机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- [机器学习(Machine Learning)](#机器学习(Machine Learning))
- 构建神经网络:从基础架构到实际应用
构建神经网络:从基础架构到实际应用
一、引言
在上一篇博客中,我们初步掌握了 TensorFlow 在深度学习神经网络中的基础代码实现,对简单模型的搭建和核心概念有了基础认知。本篇将深入探索如何构建更复杂、更具实际应用价值的神经网络架构,并结合具体案例,逐步掌握其在不同场景下的实践技巧。
二、构建神经网络架构
(一)简单神经网络架构示例
我们从一个直观的案例入手,解读 "Building a neural network architecture" 图中的网络结构:
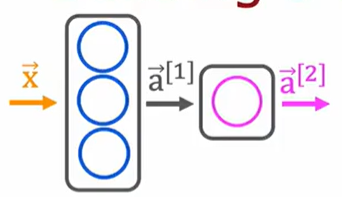
- 网络结构解析 :这是一个两层神经网络,输入层接收特征向量 x ⃗ \vec{x} x ,第一层包含 3 个神经元,采用 sigmoid 激活函数,能将线性输入转换为非线性输出;第二层仅有 1 个神经元,同样使用 sigmoid 函数,用于输出最终预测概率。使用 TensorFlow 的 Sequential 模型可轻松实现该结构:
python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(units=3, activation="sigmoid"),
Dense(units=1, activation="sigmoid")
])- 数据准备要点 :输入数据
x是形状为4 x 2的 numpy 数组,意味着包含 4 个样本,每个样本具有 2 个特征;目标数据y则是对应的标签数据,同样以 numpy 数组形式呈现。例如:
python
x = np.array([[200.0, 17.0],
[120.0, 5.0],
[425.0, 20.0],
[212.0, 18.0]])
y = np.array([1, 0, 0, 1])- 模型训练与预测流程 :尽管图中
model.compile(...)部分未详细展开,但我们知道这一步至关重要,需配置优化器、损失函数等关键参数。通过model.fit(x, y)进行模型训练,使其学习输入特征与目标标签的映射关系。训练完成后,使用model.predict(x_new)即可对新数据进行预测。
(二)数字分类模型架构
接下来分析 "Digit classification model" 图中的复杂神经网络架构:
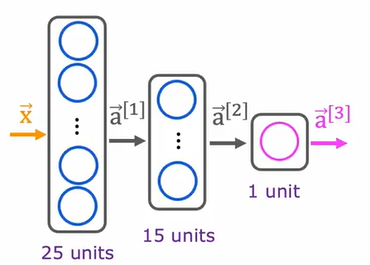
- 网络深度与设计:该网络包含三层,第一层 25 个神经元用于初步特征提取,第二层 15 个神经元进一步提炼特征,第三层单神经元输出最终预测结果,每层均采用 sigmoid 激活函数。我们可以分步定义各层,再组合成 Sequential 模型:
python
layer_1 = Dense(units=25, activation="sigmoid")
layer_2 = Dense(units=15, activation="sigmoid")
layer_3 = Dense(units=1, activation="sigmoid")
model = Sequential([layer_1, layer_2, layer_3])- 数据特征与标签 :输入数据
x是代表数字图像特征的 numpy 数组(如像素值等),由于图像数据维度较高,这里仅展示部分数据结构;目标数据y则是对应数字标签,例如:
python
x = np.array([[0..., 245,..., 17],
[0..., 200,..., 184]])
y = np.array([1, 0])- 完整训练预测链路 :与简单模型类似,先通过
model.compile(...)配置训练参数,再使用model.fit(x, y)完成训练,最终利用训练好的模型对新图像数据进行预测。
三、构建神经网络的关键要点
(一)层的选择与设计策略
在神经网络构建中,层的选择直接决定模型性能:
-
全连接层(Dense):适用于多种数据类型,其神经元全连接特性使其能捕捉全局特征关系,但计算复杂度较高。
-
卷积层(Conv):专为图像数据设计,通过卷积核自动提取局部特征,大幅减少参数数量,有效避免过拟合,是计算机视觉领域的核心层。
-
循环层(RNN 及变体 LSTM、GRU):擅长处理序列数据,如时间序列、文本等,能记忆历史信息,捕捉长距离依赖关系。
(二)激活函数的应用场景
激活函数是赋予神经网络非线性能力的关键:
-
sigmoid 函数:将输出压缩至 (0, 1) 区间,常用于二分类问题的输出层,但存在梯度消失问题,不适用于深层网络。
-
ReLU 函数 :以 f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x) 为核心逻辑,有效缓解梯度消失,加速训练,是隐藏层的常用选择。
-
tanh 函数:输出值域为 (-1, 1),相比 sigmoid 有更好的中心化效果,在某些特定场景表现优异。
(三)数据预处理的核心操作
高质量的数据是模型训练的基础:
-
归一化处理:将图像像素值从 0, 255 归一化到 0, 1,或使用标准化方法将数据转换为均值为 0、方差为 1 的分布,可提升模型稳定性与收敛速度。
-
维度校验:确保输入数据维度与模型要求一致,如图像数据需注意通道数、尺寸等维度信息,避免因维度错误导致训练失败。
continue...