你是否曾经在半夜被告警电话吵醒,发现是因为MySQL数据库表太大导致查询慢如蜗牛?或者每月手动创建新分区、删除旧分区已经成为你生活的一部分?
如果是,那这篇关于MySQL动态分区管理的文章将是你的"救命稻草"。今天,一起来看看如何让MySQL自动管理分区,让你既能安心睡觉,又能保持数据库的高性能。
什么是MySQL分区?先搞懂基础概念
在深入动态分区前,我们先来理解一下基本的分区概念。
简单来说,MySQL分区就是将一个大表在物理上分成多个小块,但在逻辑上它仍然是一个表。这有点像把一本厚重的百科全书分成多个小册子,每个小册子包含一部分内容,但整体上它们仍然是一本完整的百科全书。
MySQL分区的主要优势包括:
- 查询性能提升:针对分区列的查询可以只扫描相关分区,而不是整个表
- 维护简化:可以独立维护每个分区,比如备份或修复
- 大表管理:能够处理超大表,突破单个文件系统的限制
MySQL支持的分区类型
MySQL提供了几种主要的分区类型:
- RANGE分区:基于列值在连续区间范围内的分区
- LIST分区:基于列值属于预定义值列表的分区
- HASH分区:基于用户定义的表达式的返回值来均匀分布数据
- KEY分区:类似HASH分区,但使用MySQL服务器提供的哈希函数
对于时间序列数据(如日志、订单历史等),最常用的是RANGE分区,特别是按日期范围分区。
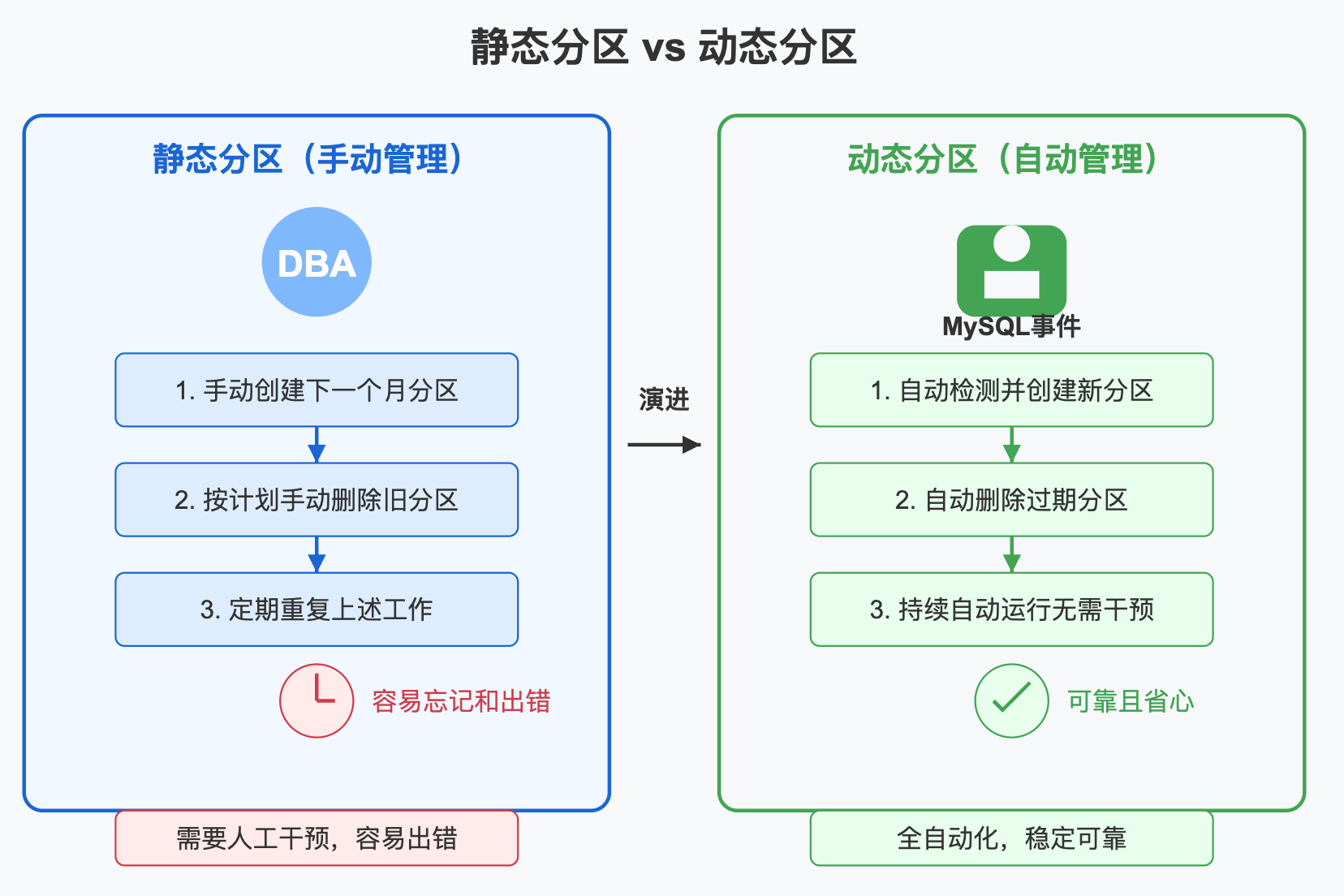
静态分区与动态分区:从"手工作坊"到"智能工厂"
静态分区:传统的手动方式
传统的静态分区需要DBA手动创建和维护分区。比如,对于一个按月分区的订单表,你需要:
- 提前创建下个月的分区
- 定期删除过旧的分区
- 如果忘记创建新分区,新数据将无法插入
这就像一个手工作坊,需要人工完成所有操作,容易出错且耗时耗力。
动态分区:自动化的智能方式
动态分区则是通过MySQL事件调度器自动管理分区,实现:
- 自动创建新分区
- 自动删除旧分区
- 无需人工干预,系统持续稳定运行
这就像升级到了智能工厂,一切都是自动化的,你只需要设定规则并监督运行。
MySQL动态分区实战,从理论到实践
接下来,我们将一步步实现动态分区管理。我们以一个常见的场景为例:一个按月分区的订单表,需要保留最近12个月的数据。
步骤1:创建具有初始分区的表
首先,我们创建一个带有初始分区的订单表:
sql
CREATE TABLE orders (
order_id BIGINT NOT NULL,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
amount DECIMAL(10,2) NOT NULL,
status VARCHAR(20) NOT NULL,
PRIMARY KEY (order_id, order_date)
) ENGINE=InnoDB
PARTITION BY RANGE (TO_DAYS(order_date)) (
PARTITION p202301 VALUES LESS THAN (TO_DAYS('2023-02-01')),
PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01')),
PARTITION p202303 VALUES LESS THAN (TO_DAYS('2023-04-01'))
);这里我们:
- 使用RANGE分区基于订单日期
- 使用TO_DAYS函数将日期转换为天数
- 创建了三个初始分区,分别对应2023年1月、2月和3月
步骤2:创建动态分区管理存储过程
接下来,我们创建两个关键的存储过程:
- 一个用于创建新分区
- 一个用于删除旧分区
java
-- 创建管理分区的存储过程
DELIMITER $$
-- 存储过程:创建新的分区
CREATE PROCEDURE create_next_partition(IN_TABLE VARCHAR(64), IN_SCHEMA VARCHAR(64))
BEGIN
-- 声明变量
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SELECT 'Error occurred while creating partition';
-- 当前日期变量
DECLARE v_current_date DATE DEFAULT CURRENT_DATE();
-- 下个月的第一天
DECLARE v_next_month_start DATE DEFAULT DATE_ADD(DATE_ADD(LAST_DAY(v_current_date), INTERVAL 1 DAY), INTERVAL 1 MONTH);
-- 下下个月的第一天
DECLARE v_next_next_month_start DATE DEFAULT DATE_ADD(LAST_DAY(v_next_month_start), INTERVAL 1 DAY);
-- 分区名
DECLARE v_partition_name VARCHAR(32) DEFAULT CONCAT('p', DATE_FORMAT(v_next_month_start, '%Y%m'));
-- 创建SQL语句
DECLARE v_sql VARCHAR(1000);
-- 检查分区是否已存在
SET @partition_exists = 0;
SET @check_sql = CONCAT('SELECT COUNT(1) INTO @partition_exists
FROM information_schema.partitions
WHERE table_schema = ''', IN_SCHEMA, '''
AND table_name = ''', IN_TABLE, '''
AND partition_name = ''', v_partition_name, '''');
PREPARE stmt FROM @check_sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 如果分区不存在,则创建
IF @partition_exists = 0 THEN
-- 构建ALTER TABLE语句
SET v_sql = CONCAT('ALTER TABLE ', IN_SCHEMA, '.', IN_TABLE,
' ADD PARTITION (PARTITION ', v_partition_name,
' VALUES LESS THAN (TO_DAYS(''',
DATE_FORMAT(v_next_next_month_start, '%Y-%m-%d'), ''')))');
-- 执行SQL
SET @alter_stmt = v_sql;
PREPARE stmt FROM @alter_stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 记录日志
SELECT CONCAT('Created new partition ', v_partition_name,
' for table ', IN_SCHEMA, '.', IN_TABLE) AS log_message;
ELSE
-- 分区已存在,记录日志
SELECT CONCAT('Partition ', v_partition_name, ' already exists for table ',
IN_SCHEMA, '.', IN_TABLE, '. Skipping creation.') AS log_message;
END IF;
END$$
-- 存储过程:删除过期分区
CREATE PROCEDURE drop_old_partition(IN_TABLE VARCHAR(64), IN_SCHEMA VARCHAR(64), IN_MONTHS_TO_KEEP INT)
BEGIN
-- 声明变量
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SELECT 'Error occurred while dropping partition';
-- 当前日期
DECLARE v_current_date DATE DEFAULT CURRENT_DATE();
-- 要保留的最早日期
DECLARE v_earliest_date DATE DEFAULT DATE_SUB(v_current_date, INTERVAL IN_MONTHS_TO_KEEP MONTH);
-- 将日期转为月初
SET v_earliest_date = DATE_FORMAT(v_earliest_date, '%Y-%m-01');
-- 创建游标查询获取所有分区
BLOCK1: BEGIN
DECLARE v_partition_name VARCHAR(32);
DECLARE v_partition_description VARCHAR(256);
DECLARE v_partition_date DATE;
DECLARE v_done INT DEFAULT 0;
-- 声明游标
DECLARE partition_cursor CURSOR FOR
SELECT partition_name, partition_description
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMA
AND table_name = IN_TABLE
AND partition_name IS NOT NULL
ORDER BY partition_name;
-- 声明NOT FOUND处理器
DECLARE CONTINUE HANDLER FOR NOT FOUND SET v_done = 1;
-- 打开游标
OPEN partition_cursor;
read_loop: LOOP
-- 读取下一个分区
FETCH partition_cursor INTO v_partition_name, v_partition_description;
-- 如果没有更多分区,跳出循环
IF v_done THEN
LEAVE read_loop;
END IF;
-- 解析分区描述,获取日期
-- 分区描述形式为:TO_DAYS('YYYY-MM-DD')
SET v_partition_description = TRIM(BOTH '()' FROM v_partition_description);
SET v_partition_description = REPLACE(v_partition_description, 'TO_DAYS', '');
SET v_partition_description = REPLACE(v_partition_description, '''', '');
SET v_partition_description = TRIM(BOTH '()' FROM v_partition_description);
-- 现在描述形式为:YYYY-MM-DD
SET v_partition_date = STR_TO_DATE(v_partition_description, '%Y-%m-%d');
-- 检查是否是过期分区
IF v_partition_date < v_earliest_date THEN
-- 构建删除分区SQL
SET @drop_sql = CONCAT('ALTER TABLE ', IN_SCHEMA, '.', IN_TABLE,
' DROP PARTITION ', v_partition_name);
-- 执行SQL
PREPARE stmt FROM @drop_sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 记录日志
SELECT CONCAT('Dropped old partition ', v_partition_name,
' for table ', IN_SCHEMA, '.', IN_TABLE) AS log_message;
END IF;
END LOOP;
-- 关闭游标
CLOSE partition_cursor;
END BLOCK1;
END$$
-- 创建一个组合存储过程,同时管理创建新分区和删除旧分区
CREATE PROCEDURE manage_partitions(IN_TABLE VARCHAR(64), IN_SCHEMA VARCHAR(64), IN_MONTHS_TO_KEEP INT)
BEGIN
-- 创建新分区
CALL create_next_partition(IN_TABLE, IN_SCHEMA);
-- 删除旧分区
CALL drop_old_partition(IN_TABLE, IN_SCHEMA, IN_MONTHS_TO_KEEP);
END$$
DELIMITER ;上面的存储过程包括三个主要功能:
create_next_partition:检查并创建下个月的分区drop_old_partition:删除超过保留期限的旧分区manage_partitions:组合前两个过程的主过程
步骤3:创建定时事件自动执行分区管理
最后,我们需要创建MySQL事件,定期自动执行分区管理存储过程:
sql
-- 确保事件调度器已启用
SET GLOBAL event_scheduler = ON;
-- 创建每月执行一次的事件
DELIMITER $$
CREATE EVENT event_monthly_partition_maintenance
ON SCHEDULE
EVERY 1 MONTH
STARTS CURRENT_DATE + INTERVAL 1 DAY
DO
BEGIN
-- 管理orders表的分区,保留最近12个月的数据
CALL manage_partitions('orders', 'your_database_name', 12);
-- 如果有其他需要分区管理的表,可以在这里添加
-- CALL manage_partitions('another_table', 'your_database_name', 6);
END$$
DELIMITER ;这个事件设置为每月执行一次,它会:
- 自动创建下个月的分区(如果尚未存在)
- 自动删除12个月前的旧分区
步骤4:监控分区状态
设置好动态分区后,你可以使用以下查询监控分区状态:
sql
-- 查看表的所有分区
SELECT
partition_name,
partition_ordinal_position,
table_rows,
concat(round(data_length / (1024 * 1024), 2), ' MB') as 'data_size',
concat(round(index_length / (1024 * 1024), 2), ' MB') as 'index_size',
partition_description
FROM
information_schema.partitions
WHERE
table_schema = 'your_database_name'
AND table_name = 'orders'
ORDER BY
partition_ordinal_position;动态分区的工作原理,揭秘底层机制
理解动态分区的内部工作原理有助于我们更好地运用这一技术。下面是整个过程的详细分解:
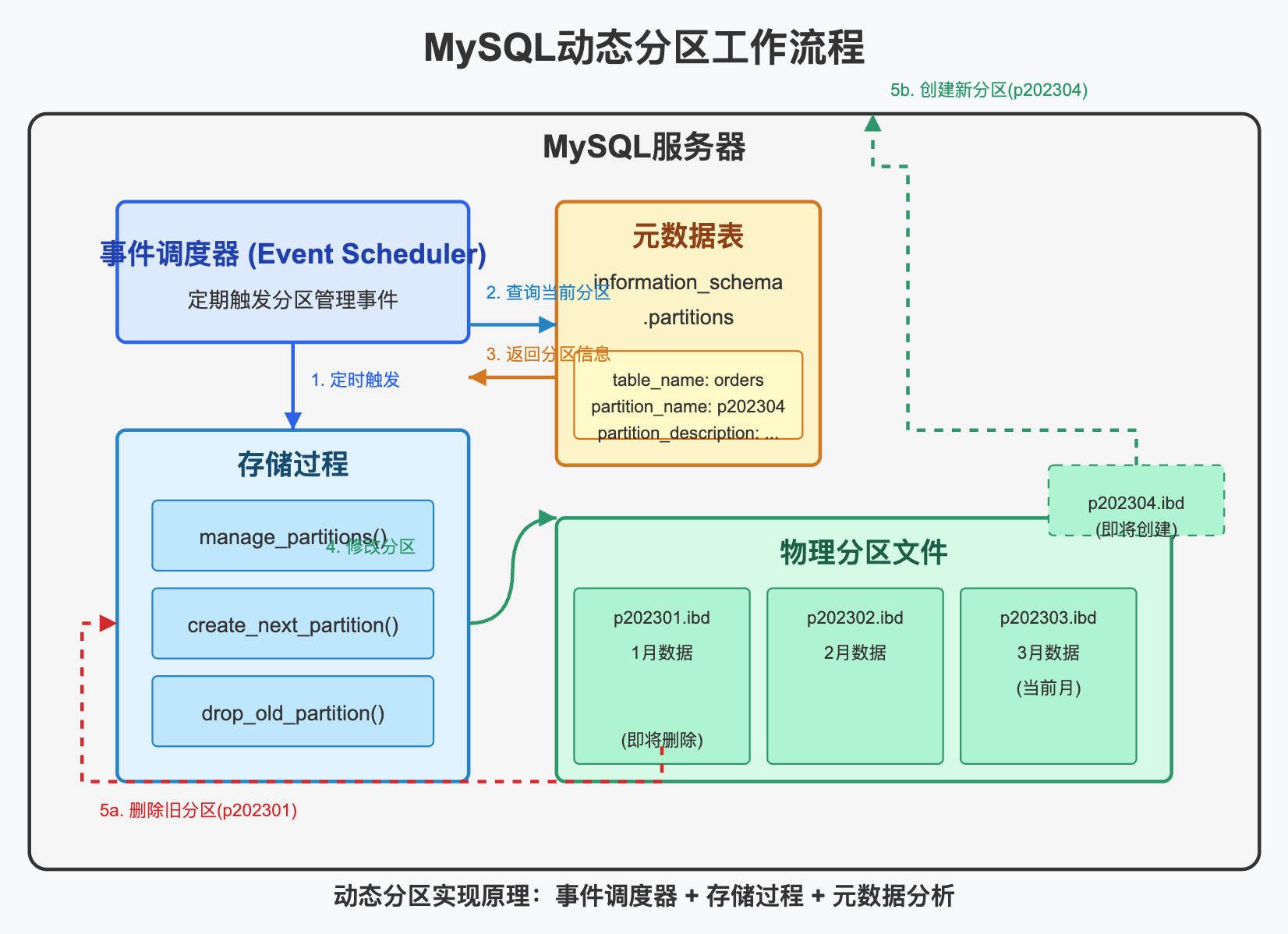
1. 事件调度器(Event Scheduler)
MySQL的事件调度器是实现动态分区的核心组件。它就像一个内置的cron作业,可以按计划执行SQL语句或存储过程。
事件调度器的工作方式:
- 在MySQL服务器内部持续运行
- 根据预定时间表触发事件
- 可以设置为一次性或定期重复执行
- 事件被执行时,存储过程被自动调用
2. 情报收集:分析分区元数据
动态分区管理的第一步是了解当前的分区状态,这通过查询MySQL的information_schema.partitions表实现:
sql
SELECT
partition_name,
partition_description
FROM
information_schema.partitions
WHERE
table_schema = 'your_database_name'
AND table_name = 'orders';这个查询返回表的所有分区信息,包括:
- 分区名称(如p202301)
- 分区定义(如TO_DAYS('2023-02-01'))
存储过程利用这些信息来确定:
- 最新的分区是哪个
- 最旧的分区是哪个
- 是否需要创建新分区
- 哪些旧分区应该被删除
3. 分区管理的核心操作:ALTER TABLE
所有分区管理操作最终都通过ALTER TABLE语句执行:
sql
-- 创建新分区
ALTER TABLE your_database_name.orders
ADD PARTITION (PARTITION p202304 VALUES LESS THAN (TO_DAYS('2023-05-01')));
-- 删除旧分区
ALTER TABLE your_database_name.orders
DROP PARTITION p202301;这些语句通过存储过程动态生成并执行,无需手动干预。
4. 物理存储的变化
在MySQL的InnoDB引擎中,每个分区实际上是一个独立的.ibd文件。当你添加或删除分区时,MySQL会:
- 添加分区:创建新的.ibd文件
- 删除分区:移除对应的.ibd文件并释放空间
这种物理隔离使得分区操作高效且对现有数据影响小。
动态分区的高级技巧与最佳实践
到目前为止,我们已经掌握了基本的动态分区管理。现在,让我们探讨一些高级技巧和最佳实践。
1. 处理特殊情况:预创建多个未来分区
在某些场景下,你可能希望预先创建多个未来分区,而不仅仅是下一个月的分区。例如:
sql
-- 修改存储过程以创建未来3个月的分区
CREATE PROCEDURE create_future_partitions(IN_TABLE VARCHAR(64), IN_SCHEMA VARCHAR(64), IN_MONTHS INT)
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE v_current_date DATE DEFAULT CURRENT_DATE();
DECLARE v_future_date DATE;
DECLARE v_next_date DATE;
DECLARE v_partition_name VARCHAR(32);
DECLARE v_sql VARCHAR(1000);
WHILE i < IN_MONTHS DO
-- 计算未来的月份
SET v_future_date = DATE_ADD(v_current_date, INTERVAL i+1 MONTH);
SET v_future_date = DATE_FORMAT(v_future_date, '%Y-%m-01'); -- 月初
-- 计算分区结束日期(下个月第一天)
SET v_next_date = DATE_ADD(v_future_date, INTERVAL 1 MONTH);
-- 生成分区名
SET v_partition_name = CONCAT('p', DATE_FORMAT(v_future_date, '%Y%m'));
-- 检查分区是否已存在
SET @partition_exists = 0;
SET @check_sql = CONCAT('SELECT COUNT(1) INTO @partition_exists
FROM information_schema.partitions
WHERE table_schema = ''', IN_SCHEMA, '''
AND table_name = ''', IN_TABLE, '''
AND partition_name = ''', v_partition_name, '''');
PREPARE stmt FROM @check_sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 如果分区不存在,则创建
IF @partition_exists = 0 THEN
SET v_sql = CONCAT('ALTER TABLE ', IN_SCHEMA, '.', IN_TABLE,
' ADD PARTITION (PARTITION ', v_partition_name,
' VALUES LESS THAN (TO_DAYS(''',
DATE_FORMAT(v_next_date, '%Y-%m-%d'), ''')))');
SET @alter_stmt = v_sql;
PREPARE stmt FROM @alter_stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT CONCAT('Created partition ', v_partition_name) AS log_message;
END IF;
SET i = i + 1;
END WHILE;
END$$2. 根据数据量而非时间进行分区管理
有时候,你可能希望根据每个分区中的数据量而不是固定时间来管理分区。例如,当分区大小超过某个阈值时才创建新分区:
sql
-- 检查分区大小并根据需要创建新分区
CREATE PROCEDURE check_partition_size(IN_TABLE VARCHAR(64), IN_SCHEMA VARCHAR(64), IN_SIZE_MB INT)
BEGIN
DECLARE v_largest_partition VARCHAR(64);
DECLARE v_largest_size BIGINT;
-- 查找最大的分区
SELECT
partition_name, data_length
INTO
v_largest_partition, v_largest_size
FROM
information_schema.partitions
WHERE
table_schema = IN_SCHEMA
AND table_name = IN_TABLE
ORDER BY
data_length DESC
LIMIT 1;
-- 如果最大分区超过阈值,创建新分区
IF v_largest_size > (IN_SIZE_MB * 1024 * 1024) THEN
-- 创建新分区的逻辑
-- ...
END IF;
END$$3. 多表分区并行管理
对于有多个需要分区管理的表,可以创建一个主存储过程来管理所有表:
sql
CREATE PROCEDURE manage_all_partitions()
BEGIN
-- 管理订单表
CALL manage_partitions('orders', 'your_database', 12);
-- 管理日志表
CALL manage_partitions('logs', 'your_database', 3);
-- 管理交易表
CALL manage_partitions('transactions', 'your_database', 24);
-- 可以继续添加更多表...
END$$4. 监控与告警
动态分区管理也需要监控,以确保一切正常运行:
sql
-- 创建分区管理审计表
CREATE TABLE partition_management_log (
id INT AUTO_INCREMENT PRIMARY KEY,
table_name VARCHAR(64) NOT NULL,
action VARCHAR(20) NOT NULL,
partition_name VARCHAR(64) NOT NULL,
execution_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
status VARCHAR(10) NOT NULL,
error_message TEXT
);
-- 修改存储过程,记录日志
-- 在manage_partitions()中添加:
BEGIN
-- 声明处理程序
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1
@sqlstate = RETURNED_SQLSTATE,
@errno = MYSQL_ERRNO,
@text = MESSAGE_TEXT;
INSERT INTO partition_management_log (table_name, action, partition_name, status, error_message)
VALUES (IN_TABLE, 'MANAGE', '', 'ERROR', CONCAT('Error: ', @errno, ' SQLSTATE: ', @sqlstate, ' Message: ', @text));
RESIGNAL;
END;
-- 正常执行...
-- 成功记录
INSERT INTO partition_management_log (table_name, action, partition_name, status, error_message)
VALUES (IN_TABLE, 'MANAGE', '', 'SUCCESS', '');
END$$性能对比:静态分区vs动态分区
理论讲完了,我们来看看分区管理对性能的实际影响:
查询性能
对于查询性能,静态分区和动态分区没有本质区别,因为它们都是物理分区表。关键区别在于维护成本和可靠性。
对于一个典型的查询,分区的好处是明显的:
sql
-- 不使用分区的查询(扫描整个表)
SELECT * FROM orders_no_partition
WHERE order_date BETWEEN '2023-03-01' AND '2023-03-31';
-- 执行时间:2.5秒(假设表有1000万行)
-- 使用分区的查询(只扫描相关分区)
SELECT * FROM orders
WHERE order_date BETWEEN '2023-03-01' AND '2023-03-31';
-- 执行时间:0.1秒(只扫描了p202303分区,约83万行)维护成本
这是静态分区和动态分区的最大区别:
-
静态分区:需要手动管理,容易出错,工作量大
- DBA每月工作:30分钟
- 出错概率:中高(人为失误导致)
- 响应突发情况能力:差(需要人工干预)
-
动态分区:自动管理,可靠性高,几乎零维护
- DBA每月工作:0分钟(设置后自动运行)
- 出错概率:低(代码一旦调试好就稳定运行)
- 响应突发情况能力:好(可以编写智能逻辑应对)
MySQL分区的限制与注意事项
尽管动态分区是一个强大的工具,但在使用它之前需要了解一些限制:
-
分区键限制:分区列必须是主键的一部分,或者是唯一键的一部分
-
存储引擎兼容性:只有某些存储引擎支持分区(如InnoDB、MyISAM),但不是所有的都支持
-
分区数量限制:MySQL对每个表的分区数量有上限(通常为8192个)
-
子分区限制:使用子分区会使分区管理更复杂
-
外键限制:分区表不能有外键约束,也不能被外键引用
-
全文索引限制:分区表不支持全文索引(在MySQL 8.0之前)
-
查询优化器限制:并非所有查询都能利用分区裁剪(partition pruning)技术
-
事件调度器依赖:如果事件调度器被禁用,动态分区管理将无法工作
面试热点问题解答
准备一个MySQL技术面试?以下是一些关于MySQL分区的常见面试问题及解答:
1. MySQL分区与分表有什么区别?
答:MySQL分区是将一个表分成多个物理部分,但逻辑上仍是一个表,SQL语句不需要修改。分表则是将一个大表拆分成多个独立的小表,每个小表有独立的表名,查询时需要修改SQL或使用中间件来路由查询。
分区由数据库自身管理,对应用透明;分表则需要应用层处理路由逻辑。分区适合中等规模数据,分表适合超大规模数据。
2. MySQL分区对性能有什么影响?
答:MySQL分区可以显著提升特定查询的性能,主要通过以下机制:
- 分区裁剪:查询只访问包含目标数据的分区,而不是整个表
- 并行查询:MySQL可以并行扫描多个分区
- 批量删除:删除整个分区比删除行更高效
- 维护简化:可以独立维护每个分区
但分区并非万能的性能解决方案。如果查询不能利用分区列进行筛选,可能需要扫描所有分区,反而会降低性能。
3. 如何选择合适的分区策略?
答:选择分区策略时应考虑以下因素:
- 数据分布:如果数据有明显的时间属性,RANGE分区最适合
- 查询模式:分析最常见的查询,确保它们能利用分区裁剪
- 数据增长方式:对于不断增长的历史数据,按时间范围分区最合适
- 数据生命周期:如果数据有明确的保留期限,分区可以方便地实现数据过期删除
- 数据均衡性:如果希望数据均匀分布,可以考虑HASH分区
最佳实践是根据最频繁的查询条件来选择分区键。
4. 动态分区管理的优缺点是什么?
答 :
优点:
- 自动化维护,减少人工操作
- 降低人为错误风险
- 确保新分区及时创建,旧分区按计划删除
- 提高系统可靠性和可预测性
- 节省DBA时间
缺点:
- 依赖MySQL事件调度器
- 设置初期需要更多技术投入
- 如果逻辑有错误,可能导致意外的分区删除
- 对于特殊情况处理可能不够灵活
- 需要监控机制确保正常运行
5. MySQL 8.0对分区有哪些改进?
答:MySQL 8.0对分区功能进行了多项改进:
- 支持分区表上的全文索引
- 改进了分区裁剪的优化器
- 增强了对JSON字段的分区支持
- 提供了更好的分区相关元数据
- 删除了非原生分区处理器
- 提供了更多分区相关的性能计数器
- 改进了分区表的DDL操作性能
让MySQL分区为你"自动工作"
动态分区管理将MySQL分区从一个需要持续手动维护的功能,转变为一个"设置后忘记"的自动化解决方案。它可以大大减少DBA的工作量,同时提高系统的可靠性和预测性。
关键要点回顾:
- MySQL分区可以显著提高大表的查询性能和管理效率
- 动态分区管理使用事件调度器和存储过程自动创建新分区、删除旧分区
- 正确设置后,动态分区几乎不需要人工干预
- 分区最适合有明确时间属性的数据,如日志、订单历史等
- 动态分区可以根据业务需求进行高度定制,如根据数据量或访问模式调整策略
如果你的数据库中有大型时间序列表,而且你厌倦了手动管理分区的繁琐工作,那么是时候考虑实施动态分区管理了。它不仅能让你的系统更可靠,还能让你把时间花在更有价值的工作上。
毕竟,好的数据库管理员不是"修复问题",而是"防止问题发生"。动态分区管理正是这种理念的完美体现。
希望这篇文章对你有所帮助!如果你有任何问题或想分享你的动态分区实践经验,欢迎在评论区留言。祝你的MySQL数据库运行顺畅,分区管理无忧!