集成学习方法之随机森林
- [1 集成学习](#1 集成学习)
- [2 随机森林的算法原理](#2 随机森林的算法原理)
-
- [2.1 Sklearn API](#2.1 Sklearn API)
- [2.2 示例](#2.2 示例)
1 集成学习
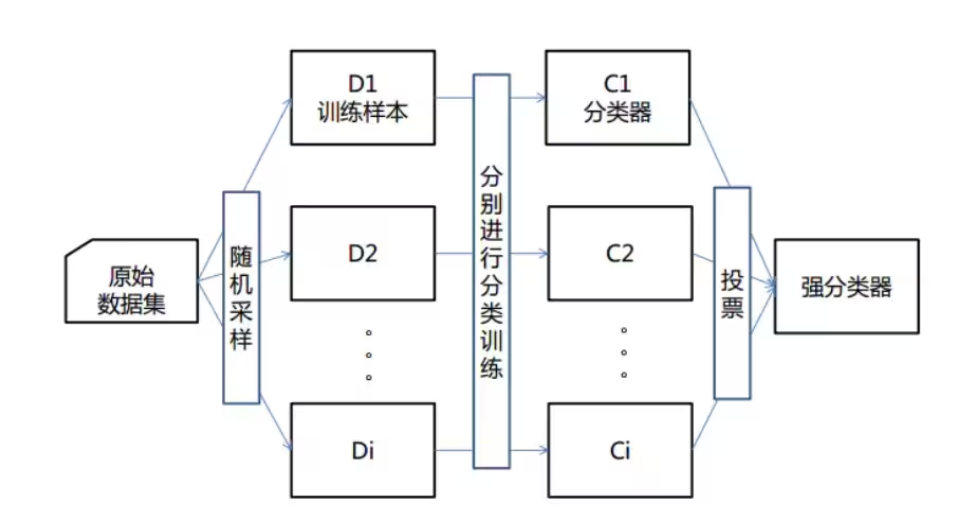
机器学习中有一种大类叫集成学习 (Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。集成算法大致可以分为:Bagging,Boosting 和 Stacking 三大类型。
(1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
(2)利用新的训练集,训练得到M个子模型;
(3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;
2 随机森林的算法原理
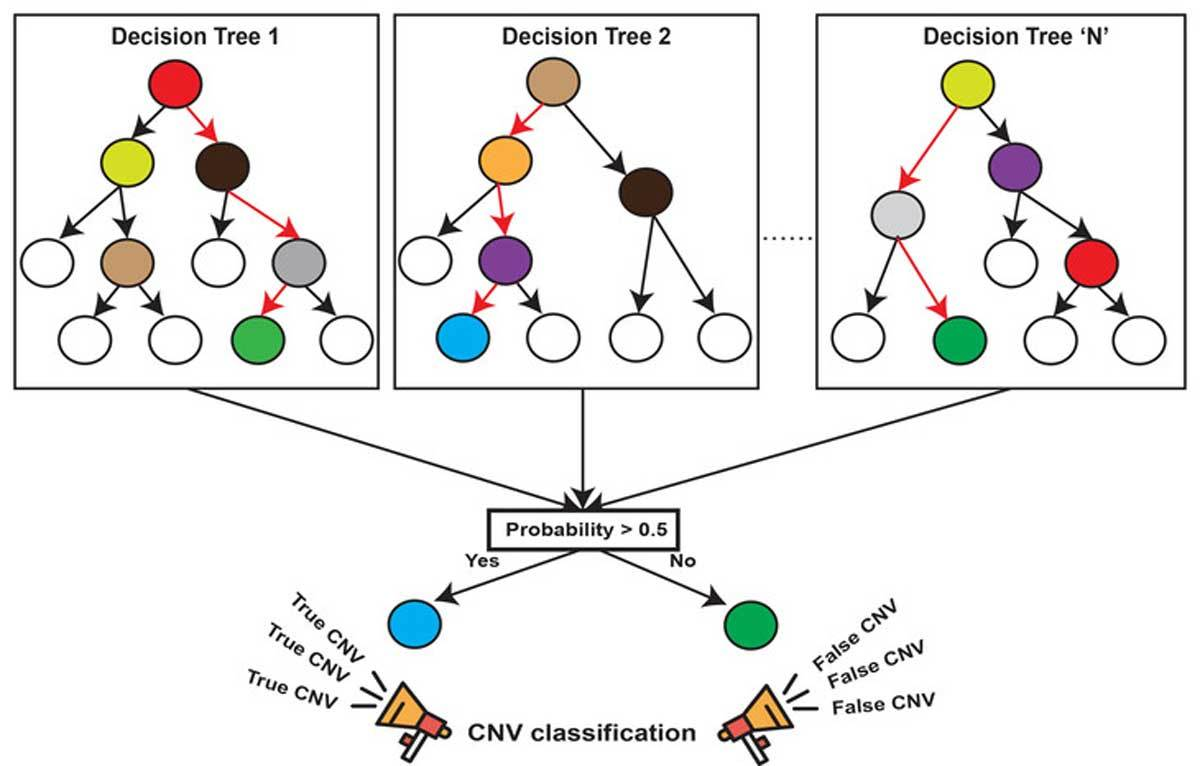
随机森林 就属于集成学习,是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林, 每棵树都在不同的数据子集和特征子集上进行训练,最终通过投票或平均预测结果来产生更准确和稳健的预测。这种方法不仅提高了预测精度,也降低了过拟合风险,并且能够处理高维度和大规模数据集
特点:
- 随机: 特征随机,训练集随机
- 样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
- 特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
- 森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
- 处理具有高维特征的输入样本,而且不需要降维
- 使用平均或者投票来提高预测精度和控制过拟合
2.1 Sklearn API
class sklearn.ensemble.RandomForestClassifier
参数:
n_estimators int, default=100
森林中树木的数量。(决策树个数)
criterion {"gini", "entropy"}, default="gini" 决策树属性划分算法选择
当criterion取值为"gini"时采用 基尼不纯度(Gini impurity)算法构造决策树,
当criterion取值为 "entropy" 时采用信息增益( information gain)算法构造决策树.
max_depth int, default=None 树的最大深度。 2.2 示例
坦尼克号乘客生存
代码如下:
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import joblib
def train():
# 数据集加载
titanic=pd.read_csv(r"..\22day4.25机器学习\src\titanic\titanic.csv")
# 数据集处理
#获取关键特征
titanic=titanic[['age','pclass','sex','survived']]
# 将其中的缺省值赋值为这个列的平均值
titanic["age"].fillna(titanic["age"].mean(),inplace=True)
# 获取特征值和目标值
x=titanic[['age','pclass','sex']]
y=titanic[['survived']].to_numpy()
# 将x转化为字典
x=x.to_dict(orient='records')
# 字典向量化
vac=DictVectorizer(sparse=True)
x=vac.fit_transform(x).toarray()
# 划分数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=22,shuffle=True)
# 标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_train)
print(x_test.shape,y_test.shape)
# 模型建立
model=RandomForestClassifier(n_estimators=10,max_depth=4)
# 训练模型
model.fit(x_train,y_train)
# 模型评估
score=model.score(x_test,y_test)
print(score)
# 保存模型
joblib.dump(model,r"..\23day5.8\src\model\rf.pkl")
joblib.dump(transfer,r"..\23day5.8\src\model\rf_transfer.pkl")
joblib.dump(vac,r"..\23day5.8\src\model\rf_vac.pkl")
def detect():
model=joblib.load(r"..\23day5.8\src\model\rf.pkl")
transfer=joblib.load(r"..\23day5.8\src\model\rf_transfer.pkl")
vac=joblib.load(r"..\23day5.8\src\model\rf_vac.pkl")
x_test=[{'age':24,'pclass':'1st','sex':"male"}]
x_test=vac.transform(x_test).toarray()
# print(x_test)
x_test=transfer.transform(x_test)
prd=model.predict(x_test)
print(prd)
if __name__=="__main__":
train()
# predict()
detect()