Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第五章 Functions(函数)
程序员在 Python 中使用的第一个组织工具就是函数。与其他编程语言一样,函数可使你将大型程序分解为更小、更简单的组成部分,并为每个部分赋予名称以表示其功能。这有助于提高代码的可读性,使其更加易于理解。同时,函数还支持代码的复用和重构。
Python 中的函数拥有多种附加特性,这些特性使程序员的编程工作变得更加轻松。其中一些特性与其他编程语言中的功能相似,但许多特性是 Python 所独有的。这些附加功能能够使函数的接口更加清晰明了。它们能够消除冗余信息,强化调用者的意图。此外,它们还能显著减少那些难以发现的细微错误。
Item 33:了解闭包如何与变量作用域和 nolocal 交互
想象一下,我想要对数字列表进行排序,但将一组数字优先排列在第一位。当您渲染用户界面并希望在其他所有内容之前显示重要消息或异常事件时,此模式非常有用。执行此操作的常见方法是将助手函数作为键参数传递给列表的排序方法(有关详细信息,请参阅 Item 100:"使用键参数按复杂条件排序")。助手函数的返回值将用作对列表中每个项目进行排序的值。助手函数可以检查给定的项目是否在重要组中,并可以相应地改变排序值:
def sort_priority(values, group):
def helper(x):
if x in group:
return (0, x)
return (1, x)
values.sort(key=helper)该函数适用于简单的输入情况:
numbers = [8, 3, 1, 2, 5, 4, 7, 6]
group = {2, 3, 5, 7}
sort_priority(numbers, group)
print(numbers)
>>>
[2, 3, 5, 7, 1, 4, 6, 8]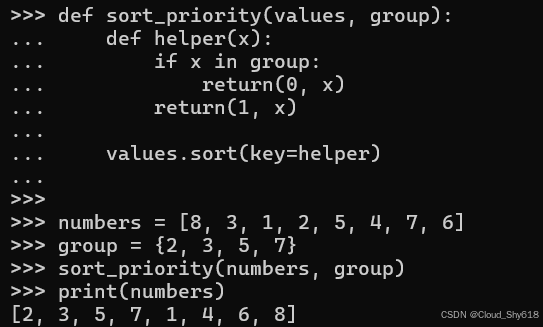
该功能能够按预期运行的原因有三点:
- Python 支持闭包------即那些引用其所定义作用域内变量的函数。正因如此,助手函数才能够访问 sort_priority 函数中的 group 参数。
- 在 Python 中,函数属于一等对象,这意味着你可以直接引用它们、将其赋值给变量、将其作为参数传递给其他函数、在表达式和 if 语句中进行比较等。正是基于此,排序方法才能接受闭包函数作为关键参数。
- Python 对比较序列(包括元组)有着特定的规则。它首先比较位于索引为 0 的项;如果这些项相等,则接着比较位于索引为 1 的项;如果这些项仍然相等,则继续比较位于索引为 2 的项,以此类推。正因如此,来自助手闭包函数的返回值才会导致排序结果中出现两个截然不同的组别。
如果这个函数能够返回更高优先级项是否已被查看的信息,那将会非常有用,这样用户界面代码就能据此采取相应的操作。添加此类功能似乎相当简单。目前已有一个闭包函数用于确定每个数字所属的组别。何不利用这个闭包功能,在遇到更高优先级项时翻转一个标志位呢?如此一来,函数便可在经过闭包修改后返回标志位的值。
在此,我试图以一种看似显而易见的方式做到这一点:
def sort_priority2(numbers, group):
found = False # Flag initial value
def helper(x):
if x in group:
found = True # Flip the flag
return (0, x)
return (1, x)
numbers.sort(key=helper)
return found # Flag final value我能够用与之前相同的输入来运行这个函数:
found = sort_priority2(numbers, group)
print("Found:", found)
print(numbers)
>>>
Found: False
[2, 3, 5, 7, 1, 4, 6, 8]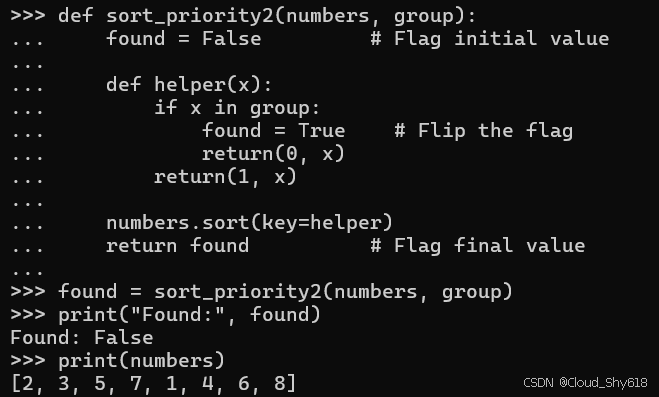
排序后的结果是正确的,这意味着来自该组的项目确实以数字形式被找到了。然而,该函数返回的结果却是 False(而本应返回 True)。这究竟是如何发生的呢?当你在表达式中引用一个变量时,Python 解释器会按以下顺序遍历嵌套的上下文范围以解析该引用:
- 当前函数的作用域;
- 任何包含的上下文范围(例如其他包含的函数);
- 包含代码所在的模块的范围(也称为全局范围);
- 内置作用域(其中包含诸如 len 和 str 之类的函数)。
如果上述任何地方均未以所引用的名称定义过某个变量,则会引发 NameError 异常:
foo = does_not_exist * 5
>>>
Traceback ...
NameError: name 'does_not_exist' is not defined
为变量赋值的方式是不同的。如果变量已在当前作用域中定义,则该名称将采用该作用域中的新值。如果当前作用域中不存在该变量,Python 会将赋值视为变量定义。至关重要的是,新定义的变量的作用域是包含赋值的函数,而不是具有早期赋值的封闭作用域。
此赋值行为解释了 sort_priority2 函数的错误返回值。在帮助闭包中,found 变量被赋值为 True。闭包的赋值被视为 helper 范围内的新变量定义,而不是 sort_priority2 范围内的赋值:
def sort_priority2(numbers, group):
found = False # Scope: 'sort_priority2'
def helper(x):
if x in group:
found = True # Scope: 'helper' -- Bad!
return (0, x)
return (1, x)
numbers.sort(key=helper)
return found这个问题有时会被称作 "范围界定错误",因为它可能会让新手感到十分惊讶。但这种行为恰恰是预期的结果:它能够防止函数中的局部变量污染包含该函数的模块。否则,函数中的每一次赋值操作都会将垃圾数据引入全局模块作用域。这不仅会造成干扰,而且由此产生的全局变量的相互作用还可能导致难以察觉的漏洞。
在 Python 中,存在一种特殊的语法用于在闭包作用域之外进行数据赋值。 nolocal 语句被用于表明应在为某个特定变量名进行赋值时进行作用域遍历。唯一的限制在于 nolocal 不会向上追溯至模块级作用域(以避免污染全局变量)。
在此处,我再次定义了相同的函数,但这次使用了 nolocal 变量:
def sort_priority3(numbers, group):
found = False
def helper(x):
nonlocal found # Added
if x in group:
found = True
return (0, x)
return (1, x)
numbers.sort(key=helper)
return found现在 foundflag 符合预期生效:
found = sort_priority3(numbers, group)
print("Found:", found)
print(numbers)
>>>
Found: True
[2, 3, 5, 7, 1, 4, 6, 8]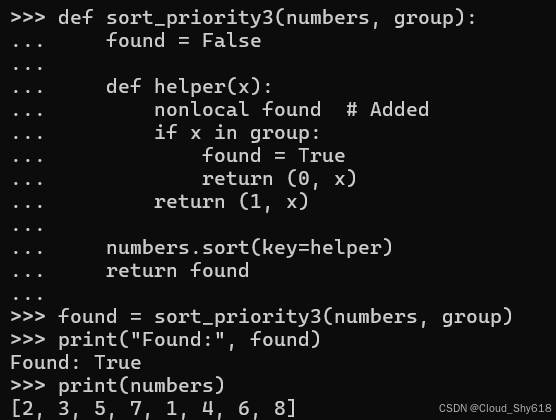
nolocal 语句清晰地表明了数据何时会从闭包中被赋值并进入到另一个作用域中。它与 global 语句相辅相成,后者表示变量的赋值应直接进入模块作用域。
然而,就像全局变量的反模式一样,警告不要对简单函数之外的任何内容使用 nolocal。nonlocal 的副作用可能很难理解。在长函数中尤其难以理解,因为 nolocal 语句和关联变量的赋值相距甚远。
当您对 nolocal 的使用变得愈发复杂时,最好将您的状态封装到一个辅助类中。在此处,我定义了一个可以像函数一样调用的类;它通过在排序过程中赋值对象属性的方式实现了与 nolocal 相同的效果(参见 Item 55:"优先使用公共属性而非私有属性"):
class Sorter:
def __init__(self, group):
self.group = group
self.found = False
def __call__(self, x):
if x in self.group:
self.found = True
return (0, x)
return (1, x)它比以前长了一点,但如果需要的话,它更容易推理和扩展(有关 __call__ 特殊方法的详细信息,请参阅 Item 48:"接受函数而不是简单接口的类")。我可以访问 Sorter 实例上的 found 属性来获取结果:
numbers = [8, 3, 1, 2, 5, 4, 7, 6]
sorter = Sorter(group)
numbers.sort(key=sorter)
print("Found:", sorter.found)
print(numbers)
>>>
Found: True
[2, 3, 5, 7, 1, 4, 6, 8]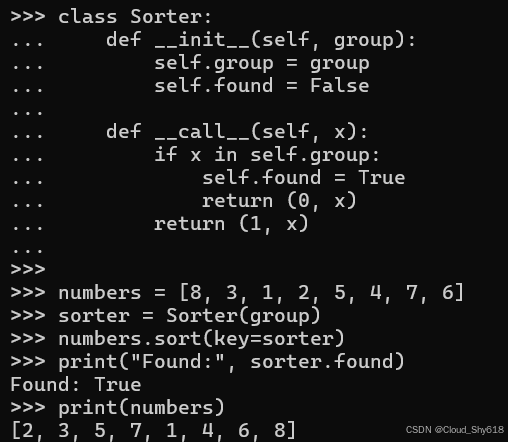
注意:
- 闭包函数可以引用其所定义于其中的任何封闭作用域中的变量。
- 默认情况下,闭包无法通过赋值变量来影响其所在的上下文范围。
- 使用 nolocal 语句来表明何时一个闭包能够修改其所属作用域中的变量。使用 global 语句来对模块级别的名称实现同样的功能。
- 避免将 nolocal 语句用于简单函数之外的任何内容。
Item 34:通过可变位置参数减少视觉噪音
接受可变数量的位置参数可以使函数调用更清晰并减少视觉噪音。这些位置参数通常简称为 varargs 或 *args,参考参数 *args 的常规名称。例如,假设我想记录一些调试信息。对于固定数量的参数,我需要一个接受消息和值列表的函数:
def log(message, values):
if not values:
print(message)
else:
values_str = ", ".join(str(x) for x in values)
print(f"{message}: {values_str}")
log("My numbers are", [1, 2])
log("Hi there", [])
>>>
My numbers are: 1, 2
Hi there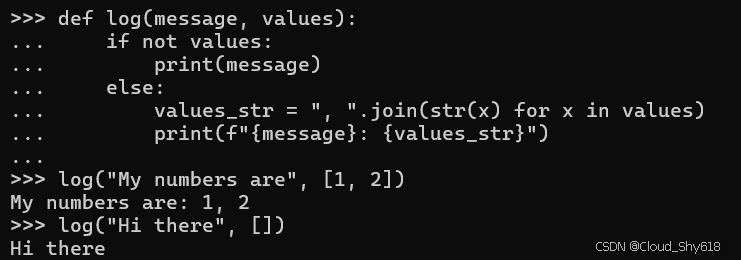
当我没有要记录的值时,必须传递一个空列表既麻烦又嘈杂。最好完全省略第二个参数。我可以在 Python 中通过在最后一个位置参数名称前添加 * 来完成此操作。日志消息的第一个参数是必需的,任意数量的后续位置参数是可选的。函数体不需要改变;只有调用者才会这样做:
def log(message, *values): # Changed
if not values:
print(message)
else:
values_str = ", ".join(str(x) for x in values)
print(f"{message}: {values_str}")
log("My numbers are", 1, 2)
log("Hi there") # Changed
>>>
My numbers are: 1, 2
Hi there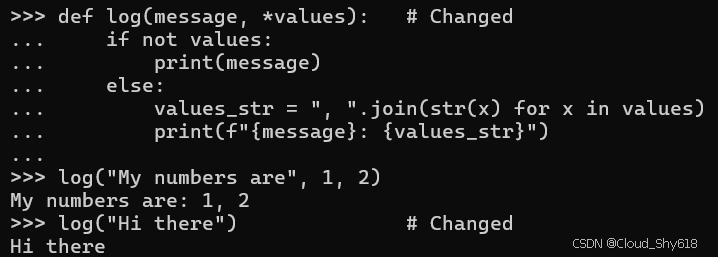
此语法的工作方式与解包赋值语句中使用的带星号的表达式非常相似(有关更多示例,请参阅 Item 16:"与切片相比,首选 Catch-All 解包"和 Item 9:"考虑流程控制中的 match 来解构;避免使用 if 语句足够了")。
如果我已经有一个序列(如列表)并且我想调用可变参数函数(如 log),我可以使用 * 运算符来完成此操作。 这指示 Python 将序列中的项目作为位置参数传递给函数:
favorites = [7, 33, 99]
log("Favorite colors", *favorites)
>>>
Favorite colors: 7, 33, 99
接受可变数量的位置参数存在两个问题。
第一个问题是这些可选位置参数在传递给函数之前始终会转换为元组。 这意味着,如果函数的调用者在生成器上使用 * 运算符,它将被迭代直到耗尽(有关信息,请参阅 Item 43:"考虑生成器而不是返回列表")。生成的元组包含生成器中的每个值,这可能会消耗大量内存并导致程序崩溃:
def my_generator():
for i in range(10):
yield i
def my_func(*args):
print(args)
it = my_generator()
my_func(*it)
>>>
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)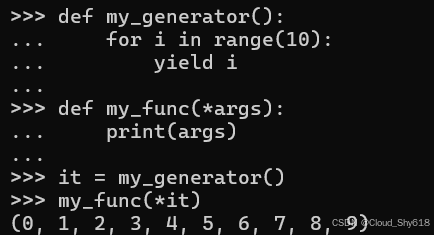
接受 *args 的函数最适合于在知道参数列表中的输入数量相当小的情况下。 *argsi 非常适合一起传递许多文字或变量名称的函数调用。这主要是为了方便调用函数的程序员以及调用代码的可读性。
*arg 的第二个问题是,如果不迁移每个调用者,将来就无法向函数添加新的位置参数。如果您尝试在参数列表的前面添加位置参数,现有的调用者如果不更新,就会巧妙地中断。例如,在这里我添加序列作为函数的第一个参数,并使用它来呈现日志消息:
def log_seq(sequence, message, *values):
if not values:
print(f"{sequence} - {message}")
else:
values_str = ", ".join(str(x) for x in values)
print(f"{sequence} - {message}: {values_str}")
log_seq(1, "Favorites", 7, 33) # New with *args OK
log_seq(1, "Hi there") # New message only OK
log_seq("Favorite numbers", 7, 33) # Old usage breaks
>>>
1 - Favorites: 7, 33
1 - Hi there
Favorite numbers - 7: 33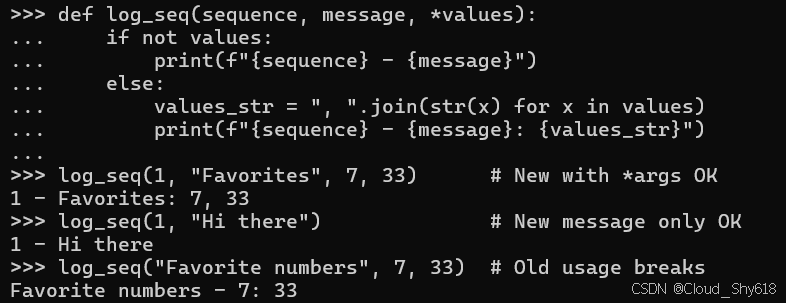
上面代码的问题是第三次调用 log 使用 7 作为消息参数,因为没有提供序列参数。像这样的错误很难追踪,因为代码仍然可以运行而不会引发任何异常。为了完全避免这种可能性,当您想要扩展接受 *args 的函数时,您应该使用仅关键字参数(请参阅 Item 37 条:"使用仅关键字和仅位置参数来增强清晰度")。为了更具防御性,您还可以考虑使用类型注释(请参阅 Item 124:"考虑通过键入进行静态分析以消除错误")。
注意:
- 你可以通过在 def 语句中使用 *args 让函数接受可变数量的位置参数。
- 你可以使用序列中的项目作为带有 * 运算符的函数的位置参数。
- 将 * 运算符与生成器一起使用可能会导致程序内存不足并崩溃。
- 向接受 *args 的函数添加新的位置参数会引入难以检测的错误。
Item 35:使用关键字参数提供可选行为
与大多数其他编程语言一样,在 Python 中,您可以在调用函数时按位置传递参数:
def remainder(number, divisor):
return number % divisor
assert remainder(20, 7) == 6Python 函数的所有普通参数也可以通过关键字传递,其中参数名称用于函数调用括号内的赋值。只要指定了所有必需的位置参数,就可以按任何顺序传递关键字参数。您可以混合和匹配关键字和位置参数。这些调用是等效的:
remainder(20, 7)
remainder(20, divisor=7)
remainder(number=20, divisor=7)
remainder(divisor=7, number=20)位置参数必须在关键字参数之前指定:
remainder(number=20, 7)
>>>
Traceback ...
SyntaxError: positional argument follows keyword argument
每个参数只能指定一次:
remainder(20, number=7)
>>>
Traceback ...
TypeError: remainder() got multiple values for argument 'number'
如果您已经有一个字典对象,并且想要使用其内容来调用 remainder 之类的函数,则可以使用 ** 运算符来完成此操作。这指示 Python 将字典中的键值对作为函数的相应关键字参数传递:
my_kwargs = {
"number": 20,
"divisor": 7,
}
assert remainder(**my_kwargs) == 6只要不重复参数,您就可以在函数调用中将 ** 运算符与位置参数或关键字参数混合使用:
my_kwargs = {
"divisor": 7,
}
assert remainder(number=20, **my_kwargs) == 6如果您知道字典不包含重叠键,您还可以多次使用 ** 运算符:
my_kwargs = {
"number": 20,
}
other_kwargs = {
"divisor": 7,
}
assert remainder(**my_kwargs, **other_kwargs) == 6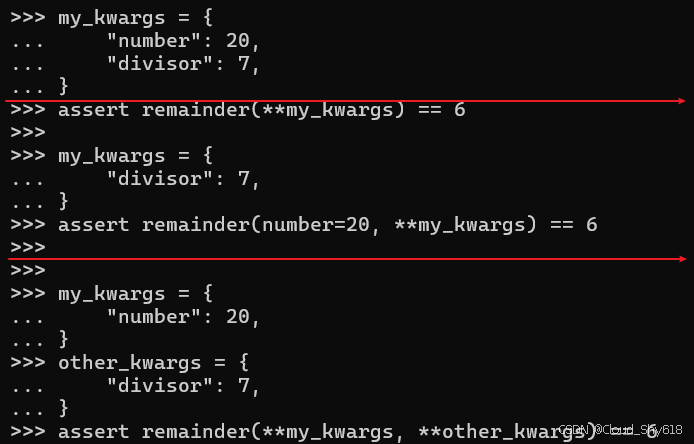
如果您希望函数接收任何命名关键字参数,您可以使用 **kwargs catch-all 参数将这些参数收集到一个字典中,然后您可以对其进行处理(请参阅 Item 38:"使用 functools.wraps 定义函数装饰器" ):
def print_parameters(**kwargs):
for key, value in kwargs.items():
print(f"{key} = {value}")
print_parameters(alpha=1.5, beta=9, gamma=4)
>>>
alpha = 1.5
beta = 9
gamma = 4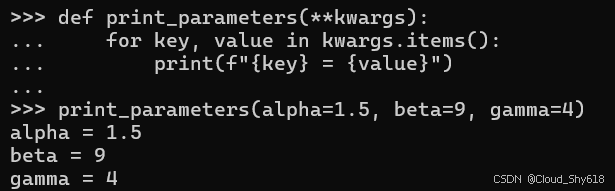
关键字参数的灵活性提供了三个明显的好处。
第一个好处是关键字参数使函数调用对于代码的新读者来说更加清晰。调用 remainder(20, 7),除非您查看 remainder 方法的实现,否则不清楚哪个参数是数字,哪个参数是除数。在使用关键字参数的调用中,number=20 和 divisor=7 可以立即明显看出哪个参数用于哪个目的。
关键字参数的第二个好处是它们可以在函数定义中指定默认值。这允许函数在您需要时提供附加功能,但大多数时候您可以接受默认行为。这消除了重复的代码并减少了噪音。例如,假设我想计算流体流入大桶的速率。如果大桶也用秤来测量其重量,那么我可以使用两个不同时间的两次重量测量之间的差异来确定流量:
def flow_rate(weight_diff, time_diff):
return weight_diff / time_diff
weight_a = 2.5
weight_b = 3
time_a = 1
time_b = 4
weight_diff = weight_b - weight_a
time_diff = time_b - time_a
flow = flow_rate(weight_diff, time_diff)
print(f"{flow:.3} kg per second")
>>>
0.167 kg per second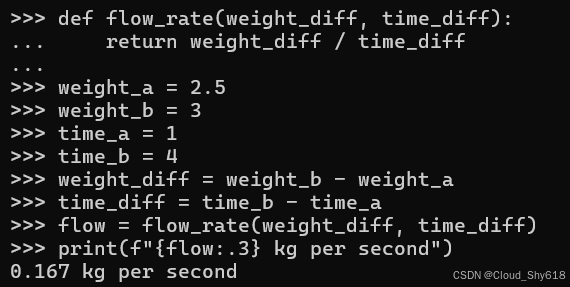
在典型情况下,了解以千克每秒为单位的流速很有用。其他时候,使用最后的传感器测量值来近似更大的时间尺度(例如小时或天)会很有帮助。 可以通过添加时间段缩放因子的参数在同一函数中提供此行为:
def flow_rate(weight_diff, time_diff, period):
return (weight_diff / time_diff) * period问题是,现在我每次调用函数时都需要指定周期参数,即使是在每秒流量的常见情况下(周期为 1):
flow_per_second = flow_rate(weight_diff, time_diff, 1)为了减少噪音,我可以给 period 参数一个默认值:
def flow_rate(weight_diff, time_diff, period=1): # Changed
return (weight_diff / time_diff) * periodperiod 参数现在是可选的:
flow_per_second = flow_rate(weight_diff, time_diff)
flow_per_hour = flow_rate(weight_diff, time_diff, period=3600)这对于不可变的简单默认值非常有效;对于复杂的默认值(例如列表实例和用户定义的对象),它会变得很棘手(有关详细信息,请参阅 Item 36:"使用 None 和 Docstrings 指定动态默认参数")。
使用关键字参数的第三个原因是它们提供了一种强大的方法来扩展函数的参数,同时保持与现有调用者的向后兼容。 这意味着您可以提供额外的功能,而无需迁移大量现有代码,从而减少了引入错误的机会。
例如,假设我想扩展上面的 flow_rate 函数来计算除公斤之外的重量单位的流量。我可以通过添加一个新的可选参数来实现此目的,该参数提供替代测量单位的转换率:
def flow_rate(weight_diff, time_diff,
period=1, units_per_kg=1):
return ((weight_diff *units_per_kg) /time_diff) * periodunits_per_kg 的默认参数值为 1,这使得返回的重量单位仍为千克。这意味着所有现有调用者的行为不会发生变化。flow_rate 的新调用者可以指定新的关键字参数来查看新的行为:
pounds_per_hour = flow_rate(
weight_diff,
time_diff,
period=3600,
units_per_kg=2.2,
)使用像这样的可选关键字参数提供向后兼容性对于接受 *args 的函数也至关重要(请参阅 Item 34:"使用可变位置参数减少视觉噪音")。这种方法的唯一问题是可选的关键字参数(如 period 和 units_per_kg)仍然可以指定为位置参数:
pounds_per_hour = flow_rate(weight_diff, time_diff, 3600, 2.2)根据位置提供可选参数可能会令人困惑,因为不清楚值 3600 和 2.2 对应什么。最佳实践是始终使用关键字名称指定可选参数,并且永远不要将它们作为位置参数传递。作为函数作者,您还可以要求所有调用者使用这种更明确的关键字样式,以最大程度地减少潜在错误(请参阅 Item 37:"通过仅关键字和仅位置参数增强清晰度")。
注意:
- 函数参数可以通过位置或关键字指定。
- 当仅与位置参数混淆时,关键字可以清楚地表明每个参数的目的是什么。
- 具有默认值的关键字参数可以轻松地向函数添加新行为,而无需迁移所有现有调用方。
- 可选关键字参数应始终按关键字而不是按位置传递。