🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
需求定制化开发
源码提供与讲解
技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅
基于大数据的智能制造生产效能分析与可视化系统-功能介绍
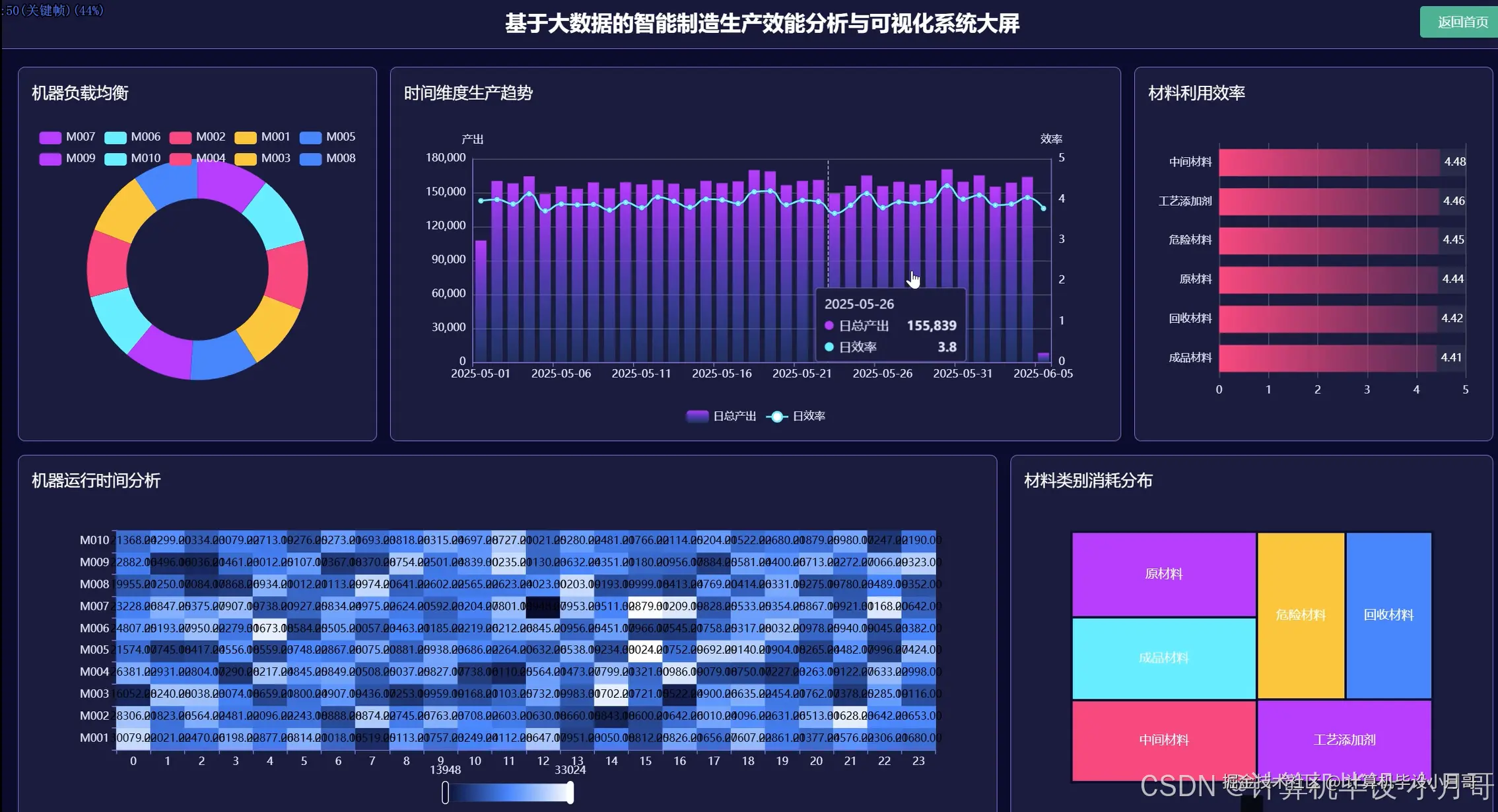
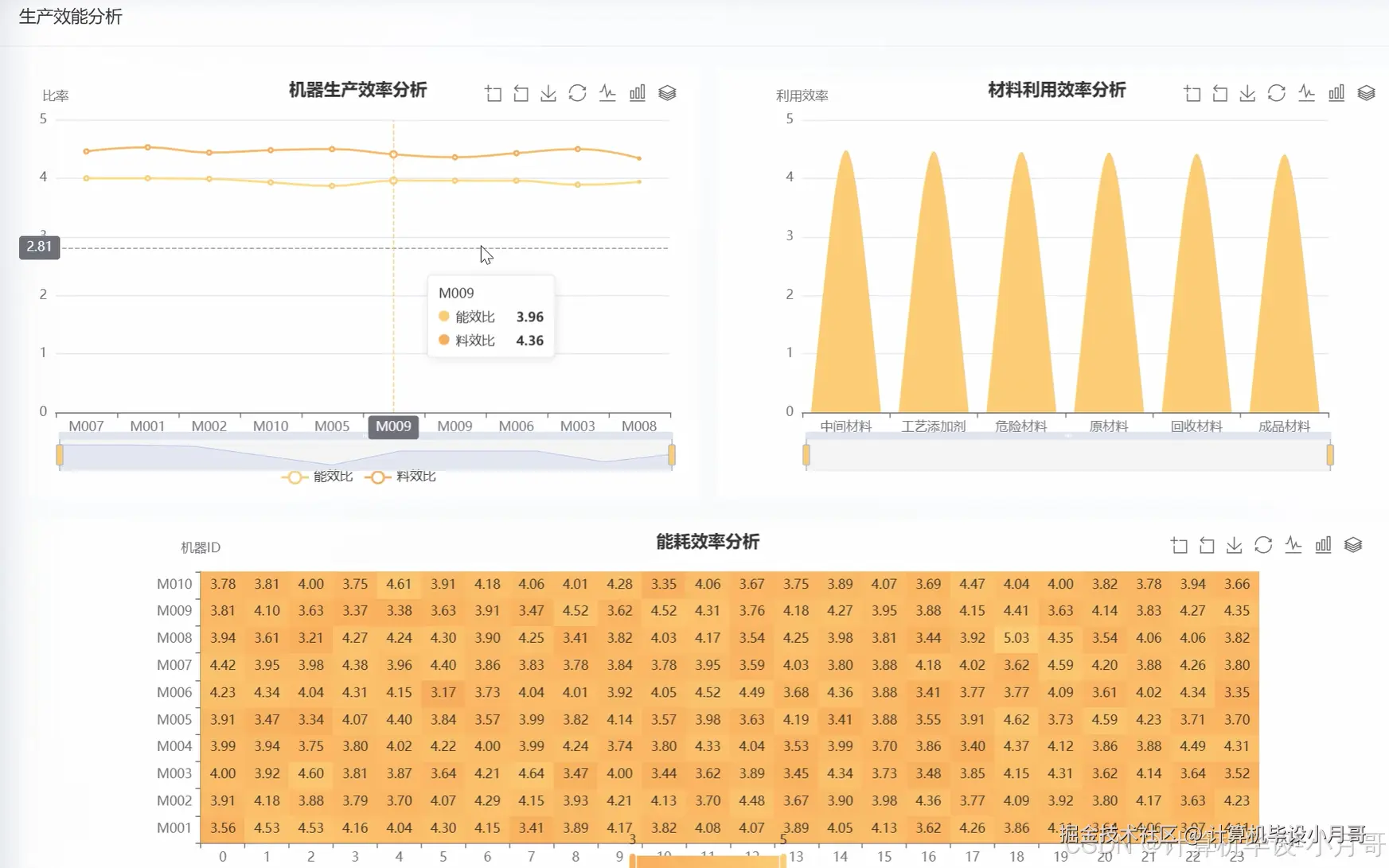
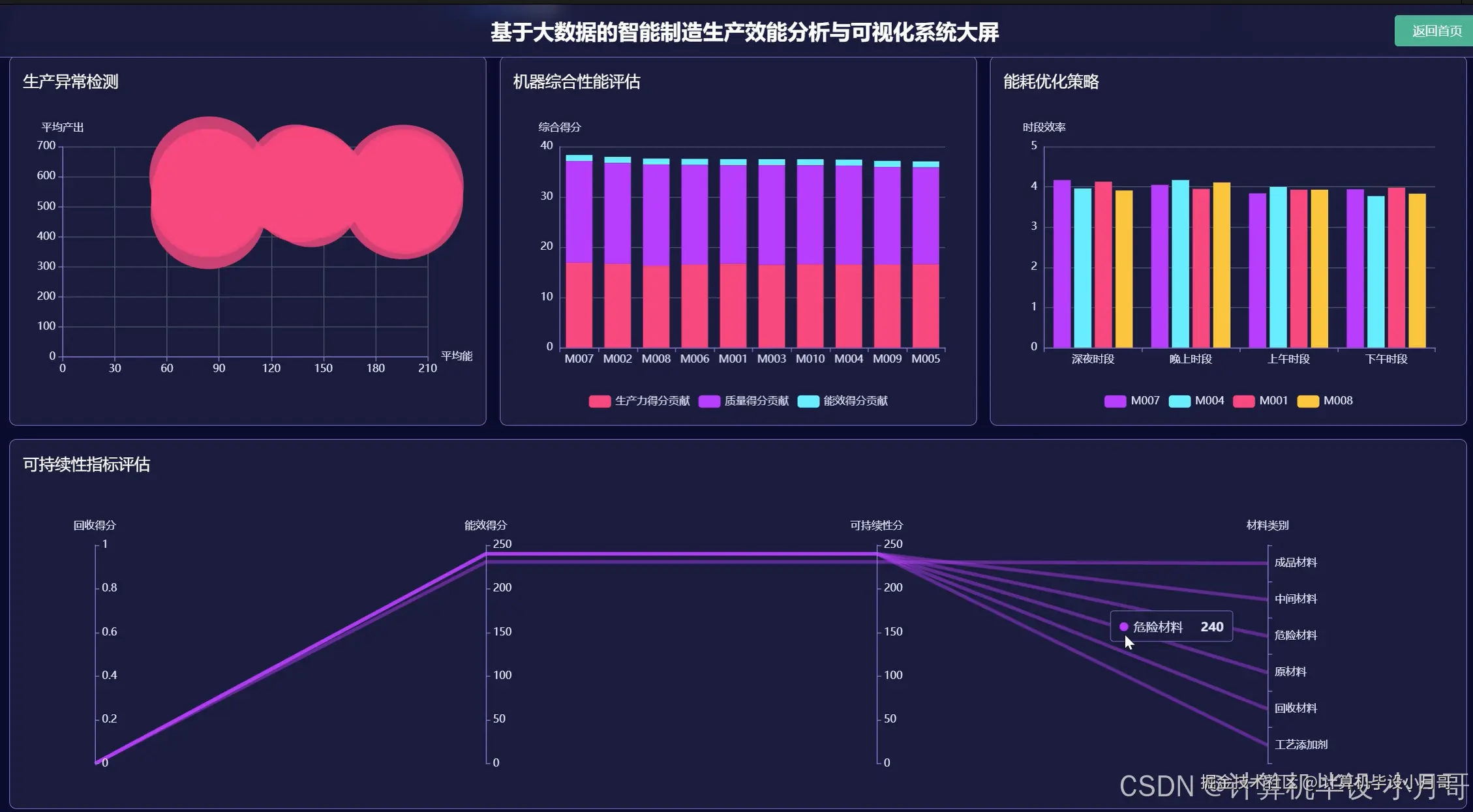
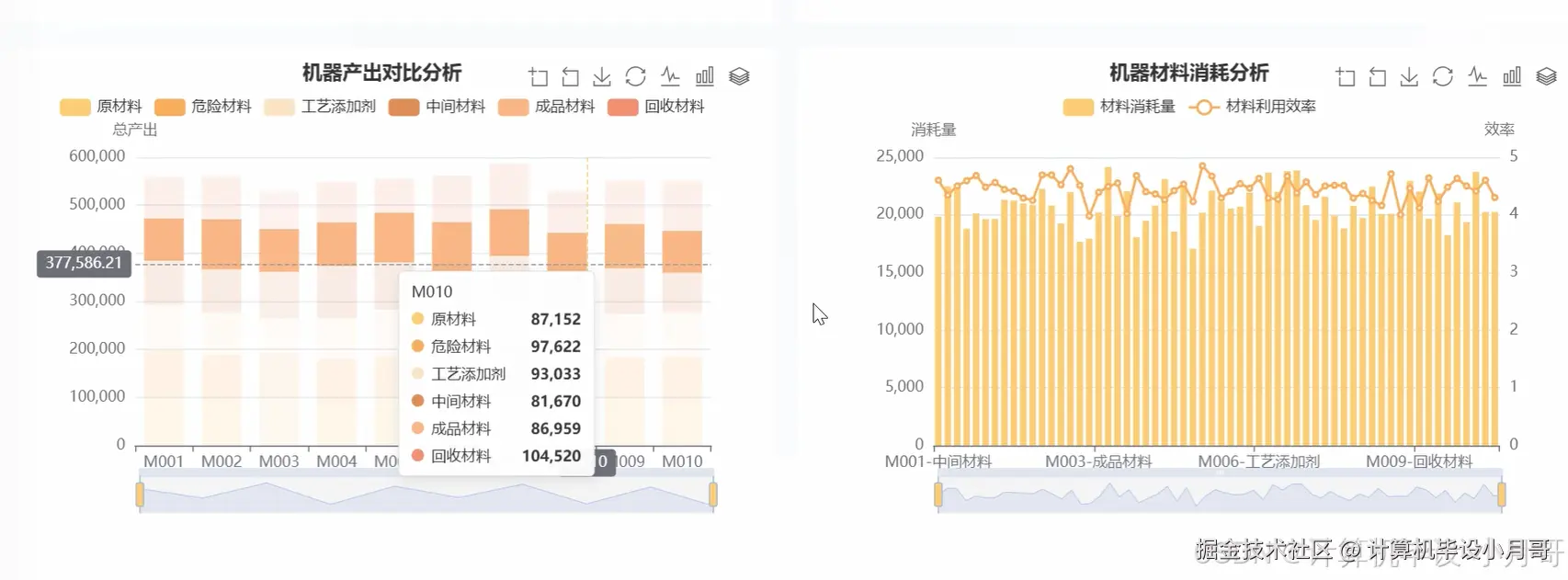
本系统是一个基于Hadoop与Spark大数据技术栈构建的智能制造生产效能分析与可视化平台,旨在应对现代工业环境中海量、多源生产数据的处理挑战。系统以Python作为主要开发语言,利用Spark强大的分布式计算能力,对智能制造场景下的核心生产数据进行深度挖掘与高效分析。系统首先通过Hadoop HDFS对海量生产记录(如smart_manufacturing_dataset.csv)进行分布式存储,随后利用Spark SQL及Pandas对数据进行清洗、转换和预处理,确保数据质量。核心分析模块围绕生产效能、质量控制、资源消耗、设备性能和运营优化五大维度展开,能够精确计算单台机器的单位能耗产出比与单位材料产出比,从而识别高效与低效设备;能够按材料类别分析其利用效率,为优化材料配置、降低成本提供依据;还能进行时间序列趋势分析,揭示生产效能的周期性规律与波动。最终,系统通过Vue与Echarts构建的前端界面,将复杂的分析结果以直观的动态图表形式呈现,如设备性能排名雷达图、材料消耗分布饼图、生产效能趋势折线图等,为管理者提供一个清晰、全面的数据驱动决策支持工具,实现生产过程的精细化管理和持续优化。
基于大数据的智能制造生产效能分析与可视化系统-选题背景意义
选题背景 随着工业4.0和智能制造概念的不断深入,现代工厂早已不是单纯的机械集合,而是演变成了由数据驱动的复杂系统。生产线上的传感器、控制器和各种信息系统每时每刻都在产生海量的数据,这些数据涵盖了设备状态、物料流转、能源消耗、产品质量等方方面面。这些数据蕴含着巨大的价值,能够帮助我们洞察生产过程中的瓶颈、发现效率提升的空间以及预测潜在的质量风险。然而,传统的数据分析方法,如基于单机或小型数据库的统计分析,在面对这种体量大、维度多、产生速度快的大数据时显得力不从心,处理效率低下且难以挖掘出数据间深层次的关联。正是在这样的背景下,利用Hadoop和Spark这类专为大数据处理而生的技术,对智能制造的生产效能进行系统性分析,成为了一个极具现实意义和应用价值的课题。它旨在解决传统方法无法处理的数据难题,将沉睡的数据转化为指导生产的宝贵洞察。 选题意义 本课题的意义在于,它尝试将前沿的大数据技术应用于一个具体的工业场景,探索解决实际问题的可能性。从实际应用的角度来看,这个系统能够为制造企业的管理者提供一个清晰的"驾驶舱",让他们能直观地看到整个生产线的运行状况。通过分析,可以帮助识别出哪些设备的能耗产出比最低,或者哪些材料组合的缺陷率最高,从而为设备维护、工艺改进和材料采购提供精准的数据支持。这不仅仅是为了提升几个百分点的效率,更是为了优化生产调度、降低不必要的能耗和材料浪费,最终实现降本增增效。从学术和实践学习的角度看,这个项目也是一个完整的大数据处理流程的实践,涵盖了从数据采集、存储、清洗、分析到最终可视化的全过程。对于计算机专业的学生而言,亲手搭建这样一个系统,能够极大地加深对大数据技术栈的理解和应用能力。虽然它只是一个毕业设计的范畴,但其核心思路和方法,即用数据驱动决策,对于未来从事相关领域的工作或研究,都具有很好的参考和启发价值。
基于大数据的智能制造生产效能分析与可视化系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的智能制造生产效能分析与可视化系统-视频展示
基于大数据的智能制造生产效能分析与可视化系统-图片展示

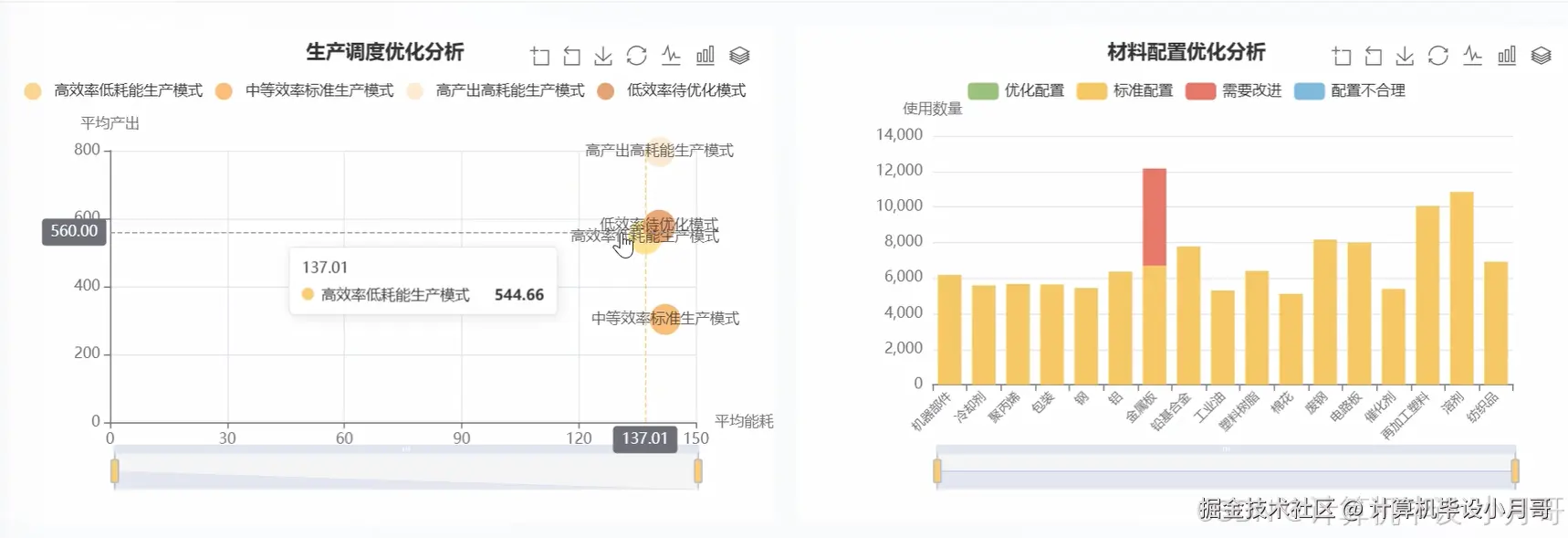
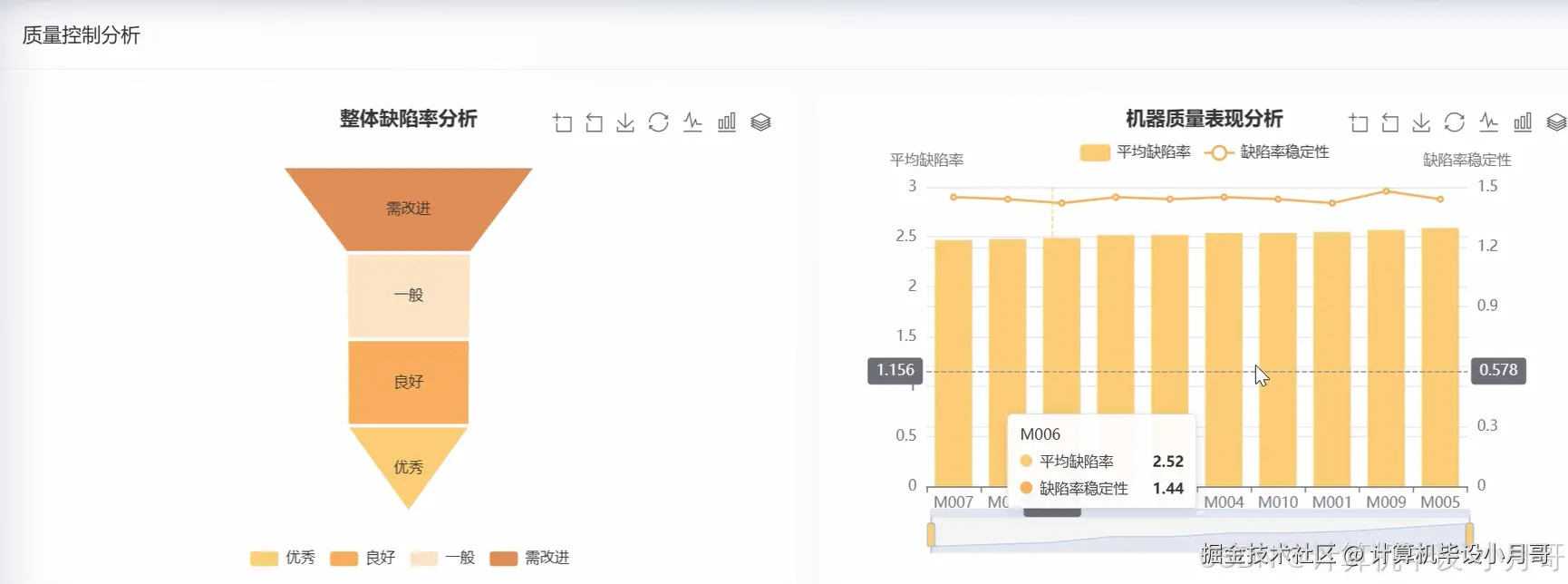
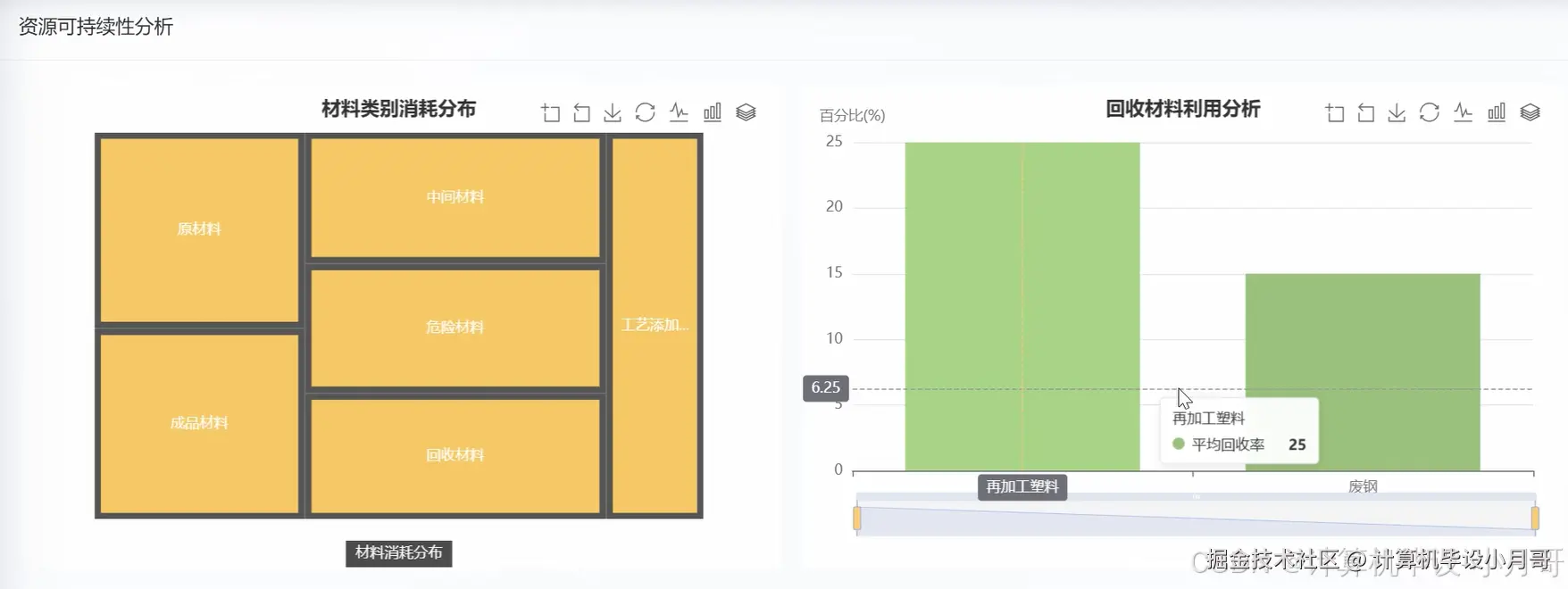
基于大数据的智能制造生产效能分析与可视化系统-代码展示
python
from pyspark.sql import SparkSession, functions as F
# 初始化SparkSession
spark = SparkSession.builder \
.appName("SmartManufacturingAnalysis") \
.getOrCreate()
# 假设df是已经加载好的Spark DataFrame
# df = spark.read.csv("hdfs://path/to/smart_manufacturing_dataset.csv", header=True, inferSchema=True)
# 核心功能1: 机器生产效率分析
def machine_efficiency_analysis(df):
# 按机器ID分组,计算总产出、总能耗、总材料用量
machine_summary = df.groupBy("Machine ID").agg(
F.sum("Production Output").alias("Total_Production_Output"),
F.sum("Energy Consumption").alias("Total_Energy_Consumption"),
F.sum("Quantity Used").alias("Total_Quantity_Used")
)
# 计算单位能耗产出比和单位材料产出比,避免除以零的错误
machine_efficiency = machine_summary.withColumn(
"Energy_Output_Ratio",
F.when(F.col("Total_Energy_Consumption") > 0, F.col("Total_Production_Output") / F.col("Total_Energy_Consumption")).otherwise(0)
).withColumn(
"Material_Output_Ratio",
F.when(F.col("Total_Quantity_Used") > 0, F.col("Total_Production_Output") / F.col("Total_Quantity_Used")).otherwise(0)
)
# 按单位能耗产出比降序排列,找出最高效的机器
return machine_efficiency.orderBy(F.desc("Energy_Output_Ratio"))
# 核心功能2: 材料利用效率分析
def material_efficiency_analysis(df):
# 按材料类别和具体材料名称分组,计算总产出和总用量
material_summary = df.groupBy("Material Category", "Material Name").agg(
F.sum("Production Output").alias("Total_Production_Output"),
F.sum("Quantity Used").alias("Total_Quantity_Used")
)
# 计算单位材料产出比
material_efficiency = material_summary.withColumn(
"Material_Output_Ratio",
F.when(F.col("Total_Quantity_Used") > 0, F.col("Total_Production_Output") / F.col("Total_Quantity_Used")).otherwise(0)
)
# 按材料类别和单位产出比排序
return material_efficiency.orderBy("Material Category", F.desc("Material_Output_Ratio"))
# 核心功能3: 时间维度生产效能趋势分析
def time_dimension_trend_analysis(df):
# 将Timestamp转换为时间类型,并提取日期和小时作为分析维度
time_df = df.withColumn("Timestamp", F.to_timestamp("Timestamp", "yyyy-MM-dd HH:mm:ss")) \
.withColumn("Date", F.date_format("Timestamp", "yyyy-MM-dd")) \
.withColumn("Hour", F.hour("Timestamp"))
# 按日期和小时分组,计算总产出、平均缺陷率和总能耗
time_trend = time_df.groupBy("Date", "Hour").agg(
F.sum("Production Output").alias("Hourly_Production_Output"),
F.avg("Defect Rate").alias("Hourly_Avg_Defect_Rate"),
F.sum("Energy Consumption").alias("Hourly_Energy_Consumption")
)
# 按日期和小时排序,以形成时间序列
return time_trend.orderBy("Date", "Hour")
# # 示例调用
# df = spark.read.csv("hdfs://path/to/smart_manufacturing_dataset.csv", header=True, inferSchema=True)
# machine_efficiency_analysis(df).show()
# material_efficiency_analysis(df).show()
# time_dimension_trend_analysis(df).show(50)基于大数据的智能制造生产效能分析与可视化系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
🍅 ↓↓主页获取源码联系↓↓🍅