Memcached支持两种不同方式的客户端路由算法,即:求余数Hash算法和一致性Hash算法。下面分别进行介绍。
一、 求余数的路由算法
求余数Hash算法的客户端路由是对插入数据的键进行求余数,根据余数来决定存储到哪个Memcached实例。
| 视频讲解如下 |
|---|
| 【赵渝强老师】Memcached基于求余数的路由算法 |
例如:Memcached服务器端有三台MemCached实例。那么客户端进行路由时会根据键值对3进行求余数的操作。下面的示例中的键分别为:7、6、5.
powershell
7%3=1,那么数据值路由到第2台Memcached实例。
6%3=0,那么数据值路由到第1台Memcached实例。
5%3=2,那么数据值路由到第3台Memcached实例。提示:求余数Hash算法的客户端路由的优点在于,能够使数据均匀地分布在每个Memcached实例上。但是它也存在很大的缺点,就是当进行扩容缩容操作时,或者某个Memcached实例出现宕机的情况。该算法会出现严重的数据丢失。
下面通过一个简单的示例来说明求余数Hash算法的数据是如何丢失的。
powershell
扩容前有3个Memcached实例:7%3=1,6%3=0,5%3=2,......
扩容后有4个Memcached实例:7%4=3,6%4=2,5%4=1,......当有3个Memcached实例时,7号键存储在第2台Memcached实例上,而扩容后变成了存储在4台Memcached实例上,其他的键以此类推。这就导致了存取的目标位置不一样,从而造成数据的丢失。

二、 一致性Hash算法
为了解决求余数Hash算法的数据丢失问题,Memcached又提出了一致性Hash算法的客户端路由。通过使用该算法能够将丢失的数据减小到最小,但不能完全解决宕机造成的数据丢失的问题。
| 视频讲解如下 |
|---|
| 【赵渝强老师】Memcached基于一致性Hash的路由算法 |
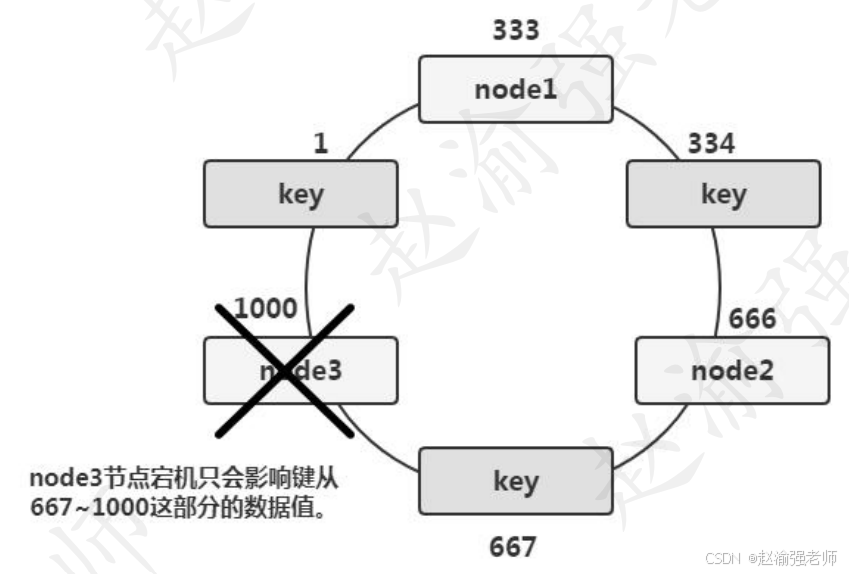
下图展示了一致性Hash算法基本原理。
在初始的状态下有三个Memcached服务器实例,分别是:node1、node2和node3。其中:node1将保存键从1333之间的数据值;node2将保存键从333666之间的数据值;node3将保存键从667~1000之间的数据值。
| 一致性Hash路由算法的扩容和缩容视频讲解如下 |
|---|
| 【赵渝强老师】Memcached一致性Hash路由算法的扩容和缩容 |
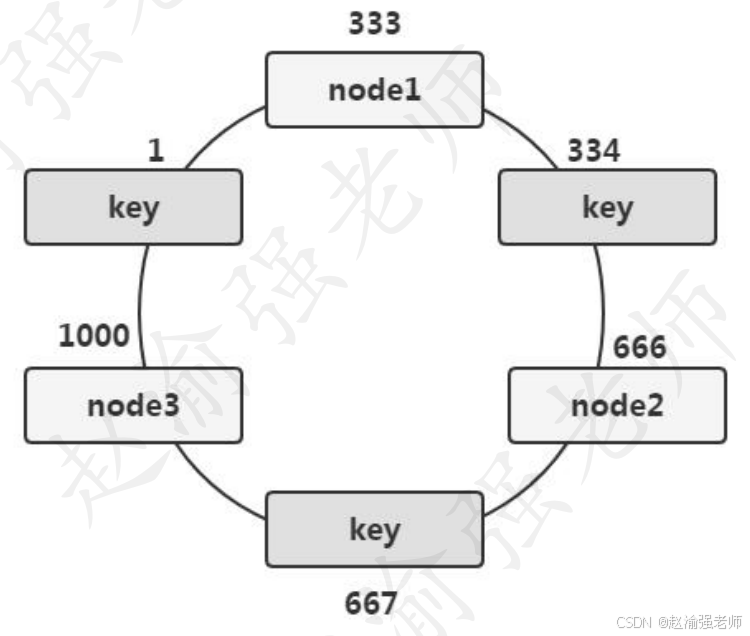
下图进一步说明当Memcached集群发生扩容时数据存储位置的变化。
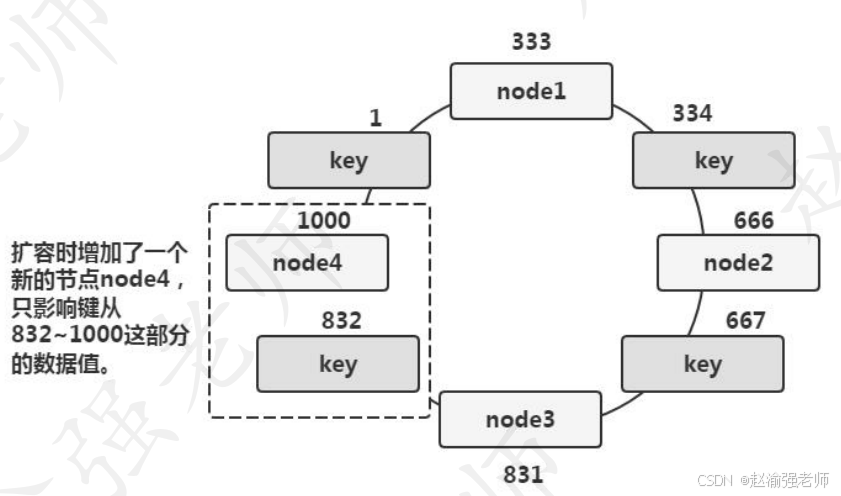
当Memcached集群发生故障出现宕机时,一致性Hash算法能够将丢失的数据减小到最小。如下图所示。当node3节点出现故障而宕机时,只会影响键从667~1000这部分的数据值。而存储在node1和node2上的数据将不会有任何的变化。换句话说,node3的宕机只影响了三分之一的数据。