
for range 中赋值的变量,这个变量指向的是真实的地址吗,还是临时变量
不是真实地址,是临时变量
go
package main
import "fmt"
func main() {
slice := []int{4, 2, 3}
for _, v := range slice {
fmt.Println(v, &v) // 这里的 v 是临时变量
}
for i := range slice{
fmt.Println(i, &i)
fmt.Println(slice[i], &slice[i])
}
fmt.Println("sjhdjaskhdjkashdkas")
for _, v := range slice {
fmt.Println(v, &v) // 这里的 v 是临时变量
}
for i := range slice{
fmt.Println(i, &i)
fmt.Println(slice[i], &slice[i])
}
}如果在for range里面有一个函数,这个函数需要传一个指针,这时候应该怎么写,这时候会进行拷贝吗
slice内容未改变, 换成另一个方法才会改变
for _,v := range x
是值拷贝
go
package main
import "fmt"
func main() {
slice := []int{4, 2, 3}
for _,v := range slice{
fmt.Println(v, &v)
doDubole(&v)
fmt.Println(v, &v)
}
fmt.Println(slice)
}
func doDubole(x *int){
fmt.Println(*x, x)
*x = *x*2
}有用过go link?那么在什么情况下如果我不赋给一个新的变量,它也是没问题的?
在 Go 语言中,link 通常指的是链接操作,主要用于将多个包和可执行文件组合成一个单一的可执行文件。
如果我要在defer里面修改return里面的值呢?这时怎么写?
命名返回值
返回110
go
package main
import "fmt"
func main() {
ans := get(10)
fmt.Println(ans)
}
func get(x int)(ans int){
defer func(){
ans += 10
}()
ans = x*10
return
}map时协程安全吗?有什么是协程安全的?
在 Go 中,map 不是协程安全的。如果多个协程同时读写同一个 map,可能会导致数据竞争和不确定的行为。因此,使用 map 时需要确保并发安全。
协程安全的解决方案:
-
使用
sync.Mutex或sync.RWMutex:- 通过互斥锁确保对
map的访问是安全的。
govar mu sync.Mutex m := make(map[string]int) func safeWrite(key string, value int) { mu.Lock() m[key] = value mu.Unlock() } func safeRead(key string) int { mu.Lock() value := m[key] mu.Unlock() return value } - 通过互斥锁确保对
-
使用
sync.Map:- Go 提供了一个内置的并发安全的
map类型sync.Map,适合并发读写。
govar m sync.Map // 存储值 m.Store("key", 42) // 读取值 value, ok := m.Load("key") - Go 提供了一个内置的并发安全的
-
使用通道 (Channels):
- 通过通道来同步对数据的访问,而不是直接操作
map。
gotype request struct { key string value int reply chan int } func mapHandler(requests <-chan request) { m := make(map[string]int) for req := range requests { m[req.key] = req.value req.reply <- m[req.key] } } - 通过通道来同步对数据的访问,而不是直接操作
总结:
map在并发环境下不安全。- 使用互斥锁、
sync.Map或通道可以实现协程安全。
channel有缓冲区和无缓冲区的区别?
无缓冲:必须有人接收才能发送,需要保证顺序性
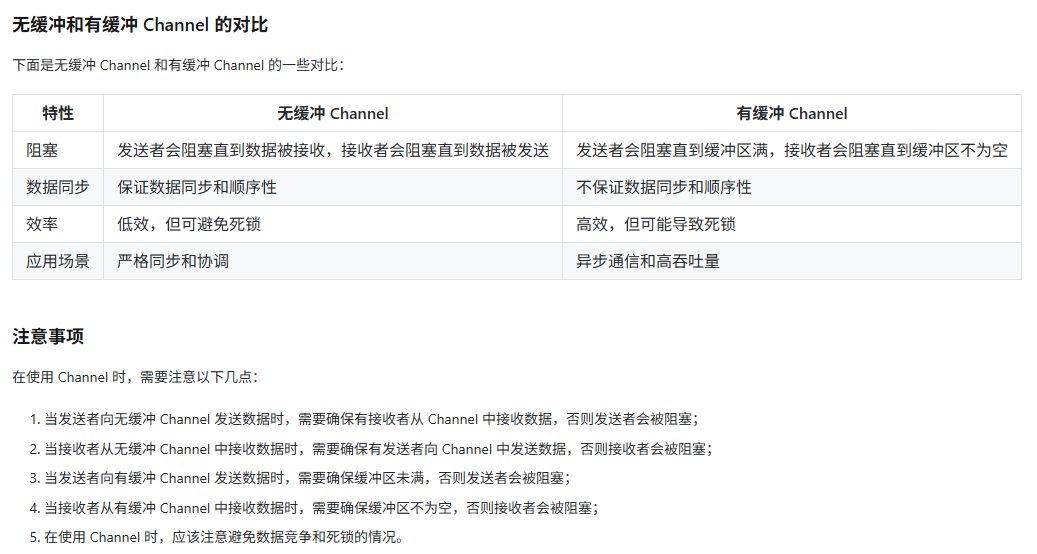
以下是有缓冲区和无缓冲区通道的实际应用场景示例。
1. 有缓冲区的通道:任务队列
在一个工作池中,多个工作者从一个任务队列中获取任务。使用有缓冲区的通道可以存储一定数量的任务,提高效率。
go
package main
import (
"fmt"
"time"
)
func worker(id int, tasks <-chan int) {
for task := range tasks {
fmt.Printf("工作者 %d 处理任务 %d\n", id, task)
time.Sleep(time.Second) // 模拟任务处理时间
}
}
func main() {
tasks := make(chan int, 5) // 创建一个缓冲区为 5 的通道
// 启动多个工作者
for i := 1; i <= 3; i++ {
go worker(i, tasks)
}
// 发送任务
for i := 1; i <= 10; i++ {
fmt.Printf("发送任务 %d\n", i)
tasks <- i
time.Sleep(500 * time.Millisecond) // 模拟任务生成时间
}
close(tasks) // 关闭通道
time.Sleep(5 * time.Second) // 等待所有任务完成
}2. 无缓冲区的通道:同步信号
在两个 goroutine 之间使用无缓冲区通道进行同步,确保一个 goroutine 在另一个完成后再继续执行。
go
package main
import (
"fmt"
)
func main() {
done := make(chan struct{}) // 创建一个无缓冲区的信号通道
go func() {
fmt.Println("工作者正在处理任务...")
// 模拟任务处理
// ...
done <- struct{}{} // 发送完成信号
}()
// 等待工作者完成
<-done
fmt.Println("任务完成,主程序继续执行。")
}总结
- 有缓冲区的通道适用于任务队列等场景,可以提高并发性能。
- 无缓冲区的通道适用于需要同步的场景,确保操作的顺序。
我能不能在写入channel的时候,先判断它阻不阻塞再写?
在 Go 中,无法直接检查一个通道是否会阻塞。通道的发送和接收都是阻塞操作,具体行为取决于通道的状态和接收方是否准备好。
解决方案
如果你想在写入通道之前判断是否会阻塞,可以使用非阻塞发送配合 select 语句。例如:
go
package main
import (
"fmt"
)
func main() {
ch := make(chan int, 1) // 创建一个缓冲通道,容量为 1
// 先尝试发送
select {
case ch <- 42: // 非阻塞发送
fmt.Println("写入成功")
default:
fmt.Println("通道已满,写入阻塞")
}
// 再次尝试发送
select {
case ch <- 99:
fmt.Println("写入成功")
default:
fmt.Println("通道已满,写入阻塞")
}
// 从通道读取值
value := <-ch
fmt.Println("读取值:", value)
}关键点:
select语句:允许你进行非阻塞操作。default分支:在通道不能发送或接收时执行,避免阻塞。
通过这种方式,你可以在写入通道之前判断通道的状态,从而避免阻塞。
mutex是个悲观锁还是乐观锁,乐观锁和悲观锁的区别?
Mutex 是悲观锁,适用于高冲突的场景。
乐观锁 适用于低冲突的场景,减少了加锁带来的性能开销。
需要知道一个goroutine里面的一个函数是否执行成功还是失败,应该怎么写
要在一个 goroutine 中检查一个函数是否执行成功,可以使用通道(channel)来传递结果或错误信息。以下是一个示例,演示如何实现这一点:
示例代码
go
package main
import (
"errors"
"fmt"
"time"
)
func doWork(resultChan chan<- string, errChan chan<- error) {
// 模拟一些工作
time.Sleep(2 * time.Second)
// 假设工作成功,返回结果
// resultChan <- "工作成功"
// 假设工作失败,返回错误
errChan <- errors.New("工作失败")
}
func main() {
resultChan := make(chan string)
errChan := make(chan error)
go doWork(resultChan, errChan)
select {
case result := <-resultChan:
fmt.Println("结果:", result)
case err := <-errChan:
fmt.Println("错误:", err)
case <-time.After(3 * time.Second): // 设置超时
fmt.Println("操作超时")
}
}关键点
-
通道:
- 使用
resultChan来传递成功结果。 - 使用
errChan来传递错误信息。
- 使用
-
select语句:- 通过
select等待通道中的结果或错误。 - 如果有结果返回,则打印结果;如果有错误返回,则打印错误。
- 通过
-
超时处理:
- 可以使用
time.After设置超时处理,避免等待太久。
- 可以使用
通过这种方式,你可以有效地在 goroutine 中检查函数的执行状态。
了解过Go的内存逃逸吗?
是的,Go 的内存逃逸(Escape Analysis)是一个重要的功能,用于优化内存分配和管理。
什么是内存逃逸?
内存逃逸指的是在 Go 中某个变量的生命周期超出了其原本的作用域。这意味着该变量不能在栈上分配,而必须在堆上分配,以确保在函数返回后仍然能够访问。
如何工作?
-
栈 vs 堆:
- 栈:用于存储局部变量,分配和释放速度快,但生命周期受限于函数调用。
- 堆:用于动态分配内存,生命周期更长,但分配和释放速度较慢。
-
逃逸分析:
- Go 编译器会在编译时分析变量的使用情况,判断它是否会"逃逸"到堆上。
- 如果变量的地址被返回,或在函数外部使用,它将被分配到堆上。
示例
以下是一个简单的例子,展示了内存逃逸的情况:
go
package main
import "fmt"
type Person struct {
Name string
}
func NewPerson(name string) *Person {
return &Person{Name: name} // 逃逸到堆
}
func main() {
p := NewPerson("Alice")
fmt.Println(p.Name)
}在上面的代码中,NewPerson 函数返回一个指向 Person 结构体的指针,这导致 Person 实例被分配到堆上,因为它的生命周期超出了函数的作用域。
逃逸分析的好处
- 性能优化:通过避免不必要的堆分配,提升性能。
- 内存管理:减少内存泄漏的风险,帮助开发者更好地管理内存。
如何检查逃逸分析
可以使用 go build -gcflags -m 命令来查看编译器的逃逸分析信息:
bash
go build -gcflags -m yourfile.go这将显示哪些变量逃逸到堆上,以及相关的分析信息。
总结
内存逃逸分析是 Go 的一项重要特性,帮助编译器优化内存分配,提高程序性能。理解内存逃逸有助于编写更高效的 Go 代码。
场景:1GB文件,每个单词不超过16字节,在1M的内存里,得到出现频率最高的100个单词
由于文件大小为1GB,而内存的大小只有1MB,因此不能一次把所有的词读入到内存中去处理,可以采用分治的方法进行处理:把一个文件分解为多个小的子文件,从而保证每个文件的大小都小于1MB,进而可以直接被读取到内存中处理。
第一步:使用多路归并排序对大文件进行排序,这样相同的单词肯定是挨着的
第二步:
① 初始化一个 100 个节点的小顶堆,用于保存 100 个出现频率最多的单词
② 遍历整个文件,一个单词一个单词的从文件中取出来,并计数
③ 等到遍历的单词和上一个单词不同的话,那么上一个单词及其频率如果大于堆顶的词的频率,那么放在堆中,否则不放
最终,小顶堆中就是出现频率前 100 的单词了
多路归并排序对大文件进行排序的步骤如下:
① 将文件按照顺序切分成大小不超过 512KB 的小文件,总共 2048 个小文件
② 使用 1MB 内存分别对 2048 个小文件中的单词进行排序
③ 使用一个大小为 2048 大小的堆,对 2048 个小文件进行多路排序,结果写到一个大文件中
json和protobuf的区别
JSON(JavaScript Object Notation)和 Protobuf(Protocol Buffers)是两种常用的数据序列化格式。它们各自有不同的特点和适用场景。以下是它们之间的主要区别:
1. 数据格式
-
JSON:
- 人类可读的文本格式,易于调试和查看。
- 数据使用键值对的结构表示,支持基本数据类型(字符串、数字、布尔值、数组和对象)。
-
Protobuf:
- 二进制格式,不易于人类直接阅读。
- 需要预先定义数据结构(消息格式)并编译生成代码来处理数据。
2. 性能
-
JSON:
- 解析和序列化速度较慢,因为它是文本格式。
- 数据体积相对较大,尤其是在传输大量数据时。
-
Protobuf:
- 解析和序列化速度快,效率高。
- 数据体积较小,适合网络传输和存储。
3. 可扩展性
-
JSON:
- 结构灵活,不需要预定义模式,可以随意添加字段,但对版本控制支持较差。
-
Protobuf:
- 需要预定义结构,但支持向后兼容和向前兼容,可以安全地添加或删除字段。
4. 语言支持
-
JSON:
- 几乎所有编程语言都支持 JSON 解析和生成。
-
Protobuf:
- 支持多种编程语言,但需要使用特定的工具生成代码。
5. 使用场景
-
JSON:
- 适用于配置文件、Web API(如 RESTful API)、轻量级数据传输等场景。
-
Protobuf:
- 适用于高性能网络通信、大规模数据存储、微服务架构等场景。
总结
- JSON:易读、灵活,但性能较低,适合简单的应用场景。
- Protobuf:高效、可扩展,适合对性能和数据体积有较高要求的应用场景。
Go怎么调试的,会Goland远程调试吗?
-
安装dlv
在Linux服务器上执行:go install github.com/go-delve/delve/cmd/dlv@latest,安装dlv调试工具,因为是go编译的可执行程序,可以随意复制,其他环境甚至都可以不安装go语言环境。
-
按照goland提示添加远程调试
-
添加编译配置
-
在服务器运行
将可执行程序上传到服务器,并使用dlv运行:
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./test001_linux
带命令行参数,在可执行程序后面带上 --,再后面就是命令行参数:
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./test001_linux -- -s 123
- 然后再window的goland上运行调试
算法:查找字符串子串,有哪些算法?
暴力匹配:简单,但效率低。
KMP:高效,适合单个子串匹配。O(m+n)
部分匹配表(LPS 数组):
在开始匹配之前,KMP 算法首先构建一个部分匹配表(Longest Prefix Suffix,LPS)。
LPS 数组的每个元素 lpsi 表示子串 pattern0...i 中的最长相等前后缀的长度。
LPS 数组可以帮助我们在匹配失败时,不必回溯主串的指针,而是根据已匹配的部分直接跳到下一个可能匹配的位置。
匹配过程:
使用两个指针,i 指向主串,j 指向子串。
逐个比较主串和子串的字符:
如果字符匹配,两个指针同时向后移动。
如果不匹配且 j > 0,则根据 LPS 数组调整子串指针 j,而不移动主串指针 i。
如果 j 达到子串的长度,说明找到匹配,记录匹配位置。