博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
python语言、django框架、TensorFlow、CNN卷积神经网络模型、Echarts可视化
深度学习实战:python动物识别分类检测系统 计算机视觉 Django框架 CNN算法 深度学习 卷积神经网络 TensorFlow 毕业设计(建议收藏)✅
2、项目界面
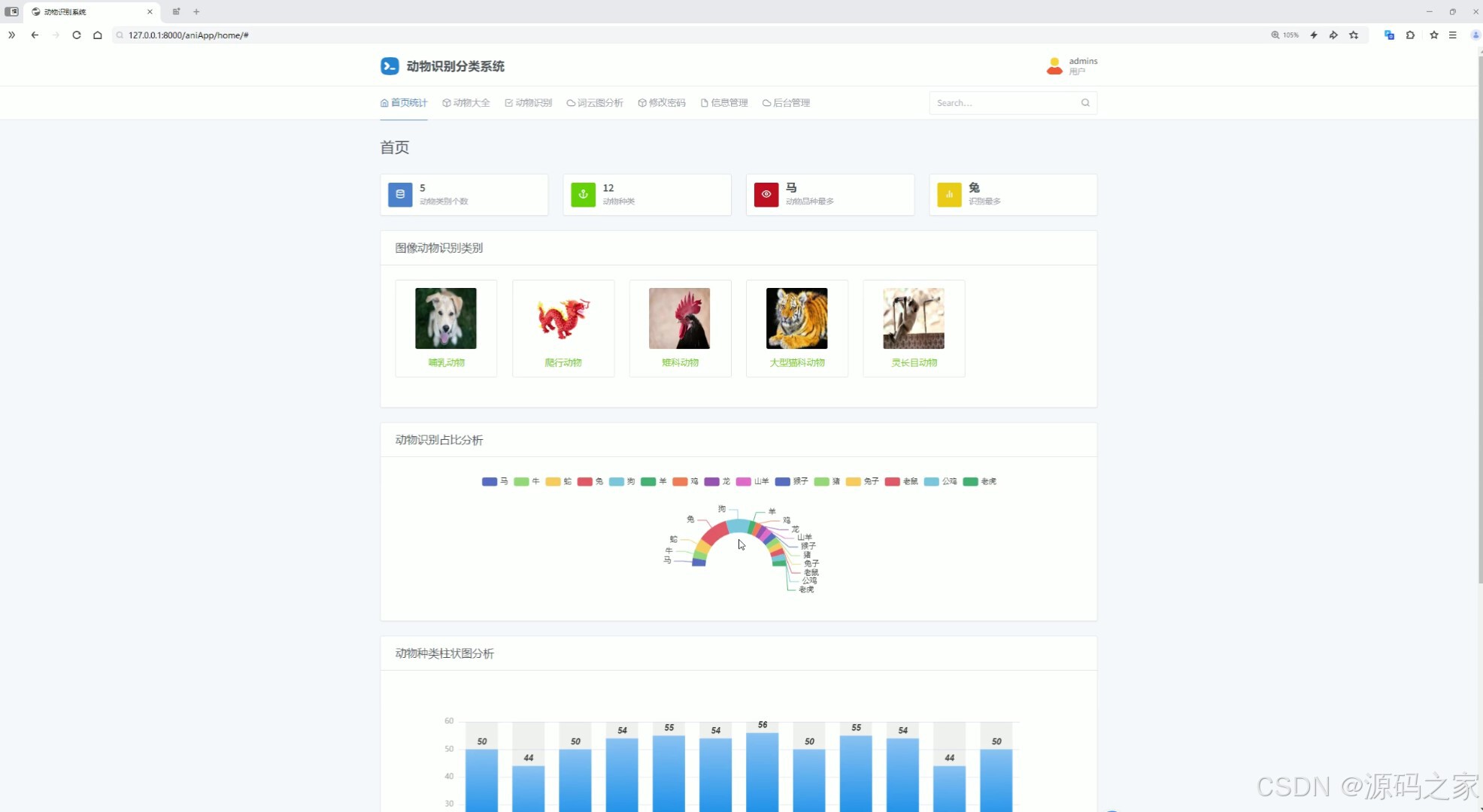
(1)首页
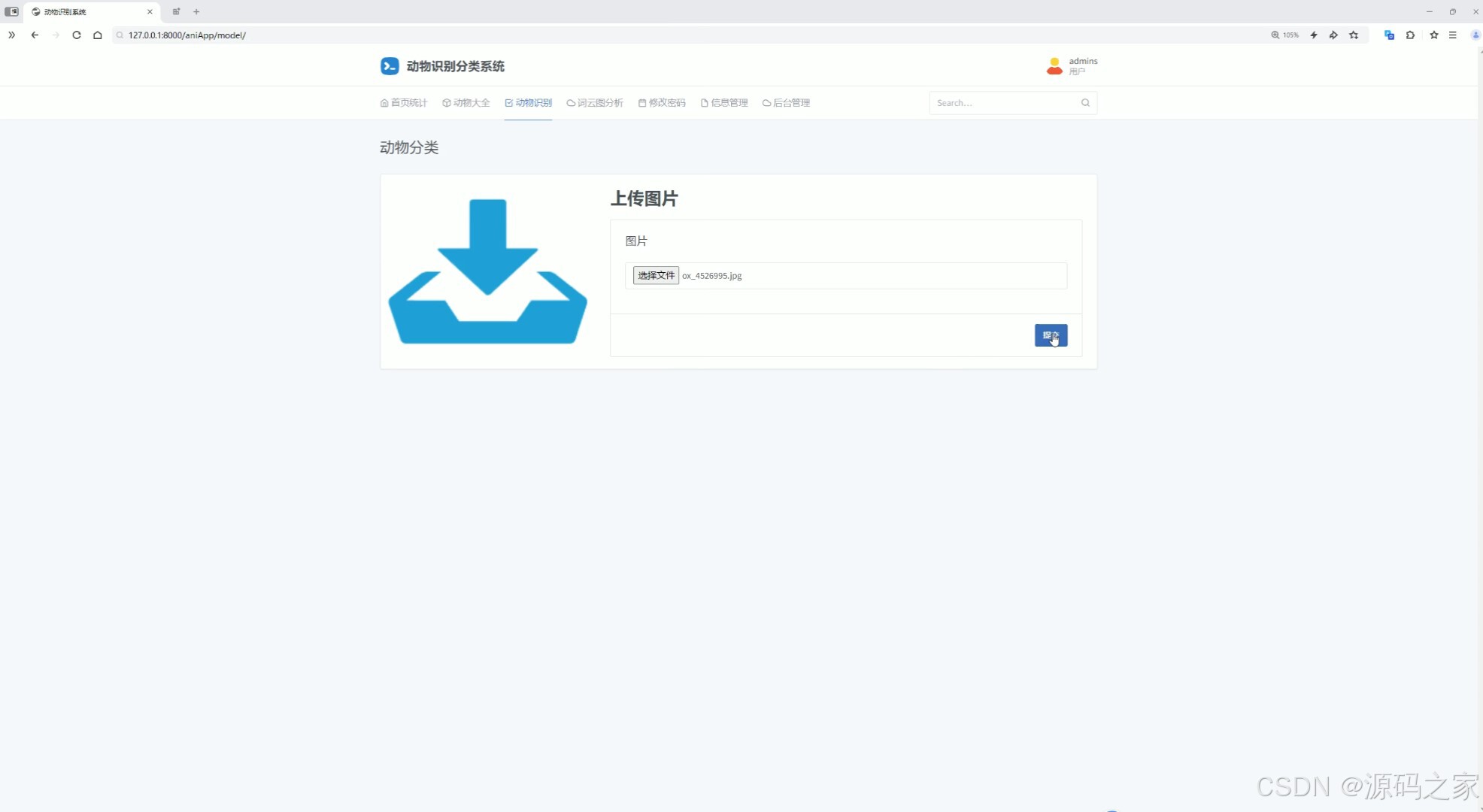
(2)上传图片检测识别
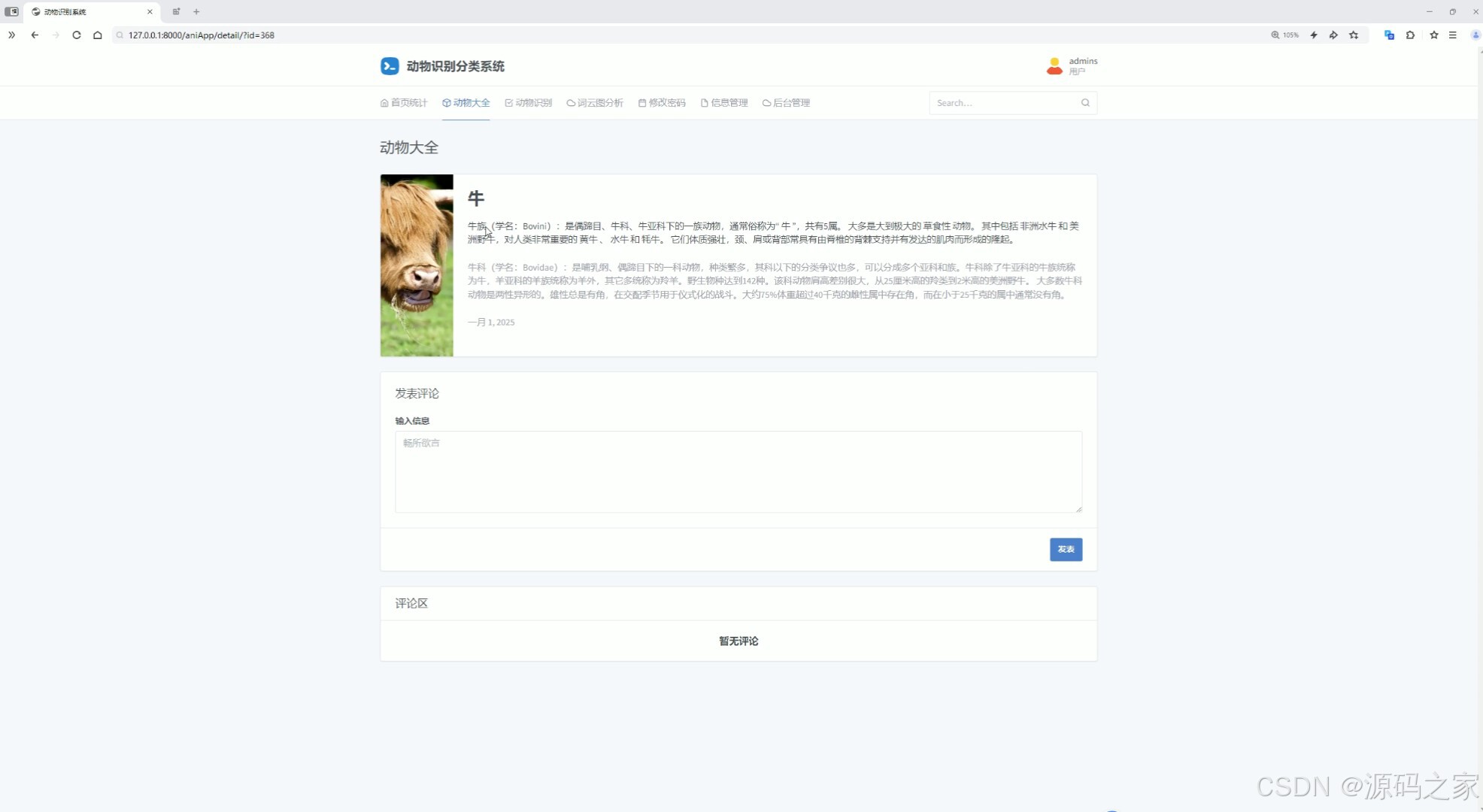
(3)识别结果
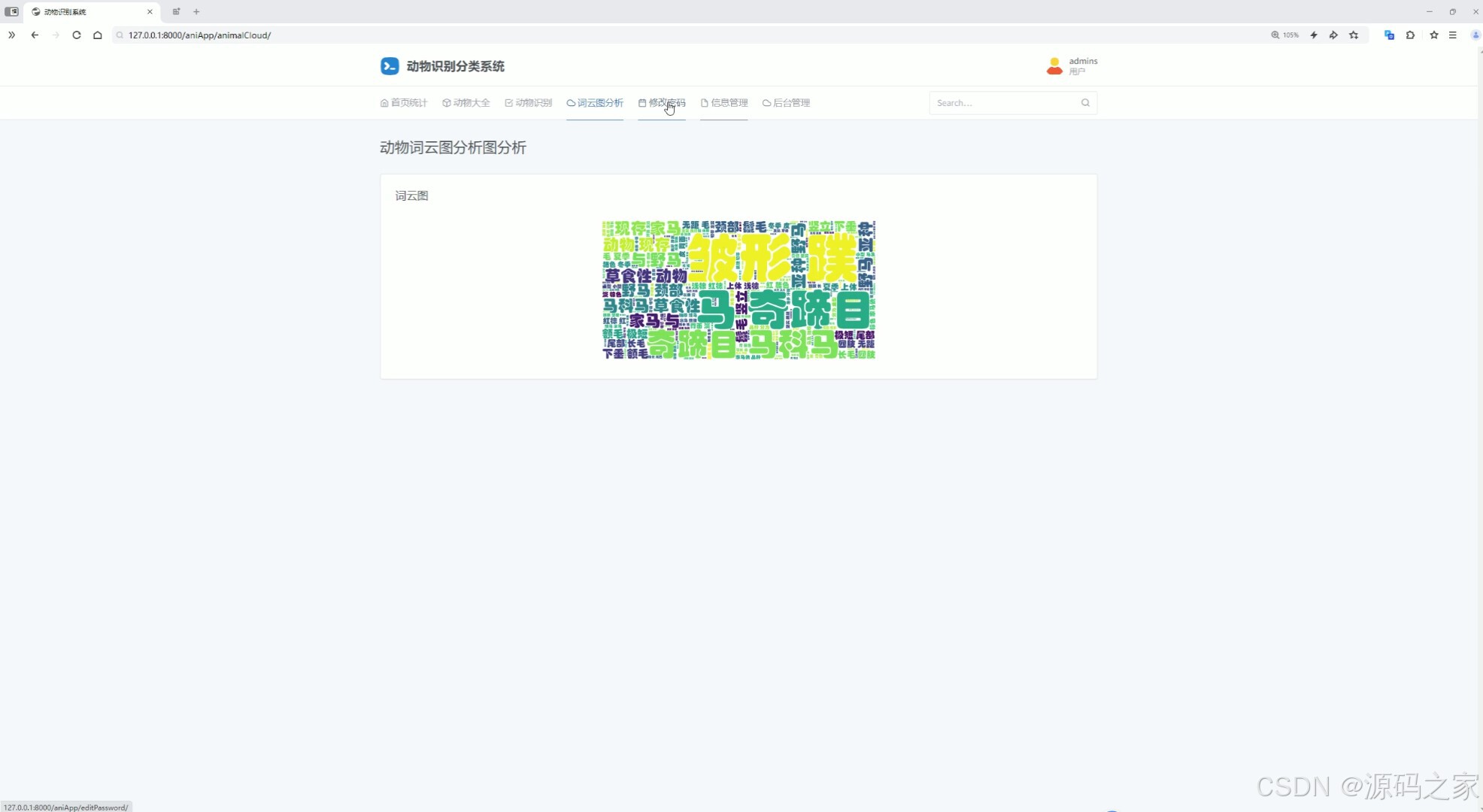
(4)词云图分析
(5)个人中心
(6)动物信息
(7)动物大全
(8)后台管理
(9)注册登录
3、项目说明
一、卷积神经网络模型
这段代码使用了 TensorFlow 和 Keras 库来构建和训练一个卷积神经网络(CNN)模型,用于图像分类任务。模型的流程如下:
-
设置 Django 环境:
代码首先设置了 Django 项目的环境变量,以便在脚本中使用 Django 的设置。
-
数据路径和参数设置:
定义了训练数据和测试数据的路径,以及批量大小(
batch_size)和训练周期(epochs)。 -
数据预处理:
使用
ImageDataGenerator类来生成图像数据的增强版本,包括缩放、旋转、平移、剪切、缩放和水平翻转。 -
加载数据集:
使用
flow_from_directory方法从指定目录加载训练集和测试集,并将图像大小调整为 224x224 像素,模式设置为分类(categorical)。 -
获取批量图像和标签:
从训练生成器和测试生成器中获取一批图像和对应的标签。
-
模型训练函数
train_model:定义了一个函数
train_model,用于构建、编译、训练和保存模型。 -
构建模型:
- 如果模型文件已经存在,则加载已存在的模型。
- 如果模型文件不存在,则创建一个新的顺序模型(
Sequential),并添加多个卷积层(Conv2D)和最大池化层(MaxPooling2D)。 - 添加一个展平层(
Flatten),将多维输入一维化。 - 添加全连接层(
Dense),其中包含一个 128 个单元的隐藏层和一个 10 个单元的输出层(因为类别数量为 10)。
-
编译模型:
使用 Adam 优化器和分类交叉熵损失函数(
categorical_crossentropy)来编译模型,并设置准确率(accuracy)作为性能指标。 -
训练模型:
使用训练生成器的数据训练模型,指定周期数和批量大小。
-
模型预测和评估:
- 使用训练好的模型对测试集进行预测。
- 计算准确率和精确率(precision),精确率使用
precision_score函数计算,这里使用了加权平均(weighted)。 - 打印出准确率和精确率。
-
保存模型:
将训练好的模型保存到指定的文件路径。
-
执行训练函数:
如果这是主程序,则调用
train_model函数开始训练模型。
总结来说,这段代码展示了使用 TensorFlow 和 Keras 构建和训练一个简单的 CNN 模型的完整流程,包括数据预处理、模型构建、编译、训练、评估和保存。
4、核心代码
python
import os
import django
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers, models
from tensorflow.keras.models import Sequential
from sklearn.metrics import precision_score
from tensorflow.keras.models import load_model
from pathlib import Path
# 设置 Django 环境
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "animalProject.settings")
django.setup()
# 数据路径
data_path = '动物十大分类/train'
test_data_path = '动物十大分类/valid'
# 参数
batch_size = 16
epochs = 10
# 数据预处理
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# 加载训练集和测试集
train_generator = train_datagen.flow_from_directory(
data_path,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
test_generator = train_datagen.flow_from_directory(
test_data_path,
target_size=(224, 224),
class_mode='categorical',
shuffle=True
)
# 获取一个批量的图像和标签
images, labels = train_generator.next()
test_images, test_labels = test_generator.next()
# 模型训练
def train_model():
# 获取当前工作目录
current_dir = os.getcwd()
# 定义模型文件的路径,保存在当前目录下
model_path = Path(current_dir) / "imgPreAnim.h5"
# 检查模型文件是否存在
if model_path.exists():
print("加载已存在的模型...")
model = load_model(model_path)
else:
print("创建新的模型...")
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 增加其他层可以按照需求解注释
# model.add(layers.Conv2D(128,(3,3),activation='relu'))
# model.add(layers.MaxPooling2D((2,2)))
# model.add(layers.Conv2D(256,(3,3),activation='relu'))
# model.add(layers.MaxPooling2D((2,2)))
# model.add(layers.Conv2D(512,(3,3),activation='relu'))
# model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
# 增加更多层也可以解注释
# model.add(layers.Dense(512,activation='relu'))
# model.add(layers.Dense(256,activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax')) # 10是类别数量
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(train_generator, epochs=epochs, batch_size=batch_size)
# 使用模型进行预测
predictions = model.predict(test_images)
correct_predictions = np.argmax(predictions, axis=1) == np.argmax(test_labels, axis=1)
accuracy = np.mean(correct_predictions)
print(f'准确率:{accuracy}')
# 计算精确率
prediction = precision_score(np.argmax(test_labels, axis=1), np.argmax(predictions, axis=1), average='weighted')
print(f'精确率:{prediction}')
# 保存模型
model.save(model_path)
if __name__ == '__main__':
train_model()
import os
from tensorflow.keras.preprocessing import image
from tensorflow import keras
import numpy as np
def predAni(img_path):
labelNames = [
'狗','羊','马','猴','牛','猪','兔','鸡','蛇','虎'
]
# 获取当前脚本所在目录路径,并拼接模型文件路径
model_path = os.path.join(os.path.dirname(__file__), 'imgPreAnim.h5')
# 加载模型
model = keras.models.load_model(model_path)
# 处理图片
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = img_array / 255 # 归一化
# 预测
predictions = model.predict(img_array)
predicted_class = np.argmax(predictions, axis=1)
print('预测结果:')
print(labelNames[predicted_class[0]])
return labelNames[predicted_class[0]]
if __name__ == '__main__':
predAni('./00000004.jpg') # 确保这个路径是正确的🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻