文件的规范拆分和写法
把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处:
- 可以让项目文件变得更加规范和清晰
- 可以让项目文件更加容易维护,修改某一个功能的时候,只需要修改一个文件,而不需要修改多个文件。
- 文件变得更容易复用,部分通用的文件可以单独拿出来,进行其他项目的复用。
一、文件的组织
1. 项目核心代码组织
- src/(source的缩写) :存放项目的核心源代码。按照机器学习项目阶段进一步细分:
- src/data/ :放置与数据相关的代码。
src/data/load_data.py:负责从各类数据源(如文件系统、数据库、API 等)读取原始数据。src/data/preprocess.py:进行数据清洗(处理缺失值、异常值)、数据转换(标准化、归一化、编码等)操作。src/data/feature_engineering.py:根据业务和数据特点,创建新特征或对现有特征进行选择、优化。
- src/models/ :关于模型的代码。
src/models/model.py:定义模型架构,比如神经网络结构、机器学习算法模型设定等。src/models/train.py:设置模型超参数,并执行训练过程,保存训练好的模型。src/models/evaluate.py:使用合适的评估指标(如准确率、召回率、均方误差等),在测试集上评估模型性能,生成评估报告。src/models/predict.py或src/models/inference.py:利用训练好的模型对新数据进行预测。
- src/utils/ :存放通用辅助函数代码,可进一步细分:
src/utils/io_utils.py:包含文件读写相关帮助函数,比如读取特定格式文件、保存数据到文件等。src/utils/logging_utils.py:实现日志记录功能,方便记录项目运行过程中的信息,便于调试和监控。src/utils/math_utils.py:特定的数值计算函数,像自定义的矩阵运算、统计计算等。src/utils/plotting_utils.py:绘图工具函数,用于生成数据可视化图表(如绘制损失函数变化曲线、特征分布直方图等 )。
- src/data/ :放置与数据相关的代码。
2. 配置文件管理
- config/ 目录 :集中存放项目的配置文件,方便管理和切换不同环境(开发、测试、生产)的配置。
config/config.py或config/settings.py:以 Python 代码形式定义配置参数。config/config.yaml或config/config.json:采用 YAML 或 JSON 格式,清晰列出文件路径、模型超参数、随机种子、API 密钥等可配置参数。.env文件:通常放在项目根目录,用于存储敏感信息(如数据库密码、API 密钥等),在代码中通过环境变量的方式读取,一般会被.gitignore忽略,防止敏感信息泄露。
3. 实验与探索代码
-
notebooks/ 或 experiments/ 目录:用于初期的数据探索、快速实验、模型原型验证。
notebooks/initial_eda.ipynb:在项目初期,使用 Jupyter Notebook 进行数据探索与可视化,了解数据特性,分析数据分布、相关性等。experiments/model_experimentation.py:编写脚本对不同模型架构、超参数组合进行快速实验,对比实验结果,寻找最优模型设置。
这部分往往是最开始的探索阶段,后面跑通了后拆分成了完整的项目,留作纪念用。
4. 项目产出物管理
- data/ 目录 :存放项目相关数据。
data/raw/:放置从外部获取的未经处理的原始数据,保持数据原始状态。data/processed/:存放经过预处理(清洗、转换、特征工程等操作)后的数据,供模型训练和评估使用。data/interim/:(可选)保存中间处理结果,比如数据清洗过程中生成的临时文件、特征工程中间步骤产生的数据等。
- models/ 目录 :专门存放训练好的模型文件,根据模型保存格式不同,可能是
.pkl(Python pickle 格式,常用于保存 sklearn 模型 )、.h5(常用于保存 Keras 模型 )、.joblib等。 - reports/ 或 output/ 目录 :存储项目运行产生的各类报告和输出文件。
reports/evaluation_report.txt:记录模型评估的详细结果,包括各项评估指标数值、模型性能分析等。reports/visualizations/:存放数据可视化图片,如损失函数收敛图、预测结果对比图等。output/logs/:保存项目运行日志文件,记录项目从开始到结束过程中的关键信息,如训练开始时间、训练过程中的损失值变化、预测时间等。
总结一下通用的拆分起步思路:
-
首先,按照机器学习的主要工作流程(数据处理、训练、评估等)将代码分离到不同的
.py文件中。 这是最基本也是最有价值的一步。 -
然后,创建一个
utils.py来存放通用的辅助函数。 -
考虑将所有配置参数集中到一个
config.py文件中。 -
为你的数据和模型产出物创建专门的顶层目录,如
data/和models/,将它们与你的源代码(通常放在src/目录)分开。
当遵循这些通用的拆分思路和原则时,项目结构自然会变得清晰。
二、以心脏病数据集为例进行拆分
import pandas as pd
import numpy as np
import sys
import os
from typing import Tuple, Dict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import time
import joblib # 用于保存模型
from typing import Tuple # 用于类型注解
# 加载数据
def load_data(file_path: str): #传入路径为字符串路径
"""加载数据文件
Args:
file_path: 数据文件路径
Returns:
加载的数据框
"""
return pd.read_csv(file_path)
def encode_categorical_features(data):
"""对分类特征进行编码
Args:
data: 原始数据框
Returns:
编码后的数据框和编码映射字典
"""
# 有序特征使用字典映射进行标签编码
ordinal_mappings = {
'cp': {0: 0, 1: 1, 2: 2, 3: 3},
'restecg': {0: 0, 1: 1, 2: 2},
'slope': {0: 0, 1: 1, 2: 2},
'ca': {0: 0, 1: 1, 2: 2, 3: 3, 4: 4},
}
data_encoded = data.copy()
for feature, mapping in ordinal_mappings.items():
data_encoded[feature] = data[feature].map(mapping)
# 独热编码(仅对thal特征)
thal_mapping = {1: 0, 2: 1, 3: 2}
data_encoded['thal'] = data['thal'].map(thal_mapping)
data_encoded = pd.get_dummies(data_encoded, columns=['thal'], prefix='thal', dtype=int)
# 存储映射关系
mappings = {
'ordinal_mappings': ordinal_mappings,
'thal_mapping': thal_mapping
}
return data_encoded, mappings
def handle_missing_values(data: pd.DataFrame) -> pd.DataFrame:
"""处理缺失值
Args:
data: 包含缺失值的数据框
Returns:
处理后的数据框
"""
data_clean = data.copy()
discrete_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal', 'target']
continuous_features = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
# 离散特征用众数补全
for feature in discrete_features:
if feature in data.columns and data[feature].isnull().any():
mode_value = data[feature].mode()[0]
data_clean[feature].fillna(mode_value, inplace=True)
# 连续特征用中位数补全
for feature in continuous_features:
if feature in data.columns and data[feature].isnull().any():
median_value = data[feature].median()
data_clean[feature].fillna(median_value, inplace=True)
return data_clean
def scale_features(data):
"""特征缩放处理
Args:
data: 需要缩放的数据框
Returns:
缩放后的数据框
"""
data_scaled = data.copy()
norm_features = ['oldpeak'] # 归一化特征
std_features = ['age', 'trestbps', 'chol', 'thalach'] # 标准化特征
# 归一化处理
if 'oldpeak' in data.columns:
minmax_scaler = MinMaxScaler()
data_scaled[norm_features] = minmax_scaler.fit_transform(data[norm_features])
# 标准化处理
std_scaler = StandardScaler()
data_scaled[std_features] = std_scaler.fit_transform(data[std_features])
return data_scaled
if __name__ == "__main__":
# 测试代码
data = load_data("heart.csv")
data_encoded, mappings = encode_categorical_features(data)
data_clean = handle_missing_values(data_encoded)
data_scaled = scale_features(data_clean)
print("预处理已完成")
# 训练模型
def prepare_data():
"""准备训练数据
Returns:
训练集和测试集的特征和标签
"""
# 加载和预处理数据
data = load_data("heart.csv")
data_encoded, _ = encode_categorical_features(data)
data_clean = handle_missing_values(data_encoded)
# 分离标签与特征
X = data_clean.drop(['target'], axis=1)
y = data_clean['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def train_model(X_train, y_train, model_params=None):
"""训练随机森林模型
Args:
X_train: 训练特征
y_train: 训练标签
model_params: 模型参数字典
Returns:
训练好的模型
"""
if model_params is None:
model_params = {'random_state': 42}
model = RandomForestClassifier(**model_params)
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
"""评估模型性能
Args:
model: 训练好的模型
X_test: 测试特征
y_test: 测试标签
"""
y_pred = model.predict(X_test)
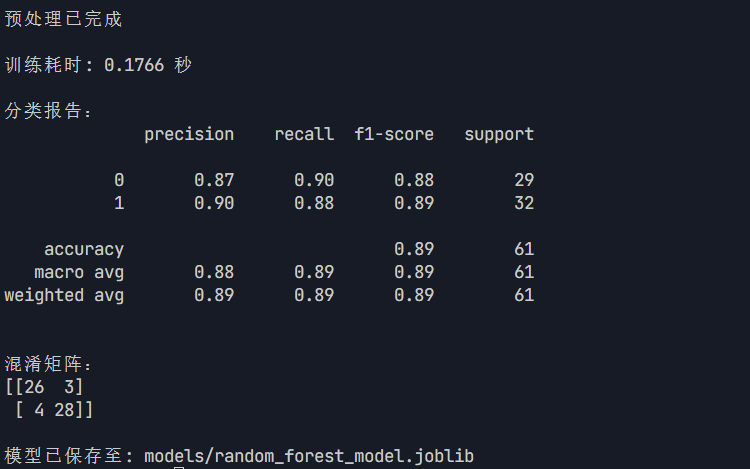
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
def save_model(model, model_path: str):
"""保存模型
Args:
model: 训练好的模型
model_path: 模型保存路径
"""
os.makedirs(os.path.dirname(model_path), exist_ok=True)
joblib.dump(model, model_path)
print(f"\n模型已保存至: {model_path}")
if __name__ == "__main__":
# 准备数据
X_train, X_test, y_train, y_test = prepare_data()
# 记录开始时间
start_time = time.time()
# 训练模型
model = train_model(X_train, y_train)
# 记录结束时间
end_time = time.time()
print(f"\n训练耗时: {end_time - start_time:.4f} 秒")
# 评估模型
evaluate_model(model, X_test, y_test)
# 保存模型
save_model(model, "models/random_forest_model.joblib") 生成结果为: