Python语法
1.基本语法
(1)注释
- # :整行、单行尾部
- ''' 或**"""** :多行
(2)条件语句
python
# 定义变量x,从用户输入中获取数值
x = float(input("请输入一个数值:"))
# 定义变量abs_x,用来存放绝对值
abs_x = x
# 如果x为正数
if x > 0:
print("x is positive")
# 如果x为零
elif x == 0:
print("x is zero")
# 如果x为负数
else:
print("x is negative")
# 计算负数绝对值
abs_x = -x
print("该数值的绝对值为:", abs_x)(3)循环语句
python
x_string = 'Python is FUN!'
# 利用for循环打印每个字符
for i_str in x_string:
4 s pa ce s print(i_str)(4)导包
python
# 这种方式会将 NumPy 包导入到当前的命名空间中,并使用别名 np 来代替 NumPy。
import numpy as np 2.数据类型
(1)特殊数值
python
import math
print(math.pi) # 输出π的值
print(math.e) # 输出e的值
print(math.sqrt(2)) # 输出根号2的值(2)字符串
- 使用加号 + 将多个字符串连接起来
- 使用乘号 * 将一个字符串复制多次
- 索引和切片:
python
greeting_str = 'Hey, James!' H e y , J a m e s !
# 打印字符串长度
print('字符串的长度为:')
print(len(greeting_str))
# 打印每个字符和对应的索引
for index, char in enumerate(greeting_str):
print(f"字符:{char},索引:{index}")
# 单个字符索引
print(greeting_str[0])
print(greeting_str[1])
print(greeting_str[-1])
print(greeting_str[-2])
# 切片
# 取出前3个字符,索引为0、1、2
print(greeting_str[:3])
# 取出索引1、2、3、4、5,不含0,不含6
print(greeting_str[1:6])
# 指定步长2,取出第0、2、4 ...
print(greeting_str[::2])
# 指定步长-1,倒序
print(greeting_str[::-1])- 插入数据:
python
name = 'James'
height = 181.18
# 使用 + 运算符
str_1 = name + ' has a height of ' + str(height) + ' cm.'
print(str_1)
# 使用 %
str_2 = '%s has a height of %.3f cm.' %(name, height)
print(str_2)
# 使用 str.format()
str_3 = '{} has a height of {:.3f} cm.'.format(name, height)
print(str_3)
# 使用f-strings
str_4 = f'{name} has a height of {height:.3f} cm.'
print(str_4)(3)列表
- 基本方法:
python
# 创建一个混合列表
my_list = [1, 1.0, '12ab', True, [1, 1.0, '1'], {1}, {1:1.0}]
print(my_list)
# 修改某个元素
my_list[2] = '123'
print(my_list)
# 在列表指定位置插入元素
my_list.insert(2, 'inserted')
print(my_list)
# 在列表尾部插入元素
my_list.append('tail')
print(my_list)
# 通过索引删除
del my_list[-1]
print(my_list)
# 删除某个元素
my_list.remove('123')
print(my_list)
# 判断一个元素是否在列表中
if '123' in my_list:
print("Yes")
else:
print("No")
# 列表翻转
my_list.reverse()
print(my_list)
# 将列表用所有字符连接,连接符为下划线 _
letters = ['J', 'a', 'm', 'e', 's']
word = '_'.join(letters)
print(word)- 拆包,打包:
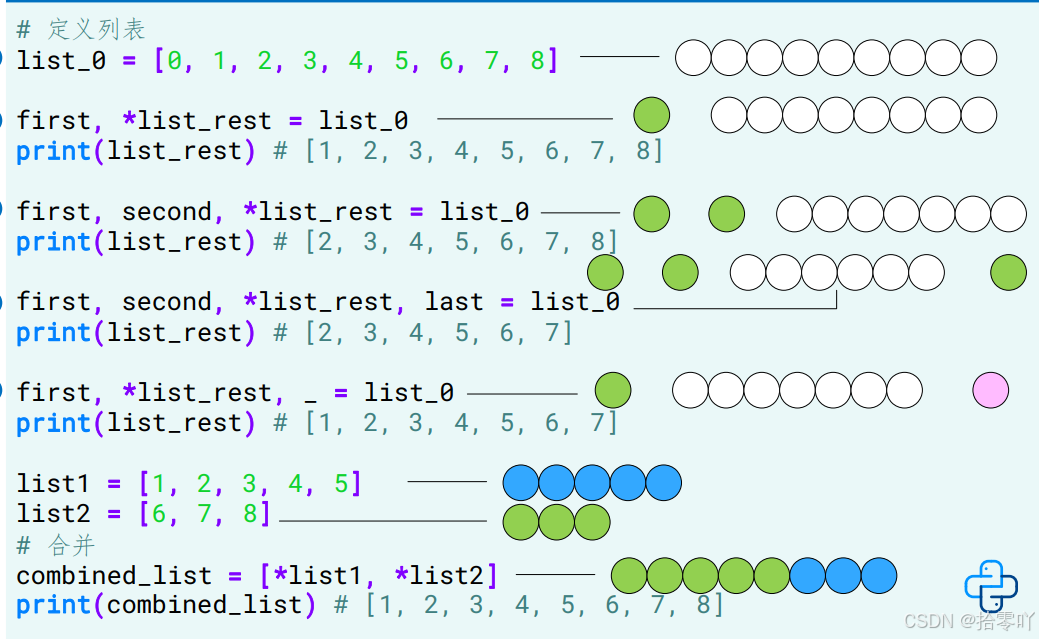
- 视图,浅复制,深复制:
- = :直接赋值,是非拷贝方法,结果是产生一个视图 (view)。这两个列表是等价的,共享同一地址修改,其中任何 (原始列表、视图) 一个列表都会影响到另一个列表。
- copy :获得的两个列表地址不同,只对 list 的第一层元素完成拷贝,深层元素还是和原 list 共用。
- deep copy :创建一个完全独立的列表对象,该对象中的元素与原始列表中的元素是 不同的对象。
(4)元组
- tuple :是一种不可变的序列类型,用圆括号 () 来表示。元组一旦创建 就不能被修改,这意味着你不能添加或删除其中的元素。
(5)集合
- set :是一种无序的、可变的数据类型,可以用来存储多个不同的元素。使 用花括号 {} 或者 set() 函数创建集合,或者使用一组元素来初始化一个集合。
(6)字典
- 字典是一种无序的键值对 (key-value pair) 集合。 可以使用大括号 {} 或者dict() 函数创建字典,键**(key)** 值**(value)** 对之间用冒号 : 分隔。
- 注意,使用大括号 {} 创建字典时,字符串键 key 用引号;而使用 dict() 创建字典时,字 符串键不使用引号。
python
# 使用大括号创建字典
person = {'name': 'James', 'age': 88, 'gender': 'male'}
# 使用 dict() 函数创建字典
fruits = dict(apple=88, banana=888, cherry=8888)
# 访问字典中的值
print(person['name'])
print(fruits['cherry'])
# 修改字典中的值
person['age'] = 28
print(person)
# 添加键值对
person['city'] = 'Toronto'
print(person)
# 删除键值对
del person['gender']
print(person)
# 获取键、值、键值对列表
print(person.keys())
print(person.values())
print(person.items()) (7)矩阵
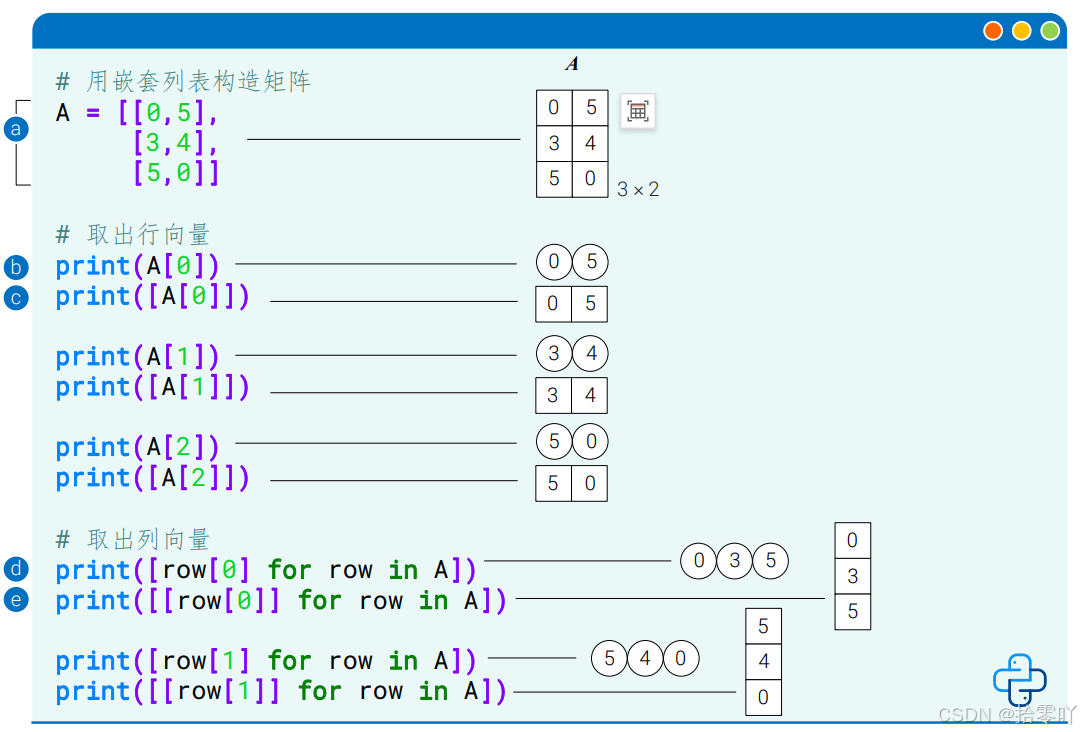
3.运算
- 乘幂 :**
- 逻辑 :and , or , not
- 成员 :int , not in (测试是否存在于序列中)
- 身份 :is , is not (判断两个对象是否引用同一个内存地址)

(1)math库
- 正弦函数:
python
# 导入包
import math
import matplotlib.pyplot as plt
# 计算正弦值
x_start = 0
x_end = 2 * math.pi
print(math.sin(x_start))
print(math.sin(x_end))
# 将 x 范围切割
num = 37
step = (x_end-x_start) / (num-1) # 间隔
x_array = [x_start + i * step for i in range(num)] # 计算 x 坐标
y_array = [math.sin(x_idx) for x_idx in x_array] # 计算 y 坐标
# 可视化正弦函数
plt.plot(x_array,y_array,label="y = sin(x)")
plt.title("Graph of y = sin(x)")
plt.xlabel("x")
plt.ylabel("y")
plt.grid(True)
plt.legend()
# 显示图像
plt.show()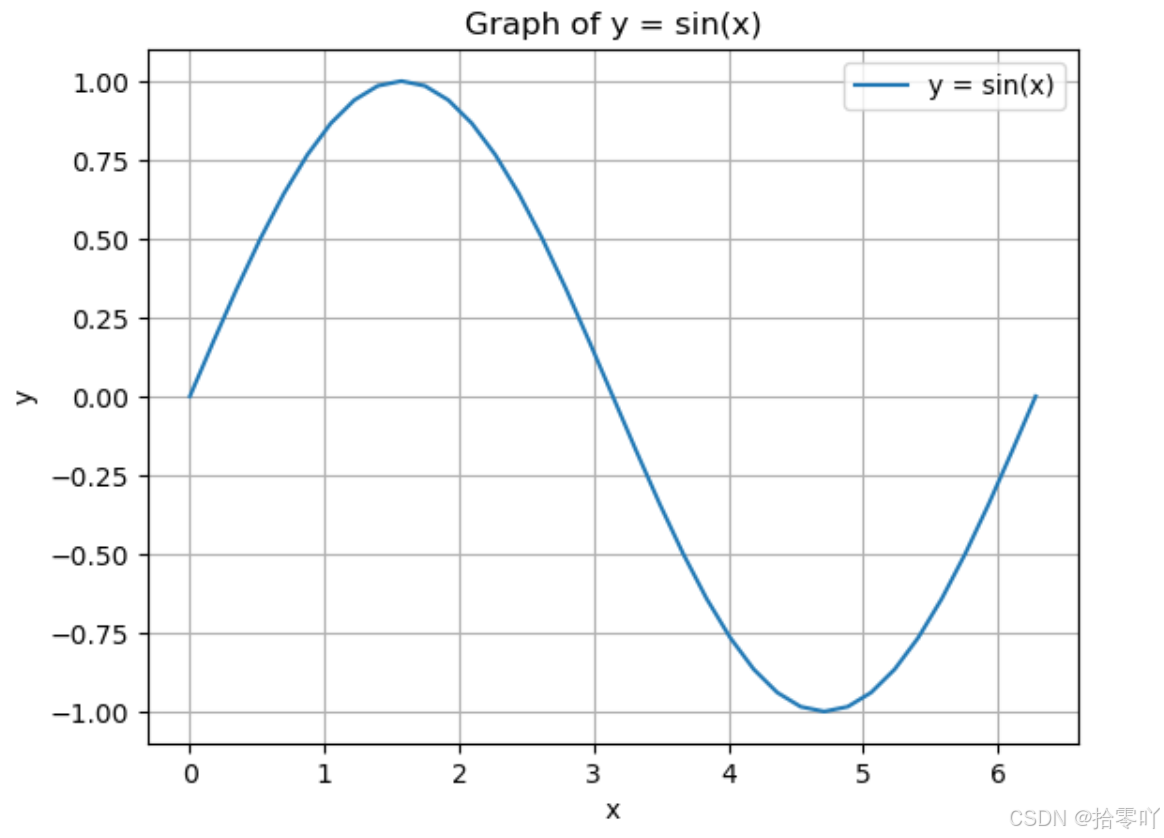
- 指数函数:
python
import math
import matplotlib.pyplot as plt
# 定义 x 的取值范围,范围从 -3 到 3,步长为 0.1
x_values = []
y_values = []
x = -3.0 # 初始值
while x <= 3.0:
x_values.append(x)
y_values.append(math.exp(x))
x += 0.1 # 步长为 0.1
# 绘制图像
plt.plot(x_values, y_values, label="f(x) = exp(x)")
plt.title("Graph of f(x) = exp(x)")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.grid(True) # 启用或显示图形中的网格线
plt.legend() # 标注每条曲线的意义
# 显示图像
plt.show()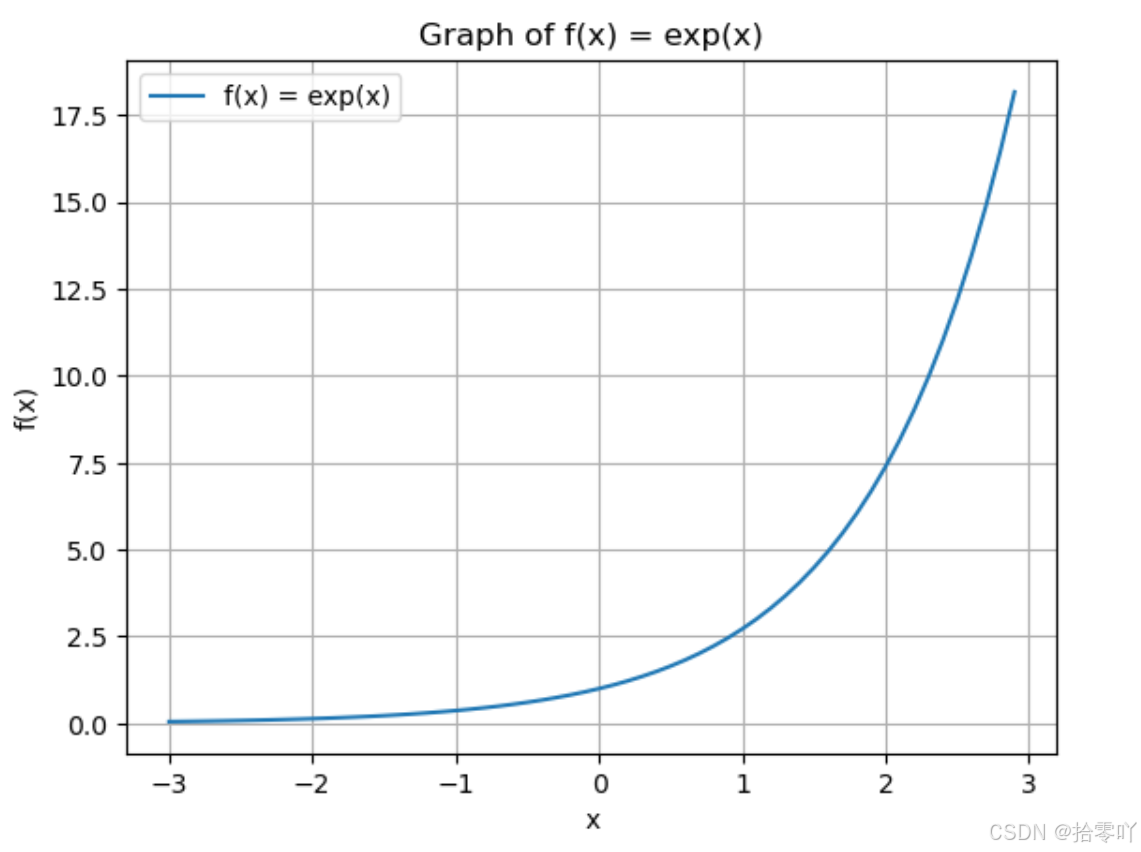
(2)random 库和 statistics 库
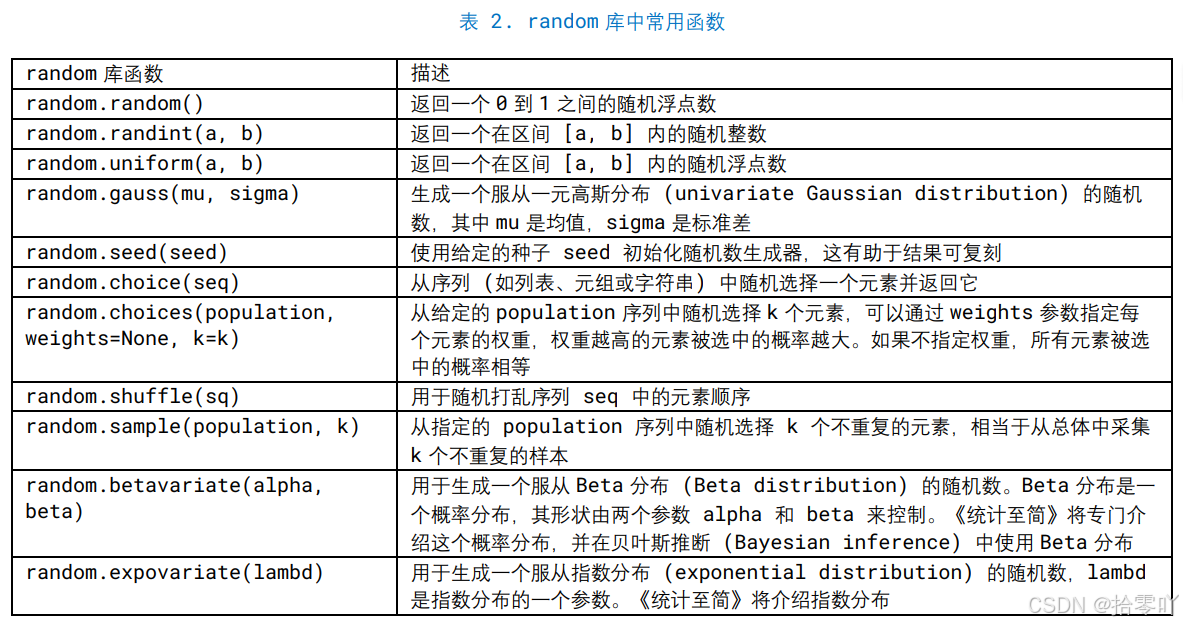
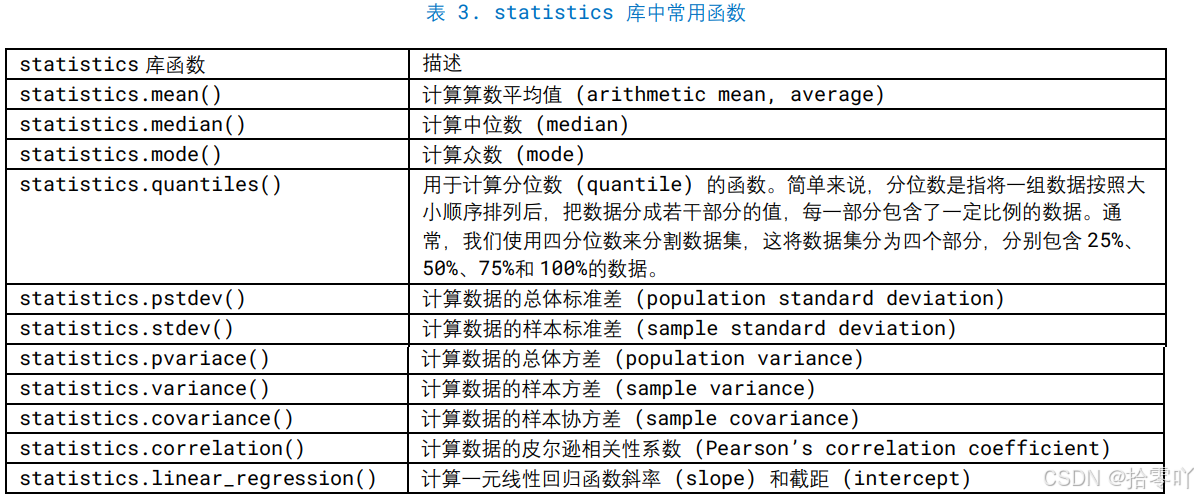
- 质地均匀抛硬币:
python
import random
import statistics
import matplotlib.pyplot as plt
# 抛硬币实验的次数
num_flips = 1000
# 用于存储每次抛硬币的结果
results = []
# 用于存储每次抛硬币后的均值
running_means = []
# 下划线 _ 是一个占位符,表示一个不需要使用的变量
for _ in range(num_flips):
# 随机抛硬币,1代表正面 (H),0代表反面 (T)
result_idx = random.randint(0, 1)
results.append(result_idx)
# 计算当前所有结果的均值
mean_idx = statistics.mean(results)
running_means.append(mean_idx)
# 可视化前100次结果均值随次数变化
visual_num = 100
# results[0:visual_num] 取出列表前 100 个元素
# marker="o"将散点的形状设置为圆圈
# cmap='cool' 用于指定颜色映射。它决定了如何将 0 和 1 映射到不同的颜色
plt.scatter(range(1, visual_num + 1), results[0:visual_num],
c=results[0:visual_num],marker="o", cmap = 'cool')
# 分别以 x,y 绘图
plt.plot(range(1, visual_num + 1), results[0:visual_num])
plt.xlabel("Number of coin flips")
plt.ylabel("Result")
plt.grid(True)
plt.show()
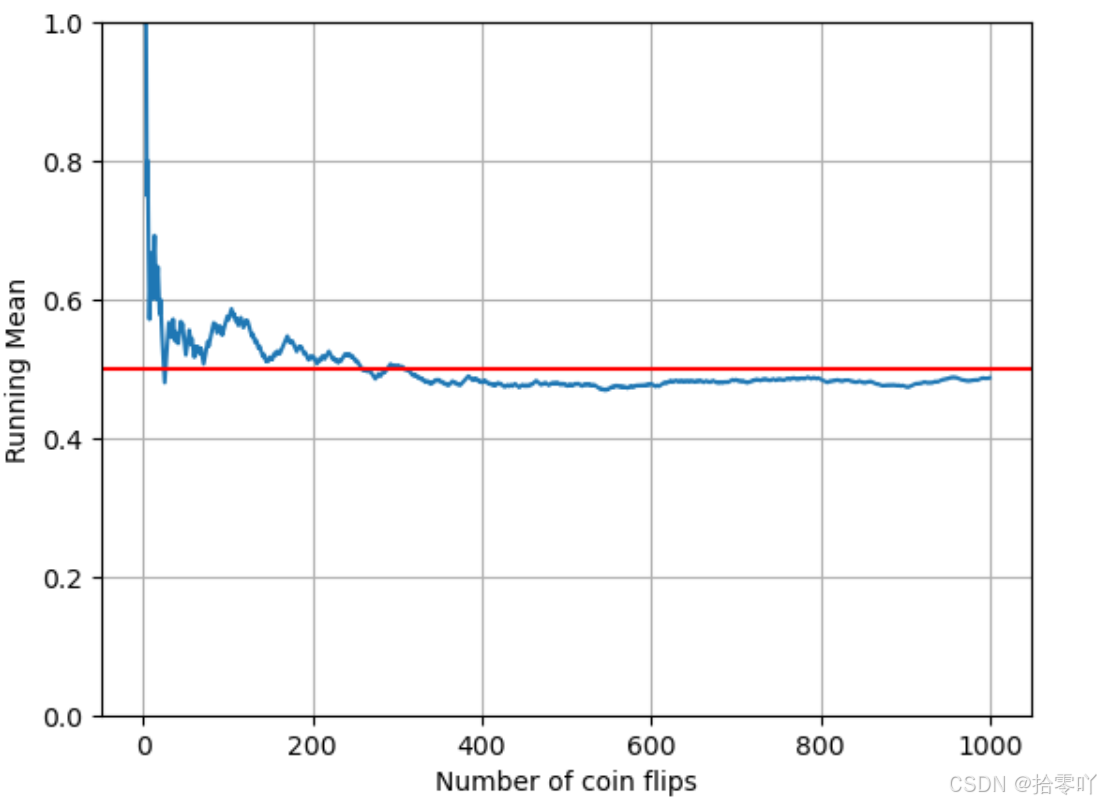
# 可视化均值随次数变化
plt.plot(range(1, num_flips + 1), running_means)
# plt.axhline(),绘制水平线
plt.axhline(0.5, color = 'r')
plt.xlabel("Number of coin flips")
plt.ylabel("Running Mean")
plt.grid(True)
# 设置 y 轴的显示范围
plt.ylim(0,1)
plt.show()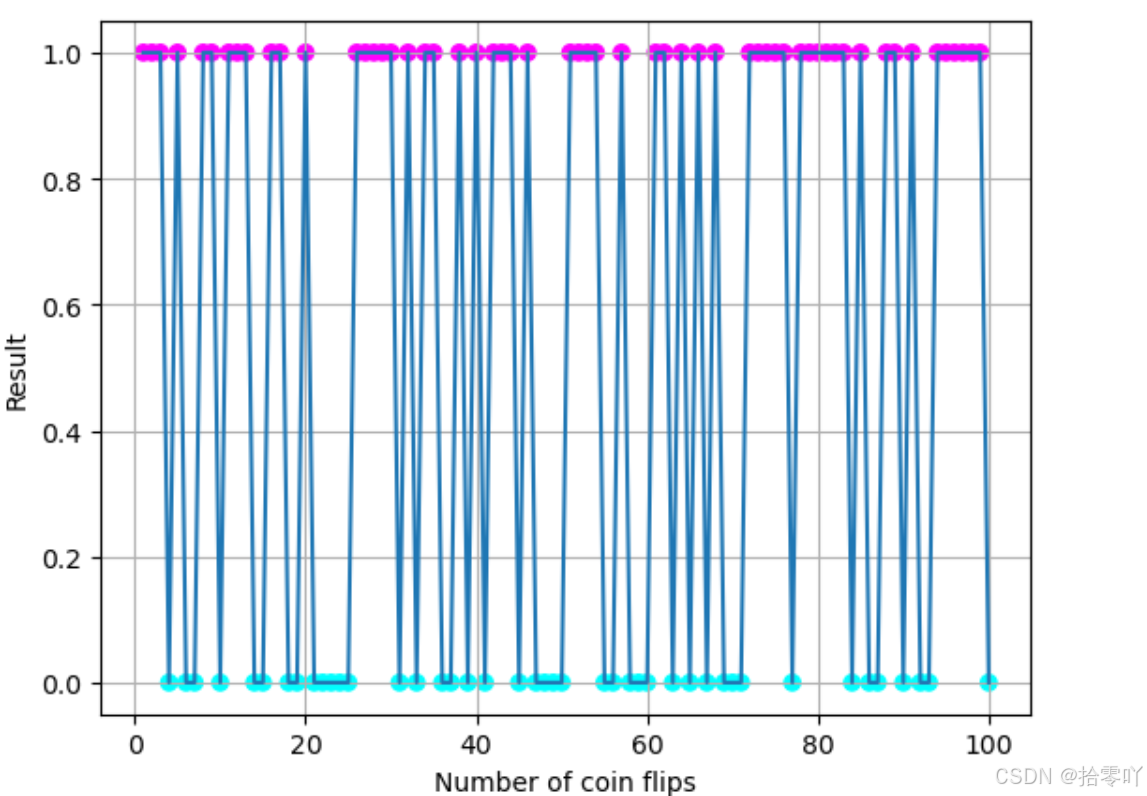
- 头重脚轻抛硬币:
random.choices会根据概率列表选择一个点数,但是它会返回一个包含选中元素的列表, 而我们只需要列表中的第一个(也是唯一的)元素,所以我们加了[0],用来提取列表中的第一个元素。
python
# 模拟抛硬币实验,硬币头重脚轻
# 用于存储每次抛硬币的结果
results = [random.choices([0, 1], [0.4, 0.6])[0]
for _ in range(num_flips)]
# 用于存储每次抛硬币后的均值
running_means = [statistics.mean(results[0:idx+1])
for idx in range(num_flips)]- 扔骰子:
python
import random
import statistics
import matplotlib.pyplot as plt
# 实验次数
num_flips = 1000
# 存储每次结果
results = []
# 存储每次均值
running_means = []
for _ in range(num_flips):
# 六面筛子
result_idx = random.randint(1,6)
results.append(result_idx)
# 计算均值
mean_idx = statistics.mean(results)
running_means.append(mean_idx)
# 可视化均值
plt.plot(range(1, num_flips + 1), running_means)
plt.axhline(3.5, color = 'r')
plt.xlabel("Number of dice flips")
plt.ylabel("Running Mean")
plt.grid(True)
plt.ylim(1,6)
plt.show()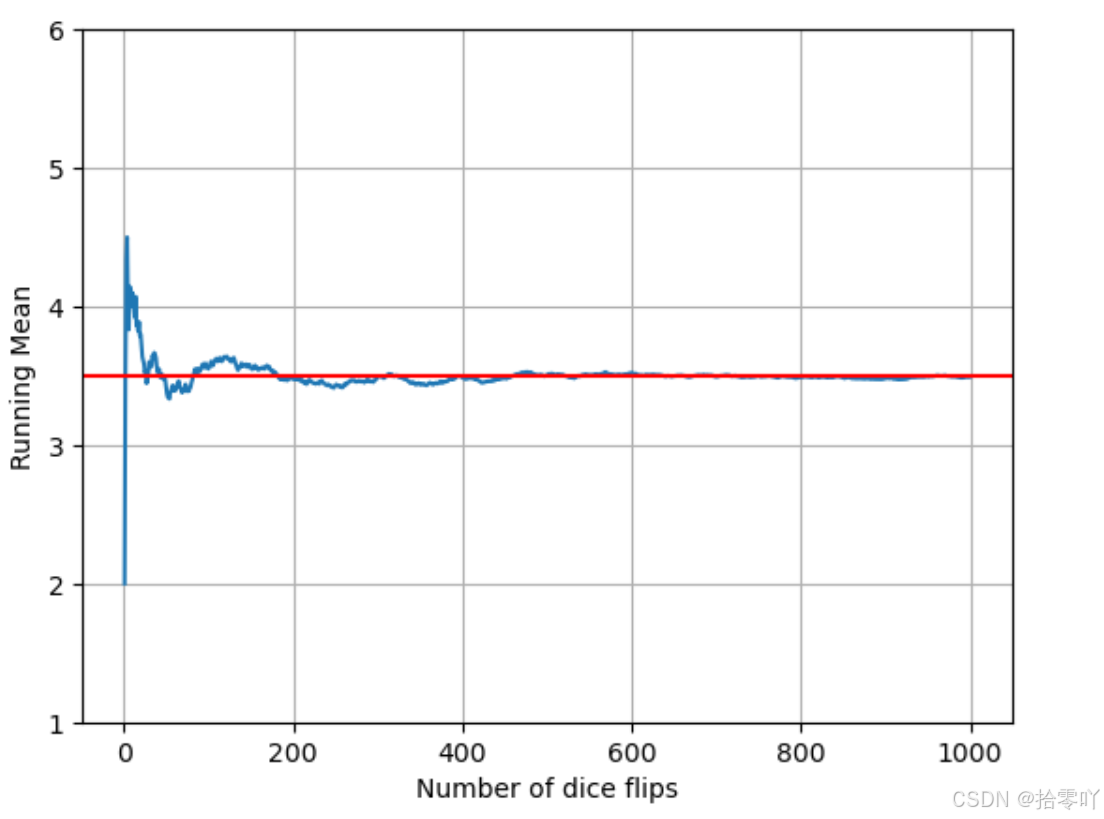
- 概率投骰子:
python
results = [random.choices([1,2,3,4,5,6], [0.2,0.16,0.16,0.16,0.16,0.16])[0]
for _ in range(num_flips)]
# 每次投骰子后的均值
running_means = [statistics.mean(results[0:idx+1])
for idx in range(num_flips)]- 线性回归:
python
# 导入包
import random
import statistics
import matplotlib.pyplot as plt
# 产生数据(0-10 取 50 个数据)
num = 50
random.seed(0) # 保证每次随机数相同
x_data = [random.uniform(0, 10) for _ in range(num)]
# 生成噪音,添加到对应 y 轴的值
noise = [random.gauss(0,1) for _ in range(num)]
y_data = [0.5 * x_data[idx] + 1 + noise[idx]
for idx in range(num)]
# 绘制散点图
fig, ax = plt.subplots() # 图形对象 fig、轴对象 ax
ax.scatter(x_data, y_data)
ax.set_xlabel('x'); ax.set_ylabel('y')
ax.set_aspect('equal', adjustable='box') # 设置轴对象 ax 的纵横比例为相等
ax.set_xlim(0,10); ax.set_ylim(-2,8)
ax.grid()
# 一元线性回归(生成斜率和截距)
slope, intercept = statistics.linear_regression(x_data, y_data)
# 生成一个坐标 x 等差数列,来绘制回归线
start, end, step = 0, 10, 0.5
x_array = []
x_i = start
while x_i <= end:
x_array.append(x_i)
x_i += step
# 利用斜率和截距,计算 y_array 预测值
y_array_predicted = [slope * x_i + intercept for x_i in x_array]
# 可视化一元线性回归直线
fig, ax = plt.subplots()
ax.scatter(x_data, y_data)
ax.plot(x_array, y_array_predicted, color = 'r') # 画出回归线
ax.set_xlabel('x'); ax.set_ylabel('y')
ax.set_aspect('equal', adjustable='box')
ax.set_xlim(0,10); ax.set_ylim(-2,8)
ax.grid()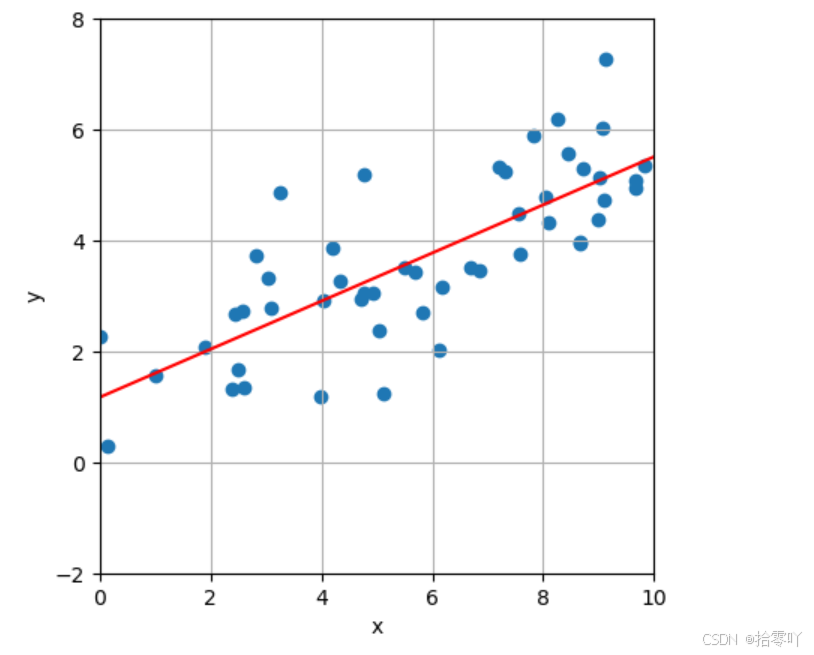
4.控制结构
(1)简单语句
- **for ... else ...**语句
python
for x in range(10):
print(x)
else: # for循环结束后会执行
print("For loop finished")- 异常处理语句
- 注意:若被break中断,则else语句不会执行
python
try:
x = 1 / 0
except ZeroDivisionError:
print("除数不能为零")- input 语句
注意:默认返回字符串
- pass 语句
pass 是一个占位符语句,它什么也不做。通常用于你还没写代码但需要占据一个位置时。
(2)for 循环语句
- 计算向量内积:
python
# 定义向量a和b
a = [1, 2, 3, 4, 5]
b = [6, 7, 8, 9, 0]
# 初始化内积为0
dot_product = 0
# 使用for循环计算内积
for i in range(len(a)):
dot_product += a[i] * b[i]
# 打印内积
print("向量内积为:", dot_product)- 使用 enumerate():
- 默认起始编号为 0 (索引),但是也可以通过传递第二个参数来指 定起始编号。
python
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits,1):
print(index, fruit)
- 使用 zip():
- 如果可迭代对象的长度不相等,以长度最短的可迭代对象为准进行迭代。
- 如果想要以长度最长的可迭代对象为准进行迭代,可以用 itertools.zip_longest()。缺失元 素默认以 None 补齐,或者以用户指定值补齐。
python
names = ['Alice', 'Bob', 'Charlie']
scores = [80, 90, 75]
for name, score in zip(names, scores):
print(name, score)- 生成二维坐标:
- **
meshgrid**用于生成横纵坐标的组合点。它返回两个矩阵:一个存储横坐标的值,另一个存储纵坐标的值。通过这两个矩阵,你可以得到所有可能的点组合。
python
def custom_meshgrid(x, y):
X = []
Y = []
for i in range(len(y)): # 外循环遍历纵坐标
X_row = []
Y_row = []
for j in range(len(x)): # 内循环遍历横坐标
X_row.append(x[j])
Y_row.append(y[i])
X.append(X_row)
Y.append(Y_row) # 沿 y 轴从小到大一行一行地生成
return X, Y
# 示例用法
x = [0, 1, 2, 3, 4, 5] # 横坐标列表
y = [0, 1, 2, 3] # 纵坐标列表
# 调用自定义函数
X, Y = custom_meshgrid(x, y)
print("X坐标:"); print(X)
print("Y坐标:"); print(Y)- 矩阵乘法:三层 for 循环:
python
# 定义矩阵 A 和 B
A = [[1, 2, 10, 20],
[3, 4, 30, 40],
[5, 6, 50, 60]]
B = [[4, 2],
[3, 1],
[40, 20],
[30, 10]]
# 定义全 0 矩阵 C 用来存放结果
C = [[0, 0],
[0, 0],
[0, 0]]
# 遍历 A 的行
for i in range(len(A)):
# 遍历 B 的列,即 len(B[0])
for j in range(len(B[0])):
# 计算矩阵乘积
for k in range(len(B)):
C[i][j] += A[i][k] * B[k][j]
# 输出矩阵 C 每一行
for row in C:
print(row)- 向量化:
- np.array() 构造一维数组 +**np.dot()**计算 a 和 b 的内积:
- 用 @ 运算符计算 A 和 B 乘积,B 和 A 乘积
python
import numpy as np
# 定义向量a和b;准确来说是一维数组
a = np.array([1, 2, 3, 4, 5])
b = np.array([6, 7, 8, 9, 0])
# 计算向量内积
dot_product = np.dot(a,b)
# 打印内积
print("向量内积为:", dot_product)
python
import numpy as np
# 定义矩阵 A 和 B
A = np.array([[1, 2, 10, 20],
[3, 4, 30, 40]])
B = np.array([[1, 3],
[2, 4],
[10, 30],
[20, 40]])
C = A @ B; print(C)
D = B @ A; print(D)- 比较 for 循环与 numpy 计算速度:
python
from numpy.random import randint
# num * num大小方阵,0~9随机数
num = 200
A = randint(0, 10, size = (num,num))
B = randint(0, 10, size = (num,num))
C = np.zeros((num,num)) # num * num大小全0方阵
# 使用NumPy计算矩阵乘法
import time
start_time = time.time() # 开始时刻
C_1 = A @ B
stop_time = time.time() # 结束时刻
time_used = stop_time - start_time
print("--- %s seconds ---" %time_used)
# 手动计算矩阵乘法
start_time = time.time() # 开始时刻
for i in range(len(A)):
for j in range(len(B[0])):
for k in range(len(B)):
C[i][j] += A[i][k] * B[k][j]
stop_time = time.time() # 结束时刻
time_used = stop_time - start_time
print("--- %s seconds ---" %time_used)
(3)列表生成式
列表生成式是一种简洁的语法形式,用于快速生成新 的列表。语法形式为**expression for item in iterable if condition** ,其中 expression 表示要生成的元素,item 表示迭代的变量,iterable 表示迭代的对象,if condition表示可选的过滤条件。
- 筛选偶数:
python
even_numbers = [num for num in range(1, 11)
if num % 2 == 0] # 一行放不下
print(even_numbers) # Output: [2, 4, 6, 8, 10]- 嵌套创建矩阵:
python
matrix = [[i * j for j in range(1, 4)]
for i in range(1, 4)]
print(matrix) # Output: [[1, 2, 3], [2, 4, 6], [3, 6, 9]]- 复刻 numpy.linspace():
在绘制二维线图时,经常会使用 numpy.linspace() 生成颗粒度高的等差数列。
python
'''
num 和 endpoint 有各自的默认值。也就是说,在调用自定函数时,如果 num 和
endpoint 这两个参数缺省时,就会使用默认值。
'''
def linspace(start,stop,num=50,endpoint=True):
if num<2:
# raise 用于引发一个异常,错误消息将被打印出来
raise ValueError("Number of samples must be at least 2")
# 是否包括右端点
if endpoint:
step = (stop - start) / (num - 1)
return [start + i * step for i in range(num)]
else:
step = (stop - start) / num
return [start + i * step for i in range(num)]
# 示例用法
start = 0 # 数列起点
stop = 10 # 数列终点
num = 21 # 数列元素个数
endpoint = True # 数列包含 stop,即右端点
# 调用自定义函数生成等差数列
values = linspace(start, stop, num, endpoint)- 矩阵转置:
python
def transpose_2(matrix):
transposed = [] # 初始化一个空的列表,用来存储转置后的矩阵
rows = len(matrix) # 获取输入矩阵的行数
cols = len(matrix[0]) # 获取输入矩阵的列数(假设矩阵是矩形的,且所有行列数相同)
# 通过列表推导式创建转置矩阵
transposed = [[matrix[j][i] for j in range(rows)] for i in range(cols)]
return transposed # 返回转置后的矩阵- 计算矩阵逐项积:
python
def hadamard_prod(M1,M2):
# 行数,列数需要完全相同
if (len(M1) != len(M2) or
len(M1[0]) != len(M2[0])):
raise ValueError("Matrices must have the same shape")
result = [[M1[i][j] * M2[i][j]
for i in range(len(M1[0]))]
for j in range(len(M1))]
A = [[1, 2],
[3, 4]]
B = [[2, 3],
[4, 5]]
# 计算矩阵逐项积
C = hadamard_prod(A, B)- 笛卡儿积:
举个简单的例子,假设有两个集合:A = {1, 2} 和 B = {'a', 'b'}。它们的笛卡尔积为 {(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')}。
python
column1 = [1,2,3,4]
column2 = ['a','b','c']
# 采用一层列表生成式计算笛卡儿积,结果为列表
cartesian_product = [(x,y) for x in column1 for y in column2]
print(cartesian_product)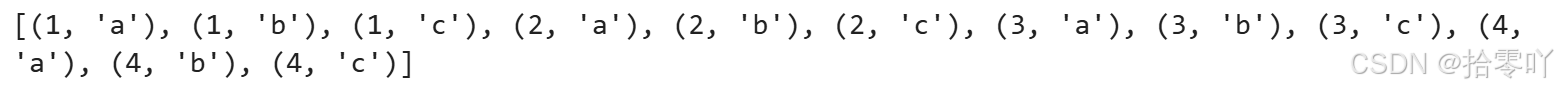
python
column1 = [1,2,3,4]
column2 = ['a','b','c']
# 采用两层列表生成式计算笛卡儿积,结果为二维列表
cartesian_product = [[(x,y) for x in column1] for y in column2]
for prod_idx in cartesian_product:
print(prod_idx)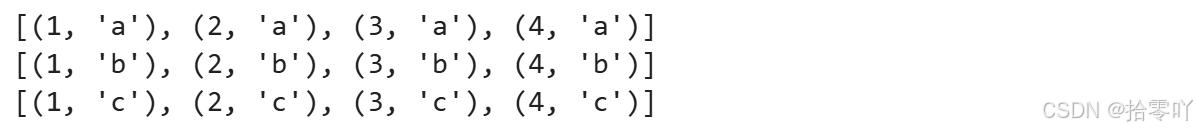
python
from itertools import product
column1 = [1, 2, 3, 4]
column2 = ['a', 'b', 'c']
'''
利用 itertools.product() 函数完成笛卡儿积计算
这个函数的结果是一个可迭代对象。
利用 list(),我们将其转化为列表,列表的每一个元素为元组。
'''
cartesian_product = list(product(column1, column2))
print(cartesian_product)
(4)迭代器 itertools
- 不放回全排列:
itertools.permutations 是 Python 标准库中的一个函数,用于返回指定长度的所有可能排 列方式。
python
import itertools
# 返回一个可迭代对象perms,其中包含了string的所有排列方式
string = 'abc'
perms_all = itertools.permutations(string)
# 用 ',' 将各种结果连接
for perm_idx in perms_all:
print(','.join(perm_idx))
- 不放回 3 取 2 排列:
python
import itertools
# 只要多传入一个参数 2,就能实现 3 取 2 排列
string = 'abc'
perms_2 = itertools.permutations(string,2)
for perm_idx in perms_2:
print(','.join(perm_idx))- 不放回 3 取 2 组合(不考虑顺序):
python
import itertools
# 将 permutations 换成 combinations 即可
string = 'abc'
perms_2 = itertools.combinations(string,2)
for perm_idx in perms_2:
print(','.join(perm_idx))- 放回 3 取 2 排列:
itertools.product 函数可以用于生成有放回排列。它接受一个可迭代 对象和一个重复参数,用于指定每个元素可以重复出现的次数。
python
import itertools
string = 'abc'
# 定义元素列表,非必须转换,只是列表是可变的
elements = list(string)
# 指定重复次数
repeat = 2
# 生成有放回排列
permutations = itertools.product(elements, repeat=repeat)
# 遍历并打印所有排列
for permutation_idx in permutations:
print(''.join(permutation_idx))- 放回 3 取 2 组合:
python
import itertools
string = 'abc'
# 定义元素列表
elements = list(string)
# 指定组合长度
length = 2
# 生成有放回组合
combos = itertools.combinations_with_replacement(elements, length)
# 遍历并打印所有组合
for combination_idx in combos:
print(''.join(combination_idx))5.函数
(1)自定义函数
- 多输入多返回:
python
# 自定义函数
def arithmetic_operations(a, b):
add = a + b
sub = a - b
mul = a * b
div = a / b
return add, sub, mul, div
# 调用函数并输出结果
a, b = 10, 5
result = arithmetic_operations(a, b) # 返回的是一个元组
print("Addition: ", result[0])
print("Subtraction: ", result[1])
print("Multiplication: ", result[2])
print("Division: ", result[3])- 部分输入有默认值:
python
# greeting 设置了一个默认值,不传参时使用
def greet(name, greeting='Hello'):
print(f"{greeting}, {name}!")
# 使用默认的问候语调用函数
greet('James') # 输出 "Hello, James!"
# 指定自定义的问候语调用函数
greet('James', 'Good morning') # 输出 "Good morning, James!"- 全局变量 vs 局部变量:
- 如果要在函数内部修改全局变量的值,需要使用 global 关键字来声明该变量是 全局变量。
python
# 全局变量
global_x = 8 # global_x: 8
print("global_x:", global_x)
# 自定义函数
def my_function(local_x):
# 局部变量
print("local_x:", local_x) # local_x: 38
# 声明变量是全局变量
global global_x
global_x = 88
print("global_x:", global_x) # global_x: 88
# 调用函数
my_function(38)
# 在函数外部访问全局变量
print("global_x:", global_x) # global_x: 88- 使用 assert语句:插入断言,检查条件:
- assert b != 0用于确保除数不为零。如果除数为零,assert 语句将引发异常。
python
# 定义除法函数
def divide(a, b):
assert b != 0, "除数不能为零"
return a / b
# 除以零,会引发 AssertionError 异常
result = divide(10, 0)
# 上行不会被执行,因为异常已经引发
print(result) - 帮助文档(即函数里的开头长篇注释):
- 如果要查询这个文档,可以使用 Python 内置的 help() 函数或者**doc**属性来查看。
python
# 计算向量内积
def inner_prod(a,b):
'''
自定义函数计算两个向量内积
输入:
a:向量,类型为数据列表
b:向量,类型为数据列表
输出:
c:标量
参考:
https://mathworld.wolfram.com/InnerProduct.html
'''
------------------
return dot_product
# 查询自定义函数文档,两种办法
help(inner_prod)
print(inner_prod.__doc__)(2)更多自定义线性代数函数
- 全 0 矩阵:numpy.zeros() 和 numpy.zeros_like()
python
# 参数为行数,列数
def create_zeros_matrix(rows,cols):
matrix = [] # 空列表
# 遍历行数
for _ in range(rows):
row_idx = [0] * cols # 一行一行的产生 0
matrix.append(row_idx)
return matrix
create_zeros_matrix(3,4)- 单位矩阵:numpy.identity()
python
# 单位矩阵为方阵
def identity_matrix(size):
matrix = []
for i in range(size):
row = [0] * size
row[i] = 1 # 对角线元素为 1
matrix.append(row)
return matrix
identity_matrix = identity_matrix(4)- 对角方阵:numpy.diag()
- 对角阵是一种特殊的矩阵 (未必是方阵),除 了主对角线上的元素之外,所有其他元素都为零。
python
# 传入对角线元素
def diagonal_matrix(values):
matrix = []
for i in range(len(values)):
row = [0] * len(values)
matrix.append(row)
matrix[i][i] = values[i] # 对角线赋值
return matrix
# 对角线元素
diagonal_values = [4, 3, 2, 1]
# 调用自定义函数
diagonal_matrix = diagonal_matrix(diagonal_values)- 提取对角线元素:numpy.diag()
python
# 传入矩阵
def extract_main_diagonal(matrix):
# 行和列较小的那个为待提取对角线
rows = len(matrix);cols = len(matrix[0])
size = min(rows,cols)
diagonal = [matrix[i][i] for i in range(size)]
return diagonal
matrix = [[1, 2, 3],
[4, 5, 6]]
main_diagonal = extract_main_diagonal(matrix)
main_diagonal- 计算方阵迹(主对角线上元素的总和):numpy.trace()
python
# 传入矩阵
def trace(matrix):
rows = len(matrix)
cols = len(matrix[0])
if rows != cols: # 不是方阵则报错
raise ValueError("Matrix is not square")
diagonal_sum = sum([matrix[i][i] for i in range(rows)])
return diagonal_sum
A = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
trace_A = trace(A)
print("矩阵的迹为:", trace_A)- 判断矩阵是否对称:利用本身 / 利用转置矩阵
python
def is_symmetric(matrix):
rows = len(matrix)
cols = len(matrix)
# 不是方阵不对称
if rows != cols:
return False
# 对应元素不相等则不对称
for i in range(rows):
for j in range(cols):
if matrix[i][j] != matrix[j][i]:
return False
return True
A = [[1, 2, 3],
[2, 4, 5],
[3, 5, 6]]
print("是否为对称矩阵:", is_symmetric(A))
python
def is_symmetric_2(matrix):
rows = len(matrix)
cols = len(matrix)
# 不是方阵不对称
if rows != cols:
return False
# 与转置矩阵不同则不对称
tranposed = [[(matrix[j][i])
for j in range(rows)]
for i in range(rows)]
if(matrix == tranposed):
return True
return False
A = [[1, 2, 3],
[2, 4, 5],
[3, 5, 6]]
print("是否为对称矩阵:", is_symmetric_2(A))- 矩阵行列式:numpy.linalg.det()
python
# determinant 意思是行列式,ad - bc
def determinant_2x2(matrix):
if len(matrix) != 2 or len(matrix[0]) != 2:
raise ValueError("Matrix must be 2x2")
a = matrix[0][0]
b = matrix[0][1]
c = matrix[1][0]
d = matrix[1][1]
det = a*d - b*c
return det
A = [[3, 2],
[1, 4]]
det = determinant_2x2(A)
print("矩阵行列式:", det)- 矩阵逆:numpy.linalg.inv()
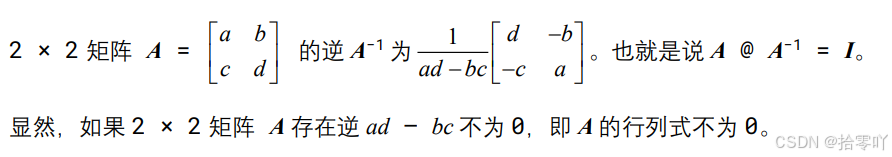
python
def inverse_2x2(matrix):
if len(matrix) != 2 or len(matrix[0]) != 2:
raise ValueError("Matrix must be 2x2")
a = matrix[0][0]
b = matrix[0][1]
c = matrix[1][0]
d = matrix[1][1]
det = a * d - b * c # 计算行列式
if det == 0:
raise ValueError("Matrix is not invertible")
# 计算逆矩阵
inv_det = 1 / det
inv_matrix = [[d * inv_det, -b * inv_det],
[-c * inv_det, a * inv_det]]
return inv_matrix
A = [[2, 3],
[4, 5]]
inv_matrix = inverse_2x2(A)(3)递归函数
- 阶乘:
python
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n - 1)
for i in range(10):
print(f'{i}! = {factorial(i)}')- 斐波那契数列:
python
def fibonacci(n):
if(n <= 1):
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
for i in range(10):
print(fibonacci(i))(4)位置参数、关键字参数
- 参数位置不同时,结果不同:
- 当指定参数名称后,参数的位置不会影响结果。
python
# 位置参数
complex(4, 3) # (4+3j)
complex(3, 4) # (3+4j)
# 关键字参数
complex(real=3, imag=4) # (3+4j)
complex(imag=4, real=3) # (3+4j)- 正斜杠 / 之前的参数是位置参数;
- 在正斜杠 / 和星号 * 之间位置或关键字传递都可以;
- 在星号 * 之后必须按关键字传递。
python
# 位置参数
def quadratic_f(a, b, c, x,/):
f = a * x **2 + b * x + c
return f
quadratic_f(1, 2, 3, 4)
quadratic_f(3, 2, 1, 4)
# 关键字参数
def quadratic_f_2(*, a, b, c, x):
f = a * x **2 + b * x + c
return f
quadratic_f_2(a = 1, b = 2, c = 3, x = 4)
quadratic_f_2(c = 3, x = 4, a = 1, b = 2)
# 关键字/位置参数
def quadratic_f_3(a, b, /, c, *, x):
f = a * x **2 + b * x + c
return f
quadratic_f_3(1, 2, 3, x = 4)
quadratic_f_3(1, 2, c = 3, x = 4)- 拆包打包:
- 单个星号
*用来解包可迭代对象(如列表或元组),并将其中的元素作为独立的参数传递给函数。这里相当于:complex(3, 4) - 双星号
**用来解包字典,并将字典的键值对作为关键字参数传递给函数。字典的键需要与函数参数的名称匹配。这里相当于:complex(real=3, imag=4)
python
# 使用一个星号
complex_list = [3, 4]
complex(*complex_list)
# 使用两个星号
complex_dict = {'real': 3, 'imag': 4}
complex(**complex_dict)(5)使用*args 和**kwargs
- *args(arguments) 和 ****kwargs(keyword)**是用于处理不定数量的参数的特殊语法
- 在自定义函数时,输入为***args**,意味着这个函数可以接受不限量数据
- 自定义函数用****kwargs**接受不限量关键字参数
python
# 利用*args
def multiply_all(*args):
result = 1
for num_idx in args:
result *= num_idx
return result
# 计算4个值的乘积
print(multiply_all(1, 2, 3, 4))
# 计算6个值的乘积
print(multiply_all(1, 2, 3, 4, 5, 6))
python
# 利用*kwargs
def multiply_all_2(**kwargs):
result = 1
# 循环dict()
for key, value in kwargs.items():
print("The value of {} is {}".format(key, value))
result *= value
return result
# 计算3个key-value pairs中值的乘积
print(multiply_all_2(A = 1, B = 2, C = 3))
# 计算4个key-value pairs中值的乘积
print(multiply_all_2(A = 1, B = 2, C = 3, D = 4))(6)匿名函数(lambda 函数)
- 匿名函数的语法格式为:lambda arguments: expression 。其中,arguments 是参数列 表,expression 是一个表达式。当匿名函数被调用时,它将返回 expression的结果。
- 我们定义了一个匿名函数lambda x: x + 1 ,该函数接受一个参数 x 并返回 x + 1。
- 在 Python 中,map() 是一种内置的高阶函数,它将 my_list中的每个元素传递给这个匿名函数,并返回一个新的迭代器。
python
my_list = [1, 2, 3, 4, 5]
# 将列表中的所有元素加 1
list_plus_1 = list(map(lambda x: x+1, my_list))
print(list_plus_1) # [2, 3, 4, 5, 6]
# 将列表中的所有元素分别求平方
list_squared = list(map(lambda x: x**2, my_list))
print(list_squared) # [1, 4, 9, 16, 25](7)构造模块、库
- 自定义模块:将自定义函数单独存于一个文件中,方便后续调用
- 自定义库:创建一个文件夹,用于存放库的代码文件。然后在该文件夹中创建多个模块文件,这些模块文件包含需要打包的函数或类。
python
# 将其存为文件circle.py
import math
def area(radius):
return math.pi * radius**2
def circumference(radius):
return 2 * math.pi * radius6.面向对象编程
(1)什么是面向对象编程
一句话概括就是:利用类去创造实例
- 矩形:
- 关键词 class 把数据 (属性) 和操作 (方法) 封装起来。
- init(self, ...) 方法用于在创建类的实例时进行初始化操作,第一个参数通常被命名为 self,它指向类的实例对象。
- 注意:调用属性时不加圆括号 (),使用方法时需要圆括号 ()
python
# 定义一个名为 Rectangle 的类
class Rectangle:
# 定义对象
def __init__(self,width,height):
self.width = width
self.height = height
# 定义方法,,分别计算矩形周长,面积
def circumference(self):
return 2 * (self.width + self.height)
def area(self):
return self.width * self.height
# 利用类创建实例
rect = Rectangle(5,10)
# 调用方法
print('矩形周长')
print(rect.circumference())
print('矩形面积')
print(rect.area())(2)定义属性
- 小鸡:
python
# 创建了一个名为 "Chicken" 的类
class Chicken:
# 定义对象,各种属性
def __init__(self,name,age,color,weight):
self.name = name
self.age = age
self.color = color
self.weight = weight
# 利用类创建实例
chicken_01 = Chicken("小红", 1, "黄色", 1.5)
chicken_02 = Chicken("小黄", 1.2, "红色", 2)
# 调用属性
print('==小鸡的名字=='); print(chicken_01.name)
print('==小鸡的年龄=='); print(chicken_01.age)
print('==小鸡的颜色=='); print(chicken_01.color)
print('==小鸡的体重=='); print(chicken_01.weight)- 先占位,再赋值:
python
# 创建了一个名为 "Chicken" 的类
class Chicken:
def __init__(self):
self.name = ''
self.age = ''
self.color = ''
self.weight = ''
# 利用类创造实例,然后赋值
chicken_01 = Chicken()
chicken_01.name = '小红'
chicken_01.age = 1
chicken_01.color = '黄色'
chicken_01.weight = 1.5(3)定义方法
- 浮点数列表:
python
# 创建 ListStatistics 类
class ListStatistics:
# 定义对象
def __init__(self,data):
self.data = data
# 方法1:计算列表的长度
def list_length(self):
return len(self.data)
# 方法2:计算列表元素之和
def list_sum(self):
return sum(self.data)
# 方法3:计算列表元素平均值
def list_mean(self):
return sum(self.data)/self.list_length()
# 方法4:计算列表元素方差
def list_variance(self, ddof = 1):
# Delta自由度 ddof 默认为 1;无偏样本方差
sum_squares = sum((x_i - self.list_mean())**2
for x_i in self.data)
return sum_squares/(self.list_length() - ddof)
# 创建ListStatistics对象实例
data = [8.8, 1.8, 7.8, 3.8, 2.8, 5.6, 3.9, 6.9]
float_list = ListStatistics(data)
# 调用方法
print("列表长度:", float_list.list_length())
print("列表和:", float_list.list_sum())
print("列表平均值:", float_list.list_mean())
print("列表方差:", float_list.list_variance())
print("列表方差 (ddof = 0):", float_list.list_variance(0))(4)父类、子类
- 父类,也称基类、超类,在继承关系中层次更高;
- 子类,也称派生类,可以继承父类的属性和方法,从而实现代码的重用和扩展。
python
# 父类,动物
class Animal:
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print(f"{self.name} is eating.")
def sleep(self):
print(f"{self.name} is sleeping.")
# 子类,鸡
class Chicken(Animal):
def __init__(self,name,age,color):
# 继承父类 name,age
super().__init__(name,age)
# 创建自己的属性
self.color = color
# 创建自己的方法
def lay_egg(self):
print(f"{self.name} is laying an egg.")
# 子类,兔
class Rabbit(Animal):
def __init__(self, name, age, speed):
super().__init__(name, age)
self.speed = speed
def jump(self):
print(f"{self.name} is jumping.")
# 子类,猪
class Pig(Animal):
def __init__(self, name, age, weight):
super().__init__(name, age)
self.weight = weight
def roll(self):
print(f"{self.name} is rolling around.")
# 构建对象,调用方法
chicken1 = Chicken("chicken1", 1, "white")
chicken1.eat(); chicken1.lay_egg()
rabbit1 = Rabbit("rabbit1", 2, 10)
rabbit1.sleep(); rabbit1.jump()
pig1 = Pig("pig1", 3, 100)
pig1.eat(); pig1.roll()