中通快递作为国内物流行业的领军企业,自2002年成立以来,始终秉持"客户要求,中通使命"的服务宗旨,致力于为客户提供高效、优质的物流服务。凭借其庞大的物流网络、先进的信息技术以及卓越的运营管理,中通快递在激烈的市场竞争中脱颖而出,业务范围覆盖全国乃至全球150多个国家和地区。
在数字化时代,数据已成为企业发展的重要资产。通过获取和分析中通快递在全国范围内的服务网点分布信息,不仅可以深入了解其市场布局策略,还能为用户提供更加便捷的服务。本文将详细探讨如何利用 POST 请求从中通快递官方网站或其公开 API 接口获取这些关键数据,并展示使用 Python 的 requests 库发送 POST 请求的具体方法,从而提取出详细的门店地址、营业时间、联系方式等信息。这些数据涵盖了中通快递在全国 300 多个城市的服务网点,通过解析 API 返回的 JSON 格式响应数据进行处理,最终整理出结构化的服务网点列表。
通过对这些服务网点数据的深入分析,我们可以全面掌握中通快递在国内市场的布局特点与发展趋势。例如,通过分析各城市的网点密度、选址特征以及周边消费环境,可以精准洞察不同地区的物流需求差异,为中通未来的服务优化、新网点开设规划以及市场拓展策略提供有力的数据支持与决策依据。同时,用户也可以借助这些数据,方便快捷地查询到最近的中通快递网点,实现快速寄件或预约上门取件服务,极大地提升了用户体验。
中通快递网点位置查询:服务网点 - 中通快递
我们第一步先找到服务网点数据的存储位置,然后看3个关键部分标头、 负载、 预览;
**标头:**通常包括URL的连接,也就是目标资源的位置;
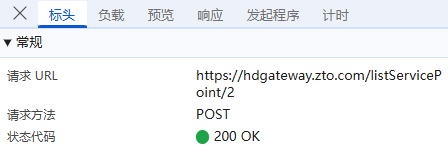
**负载:**对于POST请求:负载通常包含了传递的参数,这里我们可以看到它的传参包括各级行政区名称,是明文传输;
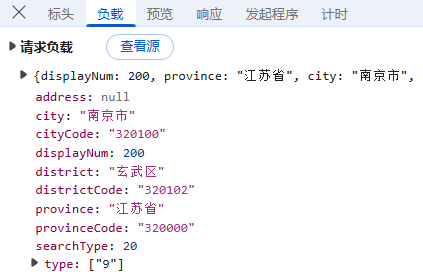
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
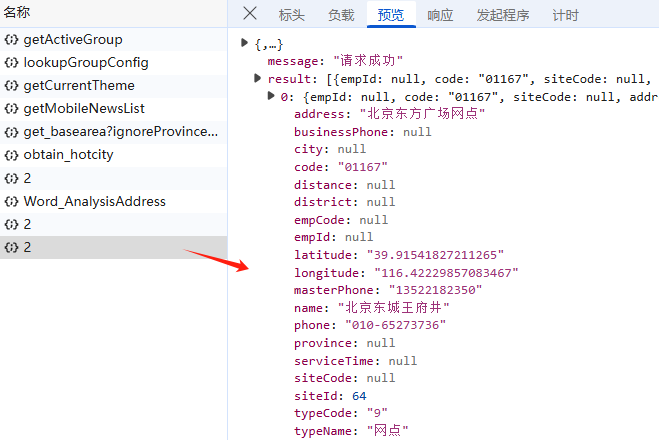
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应行政区数据存储位置,生成一个行政区对应关系字典;
- 我们通过改变查询负载的内容(各级行政区名称),来遍历全国服务网点数据,获取所有服务网点的相关标签数据;
- 坐标转换,通过coord-convert库实现BD-09转WGS84;
**第一步:**通过页面测试发现,中通服务网点查询页面采用的策略是,通过三级行政区明文这样的结构数据,进行查询的;

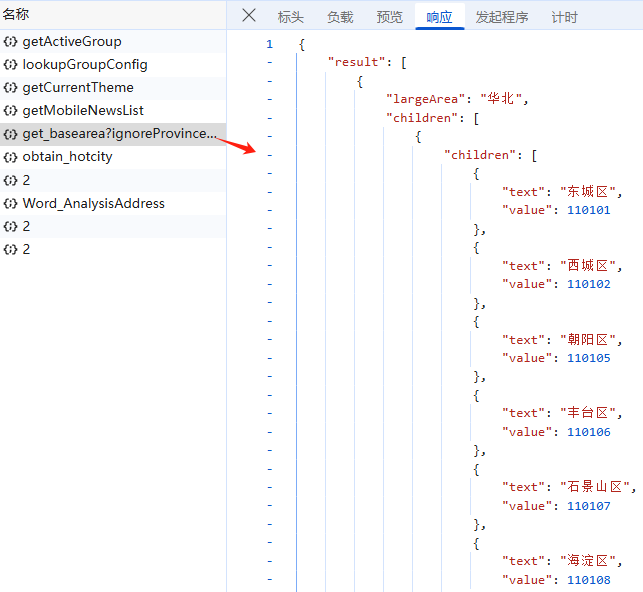
接下来,我们找到行政区划树的数据存储位置,通过脚本把数据另存为本地json,通过读取json的三级行政区字典进行遍历全国服务网点信息;
完整代码#运行环境 Python 3.11
python
import requests
import json
# 请求的URL
url = "https://hdgateway.zto.com/get_basearea?ignoreProvince=710000-820000-990000"
# 请求头部,可能需要根据实际情况调整
headers = {
'Content-Type': 'application/json',
}
# 发送POST请求
response = requests.post(url, headers=headers)
# 检查响应状态码
if response.status_code == 200:
# 将响应内容解析为JSON格式
data = response.json()
# 将数据保存到本地文件
with open('basearea_data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("数据已成功保存到 'basearea_data.json'")
else:
print(f"请求失败,状态码:{response.status_code}, 响应内容:{response.text}")等待脚本执行完成,将输出一个json文件basearea_data.json,为了更直观的展示,我们可以复制json里面的数据,并放在json可视化的工具里进行展示,这里用的在线工具是编辑器 | JSON For You | 在线JSON工具,我们可以看到三级行政区及其行政区编码;
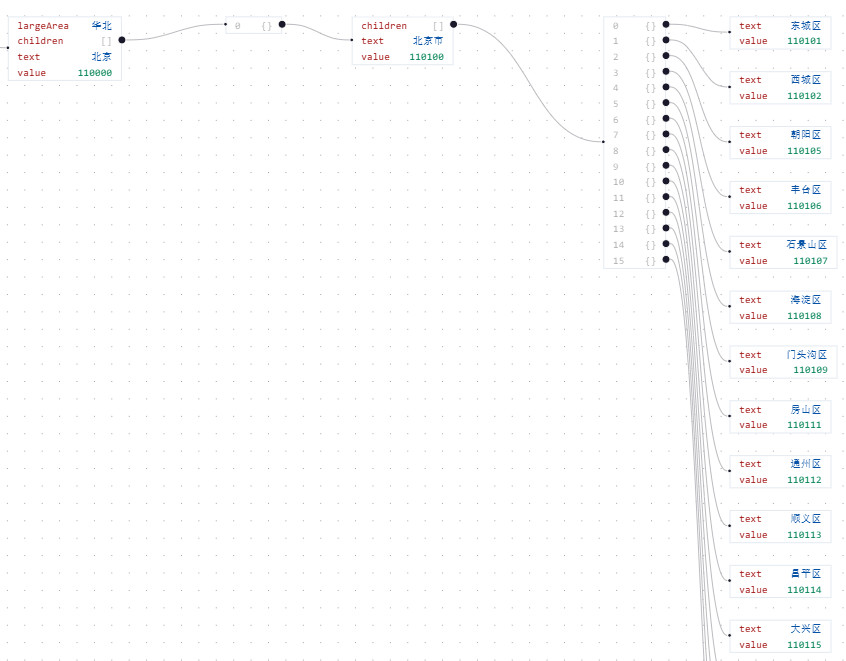
**第二步:**读取之前生成的JSON文件,并使用这些数据来查询第三级(网点)信息,并根据标签进行保存,另存为csv;
方法思路
- 读取本地的 basearea_data.json 行政区划文件;
- 遍历该文件的层级结构,提取每个区县的名称和代码;
- 对于每个区县,调用申通的网点查询 API;
- 收集所有区县的网点数据;
- 将汇总的所有网点数据保存到一个 CSV 文件。
完整代码#运行环境 Python 3.11
python
import requests
import json
import pandas as pd
import os
import time
# --- 文件路径配置 ---
AREA_TREE_FILE = "basearea_data.json"
OUTPUT_CSV_FILE = "all_zto_sites_data.csv"
# --- API 配置 ---
SITE_API_URL = "https://hdgateway.zto.com/listServicePoint/2"
SITE_API_HEADERS = {
"Content-Type": "application/json",
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0"
}
# --- 网点查询相关函数 ---
def fetch_zto_site_data(payload):
"""
发送 POST 请求获取中通网点数据。
返回一个列表(如果成功)或 None。
"""
url = SITE_API_URL
headers = SITE_API_HEADERS
# 构建最终 payload,完全匹配要求的格式
final_payload = {
"address": None,
"city": payload["city"],
"cityCode": str(payload["cityCode"]),
"displayNum": 200,
"district": payload["district"],
"districtCode": str(payload["districtCode"]),
"province": payload["province"],
"provinceCode": str(payload["provinceCode"]),
"searchType": 20,
"type": ["9"]
}
try:
# 打印完整的三级行政区划信息
print(f"\n正在请求数据:")
print(f"省份: {payload['province']} ({payload['provinceCode']})")
print(f"城市: {payload['city']} ({payload['cityCode']})")
print(f"区县: {payload['district']} ({payload['districtCode']})")
response = requests.post(url, headers=headers, json=final_payload, timeout=10)
response.raise_for_status()
# 修改这里以正确处理响应
site_data_list = response.json().get("result", [])
if isinstance(site_data_list, list):
print(f" -> 成功获取 {len(site_data_list)} 条网点数据。")
return site_data_list
else:
print(
f" -> 警告: API返回数据结构与预期不符(不是列表)。原始响应前200字符: {response.text[:200]}{'...' if len(response.text) > 200 else ''}")
return []
except requests.exceptions.RequestException as e:
print(f" -> 请求发生错误: {e}")
return []
except json.JSONDecodeError:
print(" -> 错误: 无法解析响应为 JSON 格式。")
return []
except Exception as e:
print(f" -> 发生未知错误: {e}")
return []
def save_data_to_csv(data_list, filename):
"""
将数据列表追加写入 CSV 文件。
"""
if not data_list:
print("没有数据可保存到 CSV。")
return
try:
for item in data_list:
# 添加查询信息
item["Query_Province"] = item.get("Query_Province")
item["Query_ProvinceCode"] = item.get("Query_ProvinceCode")
item["Query_City"] = item.get("Query_City")
item["Query_CityCode"] = item.get("Query_CityCode")
item["Query_District"] = item.get("Query_District")
item["Query_DistrictCode"] = item.get("Query_DistrictCode")
df = pd.DataFrame(data_list)
mode = 'a' if os.path.exists(filename) and os.path.getsize(filename) > 0 else 'w'
header = not os.path.exists(filename) or os.path.getsize(filename) == 0
df.to_csv(filename, mode=mode, header=header, index=False, encoding='utf-8-sig')
print(f"已追加 {len(data_list)} 条数据到 {filename}")
except Exception as e:
print(f"保存 CSV 文件时发生错误: {e}")
# --- 行政区划数据处理函数 ---
def load_area_tree_data(filename=AREA_TREE_FILE):
if not os.path.exists(filename):
print(f"错误: 行政区划数据文件未找到: {filename}")
return None
try:
print(f"正在从文件加载行政区划数据: {filename}")
with open(filename, 'r', encoding='utf-8') as f:
full_data = json.load(f)
area_data = []
def recurse(items, province=None, provinceCode=None, city=None, cityCode=None):
for item in items:
# 处理省份层级
if "largeArea" in item: # 这是省份层级
province = item.get("text")
provinceCode = item.get("value")
# 处理城市层级
if "children" in item:
for city_item in item["children"]:
city = city_item.get("text")
cityCode = city_item.get("value")
# 处理区县层级
if "children" in city_item:
for district_item in city_item["children"]:
area_data.append({
"province": province,
"provinceCode": provinceCode,
"city": city,
"cityCode": cityCode,
"district": district_item.get("text"),
"districtCode": district_item.get("value"),
"displayNum": 200
})
recurse(full_data["result"])
print(f"成功加载 {len(area_data)} 个区县数据")
return area_data
except json.JSONDecodeError:
print(f"错误: 无法解析文件 {filename} 为 JSON 格式。")
return None
except Exception as e:
print(f"加载行政区划文件时发生错误: {e}")
return None
# --- 主执行逻辑 ---
def fetch_all_zto_sites():
all_site_data = []
area_data_list = load_area_tree_data(AREA_TREE_FILE)
if not area_data_list:
print("行政区划数据加载失败,无法进行网点查询。")
return
print(f"找到 {len(area_data_list)} 个区县需要查询。")
save_data_to_csv([], OUTPUT_CSV_FILE) # 创建空文件
if area_data_list:
total_districts = len(area_data_list)
print("\n开始按区县查询网点数据...")
for i, payload in enumerate(area_data_list, 1):
print(f"\n处理第 {i}/{total_districts} 个区县...")
site_data = fetch_zto_site_data(payload)
if site_data:
for site in site_data:
site["Query_Province"] = payload["province"]
site["Query_ProvinceCode"] = payload["provinceCode"]
site["Query_City"] = payload["city"]
site["Query_CityCode"] = payload["cityCode"]
site["Query_District"] = payload["district"]
site["Query_DistrictCode"] = payload["districtCode"]
save_data_to_csv(site_data, OUTPUT_CSV_FILE)
time.sleep(0.2) # 添加延时,避免请求过快
print(f"\n所有网点数据已保存至 {OUTPUT_CSV_FILE}")
else:
print("未找到区县信息,跳过网点查询。")
if __name__ == "__main__":
fetch_all_zto_sites()获取数据标签如下,address(地址)、省(province)、市(city)、区(district)、latitude,longitude(经纬度)、name(网点名称)、phone(电话)、typename(网点类型)其他一些非关键标签,这里省略;
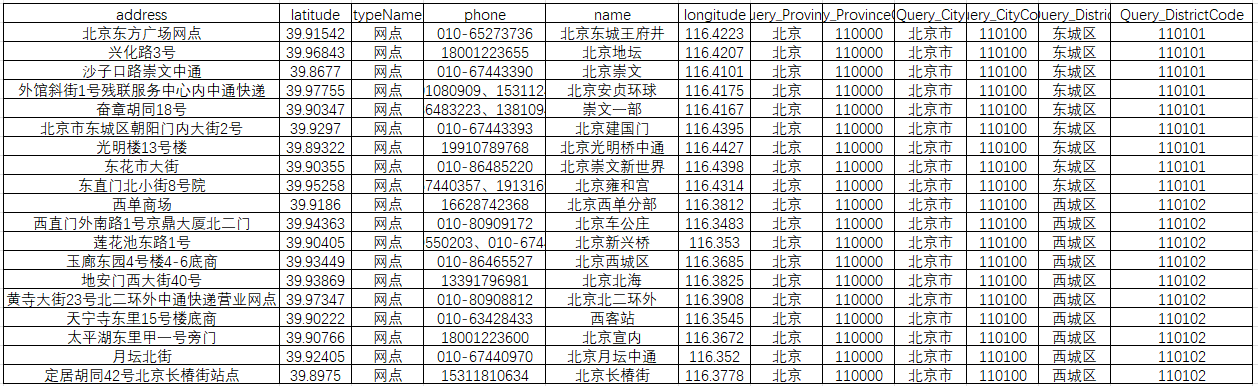
第三步: 坐标系转换,由于中通快递服务网点数据使用的是百度坐标系(BD-09),为了在ArcGIS上准确展示而不发生偏移,我们需要将服务网点的坐标从BD-09转换为WGS-84坐标系。我们可以利用coord-convert库中的bd2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的服务网点坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
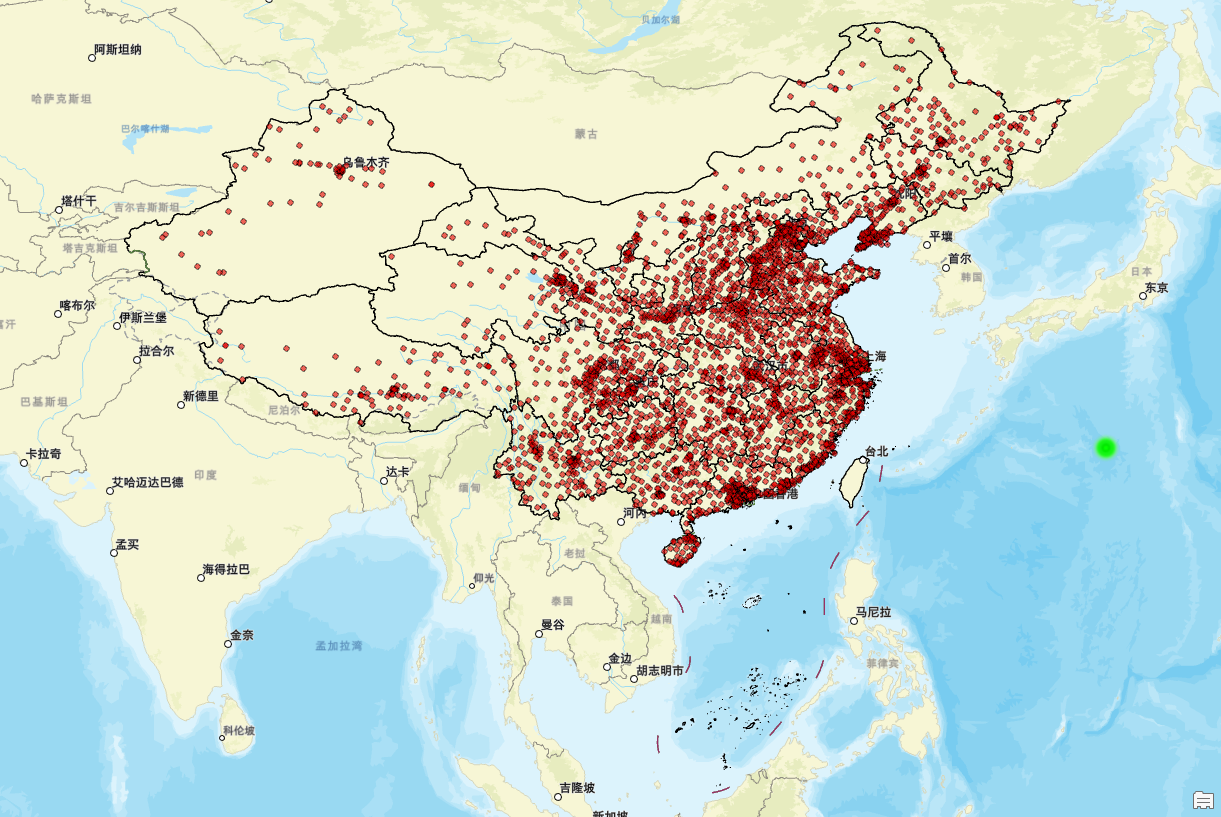
接下来,我们进行看图说话:
从这张地图上可以看出,中通快递在中国的分布具有明显的区域特征。其服务网点覆盖了全国大部分地区,但分布并不均匀。
首先,东部沿海地区是中通快递最密集的区域。在广东、江苏、浙江、山东等经济发达、人口稠密的省份,网点密度极高,显示出对这些高需求市场的重点布局。例如,在珠江三角洲和长江三角洲这两个中国经济最为活跃的区域,中通快递通过设立大量的网点来满足当地企业及居民对于快速物流服务的需求。特别是在一些大型城市如广州、深圳、上海等地,几乎每个区都有多个网点,确保了服务的便捷性和时效性。
其次,中部地区的网点分布较为密集,但略低于东部沿海。河南、湖北、湖南等省份作为重要的物流中转区域,也拥有较多的中通快递网点,体现出其在全国网络中的重要地位。比如,武汉作为华中地区的交通枢纽,不仅自身对快递服务有着庞大的需求,还承担着连接东西部的重要作用,因此中通在此设置了众多的服务点以提高物流效率。
再次,西部地区的网点相对稀疏 。尽管四川、云南、陕西等地有一定程度的覆盖,但由于地理环境复杂(如山地、高原)、交通不便以及经济发展水平较低,中通快递在这些地区的布点较少。这反映出西部地区虽然市场需求逐渐增长,但由于基础设施建设滞后等因素,导致物流成本较高,从而影响了网点的扩展速度。
此外,在偏远地区如西藏、青海、新疆的部分区域,中通快递的覆盖非常有限。这些地区因人口稀少、地理位置偏远,导致运营成本较高,因此布局较少。然而,随着国家对西部大开发战略的推进以及交通条件的逐步改善,预计未来这些地区的物流服务将得到进一步提升。
最后,城市与农村之间存在明显差异。大城市及其周边区域网点密集,而小城镇和农村地区虽然也有一定覆盖,但密度明显偏低,反映出中通快递在城乡之间的资源配置不均。例如,在北京、上海这样的超大城市,几乎每一个社区都有至少一个中通快递的服务点;而在一些偏远山区或乡村,则可能需要到镇上的集中点去取件,这种差距反映了当前中国物流市场发展的不平衡现状。
综上所述,中通快递的分布呈现出"东密西疏、城强乡弱"的格局。这种分布不仅体现了市场需求的差异,也反映了物流企业在不同区域的战略部署。随着国家政策的支持和技术的进步,预计中通快递在未来将进一步优化其网络布局,缩小城乡服务差距,为更多用户提供优质高效的物流解决方案。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。