文章目录
(一)简介
它是 视频生成中下一帧预测模型的输入帧上下文打包方法 的官方实现。
最大的特点本地可以跑,可以生成长视频,漂移较少。
- 在6GB显存的笔记本GPU上,使用130亿参数模型实现全帧率30FPS的数千帧长视频扩散生成
- 可在单台8×A100/H100计算节点上以64批量大小微调130亿参数视频模型(适合个人/实验室级实验)
- 个人RTX 4090显卡生成速度:未优化时2.5秒/帧,启用TEACache优化后1.5秒/帧
- 未使用时序蒸馏技术
- 虽为视频扩散模型,体验却接近图像扩散的流畅度
PS:记得之前尝试本地跑阿里的万象2.1文生视频,5秒钟视频耗时2小时。
而且只能跑得动文生视频(T2V),图生视频(I2V)只能在线体验......
(二)本地执行
由于作者提供了Windows下的一键安装包 (CUDA 12.6 + Pytorch 2.6)。
让使用变得非常简单了,整个过程完全是傻瓜式的(Python环境知识都不用)。
(2.1)下载
下载 One-Click Package (CUDA 12.6 + Pytorch 2.6) 一键包,
并解压到无空格和中文的目录,得到如下的结构。
(2.2)更新
执行update.bat来更新代码。
(2.3)运行
执行run.bat启动程序。
💡 提示,如果是首次运行,则模型将自动被下载。总共需要从HuggingFace下载超过30GB的数据。中途断了也没关系,再次执行可以断点续传的。
⚠️ 注意,如果您的网络环境无法访问HuggingFace,则需要事先做一些准备工作。
例如设置HF_ENDPOINT = https://hf-mirror.com 以便程序自动从镜像网站下载。
最终会启动成功,CMD日志大概如下:
bash
Currently enabled native sdp backends: ['flash', 'math', 'mem_efficient', 'cudnn']
Xformers is not installed!
Flash Attn is not installed!
Sage Attn is not installed!
Namespace(share=False, server='127.0.0.1', port=None, inbrowser=True)
Free VRAM 5.001953125 GB
High-VRAM Mode: False
Downloading shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 1333.43it/s]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 2.16it/s]
Fetching 3 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<?, ?it/s]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:01<00:00, 1.63it/s]
transformer.high_quality_fp32_output_for_inference = True
* Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.在浏览器中会打开如下的Gradio界面:
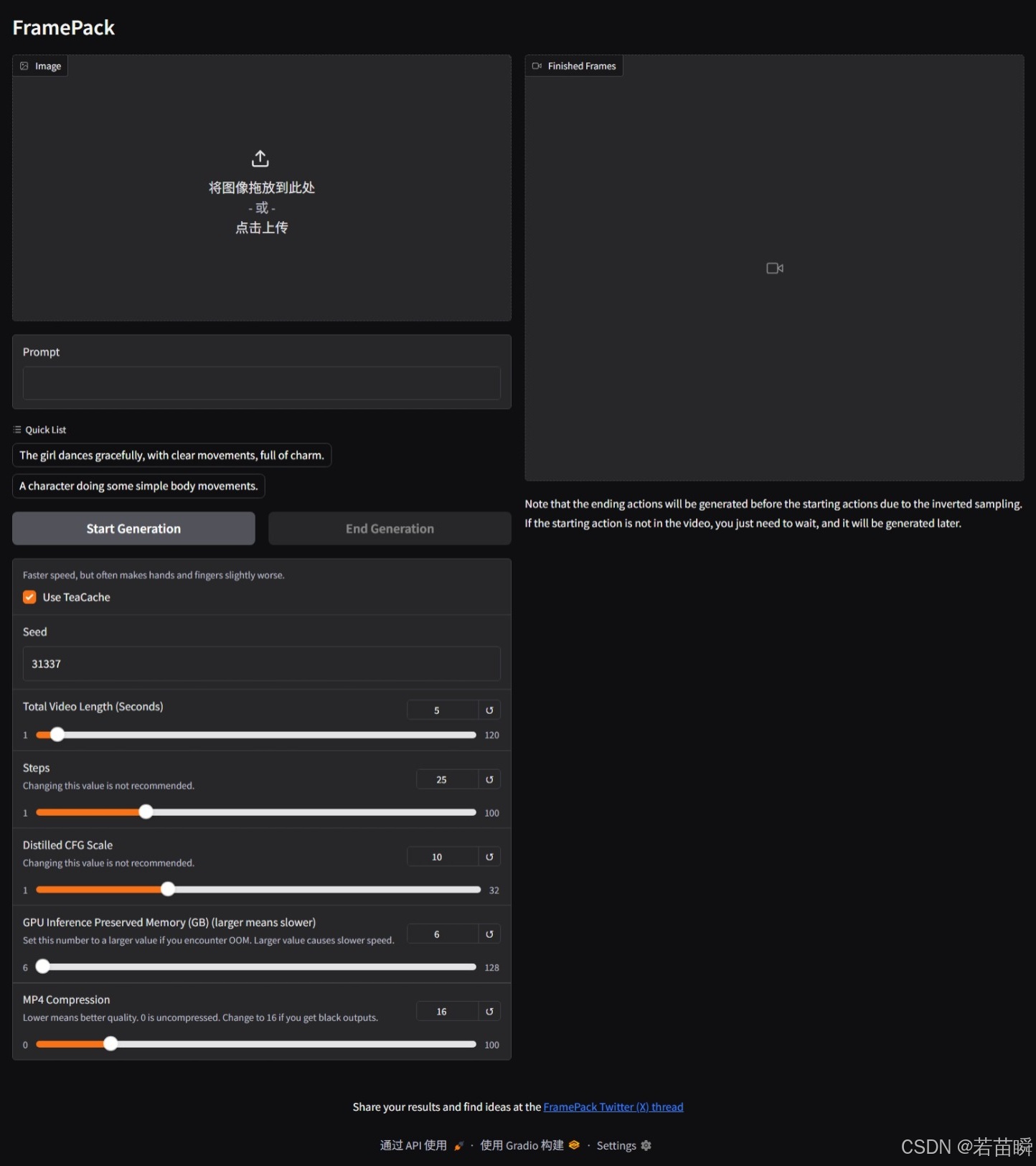
(2.4)生成
- 上传一张参考图片。
- 写入提示词。
- 点击
Start Generation开始生成视频。
bash
Unloaded DynamicSwap_LlamaModel as complete.
Unloaded CLIPTextModel as complete.
Unloaded SiglipVisionModel as complete.
Unloaded AutoencoderKLHunyuanVideo as complete.
Unloaded DynamicSwap_HunyuanVideoTransformer3DModelPacked as complete.
Loaded CLIPTextModel to cuda:0 as complete.
Unloaded CLIPTextModel as complete.
Loaded AutoencoderKLHunyuanVideo to cuda:0 as complete.
Unloaded AutoencoderKLHunyuanVideo as complete.
Loaded SiglipVisionModel to cuda:0 as complete.
latent_padding_size = 27, is_last_section = False
Unloaded SiglipVisionModel as complete.
Moving DynamicSwap_HunyuanVideoTransformer3DModelPacked to cuda:0 with preserved memory: 6 GB
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [09:05<00:00, 21.81s/it]
Offloading DynamicSwap_HunyuanVideoTransformer3DModelPacked from cuda:0 to preserve memory: 8 GB
Loaded AutoencoderKLHunyuanVideo to cuda:0 as complete.
Unloaded AutoencoderKLHunyuanVideo as complete.
Decoded. Current latent shape torch.Size([1, 16, 9, 88, 68]); pixel shape torch.Size([1, 3, 33, 704, 544])
......
latent_padding_size = 9, is_last_section = False
Moving DynamicSwap_HunyuanVideoTransformer3DModelPacked to cuda:0 with preserved memory: 6 GB
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [07:37<00:00, 18.29s/it]
Offloading DynamicSwap_HunyuanVideoTransformer3DModelPacked from cuda:0 to preserve memory: 8 GB
Loaded AutoencoderKLHunyuanVideo to cuda:0 as complete.
Unloaded AutoencoderKLHunyuanVideo as complete.
Decoded. Current latent shape torch.Size([1, 16, 99, 88, 68]); pixel shape torch.Size([1, 3, 393, 704, 544])
latent_padding_size = 0, is_last_section = True
Moving DynamicSwap_HunyuanVideoTransformer3DModelPacked to cuda:0 with preserved memory: 6 GB
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [07:37<00:00, 18.29s/it]
Offloading DynamicSwap_HunyuanVideoTransformer3DModelPacked from cuda:0 to preserve memory: 8 GB
Loaded AutoencoderKLHunyuanVideo to cuda:0 as complete.
Unloaded AutoencoderKLHunyuanVideo as complete.生成过程中会不断更新进度,预览当前的结果。
完成后得到最终结果视频。
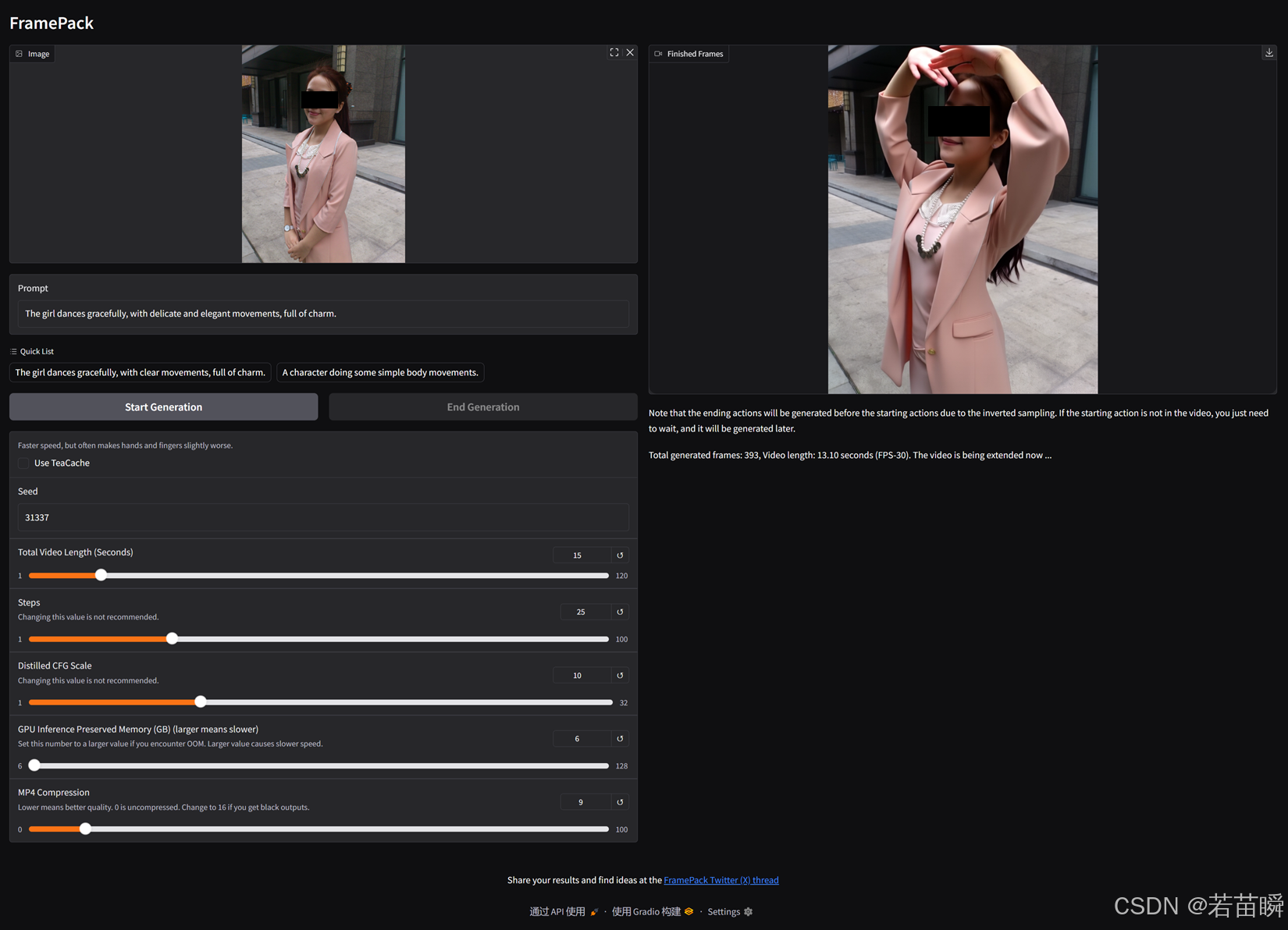
可以下载,或者到项目下的webui\outputs目录中查看(最后一个才是最终结果)。
(三)注意
(3.1)效率
虽然笔记本3060-6GB + RAM-32GB可以跑,但我自己测试速度非常慢50s/it。
而且每次生成1秒视频(有进度条)之间的时间非常久。
上面的例子是台式机4060TI-16GB,RAM-64GB跑的,生成了15秒的视频。
因为关闭了TeaCache,所以显得稍慢。如果打开则大概可以到12s/it左右的速度。
整体速度还能接受(比之前的2小时生成5秒快多了)。
作者对于速度很慢的建议:
- 用更快更大的内存。
- 用SSD代替HDD。
- 设置虚拟内存到最快的磁盘上,并保持足够的容量。
基本上相当于什么都没说。也就是不改变硬件的条件下,没啥可以优化的。
(3.2)TeaCache
不勾选慢50%,然而手指等细节动作也没有变自然,手心变手背,手表左右瞬移......
(3.3)效果
比较合适背景没啥变化的场景。
当然和在线给钱的效果差得有点远。