排序的一些相关概念
稳定性
假设在待排序序列中,存在两个元素A和B,A和B的值相同。在排序后,A和B的相对位置没有变化,就说这排序是稳定的。反之不稳定。
内部排序与外部排序
内部排序:数据完全存储在内存中,排序过程无需访问外部存储设备(如硬盘),直接在内存中完成。
外部排序:数据量过大,无法一次性装入内存,需借助外部存储设备(如硬盘、U 盘),通过内存与外存的多次数据交换完成排序。
一些重要的排序算法
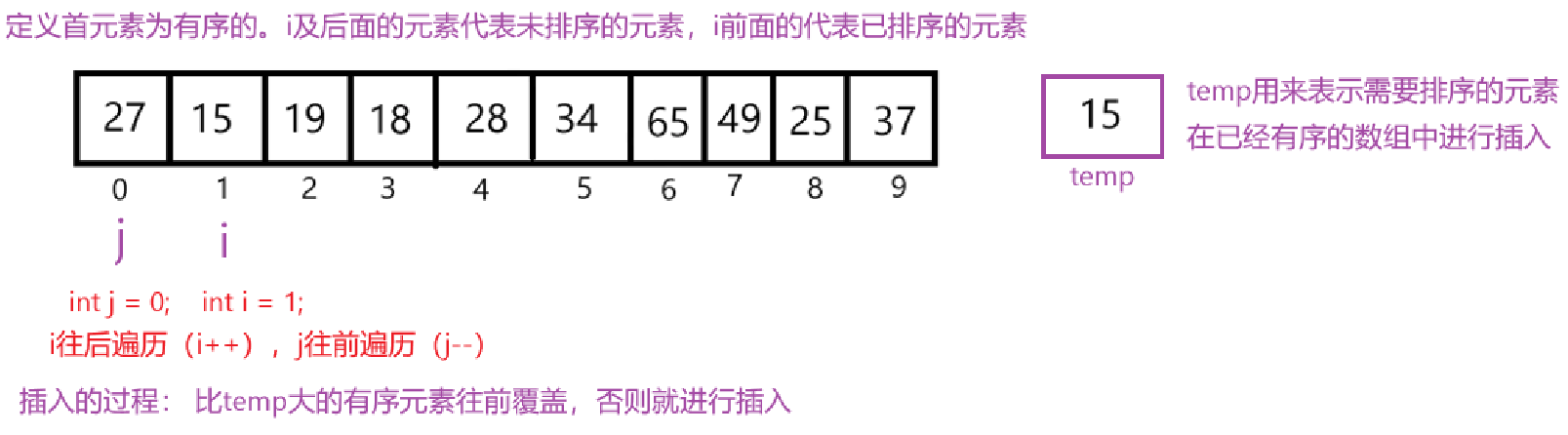
直接插入排序
网上找的动画演示可看一下,深刻理解直接插入的过程。
文字描述如下:
代码展示:
java
/**
* 时间复杂度为:O(N^2)
* 进行优化后,当数组本身有序,时间复杂度最好为:O(N)
* 空间复杂度为:O(1)
* 稳定性:稳定
* @param array
*/
public void directInsertionSort(int[] array) {
for (int i = 1; i < array.length; i++) {
int temp = array[i];
int j = i - 1;
//将比temp大的元素往后移
while (j >=0 && array[j] > temp) {
array[j + 1] = array[j];
j--;
}
//此时j下标的值比temp小,插入到其前面
array[j + 1] = temp;
}
}代码分析:
上述代码的时间复杂度为:O(N^2);空间复杂度为:O(1);稳定性:稳定 。
当已是正序的情况下,代码不会进入内循环,此时时间复杂度为:O(N)。
所以说:元素集合越接近有序,直接插入法的时间效率就高。
希尔排序
希尔排序在直接插入排序的基础上,对数组进行了分块排序。先让数组元素尽可能地接近有序状态,最终使整个数组完全有序。
代码展示:
java
/**希尔排序
*时间复杂度为:
* 根据实际来确定的,一般认为在 O(N*1.3) ~ O(N*1.5)
* 空间复杂度:O(1)
* 稳定性:不稳定
* @param array
*/
public void shellSort(int[] array) {
int gap = array.length;
while (gap > 1) {
gap = gap / 2;//每次缩小分组,让数组逐渐有序
shell(array,gap);
}
}
private void shell(int[] array,int gap) {
//直接插入排序
for (int i = gap; i < array.length; i++) {//这里i++,使得组与组之间交替进行插入排序
//由于是组内的直接插入排序,所以元素与元素直接差值是gap,而不是1了。
int temp = array[i];
int j = i - gap;
//将比temp大的元素往后移
while (j >= 0 && array[j] > temp) {
array[j + gap] = array[j];
j = j - gap;
}
array[j + gap] = temp;
}
}代码分析:
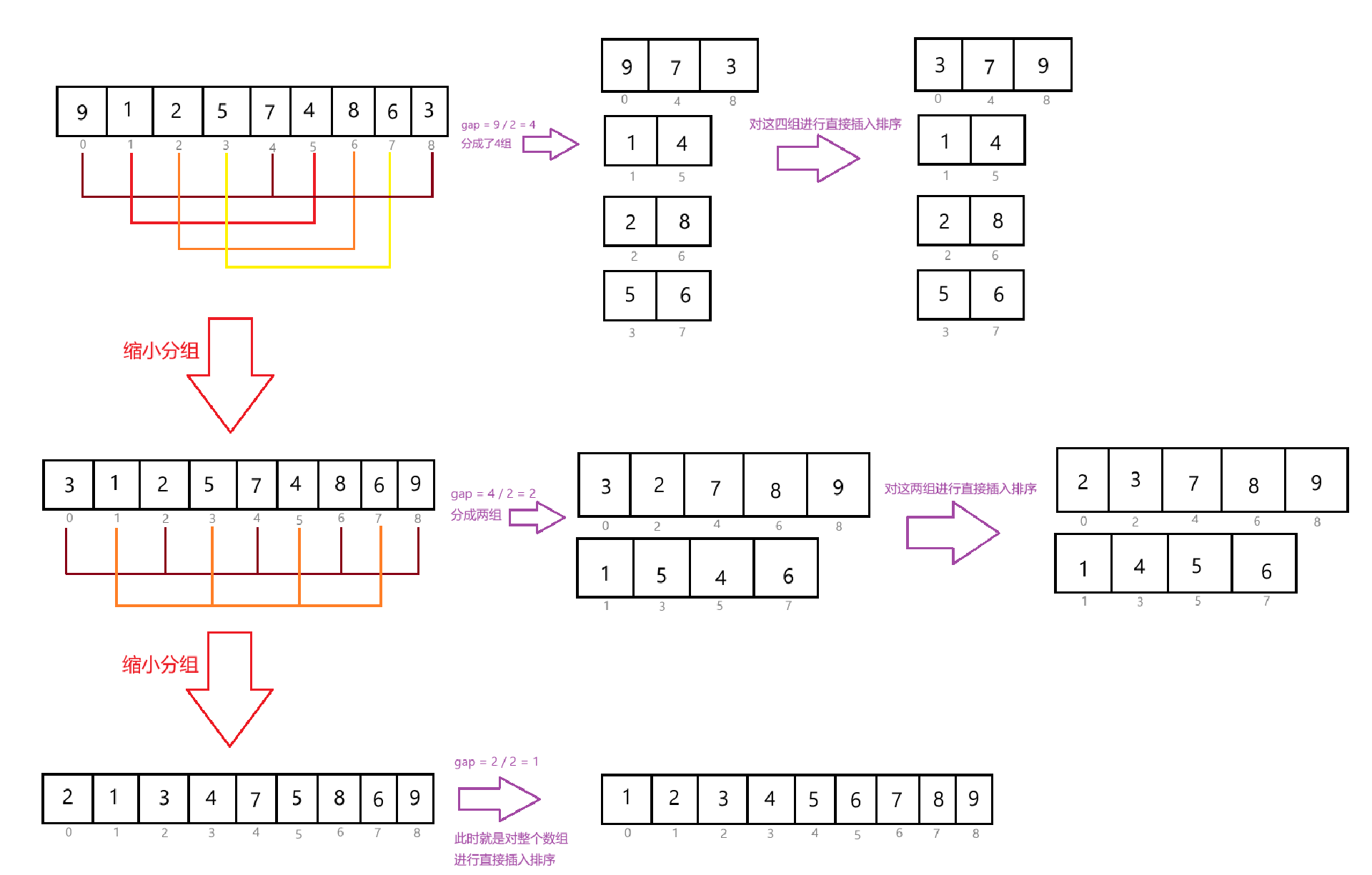
这里相比于直接用直接插入排序,这里将数组逐渐有序起来,直接插入时间复杂度更低。其次,采用交叉分组的方式,将大的元素能放在数组后面,小的元素放在数组前面。
上述代码的时间复杂度为:不同情况不同结果;空间复杂度为:O(1);稳定性:不稳定。最坏时间复杂度为:O(N^2),平均情况下约为:O(N*1.3)
选择排序
将数据分为已排序的和未排序的。在未排序中找到最小(大)值的下标,然后和未排序的第一个进行交换,这样就能保证是有序的。
代码展示:
java
/**
* 时间复杂度为:O(N^2)
* 空间复杂度为:O(1)
* 稳定性:不稳定
* @param array
*/
public void selectionSort(int[] array) {
for (int i = 0; i < array.length; i++) {
int minIndex = i;//minIndex初始为未排序的起始下标i
for (int j = i + 1; j < array.length; j++) {//从i + 1这个下标开始找最小值下标
if(array[minIndex] > array[j]) {
minIndex = j;//找到未排序中最小值的下标
}
}
//交换未排序的第一个与最小值
swap(array, minIndex, i);
}
}
private void swap(int[] array, int a ,int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}代码分析:
上述代码的时间复杂度为:O(N^2);空间复杂度为:O(1);稳定性:不稳定
堆排序
在堆的学习中有学习过
数据结构*堆
代码展示:
java
/**
* 从小到大排序
* 时间复杂度为:O(N*logN)
* 空间复杂度为:O(1)
* 稳定性:不稳定
* @param array
*/
public void heapSort(int[] array) {
//先创建一个最大堆,时间复杂度为:O(N)
for (int parent = ((array.length - 1) - 1) / 2; parent >= 0 ; parent--) {
shiftDown(array,parent,array.length);
}
int end = array.length - 1;
//进行排序,时间复杂度为:O(N*logN) <---- 有N次调整,每次调整的时间复杂度为:O(logN)
while (end > 0) {
swap(array,0,end);
end--;
shiftDown(array,0,end + 1);
}
}
private void swap(int[] array,int a,int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}
private void shiftDown(int[] array ,int parent,int useSize) {
int child = 2 * parent + 1;
while (child < useSize) {
if(child + 1 <useSize && array[child] < array[child + 1]) {
child++;
}
if(array[parent] < array[child]) {
swap(array,parent,child);
parent = child;
child = 2 * parent + 1;
}else {
break;
}
}
}代码分析:
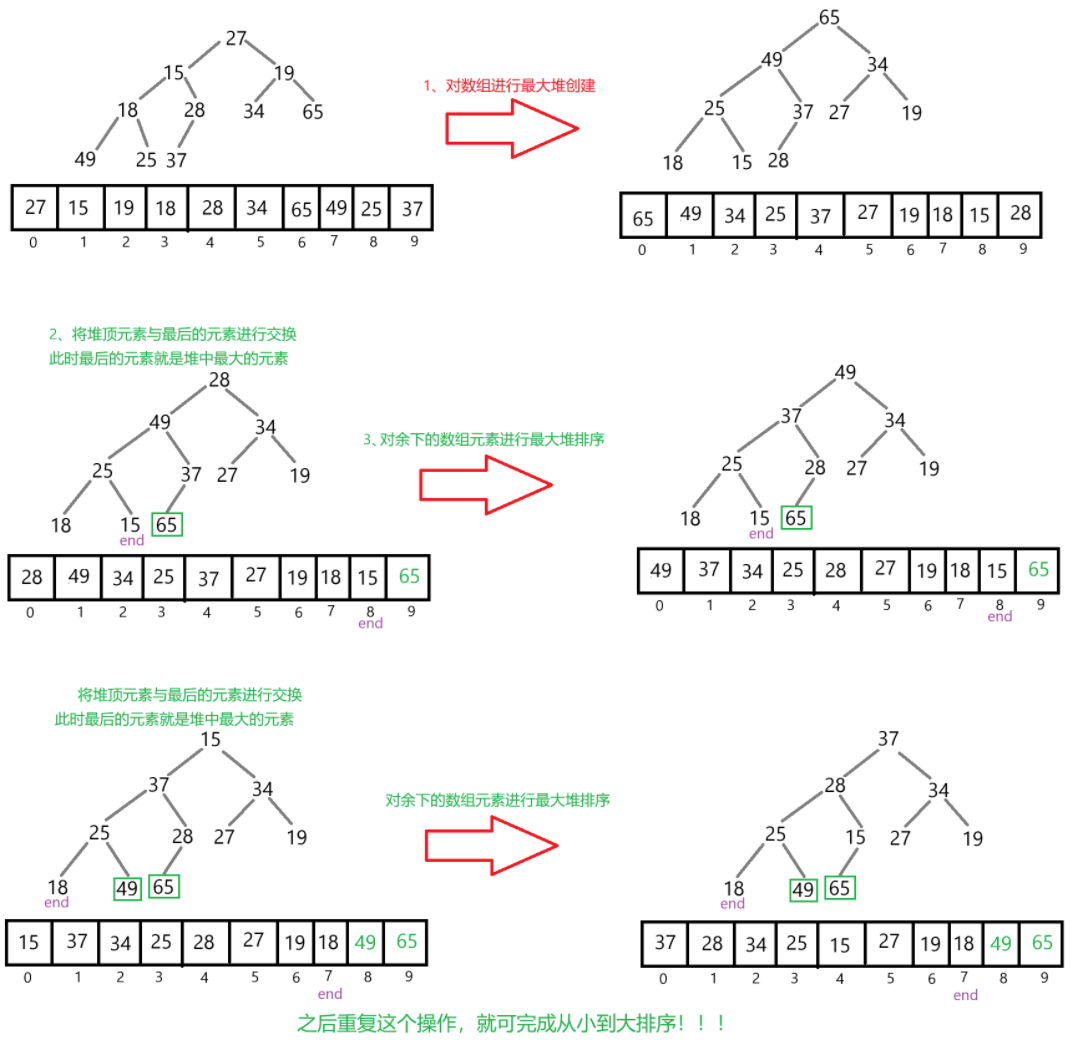
上述代码的时间复杂度为:O(N*logN);空间复杂度为:O(1);稳定性:不稳定
冒泡排序
是将数据两两比较,大的数据往后移(交换)。每趟就将最大的数据放到后面。一共要走N - 1趟。每趟元素从开头进行比较,比较到有序的数据就停止比较。
别人制作的冒泡排序视频
代码展示:
java
/**
* 时间复杂度:O(N^2)
* 进行优化后,当数组本身有序时间复杂度最好为:O(N)
* 空间复杂度:O(1)
* 稳定性:稳定
* @param array
*/
public void BubbleSort(int[] array) {
//一共要走N - 1趟
for (int i = 1; i < array.length; i++) {
boolean flag = false;
//每趟对未有序的数据进行比较交换
for (int j = 0; j < array.length - i; j++) {
if(array[j] > array[j + 1]) {
swap(array,j,j + 1);
flag = true;
}
}
if(!flag) {//说明没有在进行交换了,已经有序了
return;
}
}
}
private void swap(int[] array, int a ,int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}代码分析:
上述代码的时间复杂度为:O(N^2);空间复杂度为:O(1);稳定性:稳定
快速排序
选择一个基准元素,使其左边都是小于基准元素的值,右边都是大于基准元素的值。再进行分区操作,重复这个过程。
代码展示:
java
/**
*时间复杂度为:
* 最好情况下为:O(N*logN),每次找的基准都是中间的值
* 最坏情况下为:O(N^2),正序或逆序(即是一棵单分支的树)
* 空间复杂度:
* 最好情况下为:O(logN),每次找的基准都是中间的值
* 最坏情况下为:O(n),正序或逆序(即是一棵单分支的树)
* 稳定性:不稳定
* @param array
*/
public void quickSort(int[] array) {
quick(array,0,array.length - 1);
}
private void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
int par = standard(array,start,end);//standard()方法用来获得在区间范围内的基准,并使左边小于基准,右边大于基准
quick(array,start,par - 1);
quick(array,par + 1,end);
}对于实现standard()方法有三种方法:
1、挖坑法:
java
private int standardDigging(int[] array,int low,int high) {
int temp = array[low];
while (low < high) {
while (low < high && array[high] >= temp) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= temp) {
low++;
}
array[high] = array[low];
}
array[low] = temp;
return low;
}2、Hoare法:
java
private int standardHoare(int[] array,int low,int high) {
int pivot = array[low];
int i = low;
while (low < high) {
while (low < high && array[high] >= pivot) {
high--;
}
while (low < high && array[low] <= pivot) {
low++;
}
swap(array,low,high);
}
swap(array,i,low);
return low;
}
private void swap(int[] array, int a ,int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}3、前后指针法:
java
private int standardPoint(int[] array,int low,int high) {
int pivot = array[low];
int prev = low;//prev用来标记小于等于基准值
for(int cur = prev + 1;cur <= high;cur++) {//cur用来标记大于基准值
if(array[cur] <= pivot) {
prev++;//扩大小于等于基准值的区域
swap(array,cur,prev);//将小于等于基准值的值放到前面来
}
}
swap(array,low,prev);//将基准值放到最终位置
return prev;//返回基准值索引
}
private void swap(int[] array, int a ,int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}代码分析:
下图主要展示了排序的总逻辑:(类似二叉树的形式)
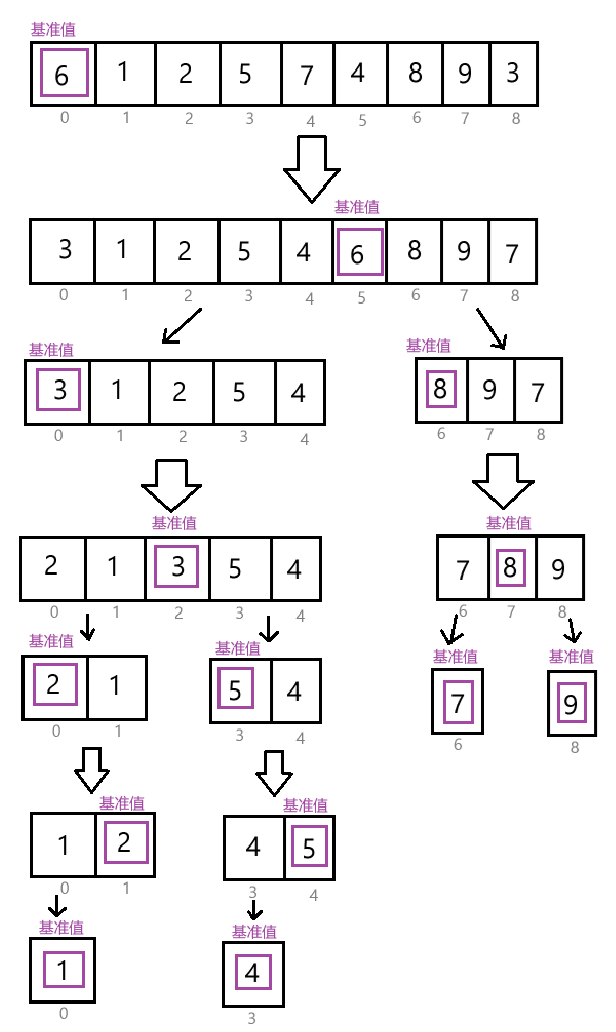
具体的实现"左边都是小于基准元素的,右边都是大于基准元素",可以用挖坑法、Hoare法、前后指针法。(使用频率:挖坑法 > Hoare法 > 前后指针法)
上述代码的时间复杂度为:1、最好情况下为:O(N*logN) 2、最坏情况下为:O(N^2);空间复杂度:1、最好情况下为:O(logN) 2、最坏情况下为:O(n);稳定性:不稳定 。
注意:
在找基准的方法中:
1、挖坑法代码中的while循环的条件那里需要有等号
java
while (low < high) {
while (low < high && array[high] > temp) {少了等号
high--;
}
array[low] = array[high];
while (low < high && array[low] < temp) {//少了等号
low++;
}
array[high] = array[low];
}当原数组首元素和尾元素相等,就会导致一直交换这两个相同的元素,死循环。
2、在Hoare法代码中调整数组的while循环中要先high找小于基准值的值。
java
while (low < high) {
while (low < high && array[low] <= pivot) {
low++;
}//错误
while (low < high && array[high] >= pivot) {
high--;
}
swap(array,low,high);
}由于我们一开始是定义首元素为基准值,如果low先动的话,最后low和high相遇的值要比基准值大,导致并没有实现左边都是小于基准元素的值,右边都是大于基准元素的值。
代码优化:
1、三数取中
在最坏情况下(正序、逆序等),当我们取区间首元素为基准值时,这样分割不均匀。这时候我们可以在区间首元素、尾元素、中间元素中找到中间大的数字。
java
private void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
//三数取中
int standard = medianOfNumbers(array,start,end);
swap(array,start,standard);//找到了中间值,将它和原来定的标准值交换(标准值还在首下标)
int par = standardDigging(array,start,end);
quick(array,start,par - 1);
quick(array,par + 1,end);
}
private int medianOfNumbers(int[] array,int low,int high) {
int mid = (low + high) / 2;
//确保array[low] <= array[high]
if(array[low] > array[high]) {
swap(array,low,high);
}
//确保array[low] <= array[mid]
if(array[low] > array[mid]) {
swap(array,low,mid);
}
//到这里说明array[low]是最小的
//确保array[mid] <= array[high]
if(array[mid] > array[high]) {
swap(array,mid,high);
}
//说明array[mid]是中间值,返回mid下标
return mid;
}2、小数组优化
在排序到后面的时候,数组已趋于有序。此时数组被分成了许多小数组,但如果继续递归,效率会相比其他的排序低很多。这时候我们可以考虑使用插入排序来提高效率。
java
private void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
//小数组优化
int VALUE = 10;
if(end - start + 1 == VALUE) {
//直接插入排序
directInsertionSort(array,start,end);
return;
}
//三数取中
int standard = medianOfNumbers(array,start,end);
swap(array,start,standard);
int par = standardDigging(array,start,end);
quick(array,start,par - 1);
quick(array,par + 1,end);
}
public void directInsertionSort(int[] array,int start,int end) {
for (int i = start + 1; i <= end; i++) {
int temp = array[i];
int j = i - 1;
//将比temp大的元素往后移
while (j >= 0 && array[j] > temp) {
array[j + 1] = array[j];
j--;
}
}
}非递归实现快速排序
代码展示:
java
private void quickNor(int[] array,int start,int end) {
int par = standardDigging(array,start,end);
// 创建栈用于保存待排序子数组的左右边界
Stack<Integer> stack = new Stack<>();
//当分成的数组长度为1,1个元素本身就是有序的,无需继续分
if(start < par - 1) {//分的数组长度大于等于二
stack.push(start);
stack.push(par - 1);
}
if(end > par + 1) {//分的数组长度大于等于二
stack.push(par + 1);
stack.push(end);
}
while (!stack.empty()) {
end = stack.pop();//一开始弹出来的是后进去的end
start = stack.pop();
//接下来就是重复上面的过程,直至栈为空,说明没有子数组需要排序了
par = standardDigging(array,start,end);
if(start < par - 1) {
stack.push(start);
stack.push(par - 1);
}
if(end > par + 1) {
stack.push(par + 1);
stack.push(end);
}
}
}代码分析:
1、初始划分:
选择基准值,将数组分为【左半部分 ≤ 基准值】和【右半部分 ≥ 基准值】,获取基准值位置par。
2、栈管理子数组:
用栈保存待排序子数组的左右边界(start和end)。
先处理初始划分后的左右子数组(若长度≥2),将其边界压入栈。
3、迭代处理栈元素:
循环弹出栈顶子数组,对其进行划分,得到新基准值位置。
将新产生的左右子数组边界(若长度≥2)压入栈,确保所有子数组被处理。
4、终止条件:
栈空时,所有子数组排序完成。
归并排序
将数组不断地平分成两个数组,最后合并两个有序数组并排序。一开始合并是两个单元素数组合并。
代码展示:
java
/**归并排序
* 时间复杂度:O(N*logN)
* 空间复杂度:O(N)
* 稳定性:稳定
* @param array
*/
public void mergeSort(int[] array) {
mergeSortChild(array,0,array.length - 1);
}
private void mergeSortChild(int[] array,int left,int right) {
if(left == right) {
return;
}
int mid = (left + right) / 2;
mergeSortChild(array,left,mid);
mergeSortChild(array,mid + 1,right);
//合并两个有序数组
merge(array,left,mid,right);
}
private void merge(int[] array,int left,int mid,int right) {
int s1 = left;
int e1 = mid;
int s2 = mid + 1;
int e2 = right;
int[] temp = new int[right - left + 1];
int index = 0;
while (s1 <= e1 && s2 <= e2) {
if(array[s1] > array[s2]) {
temp[index] = array[s2];
s2++;
}else {
temp[index] = array[s1];
s1++;
}
index++;
}
while (s2 <= e2) {
temp[index] = array[s2];
index++;
s2++;
}
while (s1 <= e1) {
temp[index] = array[s1];
index++;
s1++;
}
//此时temp数组就是排好序的数组
for (int i = 0; i < temp.length; i++) {
array[i + left] = temp[i];
}
}代码分析:
上述代码采用递归的方法,先完成左边数组的归并,在完成右边数组的归并。大致总逻辑如下图所示:
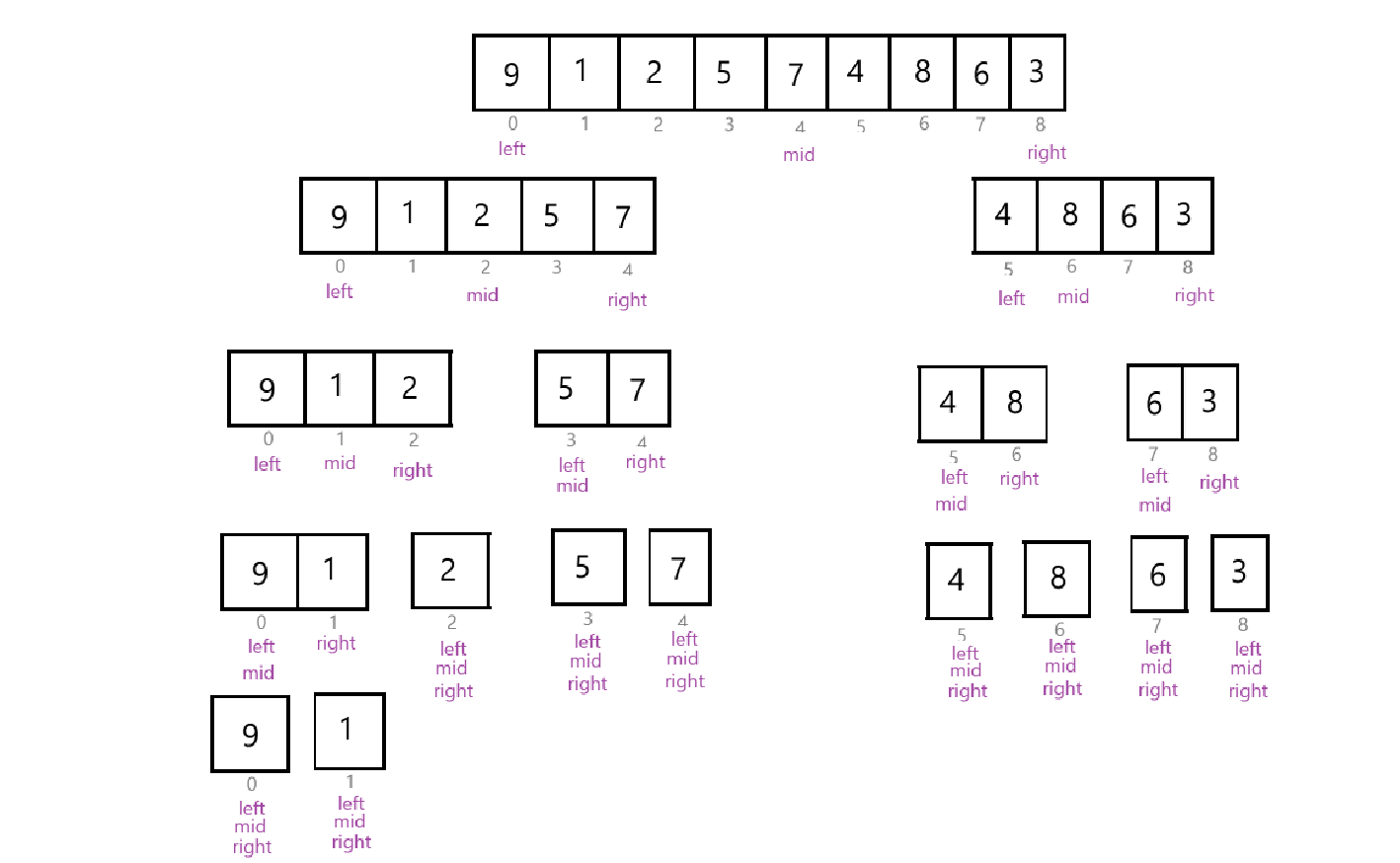
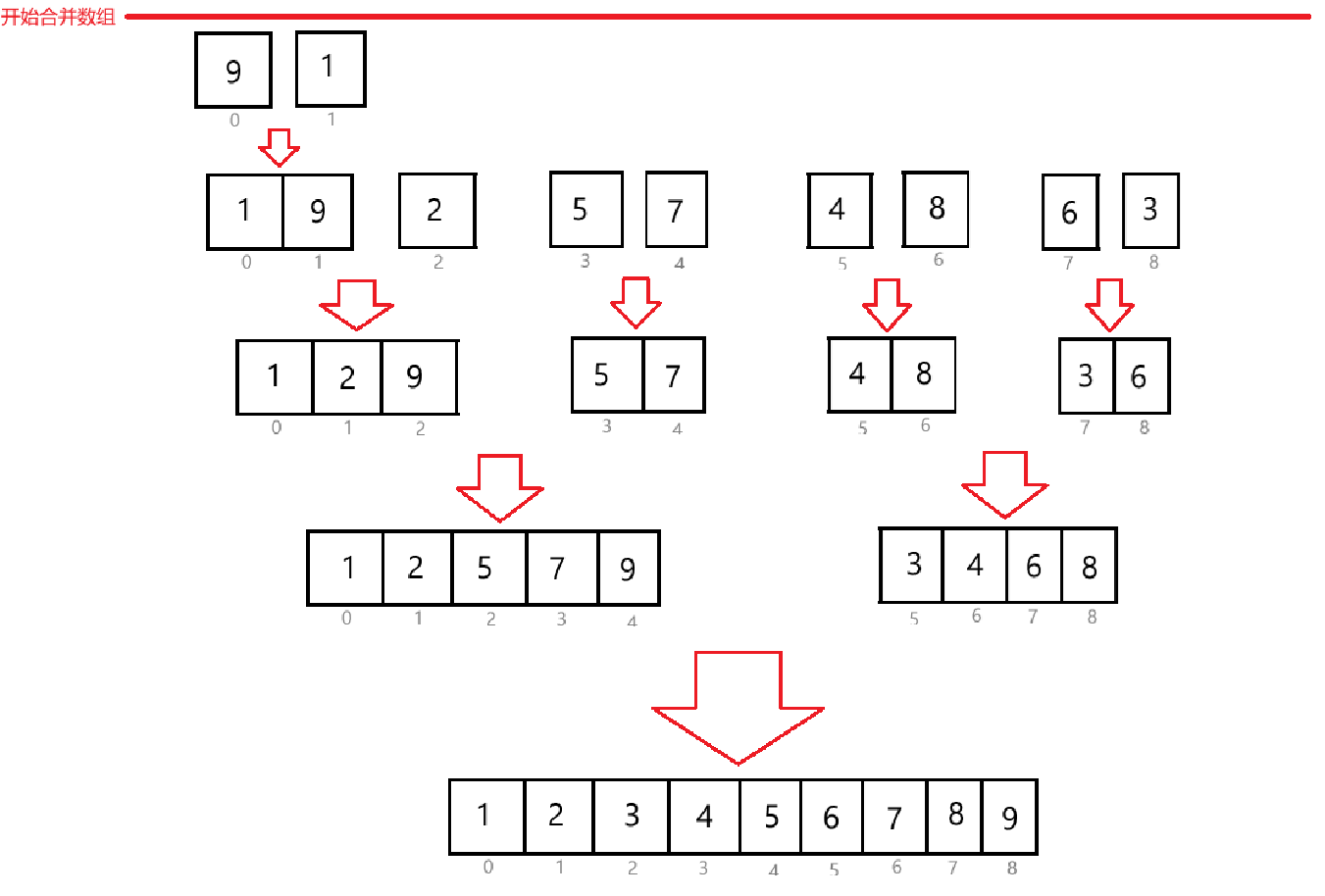
上述代码的时间复杂度为:O(N*logN);空间复杂度为:O(N);稳定性:稳定
非递归实现归并排序
代码展示:
java
public void mergeSortNor(int[] array) {
int gap = 1;
while (gap < array.length) {//当gap >= array.length,说明整个数组都完成了归并
//遍历所有子数组
for (int i = 0; i < array.length; i++) {
int left = i;
int mid = left + gap -1;
//当gap很大的时候,mid下标可能越界
if(mid >= array.length) {
mid = array.length - 1;
}
int right = mid + gap;
//当gap很大的时候,right下标可能越界
if(right >= array.length) {
right = array.length - 1;
}
merge(array,left,mid,right);
}
gap*=2;
}
}代码分析:
gap用来表示要排序的子数组大小,每次扩大子数组的大小。
总结:
| 排序名称 | 时间复杂度(最好) | 时间复杂度(最坏) | 空间复杂度 | 稳定性 | 使用场景 |
|---|---|---|---|---|---|
| 直接插入排序 | O(N) | O(N^2) | O(1) | 稳定 | 数据量较小,数据本身基本有序。 |
| 希尔排序 | O(N) | O(N^2) | O(1) | 不稳定 | 适用于大规模数据排序。如对大型文件中的数据进行初步排序。 |
| 选择排序 | O(N^2) | O(N^2) | O(1) | 不稳定 | 数据量较小且对排序稳定性无要求时可使用。 |
| 堆排序 | O(N*logN) | O(N*logN) | O(1) | 不稳定 | 适合处理大量数据且要求时间复杂度为O(N*logN) 级别的场景。 |
| 冒泡排序 | O(N^2) | O(N^2) | O(1) | 稳定 | 数据量较少,或者数据基本有序的情况。 |
| 快速排序 | O(N*logN) | O(N^2) | O(logN) ~ O(N) | 不稳定 | 大量数据的排序场景,是实践中平均性能最优的排序算法之一。 |
| 归并排序 | O(N*logN) | O(N*logN) | O(N) | 稳定 | 当处理大规模数据且要求排序稳定时使用。 |
每一种排序都有适合场景,甚至可以采用多种排序组合实现最优解。