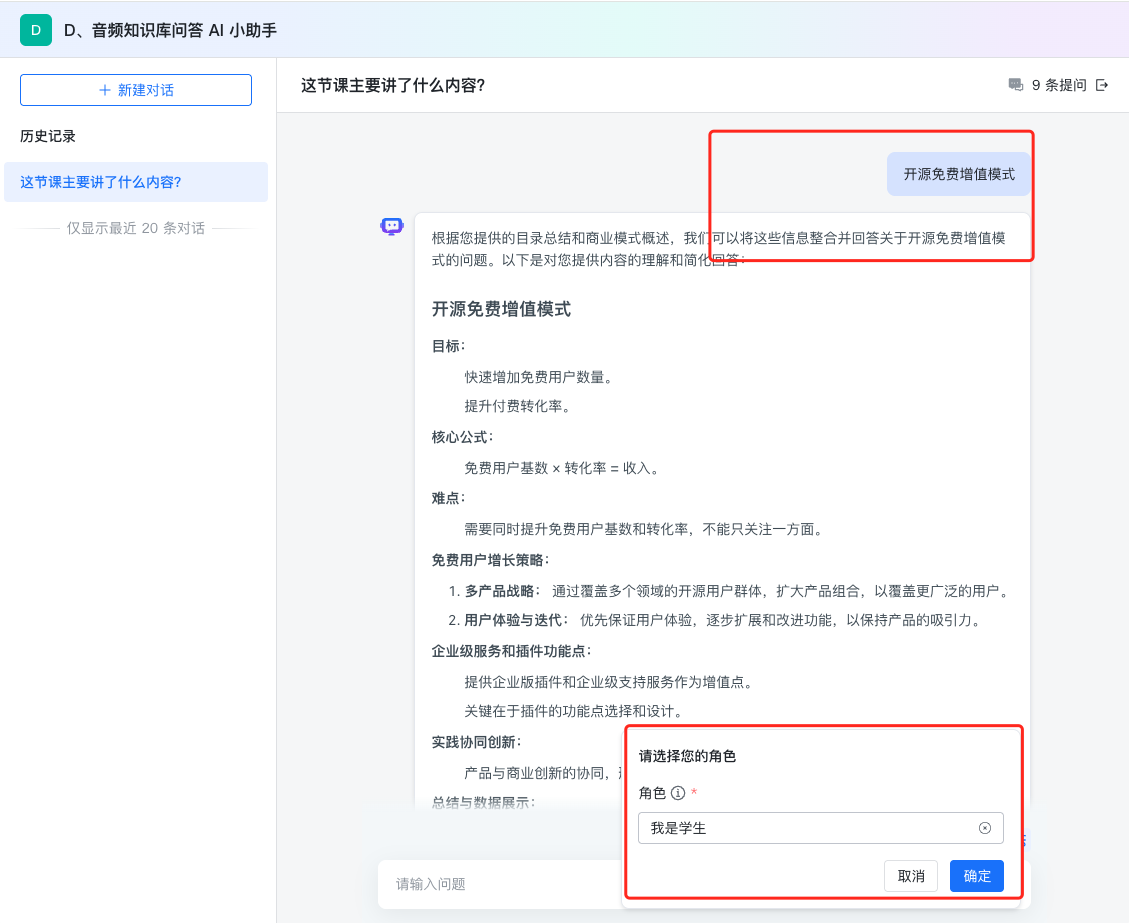
今天给大家分享一个教学的 AI 使用场景,主要用来解决课堂老师实时讲解的内容如何让学生快速了解学习。
一、教学场景说明:
课堂上老师上完课后,课堂实时讲解的内容,部分与教材或者课件有偏差(临场发挥),希望通过AI小助手将这部分知识沉淀总结下来。方便学生了解回顾。
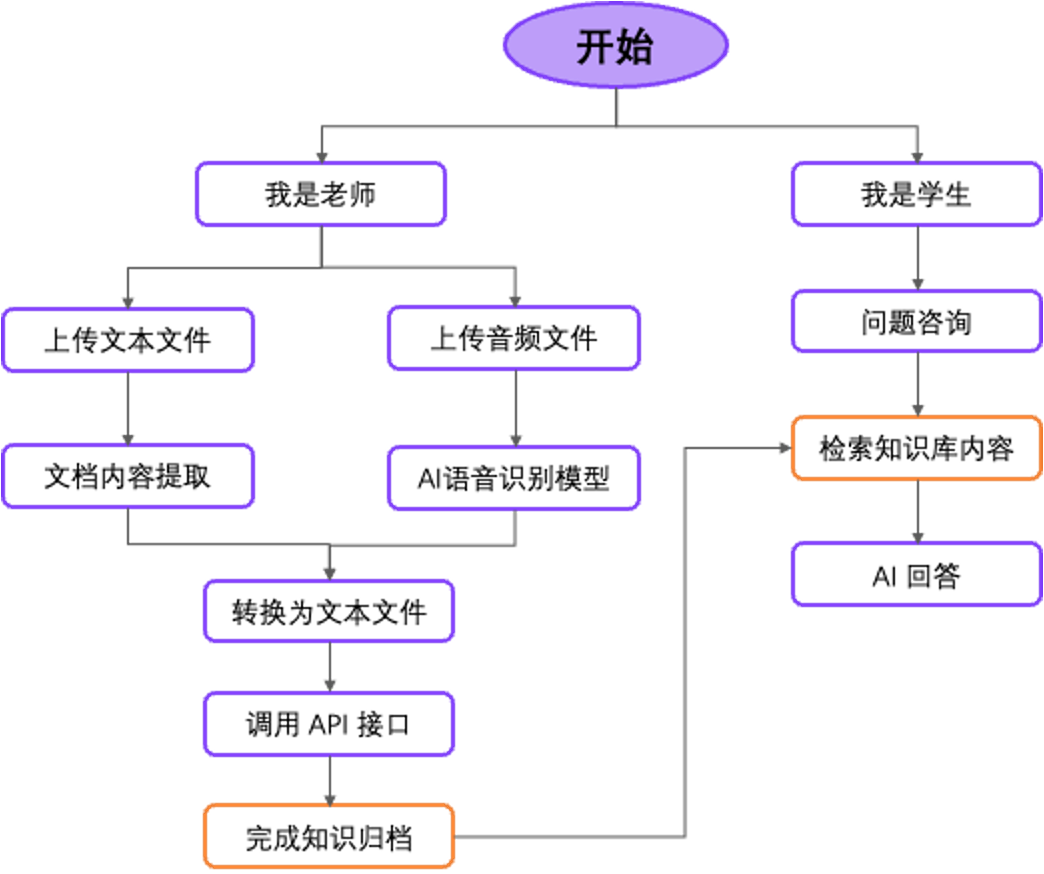
二、AI 流程设计说明:
该 AI 小助手同时被老师和学生使用,然后进入小助手之后先选择
三、使用的 AI 应用平台
MaxKB:强大易用的企业级 AI 助手(开源)
更多信息:https://maxkb.cn/
四、涉及模型及组件
4.1大语言模型:
本次使用的是阿里云百炼大语言模型,实现 AI 问答;对接说明参见:https://maxkb.cn/docs/user_manual/model/bailian_model/
4.2语音识别模型
阿里云百炼语音识别模型,实现语音转文本;
对接说明:https://maxkb.cn/docs/user_manual/model/bailian_model/
4.3文档内容提取
实现将文档内容提取文本信息,详细操作说明参见:https://maxkb.cn/docs/user_manual/app/workflow_app/#112
4.4语音转文本
将音频文件通过模型转换为文本文件。具体操作说明参见:https://maxkb.cn/docs/user_manual/app/workflow_app/#113
4.5文档生成函数:
负责将语音识别到的文本和文档内容提取到的文本信息转换成word 文档。
详细函数代码如下所示:
import requests
def convert_markdown_to_word(markdown_text):
"""
发送 Markdown 文本到指定的 API,并获取生成的 Word 文件的下载链接
:param markdown_text: Markdown 格式的文本
:param api_url: API 的 URL
:return: Word 文件的下载链接
"""
# pandoc-api 部署 pandoc-api 的服务器的URL地址
api_url = "http://ip:5000/convert"
# 构造请求数据
data = {
"markdown": markdown_text
}
# 发送 POST 请求
response = requests.post(api_url, json=data)
# 检查响应状态
if response.status_code == 200:
# 解析 JSON 响应
response_data = response.json()
if 'download_url' in response_data:
# 返回下载链接
return response_data['download_url']
else:
return "Error: 'download_url' not found in the response"
else:
# 返回错误信息
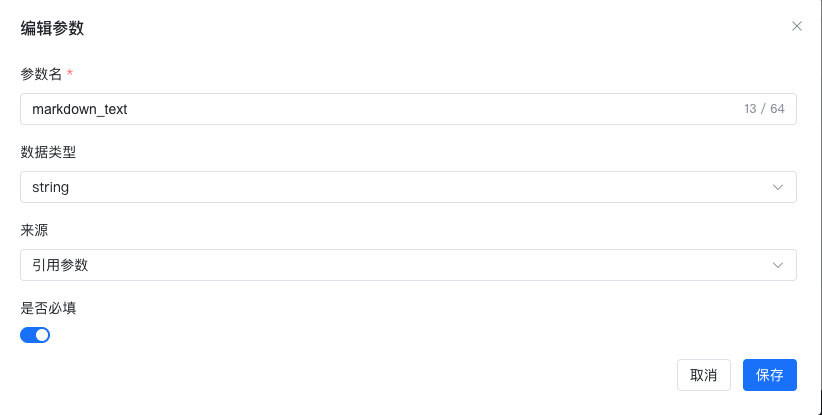
return f"Error: {response.status_code}, {response.text}"其中将markdown_test设置成输入参数,具体参见如下:
4.6知识库导入 API 调用函数:
将文档生成函数生成word文档通过Python函数调用 API 接口导入到MaxKB的知识库中。
详细函数代码如下所示:
import requests
import json
def main(user_key,dataset_id,file_name,audio_name):
# 使用字符串的 split 方法截取 /download/ 后面的内容
file_name = file_name.split("/download/")[1]
# 定义下载链接(文档生产函数中的文档上传地址)和目标路径
url = "http://IP:5000/download/"+file_name
maxkb_filename = audio_name[0].get('name')+"-"+file_name;
# 从pan-doc下载的文件,重新命名为录音文件的原名
target_path = "/opt/maxkb/app/sandbox/python-packages/"+ maxkb_filename
try:
# 发送 GET 请求下载文件
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
# 将文件内容写入目标路径
with open(target_path, "wb") as file:
file.write(response.content)
print(f"文件已成功下载到 {target_path}")
except requests.exceptions.RequestException as e:
print(f"下载失败:{e}")
print("请检查链接的合法性或网络连接,并稍后重试。")
# 目标 MaxKB URL访问地址
url = "https://域名/api/dataset/document/split"
# 请求头
headers = {
"accept": "application/json",
"AUTHORIZATION": user_key
}
# 要上传的文件
files = {
"file": (maxkb_filename, open(target_path, "rb"), "text/plain")
}
# 发送 POST 请求
response = requests.post(url, headers=headers, files=files)
# 打印响应内容
print("Response Status Code:", response.status_code)
print("Response Content:", response.json())
#根据指定知识库id,开始创建分段
# 目标 MaxKB URL访问地址
url = "https://域名/api/dataset/"+dataset_id+"/document/_bach"
# 请求头
headers = {
"accept": "application/json",
"AUTHORIZATION": user_key,
"Content-Type": "application/json"
}
# 请求数据
data = response.json().get("data")
# 将第一个content重命名为paragraphs
data[0]["paragraphs"] = data[0].pop("content")
# 发送 POST 请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 打印响应内容
print("Response Status Code:", response.status_code)
print("Response Content:", response.text)
return response.text添加函数输入参数,如下图所示:
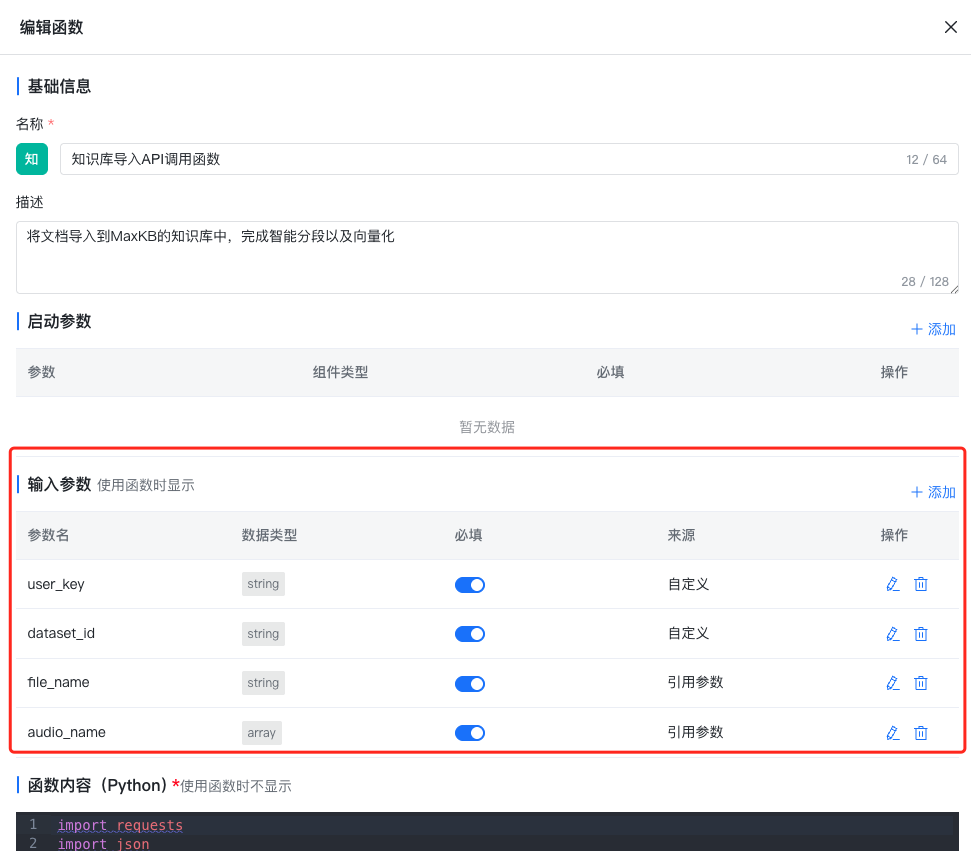
其中user_id和dataset_id的含义以及获取方式如下所示:
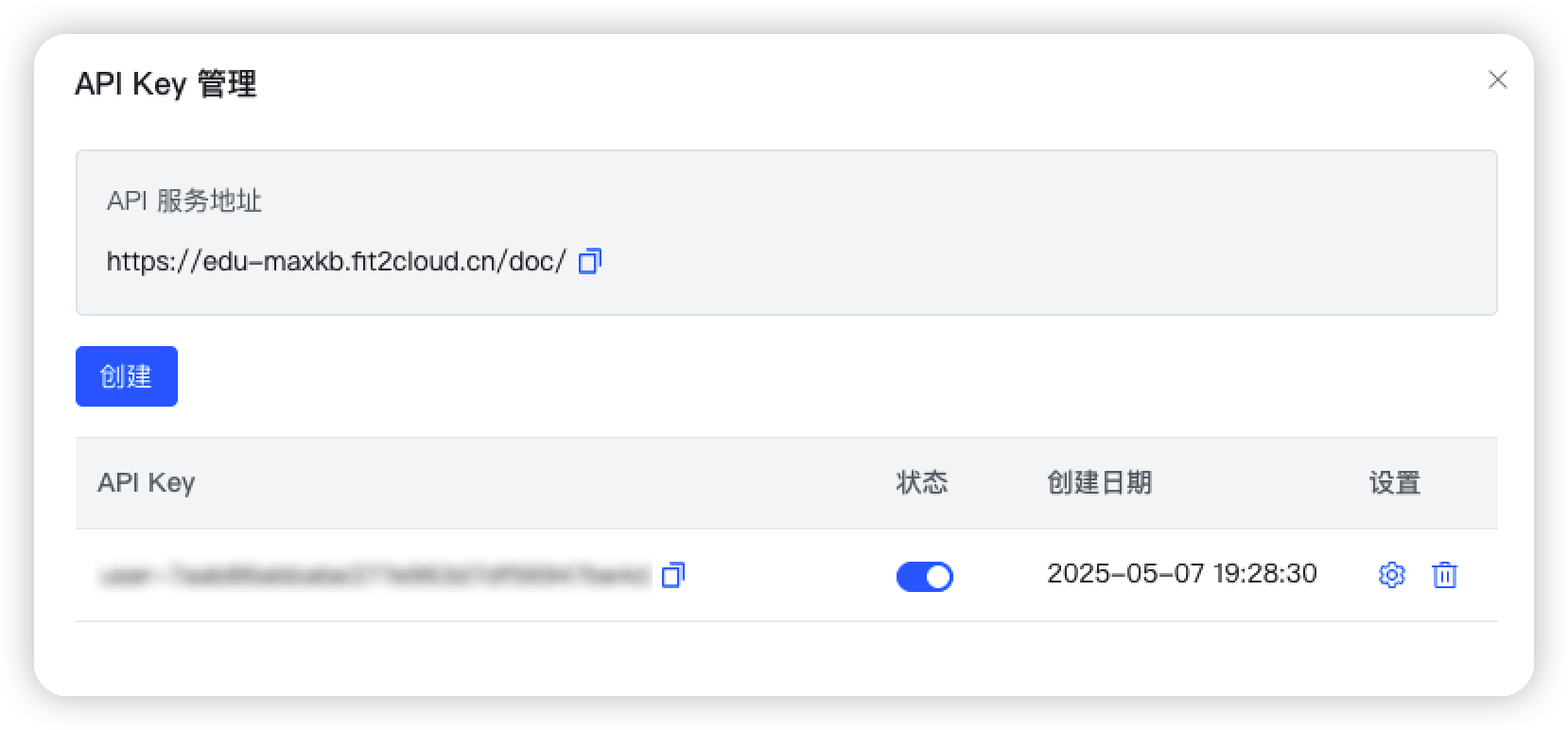
1、user_key 为调用 MaxKB 的key,参见如下截图到MaxKB中获取:
- 第一步:进入 api key 管理
- 第二步:创建专属于自己的user_key
2、dataset_id 是语音知识库需要上传的指定 MaxKB 知识库,参照以下步骤完成。
- 第一步:基于 MaxKB 创建一个通用型知识库,里面内容为空即可。参见如下截图:
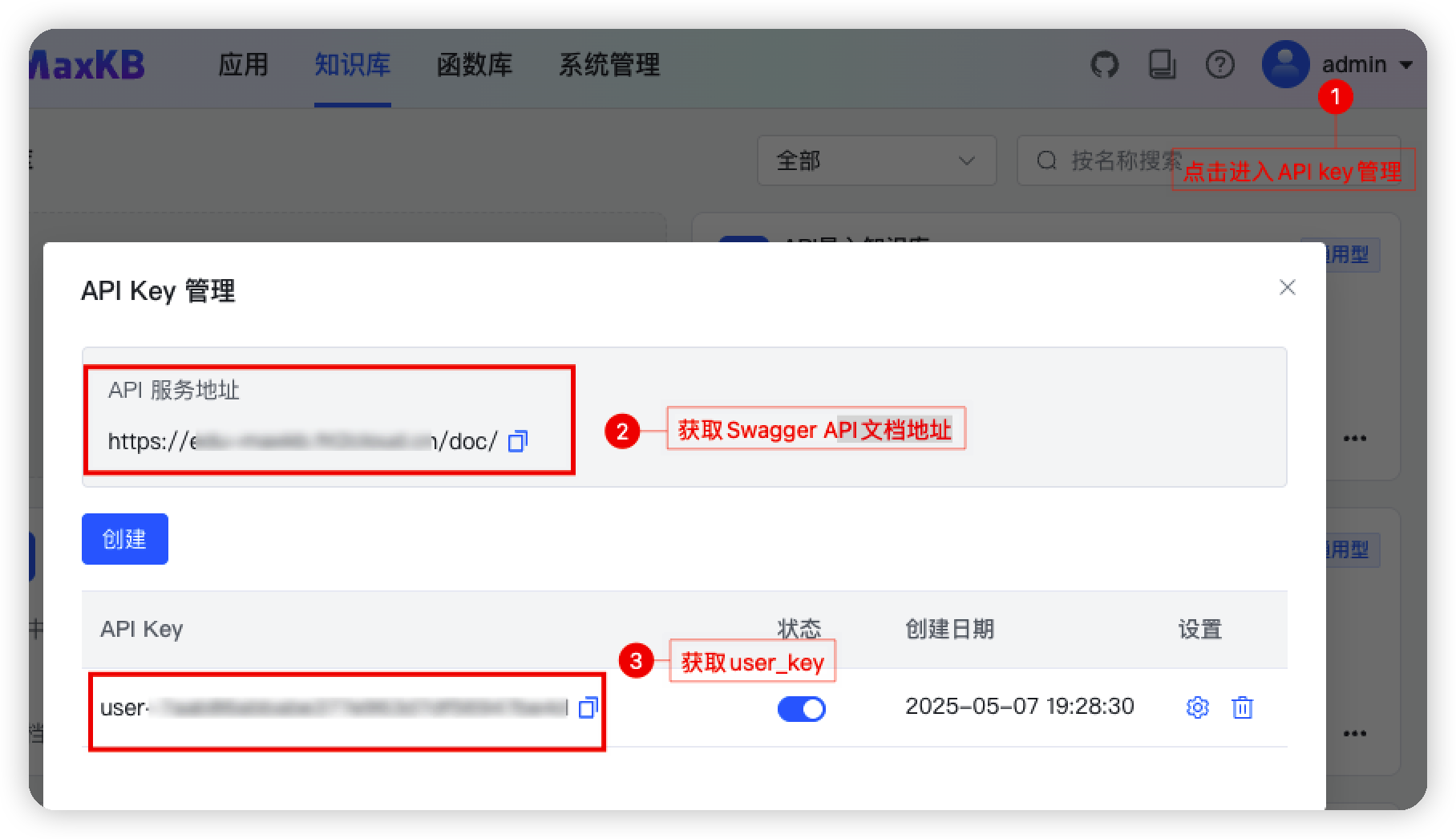
- 第二步:进入 MaxKB 的 Swagger API 文档,如下图获取访问地址以及user_key
-
第三步:进入 Swagger API 文档,进入授权输入user_key。
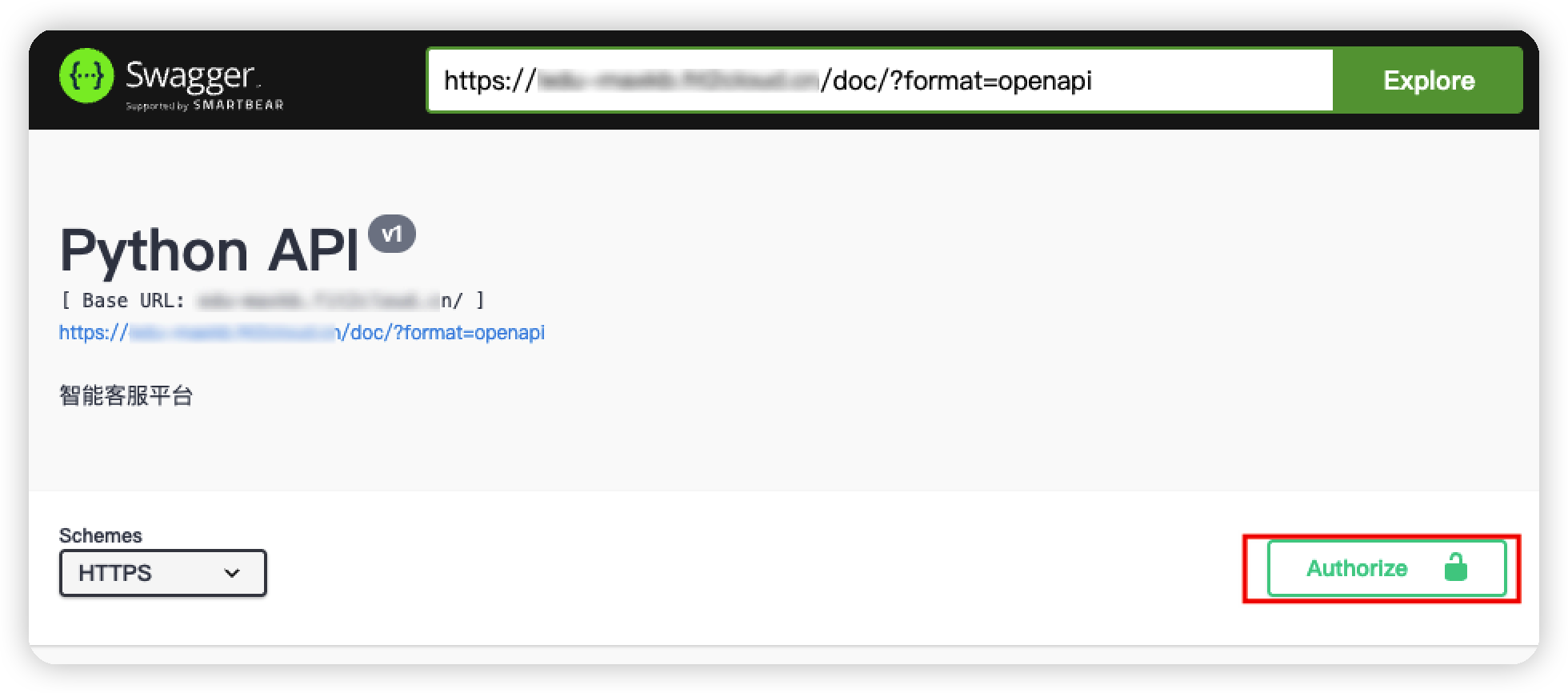
-
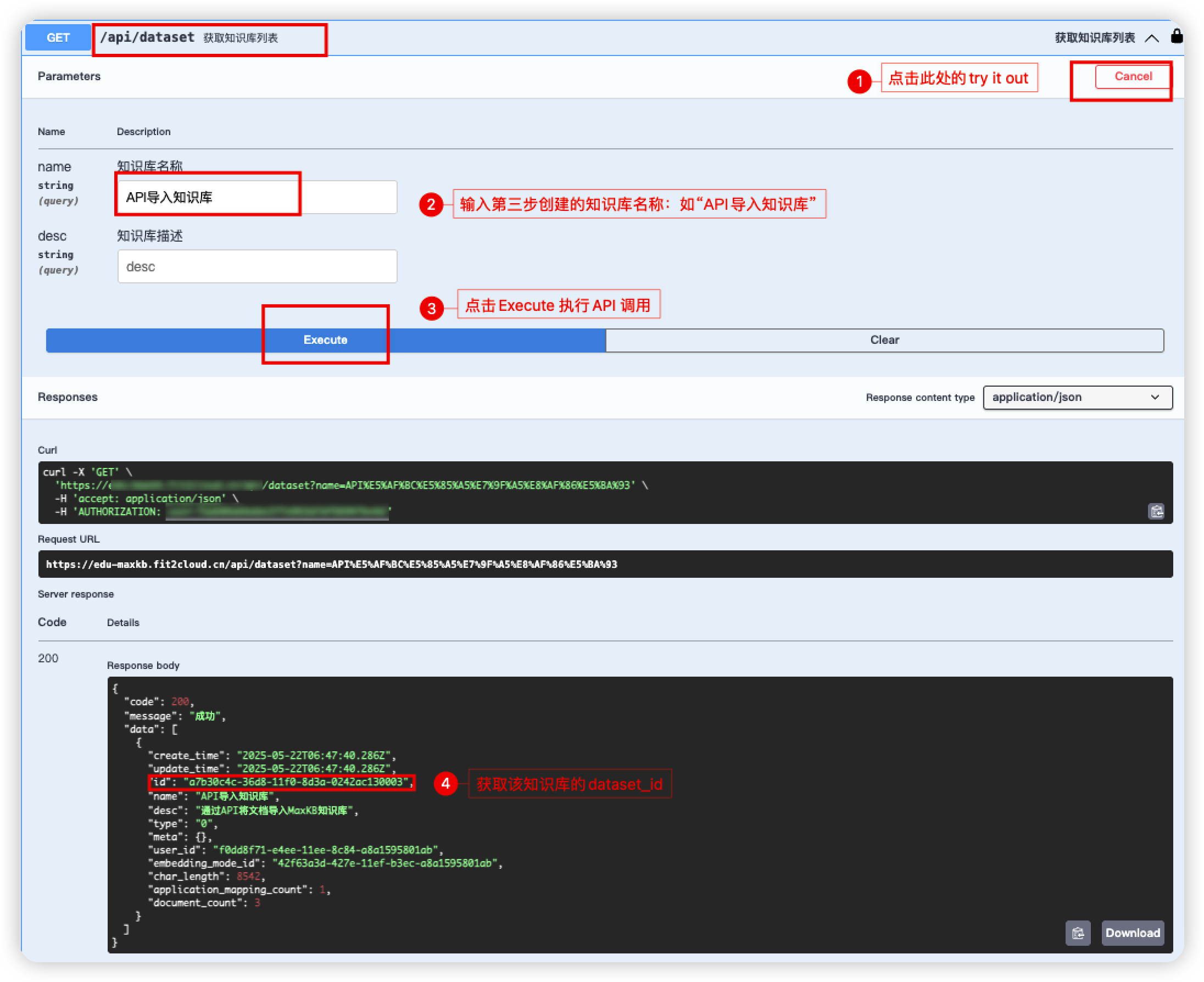
第四步:找到知识库查询的API接口,/api/dataset/ (获取知识库列表)
参照以下截图获取到 dataset_id 即可。
五、AI 工作流编排
本次涉及两个工作流编排,其中一个 AI 工作流实现知识库入库,另一个 AI 工作流实现问答,两者相互引用满足不通角色的小助手使用。
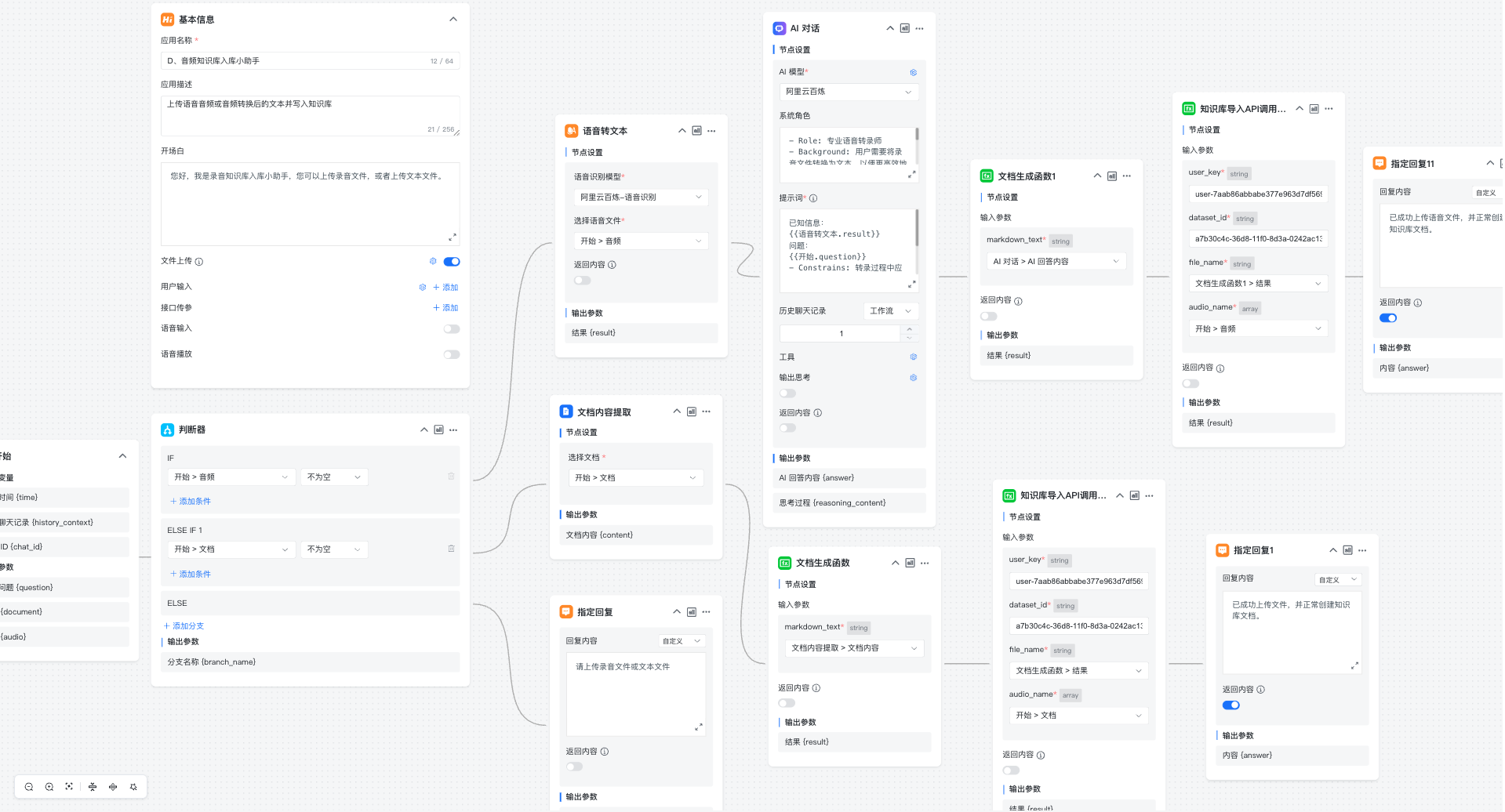
AI 工作流一:音频知识库入库小助手
如下图所示将相关节点创建完成即可。
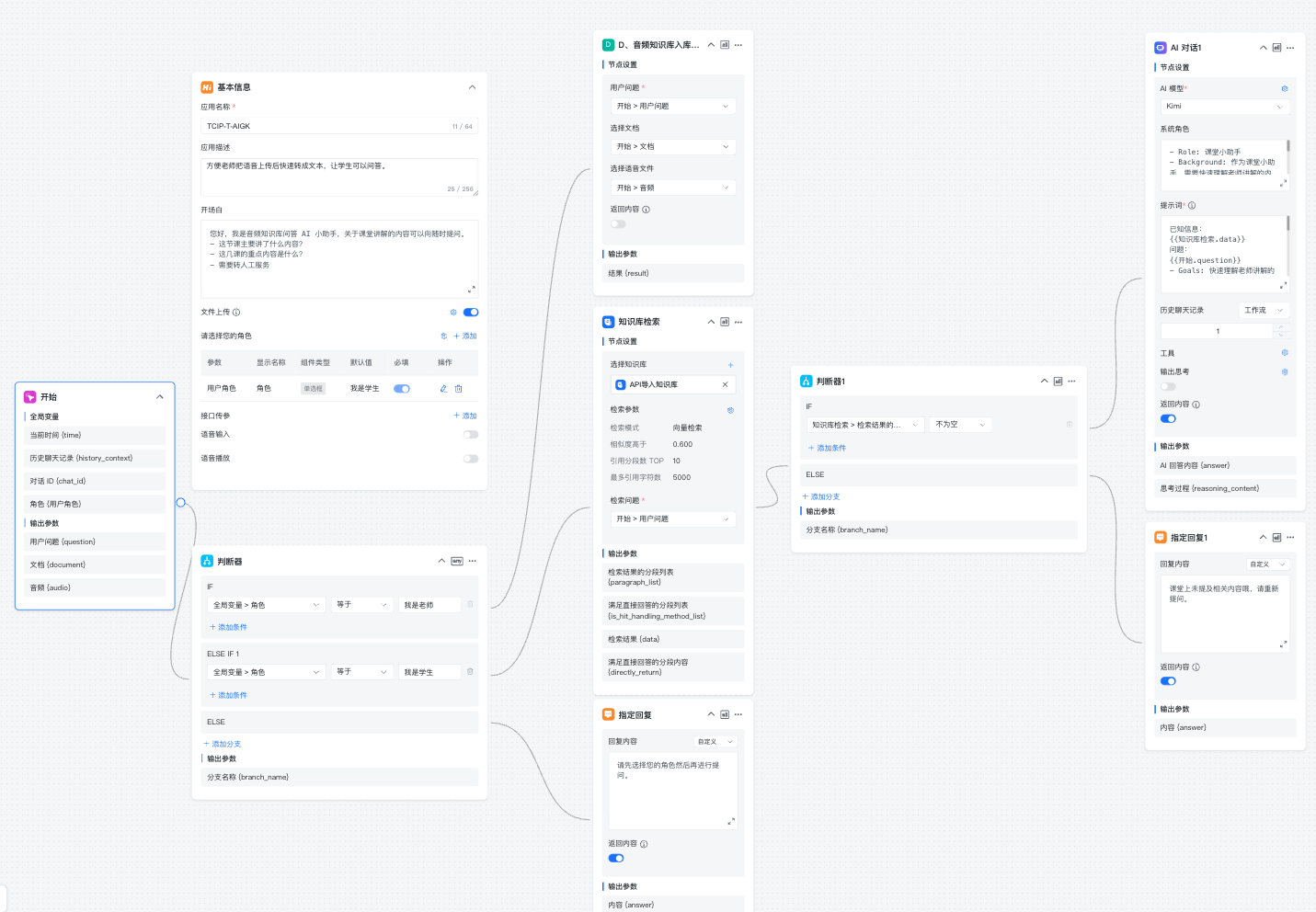
AI 工作流二:TCIP-T-AIGK
根据以下流程图编排相关 AI 工作流
其中 AI 工作流的基本信息中需要打开文件上传和设置用户输入参数,如下图所示:
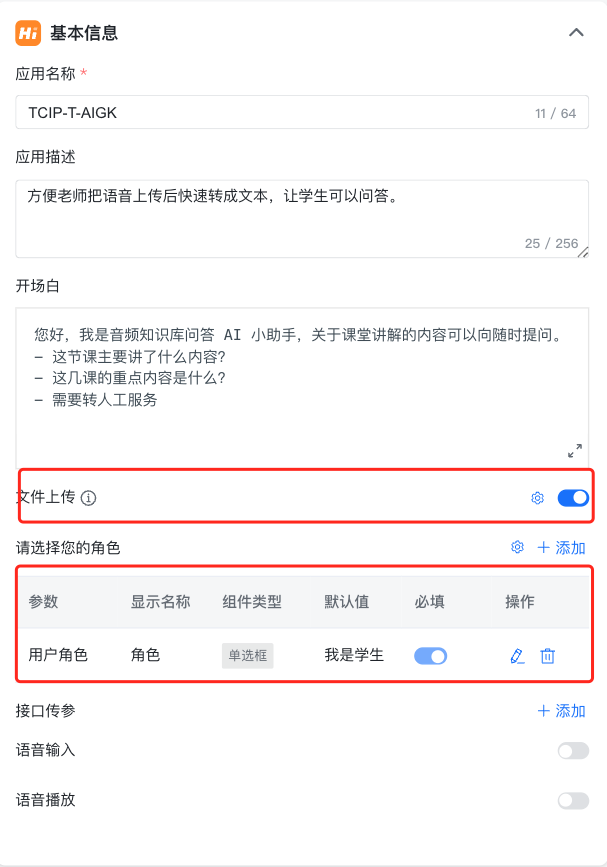
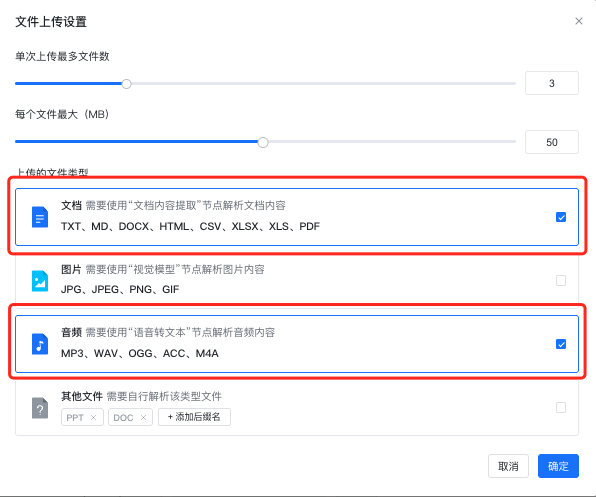
- 1、基本信息中需要打开文件上传,并同时支持文档和音频文件上传
- 2、用户输入点击添加用户角色参数,如下图所示:
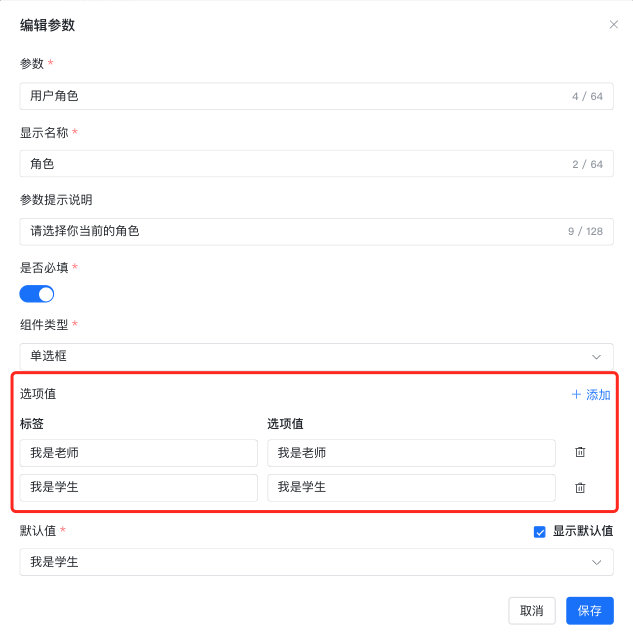
同时需要将用户输入的名称信息改为请选择你的身份。
六、AI 教学助手演示
选择角色:进入 AI 教学助手页面,选择角色。
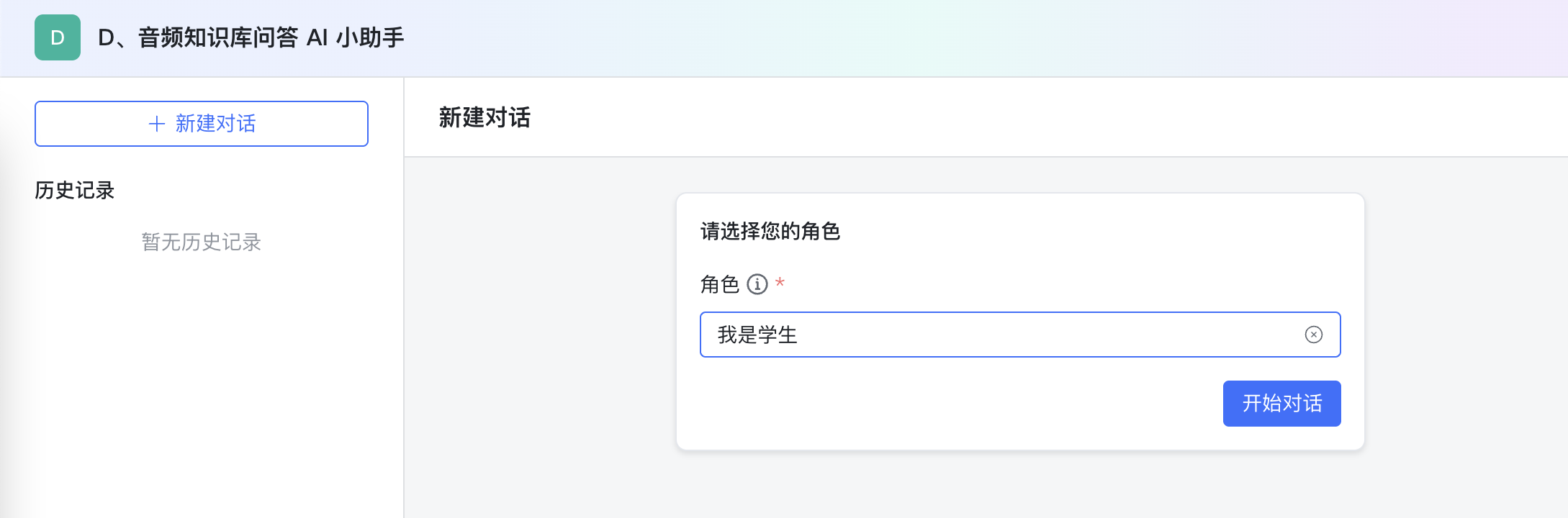
角色一:我是老师,点击上传文档或者音频文件,输入开始,点击发送,如下图所示知识库创建。
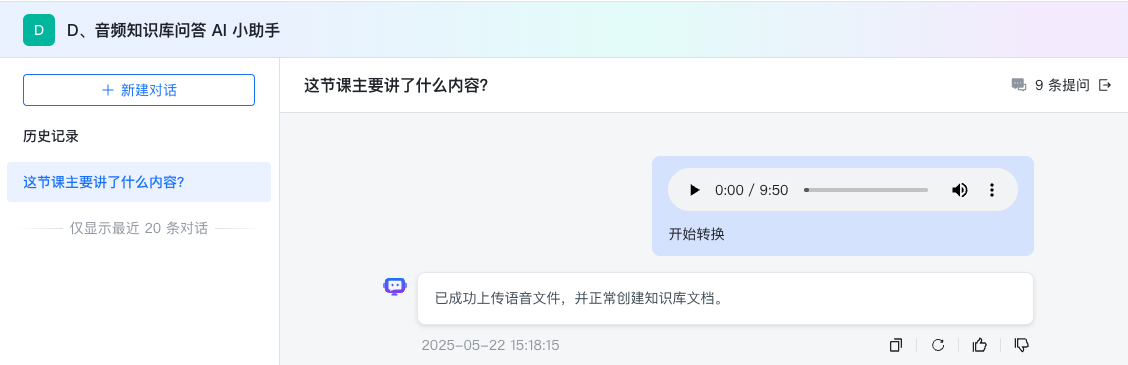
角色二:我是学生,提出问题,然后点击发送。