深入理解 LRU 缓存算法:原理、实现与应用
在计算机系统中,缓存是提升数据访问效率的核心技术,而缓存淘汰策略则决定了缓存空间满时如何选择 "待删除数据"。其中,LRU(Least Recently Used,最近最少使用)算法因逻辑直观、性能优异,成为工业界最常用的缓存淘汰策略之一。本文将从原理、实现到应用,全面解析 LRU 缓存算法。
一、LRU 算法的核心逻辑:什么是 "最近最少使用"?
LRU 的核心思想基于一个朴素的观察:最近被访问过的数据,未来被再次访问的概率更高;而长时间未被访问的数据,未来被访问的概率更低。因此,当缓存空间达到上限时,LRU 会优先删除 "最久未被使用" 的数据,为新数据腾出空间。
举个生活中的例子:手机后台 APP 的管理逻辑类似 LRU------ 最近使用的 APP 会留在内存中,长时间未点击的 APP 则会被系统自动关闭,以释放内存资源。
二、LRU 的关键技术需求:为何需要高效实现?
一个合格的 LRU 缓存需满足两大核心需求,否则会失去 "提升效率" 的意义:
- 快速查找:根据数据的 "键(Key)" 快速获取对应的 "值(Value)",时间复杂度需为 O (1);
- 快速更新与删除:
-
- 访问数据后,需将其标记为 "最近使用",更新顺序;
-
- 缓存满时,需快速删除 "最久未使用" 的数据。
这两类操作的时间复杂度也需尽可能低(理想为 O (1))。
三、LRU 的两种经典实现方案
不同数据结构的组合,决定了 LRU 的实现复杂度与性能。以下是两种最主流的实现方式,各有适用场景。
方案 1:基于 OrderedDict(Python 标准库)------ 快速实现
Python 的collections.OrderedDict是有序字典,能记住键值对的 "插入 / 访问顺序",其内置方法恰好契合 LRU 的需求,可快速实现 LRU 缓存。
核心原理
- OrderedDict.move_to_end(key):将指定键值对移到字典末尾,标记为 "最近使用";
- OrderedDict.popitem(last=False):从字典头部删除键值对,对应 "最久未使用";
- 字典本身支持 O (1) 时间的键值查找。
简化代码示例
python
import collections
class LRUCache(collections.OrderedDict):
def __init__(self, capacity: int):
super().__init__()
self.capacity = capacity # 缓存最大容量
def get(self, key: int) -> int:
if key not in self:
return -1 # 未命中返回-1
self.move_to_end(key) # 标记为最近使用
return self[key]
def put(self, key: int, value: int) -> None:
if key in self:
self.move_to_end(key) # 已存在则更新为最近使用
self[key] = value # 插入/更新值
if len(self) > self.capacity:
self.popitem(last=False) # 满了则删除最久未使用(头部)优缺点
- 优点:依赖标准库,代码极简,无需手动维护链表;
- 缺点:依赖 Python 特定数据结构,通用性较弱(如其他语言无 OrderedDict 时无法直接复用)。
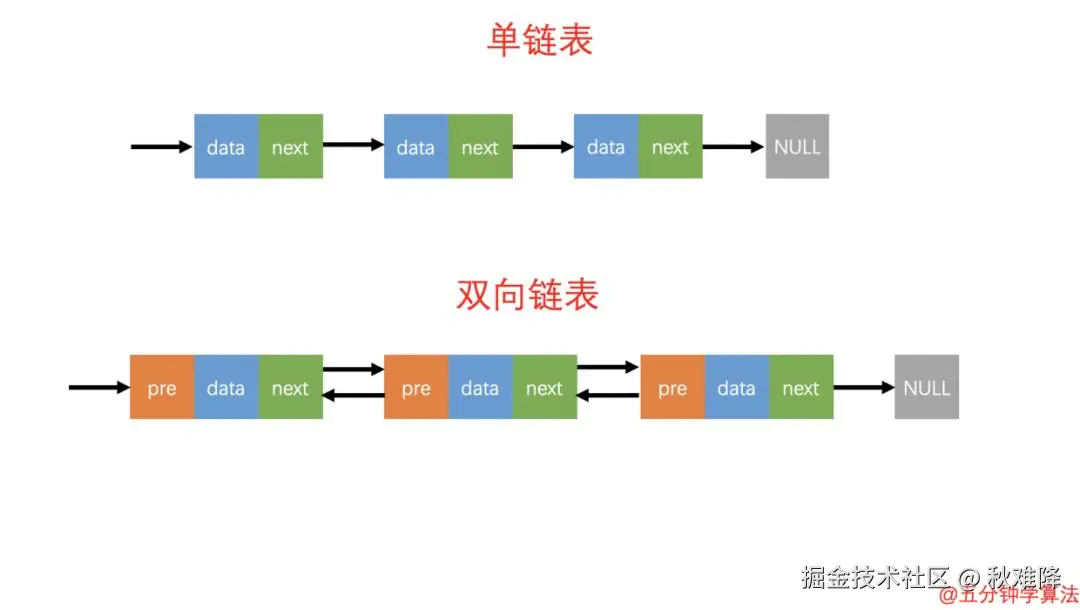
方案 2:双向链表 + 哈希表 ------ 通用高效实现
这是工业界最通用的 LRU 实现方案,通过 "双向链表维护顺序"+"哈希表快速查找" 的组合,满足所有 O (1) 操作需求,不依赖特定语言的库。
核心结构设计
- 双向链表:维护数据的访问顺序,头部为 "最近使用" 数据,尾部为 "最久未使用" 数据;
-
- 节点需存储key(删除尾部时需通过 key 同步删除哈希表数据)、value、prev(前驱指针)、next(后继指针);
-
- 引入 "伪头""伪尾"(哨兵节点),避免操作首尾节点时的边界判断(如空链表)。
- 哈希表(字典) :存储 "key→双向链表节点" 的映射,实现 O (1) 时间的键值查找。
核心逻辑与代码
python
class DLinkedNode:
"""双向链表节点"""
def __init__(self, key=0, value=0):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.cache = dict() # 哈希表:key→节点
self.head = DLinkedNode() # 伪头
self.tail = DLinkedNode() # 伪尾
self.head.next = self.tail # 初始化双向链表(伪头-伪尾相连)
self.tail.prev = self.head
self.capacity = capacity # 缓存容量
self.size = 0 # 当前缓存大小
def get(self, key: int) -> int:
"""获取数据:未命中返回-1,命中则标记为最近使用"""
if key not in self.cache:
return -1
node = self.cache[key]
self.move_to_head(node) # 移到头部(最近使用)
return node.value
def put(self, key: int, value: int) -> None:
"""插入/更新数据:满则删除最久未使用"""
if key not in self.cache:
# 1. 新增节点
node = DLinkedNode(key, value)
self.cache[key] = node
self.add_to_head(node) # 加到头部
self.size += 1
# 2. 缓存满,删除尾部(最久未使用)
if self.size > self.capacity:
removed_node = self.remove_tail()
self.cache.pop(removed_node.key) # 同步删除哈希表
self.size -= 1
else:
# 3. 更新已有节点
node = self.cache[key]
node.value = value
self.move_to_head(node) # 标记为最近使用
# 辅助方法:双向链表操作
def add_to_head(self, node):
"""将节点加到伪头之后(头部)"""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def remove_node(self, node):
"""从链表中删除指定节点"""
node.prev.next = node.next
node.next.prev = node.prev
def move_to_head(self, node):
"""将节点移到头部(先删后加)"""
self.remove_node(node)
self.add_to_head(node)
def remove_tail(self):
"""删除伪尾之前的节点(尾部,最久未使用)"""
node = self.tail.prev
self.remove_node(node)
return node优缺点
- 优点:不依赖特定库,通用性强(可移植到 Java、C++ 等语言),所有操作时间复杂度均为 O (1);
- 缺点:需手动维护双向链表,代码量略多,需注意指针操作的正确性。
四、LRU 的应用场景
LRU 算法因 "高效、直观" 的特点,广泛应用于计算机系统的各个层级:
- 内存缓存:操作系统的页面置换算法(如 Linux 的 Page Cache)、数据库的查询缓存(如 MySQL 的 Query Cache);
- 框架与中间件:Redis 的缓存淘汰策略(支持 LRU 作为可选策略)、Java 的 LinkedHashMap(底层实现类似 OrderedDict,可用于 LRU);
- 前端缓存:浏览器的缓存策略(如 HTTP 缓存的 "LRU" 模式)、前端框架的状态缓存(如 Vue 的 keep-alive 组件默认使用 LRU)。
五、LRU 的局限性与优化方向
LRU 虽优秀,但并非万能,存在以下局限性,实际应用中需结合场景优化:
- "缓存污染" 问题:若一次性访问大量 "只使用一次" 的数据(如批量查询历史日志),会将缓存中常用的数据挤掉,导致后续缓存命中率下降。
-
- 优化方案:使用LRU-K (需访问 K 次才进入缓存)或ARC(自适应替换缓存) ,减少临时数据对缓存的影响。
- 缺乏 "时间衰减" 机制:LRU 仅基于 "最近访问" 判断,无法区分 "1 小时前访问" 和 "1 天前访问" 的数据 ------ 若 1 天前的数 - 据偶尔被访问一次,会挤掉 1 小时前的高频数据。
-
- 优化方案:结合TTL(过期时间) 或使用LFU(最少使用次数) 算法,平衡 "访问时间" 与 "访问频率"。
六、总结
LRU 缓存算法是 "空间换时间" 思想的经典体现:通过双向链表(维护顺序)和哈希表(快速查找)的组合,实现了 O (1) 时间的查找、更新与删除,成为工业界缓存淘汰策略的 "默认选择"。
在实际开发中,若使用 Python,可优先基于OrderedDict快速实现;若需跨语言复用或更精细的控制,则推荐 "双向链表 + 哈希表" 的通用方案。同时,需根据业务场景(如是否有批量临时访问、是否需区分访问频率),选择 LRU 的优化变体(如 LRU-K、ARC),以最大化缓存效率。