在当今数字化时代,人工智能技术在教育领域的应用越来越广泛。特别是在题目解答方面,如何提高解答的准确率成为了研究的重点。RAG(Retrieval-Augmented Generation,检索增强生成)技术作为一种新兴的解决方案,正在改变我们对AI辅助学习的认知。本文将深入探讨RAG技术的原理、实操步骤以及如何通过RAG技术提升题目解答的准确率。
一、RAG技术的原理
RAG技术的核心在于结合检索(Retrieval)和生成(Generation)两个步骤,通过检索相关文档来增强生成模型的上下文信息,从而提高生成内容的准确性和相关性。
1.1 传统RAG
传统RAG技术分为两个主要环节:数据导入和用户检索提问。以下是详细的流程:
数据导入:
- 第0步:数据切片:将原始数据(如文档、图片等)进行切片,以便后续处理。
- 第1步:向量化:将切片后的数据通过向量大模型(Embedding Model)转换成向量。
- 第2步:存储到向量数据库:将向量存储到向量数据库中,以便后续检索。
用户检索提问:
- 检索:用户提出问题后,系统通过向量数据库检索与问题最相关的文档片段。
- 生成:将检索到的文档片段作为上下文信息输入到生成模型中,生成最终的回答。
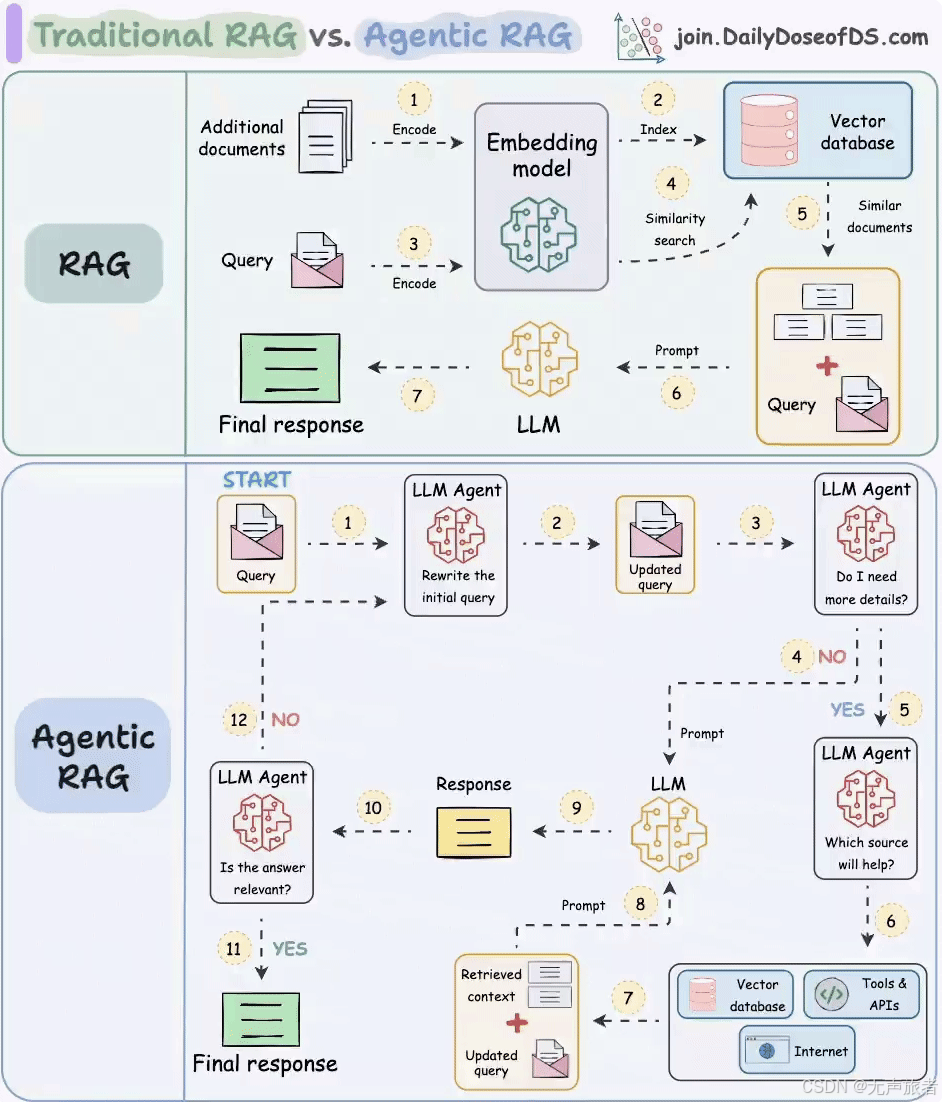
1.2 Agentic RAG
Agentic RAG是RAG技术的一种改进版本,通过引入Agent来解决传统RAG中存在的问题。Agent可以动态地调整检索策略,提高回答问题的准确率。以下是Agentic RAG的主要特点:
- 动态调整:Agent可以根据问题的复杂度和上下文信息,动态调整检索策略。
- 多轮交互:Agent可以与用户进行多轮交互,逐步完善问题的上下文信息。
- 智能决策:Agent可以根据检索结果的置信度,决定是否需要进一步检索或直接生成回答。
二、RAG技术的实操阶段
2.1 使用半开源产品进行部署
在实际应用中,我们可以使用一些半开源的产品来部署RAG系统。这些产品通常提供了完整的工具链,包括模型训练、数据清洗、向量存储等功能。
2.2 数据清洗与向量搜索
数据清洗是RAG技术中的关键步骤之一。通过清洗数据,可以提高向量搜索的命中率。以下是数据清洗的步骤:
- 去除噪声:去除数据中的噪声信息,如无关的符号、重复的内容等。
- 文本标准化:将文本转换为统一的格式,如小写化、去除停用词等。
- 切片处理:将长文本切分成多个小片段,以便更好地进行向量化处理。
2.3 利用DeepSeek-R1进行数据清洗
DeepSeek-R1是一种强大的AI模型,可以用于数据清洗。通过DeepSeek-R1,我们可以自动识别和处理数据中的噪声,提高数据的质量。
三、创建知识库助手应用
3.1 设置问答所使用的大语言模型
在创建知识库助手应用时,需要选择合适的大语言模型。不同的模型在处理不同类型的问题时表现不同,因此需要根据具体需求进行选择。
3.2 管理知识库
知识库是RAG技术的核心组成部分。通过管理知识库,可以确保数据的准确性和相关性。以下是管理知识库的步骤:
- 文档入库:将清洗后的数据存储到知识库中。
- 数据更新:定期更新知识库中的数据,确保其时效性。
- 检索优化:根据实际应用场景,优化检索策略,提高检索效率。
四、实际应用场景
4.1 根据数据量和业务需求选择检索方式
在实际应用中,需要根据数据量和业务需求选择合适的检索方式。例如,对于小规模数据,可以使用简单的向量搜索;对于大规模数据,可以使用更复杂的检索算法,如HNSW等。
4.2 RAG过程的成功案例
在成功应用RAG技术的案例中,大模型不仅能够准确回答问题,还具备举一反三的能力。例如,通过一个例题的解答,模型可以推导出新的题目并给出正确答案。
五、总结与展望
RAG技术通过结合检索和生成两个步骤,显著提高了题目解答的准确率。通过数据清洗、向量存储和智能检索,RAG技术能够为用户提供高质量的答案。在未来,随着AI技术的不断发展,RAG技术将变得更加智能和高效。
往期内容
掌握工具开发套路:用Dify和FastAPI打造高效AI应用
利用人工智能优化求职流程:开发一个智能求职助手
API文档教程