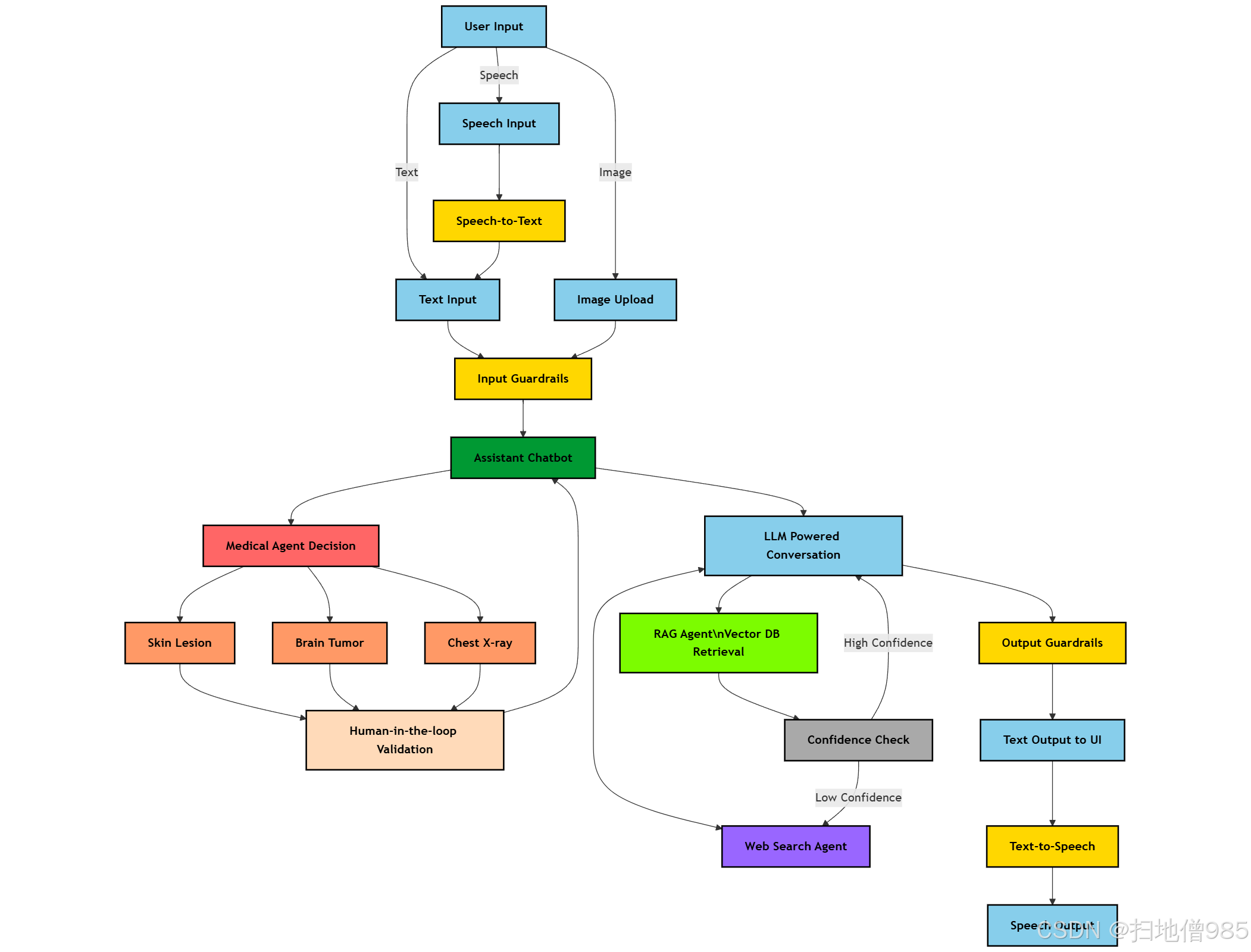
第一部分:项目主框架及框架结构图
项目主框架概述
该项目名为基于Agent的智能医疗辅助诊断系统,是一个基于多智能体的医疗辅助系统,旨在利用人工智能技术为医疗诊断、研究和患者交互提供支持。其核心是多智能体架构,集成了大语言模型(LLMs)、计算机视觉模型、检索增强生成(RAG)、实时网络搜索和人工验证等功能。
框架结构图
python
+----------------------+
| 用户界面 |
| (HTML, CSS, JavaScript)|
+----------------------+
|
v
+----------------------+
| FastAPI后端 |
| 处理用户请求 |
+----------------------+
|
| /chat, /upload, /validate等
v
+----------------------+
| 智能体决策系统 |
| 路由到合适的智能体 |
+----------------------+
|
| 不同类型请求
v
+----------------------+ +----------------------+ +----------------------+
| RAG智能体 | | 计算机视觉智能体 | | 网络搜索智能体 |
| 利用向量数据库检索 | | 分析医学图像 | | 获取最新医学研究 |
+----------------------+ +----------------------+ +----------------------+
|
| 向量数据库
v
+----------------------+
| Qdrant向量数据库 |
| 存储知识数据 |
+----------------------+第二部分:项目结构和每一个文件的作用
项目整体结构
python
Agent-Medical
├── Dockerfile # 用于构建Docker镜像
├── LICENSE # 项目的开源许可证文件
├── README.md # 项目说明文档
├── app.py # FastAPI应用的主文件
├── config.py # 项目配置文件
├── ingest_rag_data.py # 用于将数据导入RAG系统
├── requirements.txt # 项目依赖的Python包列表
├── assets/ # 项目资源文件
├── templates/ # 存储HTML模板文件
│ └── index.html # 主页面HTML模板
├── agents/ # 智能体相关代码
│ ├── README.md # 智能体模块说明文档
│ ├── agent_decision.py# 智能体决策逻辑
│ ├── guardrails/ # 护栏机制相关代码
│ ├── image_analysis_agent/ # 图像分析智能体代码
│ ├── rag_agent/ # RAG智能体代码
│ └── web_search_processor_agent/ # 网络搜索处理智能体代码
├── uploads/ # 存储上传的文件
│ ├── backend/ # 后端上传文件存储目录
│ ├── frontend/ # 前端上传文件存储目录
│ ├── skin_lesion_output/ # 皮肤病变分析输出目录
│ └── speech/ # 语音文件存储目录
├── .github/ # GitHub相关配置
│ ├── FUNDING.yml # 项目资助信息
│ └── workflows/ # GitHub Actions工作流配置
│ └── docker-image.yml # 构建Docker镜像的工作流
├── data/ # 数据存储目录
│ ├── docs_db/ # 文档数据库
│ ├── parsed_docs/ # 解析后的文档
│ ├── qdrant_db/ # Qdrant向量数据库
│ ├── raw/ # 原始数据
│ └── raw_extras/ # 额外的原始数据
└── sample_images/ # 示例医学图像
├── chest_x-ray_covid_and_normal/ # 胸部X光示例图像
└── skin_lesion_images/ # 皮肤病变示例图像主要文件作用详细分析
- app.py:使用 FastAPI 构建的后端应用程序,处理用户的文本查询、图像上传、语音转录和人工验证请求。它负责与前端进行交互,并将请求路由到相应的智能体进行处理。
- config.py:存储项目的配置信息,如 API 密钥、文件上传大小限制等。其他模块可以导入该文件中的配置对象来使用这些配置。
- ingest_rag_data.py :用于将文档数据导入到 RAG 系统中。支持单个文件和目录的导入,通过调用
MedicalRAG类的方法完成数据处理和存储。 - agents/rag_agent/init.py :定义了
MedicalRAG类,负责 RAG 系统的初始化和主要操作,包括文档解析、图像摘要、文档分块、向量存储和查询处理等。 - agents/rag_agent/doc_parser.py:实现了文档解析功能,从文档中提取结构化内容和图像,并将图像保存到指定目录。
- .github/workflows/docker-image.yml :GitHub Actions 工作流配置文件,当代码推送到
main分支或发起拉取请求时,自动构建 Docker 镜像。
技术流程图
技术栈
| 元件 | 技术 |
|---|---|
| 🔹 后端框架 | FastAPI |
| 🔹 代理编排 | 语言图 |
| 🔹 文档解析 | 文档 |
| 🔹 知识储存 | Qdrant 向量数据库 |
| 🔹 医学成像 | 计算机视觉模型 |
| • 脑肿瘤:对象检测 (PyTorch) | |
| • 胸部 X 光片:图像分类 (PyTorch) | |
| • 皮肤病变:语义分割 (PyTorch) | |
| 🔹 护栏 | LangChain 语言链 |
| 🔹 语音处理 | Eleven Labs API |
| 🔹 前端 | HTML、CSS、JavaScript |
| 🔹 部署 | Docker、GitHub Actions CI/CD |
第三部分:代码结构和代码用到的技术
代码结构分析
- 模块化设计:项目采用模块化设计,将不同功能封装在不同的模块和类中,如智能体模块、配置模块、数据导入模块等,提高了代码的可维护性和可扩展性。
- 分层架构:分为前端、后端和数据层。前端使用 HTML、CSS 和 JavaScript 构建用户界面,后端使用 FastAPI 处理业务逻辑,数据层使用 Qdrant 向量数据库存储知识数据。
用到的技术
- 后端框架:FastAPI,一个高性能的 Python Web 框架,用于构建 RESTful API。
- 多智能体编排:LangGraph 和 LangChain,用于实现智能体的编排和交互。
- 向量数据库:Qdrant,用于存储和检索向量数据,支持 RAG 系统的高效查询。
- 医学图像分析:计算机视觉模型,如 PyTorch 模型,用于脑部肿瘤检测、胸部 X 光图像分类和皮肤病变分割。
- 语音处理:Eleven Labs API,实现语音到文本和文本到语音的转换。
- 文档解析:Docling,用于解析文档并提取文本、表格和图像。
- 部署:Docker 和 GitHub Actions CI/CD,实现项目的容器化部署和自动化构建。
第四部分:完整详细的实现步骤
1. 配置 API 密钥
在config.py文件中配置所需的 API 密钥,如 Eleven Labs API 密钥等。
python
"""
此文件包含项目的所有配置参数。
如果要更改LLM(语言模型)和嵌入模型:
可以通过更改以下多个类中所有的 'llm' 和 'embedding_model' 变量来实现。
每个语言模型定义都有一个与特定类相关的唯一温度值(temperature)。
"""
import os
from dotenv import load_dotenv
from langchain_openai import AzureOpenAIEmbeddings, AzureChatOpenAI
# 从.env文件加载环境变量
load_dotenv()
class AgentDecisionConfig:
"""
智能体决策配置类
用于配置智能体决策相关的语言模型(LLM)参数。
"""
def __init__(self):
self.llm = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.1 # 确定性(较低的温度值表示更确定的输出)
)
class ConversationConfig:
"""
对话配置类
用于配置对话相关的语言模型(LLM)参数。
"""
def __init__(self):
self.llm = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.7 # 创造性但事实性(较高的温度值表示更创造性的输出)
)
class WebSearchConfig:
"""
网络搜索配置类
用于配置网络搜索相关的语言模型(LLM)参数。
"""
def __init__(self):
self.llm = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.3 # 稍微创造性但事实性
)
self.context_limit = 20 # 在历史记录中包含最后20条消息(10对问答)
class RAGConfig:
"""
RAG(Retrieval-Augmented Generation)配置类
用于配置RAG相关的参数,包括向量数据库、嵌入模型、语言模型等。
"""
def __init__(self):
self.vector_db_type = "qdrant" # 向量数据库类型
self.embedding_dim = 1536 # 嵌入维度
self.distance_metric = "Cosine" # 距离度量,默认为余弦相似度
self.use_local = True # 是否使用本地存储,默认为True
self.vector_local_path = "./data/qdrant_db" # 本地向量数据库路径
self.doc_local_path = "./data/docs_db" # 本地文档数据库路径
self.parsed_content_dir = "./data/parsed_docs" # 解析后的内容目录
self.url = os.getenv("QDRANT_URL") # Qdrant服务的URL
self.api_key = os.getenv("QDRANT_API_KEY") # Qdrant服务的API密钥
self.collection_name = "medical_assistance_rag" # 集合名称
self.chunk_size = 512 # 文本块大小
self.chunk_overlap = 50 # 文本块重叠大小
# 初始化Azure OpenAI嵌入模型
self.embedding_model = AzureOpenAIEmbeddings(
deployment = os.getenv("embedding_deployment_name"), # 替换为你的Azure嵌入部署名称
model = os.getenv("embedding_model_name"), # 替换为你的Azure嵌入模型名称
azure_endpoint = os.getenv("embedding_azure_endpoint"), # 替换为你的Azure嵌入端点
openai_api_key = os.getenv("embedding_openai_api_key"), # 替换为你的Azure OpenAI嵌入API密钥
openai_api_version = os.getenv("embedding_openai_api_version") # 确保与你的嵌入API版本匹配
)
self.llm = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.3 # 稍微创造性但事实性
)
self.summarizer_model = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.5 # 稍微创造性但事实性
)
self.chunker_model = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.0 # 事实性(较低的温度值表示更确定的输出)
)
self.response_generator_model = AzureChatOpenAI(
deployment_name = os.getenv("deployment_name"), # 替换为你的Azure部署名称
model_name = os.getenv("model_name"), # 替换为你的Azure模型名称
azure_endpoint = os.getenv("azure_endpoint"), # 替换为你的Azure端点
openai_api_key = os.getenv("openai_api_key"), # 替换为你的Azure OpenAI API密钥
openai_api_version = os.getenv("openai_api_version"), # 确保与你的API版本匹配
temperature = 0.3 # 稍微创造性但事实性
)
self.top_k = 5 # 搜索结果数量
self.vector_search_type = 'similarity' # 或 'mmr'(最大边际相关性)
self.huggingface_token = os.getenv("HUGGINGFACE_TOKEN") # Hugging Face的API密钥
self.reranker_model = "cross-encoder/ms-marco-TinyBERT-L-6" # 重排序模型
self.reranker_top_k = 3 # 重排序结果数量
self.max_context_length = 8192 # 最大上下文长度
self.include_sources = True # 是否显示参考文档和图像的链接
self.min_retrieval_confidence = 0.40 # 最小检索置信度
self.context_limit = 20 # 在历史记录中包含最后20条消息(10对问答)
class MedicalCVConfig:
"""
医疗计算机视觉配置类
用于配置医疗图像分析相关的模型路径和语言模型参数2. 数据导入
使用ingest_rag_data.py脚本将文档数据导入到 RAG 系统中。可以导入单个文件或整个目录:
python
python ingest_rag_data.py --file /path/to/your/file.pdf
# 或者
python ingest_rag_data.py --dir /path/to/your/directory3. 构建和运行 Docker 镜像(可选)
如果你选择使用 Docker 部署项目,可以按照以下步骤操作:
- 构建 Docker 镜像:
python
docker build . --file Dockerfile --tag multi-agent-medical-assistant:latest- 运行 Docker 容器:
python
docker run -p 8000:8000 multi-agent-medical-assistant:latest4. 启动应用程序
如果你没有使用 Docker,可以直接启动 FastAPI 应用:
uvicorn app:app --reload5. 使用应用程序核心代码
- 打开浏览器,访问
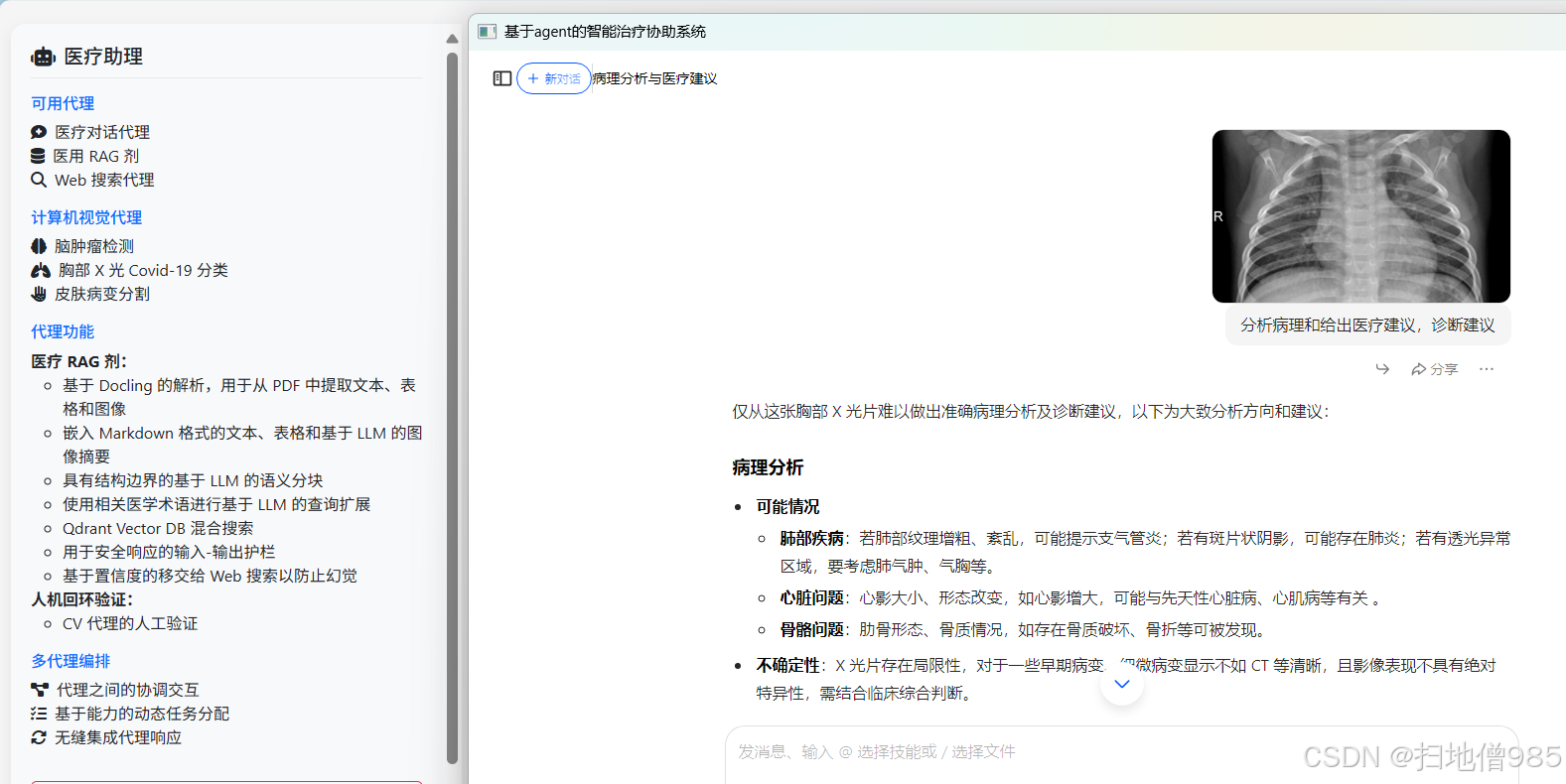
http://localhost:8000,可以看到主页面。 - 可以上传医学图像进行 AI 诊断,输入医学查询进行 RAG 检索或网络搜索,使用语音交互功能,以及进行人工验证。
python
# 导入所需库
import os # 操作系统接口
import uuid # 生成唯一标识符
import requests # HTTP请求库
from werkzeug.utils import secure_filename # 安全文件名处理
from flask import Flask, render_template, request, jsonify, make_response, abort, send_file, \
after_this_request # Flask核心组件
import threading # 多线程支持
import time # 时间相关操作
import glob # 文件路径匹配
import tempfile # 临时文件处理
from pydub import AudioSegment # 音频处理库
from io import BytesIO # 字节流处理
from elevenlabs.client import ElevenLabs # ElevenLabs语音API客户端
from config import Config # 配置文件
# 初始化配置
config = Config()
# 创建Flask应用实例
app = Flask(__name__)
# 应用配置
app.config['UPLOAD_FOLDER'] = 'uploads/frontend' # 前端上传文件目录
app.config['SPEECH_DIR'] = 'uploads/speech' # 语音文件存储目录
app.config['MAX_CONTENT_LENGTH'] = config.api.max_image_upload_size * 1024 * 1024 # 最大上传文件大小(MB转字节)
app.config['ELEVEN_LABS_API_KEY'] = config.speech.eleven_labs_api_key # ElevenLabs API密钥
app.config['API_URL'] = "http://localhost:8000" # 后端FastAPI服务地址
# 确保上传目录存在
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
# 初始化ElevenLabs客户端
client = ElevenLabs(
api_key=app.config['ELEVEN_LABS_API_KEY'],
)
# 允许上传的文件类型
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg'}
def allowed_file(filename):
"""检查文件扩展名是否合法"""
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
def cleanup_old_audio():
"""后台清理任务:每5分钟删除旧的语音文件"""
while True:
try:
# 获取所有MP3文件并删除
files = glob.glob(f"{app.config['SPEECH_DIR']}/*.mp3")
for file in files:
os.remove(file)
print("已清理旧语音文件")
except Exception as e:
print(f"清理过程中出错: {e}")
time.sleep(300) # 每5分钟运行一次
# 启动后台清理线程
cleanup_thread = threading.Thread(target=cleanup_old_audio, daemon=True)
cleanup_thread.start()
@app.route('/')
def index():
"""首页路由"""
return render_template('index.html')
@app.route('/send_message', methods=['POST'])
def send_message():
"""
处理发送消息请求
功能:接收用户消息和文件,转发到后端API并返回响应
"""
data = request.form
prompt = data.get('message') # 获取用户消息
# 获取会话cookie
session_cookie = request.cookies.get('session_id')
# 处理文件上传
uploaded_file = None
if 'file' in request.files:
file = request.files['file']
if file and file.filename != '':
# 验证文件类型
if not allowed_file(file.filename):
return jsonify({
"status": "error",
"agent": "系统",
"response": "不支持的文件类型。允许格式: PNG, JPG, JPEG"
}), 400
# 验证文件大小
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0) # 重置文件指针
if file_size > app.config['MAX_CONTENT_LENGTH']:
return jsonify({
"status": "error",
"agent": "系统",
"response": f"文件过大。最大允许大小: {config.api.max_image_upload_size}MB"
}), 413
# 安全保存文件
filename = secure_filename(f"{uuid.uuid4()}_{file.filename}")
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(filepath)
uploaded_file = filepath
try:
# 准备cookies
cookies = {}
if session_cookie:
cookies['session_id'] = session_cookie
if uploaded_file:
# 发送带图片的API请求
with open(uploaded_file, "rb") as image_file:
files = {"image": (os.path.basename(uploaded_file), image_file, "image/jpeg")}
data = {"text": prompt}
response = requests.post(
f"{app.config['API_URL']}/upload",
files=files,
data=data,
cookies=cookies
)
# 删除临时文件
try:
os.remove(uploaded_file)
except Exception as e:
print(f"删除临时文件失败: {str(e)}")
else:
# 发送纯文本API请求
payload = {
"query": prompt,
"conversation_history": [] # 对话历史由后端维护
}
response = requests.post(
f"{app.config['API_URL']}/chat",
json=payload,
cookies=cookies
)
if response.status_code == 200:
result = response.json()
# 准备响应数据
response_data = {
"status": "success",
"agent": result["agent"],
"response": result["response"]
}
# 添加结果图片URL(如果有)
if "result_image" in result:
response_data["result_image"] = f"{app.config['API_URL']}{result['result_image']}"
flask_response = jsonify(response_data)
# 更新会话cookie(如果需要)
if 'session_id' in response.cookies:
flask_response.set_cookie('session_id', response.cookies['session_id'])
return flask_response
else:
return jsonify({
"status": "error",
"agent": "系统",
"response": f"错误: {response.status_code} - {response.text}"
}), response.status_code
except Exception as e:
print(f"异常: {str(e)}")
return jsonify({
"status": "error",
"agent": "系统",
"response": f"错误: {str(e)}"
}), 500
@app.route('/transcribe', methods=['POST'])
def transcribe_audio():
"""语音转文字接口"""
if 'audio' not in request.files:
return jsonify({"error": "未提供音频文件"}), 400
audio_file = request.files['audio']
if audio_file.filename == '':
return jsonify({"error": "未选择音频文件"}), 400
try:
# 临时保存音频文件
temp_dir = app.config['SPEECH_DIR']
os.makedirs(temp_dir, exist_ok=True)
temp_audio = f"./{temp_dir}/speech_{uuid.uuid4()}.webm"
audio_file.save(temp_audio)
# 检查文件大小
file_size = os.path.getsize(temp_audio)
print(f"接收到的音频文件大小: {file_size} 字节")
if file_size == 0:
return jsonify({"error": "收到空音频文件"}), 400
# 转换为MP3格式
mp3_path = f"./{temp_dir}/speech_{uuid.uuid4()}.mp3"
try:
audio = AudioSegment.from_file(temp_audio)
audio.export(mp3_path, format="mp3")
mp3_size = os.path.getsize(mp3_path)
print(f"转换后的MP3文件大小: {mp3_size} 字节")
with open(mp3_path, "rb") as mp3_file:
audio_data = mp3_file.read()
print("成功将音频文件转换为字节数组!")
# 调用ElevenLabs API进行语音转文字
transcription = client.speech_to_text.convert(
file=audio_data,
model_id="scribe_v1", # 使用的模型
tag_audio_events=True, # 标记音频事件(如笑声、掌声等)
language_code="eng", # 音频语言
diarize=True, # 是否标注说话人
)
# 清理临时文件
try:
os.remove(temp_audio)
os.remove(mp3_path)
print(f"已删除临时文件: {temp_audio}, {mp3_path}")
except Exception as e:
print(f"无法删除文件: {e}")
if transcription.text:
return jsonify({"transcript": transcription.text})
else:
return jsonify({"error": f"API错误: {transcription}", "details": transcription.text}), 500
except Exception as e:
print(f"音频处理错误: {str(e)}")
return jsonify({"error": f"音频处理错误: {str(e)}"}), 500
except Exception as e:
print(f"语音转文字错误: {str(e)}")
return jsonify({"error": str(e)}), 500
@app.route('/generate-speech', methods=['POST'])
def generate_speech():
"""文字转语音接口"""
try:
data = request.json
text = data.get("text", "")
selected_voice_id = data.get("voice_id", "EXAMPLE_VOICE_ID") # 语音ID
if not text:
return jsonify({"error": "需要提供文本内容"}), 400
# 准备ElevenLabs API请求
elevenlabs_url = f"https://api.elevenlabs.io/v1/text-to-speech/{selected_voice_id}/stream"
headers = {
"Accept": "audio/mpeg",
"Content-Type": "application/json",
"xi-api-key": app.config['ELEVEN_LABS_API_KEY']
}
payload = {
"text": text,
"model_id": "eleven_monolingual_v1",
"voice_settings": {
"stability": 0.5, # 语音稳定性
"similarity_boost": 0.5 # 相似度增强
}
}
# 调用ElevenLabs API
response = requests.post(elevenlabs_url, headers=headers, json=payload)
if response.status_code != 200:
return jsonify({"error": f"语音生成失败, 状态码: {response.status_code}", "details": response.text}), 500
# 临时保存生成的语音文件
temp_dir = app.config['SPEECH_DIR']
os.makedirs(temp_dir, exist_ok=True)
temp_audio_path = f"./{temp_dir}/{uuid.uuid4()}.mp3"
with open(temp_audio_path, "wb") as f:
f.write(response.content)
# 返回生成的语音文件
return send_file(temp_audio_path, mimetype="audio/mpeg")
except Exception as e:
return jsonify({"error": str(e)}), 500
@app.errorhandler(413)
def request_entity_too_large(error):
"""文件过大错误处理"""
return jsonify({
"status": "error",
"agent": "系统",
"response": f"文件过大。最大允许大小: {config.api.max_image_upload_size}MB"
}), 413
@app.route('/send_validation', methods=['POST'])
def send_validation():
"""发送验证结果到后端"""
try:
# 获取表单数据
validation_result = request.form.get('validation_result')
comments = request.form.get('comments', '')
if not validation_result:
return jsonify({"error": "未提供验证结果"}), 400
# 获取会话cookie
session_cookie = request.cookies.get('session_id')
cookies = {}
if session_cookie:
cookies['session_id'] = session_cookie
# 转发数据到后端验证接口
fastapi_url = f"{app.config['API_URL']}/validate"
form_data = {
"validation_result": validation_result,
"comments": comments
}
response = requests.post(
fastapi_url,
data=form_data,
cookies=cookies
)
if response.status_code == 200:
result = response.json()
# 更新会话cookie(如果需要)
if 'session_id' in response.cookies:
resp = make_response(jsonify(result))
resp.set_cookie('session_id', response.cookies['session_id'])
return resp
return jsonify(result)
else:
return jsonify({
"error": f"后端API错误: {response.status_code}",
"details": response.text
}), response.status_code
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(host="0.0.0.0",debug=True, port=5000)6. 也可使用pycharm+Python虚拟环境集成和部署(可选)
选项 2:不使用 Docker
1️⃣ 克隆仓库
git clone https://github.com/souvikmajumder26/Multi-Agent-Medical-Assistant.git
cd Multi-Agent-Medical-Assistant 2️⃣ 创建并激活虚拟环境
- 如果使用 conda:
conda create --name <environment-name> python=3.11
conda activate <environment-name>- 如果使用 python venv:
python -m venv <environment-name>
source <environment-name>/bin/activate # For Mac/Linux
<environment-name>\Scripts\activate # For Windows 3️⃣ 安装依赖项
重要
语音服务需要 FFmpeg 才能正常工作。
- 如果使用 conda:
conda install -c conda-forge ffmpegpip install -r requirements.txt - 如果使用 python venv:
winget install ffmpegpip install -r requirements.txt 4️⃣ 设置 API 密钥
- 创建文件并添加所需的 API 密钥,如 所示。
.env``Option 1
5️⃣ 运行应用程序
- 在 activate 环境中运行以下命令。
python app.py申请地址为:http://localhost:8000
6️⃣ 将其他数据摄取到 Vector DB 中
根据需要执行以下任一命令。
- 要一次摄取一个文档:
python ingest_rag_data.py --file ./data/raw/brain_tumors_ucni.pdf- 要从目录中摄取多个文档:
python ingest_rag_data.py --dir ./data/raw✨ 项目的主要特点
-
🤖 多代理架构 : 大模型协助,代理协同工作,处理诊断、信息检索、推理等
-
🤖 多交流联系 : 扣扣2551931023(备注用途来意),微微交流ZQZ2551931023,处理诊断、信息检索
-
🔍 高级代理 RAG 检索系统:
- 基于 Docling 的解析,用于从 PDF 中提取文本、表格和图像。
- 嵌入 Markdown 格式的文本、表格和基于 LLM 的图像摘要。
- 具有结构边界感知的基于 LLM 的语义分块。
- 基于 LLM 的查询扩展,包含相关的医学领域术语。
- Qdrant 混合搜索结合了 BM25 稀疏关键字搜索和密集嵌入向量搜索。
- 基于 HuggingFace 跨编码器对检索到的文档块进行重新排序,以获得准确的 LLM 响应。
- 输入输出护栏,确保安全和相关的响应。
- 指向随 repence 提供的参考文档块中存在的源文档和图像的链接。
- RAG 和 Web 搜索之间基于置信度的代理到代理切换,以防止幻觉。
-
🏥 医学影像分析
- 脑肿瘤检测 (TBD)
- 胸部 X 线疾病分类
- 皮肤病变分割
-
🌐 实时研究集成 : 检索最新医学研究论文和发现的 Web 搜索代理
-
📊 基于置信度的验证 : 对数概率分析确保医疗建议的高精度
-
🎙️ 语音交互功能 : 由 Eleven Labs API 提供支持的无缝语音转文本和文本转语音
-
👩 ⚕️ 专家监督系统 : 在最终确定输出之前,由医疗专业人员进行人机回圈验证
-
⚔️ 输入和输出防护栏:确保安全、公正和可靠的医疗反应,同时过滤掉有害或误导性内容
-
💻 直观的用户界面 : 专为技术专业知识最少的医疗保健专业人员设计
最终效果
Agent Medical 是一个 AI 驱动的聊天机器人 ,旨在协助医疗诊断、研究和患者互动。
🚀 该系统集成了:
- 🤖 大型语言模型 (LLM)
- 用于医学成像分析的计算机视觉模型 🖼️
- 利用向量数据库的检索增强生成 (RAG) 📚
- 🌐 实时 Web 搜索,获取最新的医学见解
- 👨 ⚕️ 人机协同验证,用于验证基于 AI 的医学影像诊断
您将从该项目📖中学到什么(交流博主主页有联系)
🔹 具有结构化图形工作流
🔹的多代理编排 先进的RAG技术 - 混合检索、语义分块和向量搜索 基于信心的路由和代理到代理的切换 可扩展的、生产就绪的人工智能,带有模块化代码和强大的异常处理能力 👨 💻