "游标卡尺" 精准测量,而非 "普通尺子" 粗略取整。
连续特征映射:
双线性插值让每个采样点都能 "感知" 周围像素的信息,避免因取整导致的 "特征断裂"。比如,原图中汽车轮胎的边缘可能落在小数坐标上,RoIAlign 能准确捕捉,而 RoI Pooling 可能直接裁掉或错放到相邻像素。类比:像素画 vs. 矢量图
RoI Pooling:像像素画,放大后边缘锯齿明显(量化误差导致特征模糊)。
RoIAlign:像矢量图,无论怎么缩放,边缘都平滑(连续坐标 + 插值保留细节)。
在 Mask RCNN 中,这种精度提升对实例分割至关重要 ------ 比如分割汽车时,轮胎边缘的精确性直接影响掩码(Mask)的质量。