1. 维度灾难
当我们谈论机器学习模型在处理数据时遇到的困难,一个常常被提及的词便是"维度灾难 "(Curse of Dimensionality)。这不是科幻小说里的情节,而是数学和计算世界里真实存在的困境。它指的正是:当数据集的特征数量(即维度)增加时,分析、组织和处理数据会变得异常困难,甚至在某些情况下,根本不可能。
1.1. 灾难一:数据稀疏性
想象一下。你在一根一米长的绳子上,每10厘米放一颗珠子,一共需要 10 颗。如果将这颗珠子放在一个一平米的正方形里,每边都保持10厘米的间隔,那你就需要 10 × 10 = 100 10 \times 10 = 100 10×10=100 颗珠子。进一步,在一个一立方米的房间里,同样间隔就需要 10 × 10 × 10 = 1000 10 \times 10 \times 10 = 1000 10×10×10=1000 颗。

现在,把这个概念推广到 D D D 维空间。在一个边长为1的 D D D 维超立方体中,若我们希望每个维度上都能被划分成10个区间,那么总共需要 10 D 10^D 10D 个单元格来覆盖整个空间。
- 当 D = 10 D=10 D=10 时,就是 10 10 10^{10} 1010 个单元格。
- 当 D = 100 D=100 D=100 时,便是 10 100 10^{100} 10100 个单元格。
这个数字是天文量级的。这意味着,即使我们拥有再多的训练样本,在高维空间中,它们也仅仅是散落在浩瀚宇宙中的几粒尘埃,数据会变得极其稀疏。
1.2. 灾难二:距离度量失效
这种极端稀疏性,带来了一个反直觉的现象:在高维空间里,任意两个随机数据点之间的距离,其差异会变得非常小,几乎所有点之间的距离都会趋于相等。这并不是说所有点都"挨得很近",恰恰相反,它们都很"远",但它们"远"的程度却彼此非常接近。
举个不那么严谨的例子, 假设我们在1000维空间里有两个点 A A A 和 B B B。它们的欧氏距离是它们在1000个维度上的坐标差的平方和的平方根:
D i s t a n c e ( A , B ) = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + . . . + ( a 1000 − b 1000 ) 2 Distance(A, B) = \sqrt{(a_1-b_1)^2 + (a_2-b_2)^2 + ... + (a_{1000}-b_{1000})^2} Distance(A,B)=(a1−b1)2+(a2−b2)2+...+(a1000−b1000)2
如果我们在低维空间里,某几个维度上的差异很大,就能显著影响总距离。但在高维空间里,即使在某个维度上的差异很大,这个差异的平方只占总的1000项中的一项。总的距离更多地取决于在大多数维度上微小的差异累积起来。
这种累积效应导致的结果是:
- 即使两个点在某个或几个维度上看起来很不同,但在其他绝大多数维度上它们的差异可能很随机,总的距离也就趋于一个平均值。
- 任意两个随机点,它们在大部分维度上的差异累积起来,最终得到的总距离往往差异不大。
因此,这种在多维度上差异的随机累积,使得任意两个数据点之间的总距离趋于一个平均值,距离的最小值和最大值之间的差距在高维下变得微乎其微。用数学语言说,最小距离与最大距离的比率会趋近于1。
这意味着,原本在低维空间中能够清晰区分的"近"和"远"的概念,在高维下变得模糊不清,所有点从距离上看都变得"差不多远"。这种由高维稀疏性导致的"距离相似"现象,严重削弱了许多依赖于判断数据点之间邻近关系的算法性能,例如K近邻和聚类等。
1.3. 灾难三:复杂的模型
当我们尝试用模型拟合这些高维数据时,会让模型设计变得困难。
- 参数爆炸: 很多机器学习模型,其参数数量与特征维度密切相关。例如,一个简单的线性模型,其参数数量与维度呈线性关系。但一旦我们转向非线性模型,如多项式回归,参数数量可能呈指数级增长。
- 泛化能力下降: 在高维空间中,由于数据样本的稀疏性,模型很容易"记住"训练数据中的每一个细节,包括那些无关紧要的噪声和偶然模式,而非数据的真实规律。这导致模型在训练集上表现完美,但在面对未见过的新数据时,性能却一落千丈,这就是过拟合。一个高维模型,就像一个记性太好的学生,把教科书上的错别字也当成了知识点。
1.4. 灾难四:计算成本飙升
最后,维度灾难也直接转化为实际的计算负担。
-
存储: 高维数据需要巨大的存储空间。
-
计算: 许多机器学习算法的计算复杂度随维度呈指数级增长。例如,矩阵运算、特征选择等都变得异常耗时。在处理海量高维数据时,计算资源往往成为瓶颈。
2. 维度失衡的表象
在机器学习中,我们常常用偏差(Bias) 和方差(Variance) 来诊断模型的问题。它们是理解模型性能的两把尺子,其实它们也反映了维度处理上的失衡。
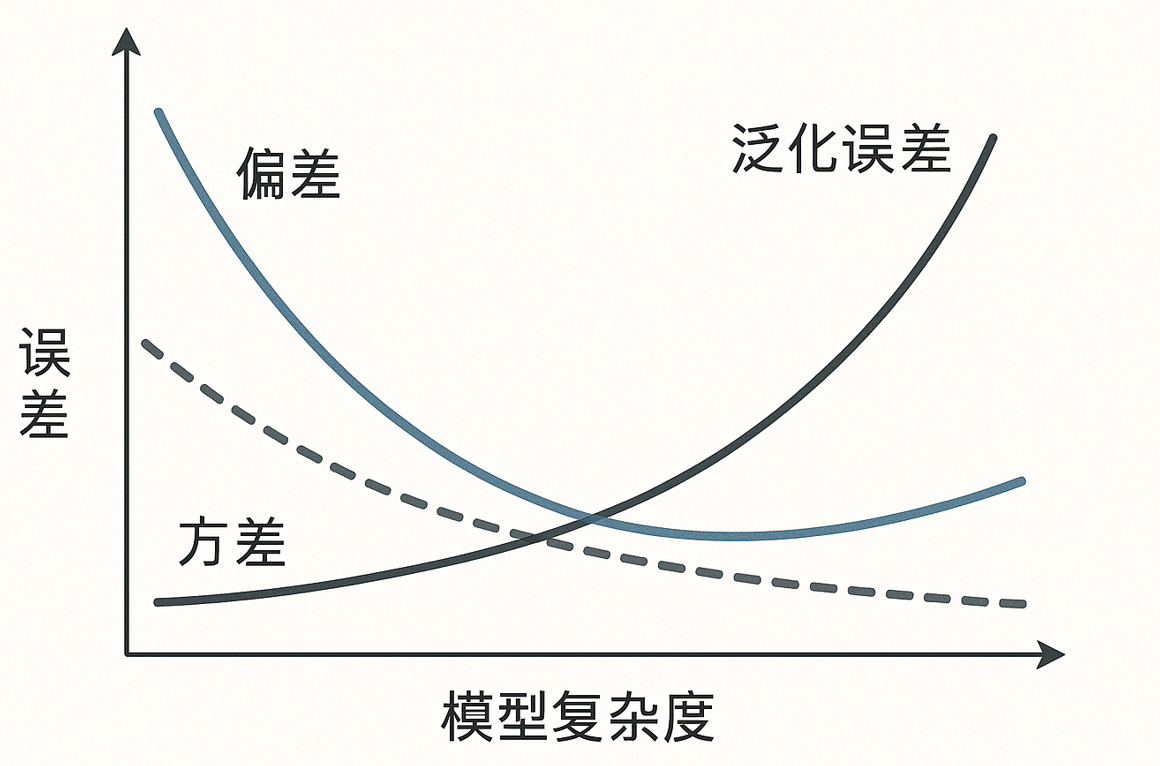
2.1. 欠拟合:高偏差 (Bias)
想象你试图用一条直线去拟合一个明显是弯曲的数据点集合,比如一个抛物线。无论你如何调整直线的斜率和截距,它都无法完美贴合那些弯曲的点。这就是欠拟合,模型连训练数据都无法学好。
- 模型过于简单: 欠拟合的本质是模型过于简单,其学习能力(或称模型容量)不足以捕捉数据中真实存在的复杂模式。
- 维度过少: 当我们提供的特征维度过少 时,模型可能根本没有足够的信息来识别数据中的真实关系。在一个低维空间中,复杂、非线性的模式可能被"压缩"得无法被简单模型所理解。这表现为高偏差:模型在训练数据上就存在较大误差,因为它从一开始就没能"看懂"数据的真实结构。
2.2. 过拟合:高方差 (Var)
与欠拟合相反,过拟合是模型学得"太好"了,好到它把训练数据里的噪声和偶然的波动也当成了规律。
- 模型过于复杂: 过拟合的根源是模型学习能力过强,其自由度远超数据本身的内在复杂度。它像一个模仿能力超群的演员,不仅模仿了角色的一举一动,连口音、习惯动作里偶然的颤抖都学得惟妙惟肖。
- 维度过多与过拟合:
- 高维空间中的稀疏性: 回顾第一节的"维度灾难"。在高维空间中,数据本身就极其稀疏。这意味着模型看到的每个训练样本都是茫茫宇宙中的一个孤立点。即使模型的参数数量看起来"不多",但相对于这些稀疏的样本而言,模型仍然拥有过多的"自由度"去精确地拟合每一个点,包括其中的噪声。它会试图在这些孤立点之间画出扭曲的、毫无意义的线条,从而导致高方差:模型对训练数据的微小变化极其敏感,泛化到新数据时,性能会大幅波动。
- 参数量与信息量不匹配: 在低维空间中,如果模型参数量(模型复杂度)依然非常大,远超数据所能提供的有效信息,同样会导致过拟合。这相当于给一个简单的任务配置了一个过于强大的工具,它在完成任务的同时,也把周边无关紧要的东西都处理了一遍。
2.3. 误差:维度失衡的表象
我们可以将误差 (MSE) 分解为 :
E r r o r = B i a s 2 + V a r 2 + σ 2 \mathrm{Error=Bias^2+Var^2+\sigma^2} Error=Bias2+Var2+σ2
其中 σ 2 \sigma^2 σ2 是噪声的方差, 可以看作是常数。
所以,无论是欠拟合还是过拟合,其根本都指向一个问题:模型复杂度 与训练数据中包含的有效信息量之间的不匹配。(在充足训练的情况下)
-
模型过于简单(低复杂度) ,无法捕捉数据中复杂的模式,导致欠拟合(高偏差)。这可能源于特征维度不足,或模型本身表达能力有限。
-
模型过于复杂(高复杂度) ,过度学习噪声,导致过拟合(高方差)。这在高维数据稀疏的环境中尤为突出,因为即使参数量看起来适中,在高维的空旷下,模型依然显得过于强大。
3. 妙用数据维度
3.1. 降维
既然维度太高不行,在不人为操作的情况,能否让算法自行减少特征维度呢?
当然可以,这就是降维技术。它通常是应对维度灾难最直观的策略。
降维 技术可以削减特征数量,在尽可能保留数据核心信息的前提下,将高维数据映射到低维空间。降维的核心思想就像从一堆行李中,直接挑出最有价值的几件 (也可以是特征的组合, 比如PCA降维)。我们从原始特征集中筛选出与目标最相关、最具区分度的子集,直接剔除不必要或带噪声的维度。
我们可以将特征维度 类比为方程的变量数量 ,而训练样本数量 类比为方程的数量 。当特征维度过高(变量多)而训练样本不足(方程少)时,模型难以找到一个稳定的解,很容易"过度拟合"训练数据中的噪声。降维的作用,就是减少这些"变量数量"。方程越少,意味着我们给模型的先验假设越多,这引导模型在简化的维度空间中,更容易发现数据固有的更普遍的规律,进而显著提升其泛化能力。
3.2. 随机投影
在降维技术中,有一种优雅巧妙又有点反直觉的方法: 随机投影 ,它的有效性巧妙利用了高维空间的一个奇特特性:高维空间中,随机选择的两个向量大概率是正交的。
这听起来很玄乎。在二维平面上,两条随机线正交的概率微乎其微。但在 D D D 维空间中,当 D D D 足够大时,情况截然不同。你可以想象,在极端广阔的空间中,两个随机选择的方向彼此"正对着"或"平行"的概率几乎为零,它们有无数种方式可以彼此垂直。
正是利用了这一点,随机投影通过一个随机生成的矩阵,将高维数据投影到低维空间。由于随机投影方向的这种近似正交性,它能够以高概率近似地保留原始数据点之间的相对距离和结构(这被称为 Johnson-Lindenstrauss 引理)。这意味着,我们无需付出高昂的计算代价去寻找"最佳"投影(如PCA),只需随机一投,就能达到不错的效果。
这种随机正交的特性,恰恰是维度灾难的推论。正是因为高维空间如此"空旷"和"广阔",以至于随机生成的向量能够彼此"不重叠",从而倾向于正交。随机投影正是巧妙地利用了维度灾难所揭示的高维空间特性,提供了一种高效、简便的降维手段。
3.3. 升维
还可以有更令人惊奇的升维 操作。既然维度灾难如此可怕,我们为何还要"增加"维度?这里的升维并非简单地增加特征,而是一种策略性的非线性映射 ,其核心目的在于:将低维空间中非线性可分的数据,通过某种非线性变换,映射到更高维空间,使其在高维空间中变得线性可分。
-
核函数: 在支持向量机(SVM)中,核函数(如高斯核、多项式核)则更巧妙地实现了升维。它无需显式地将数据点映射到那个可能极其高维的特征空间,而是通过计算在那个高维空间中的点积。这意味着我们可以在原始低维空间中进行计算,却能享受到高维空间中线性可分所带来的分类优势。这种核技巧,它避开了显式升维带来的计算和存储难题,从而化解了部分维度灾难的冲击。
-
非线性函数升维: 最简单的例子便是多项式特征 。如果我们有 x 1 , x 2 x_1, x_2 x1,x2 两个特征,我们可以通过添加 x 1 2 , x 2 2 , x 1 x 2 x_1^2, x_2^2, x_1x_2 x12,x22,x1x2 等项,将其升维到更高维空间。原来在二维平面上需要曲线才能分开的数据,在新的高维空间中,可能只需一个平面即可完成分离。
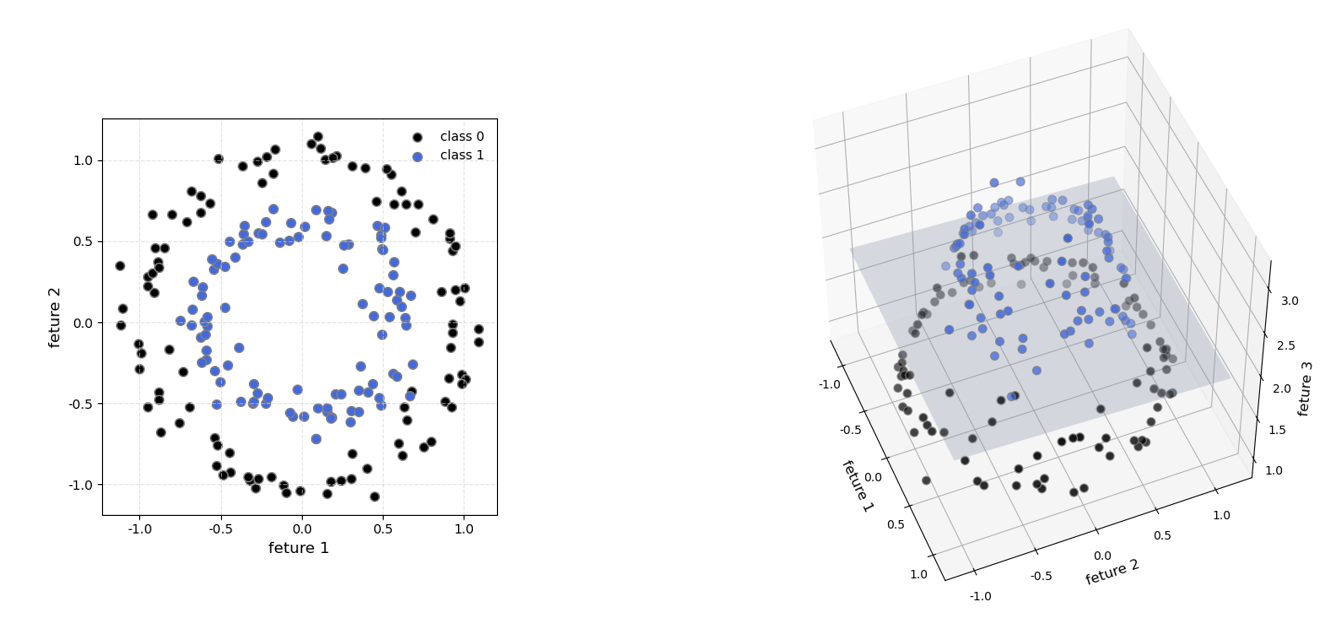
深度学习中的神经网络 正是如此。每一层的隐藏神经元,都通过非线性激活函数 (类似于核函数)对前一层特征进行非线性变换 ,将数据从一个特征空间映射到另一个更高维(或至少是不同维度)的"隐式特征空间" 。同时,增加隐藏层的维度则相当于有意地增加这个"隐式特征空间"的维度(类似于非线性函数升维),旨在让模型能够学习到原始特征之间更抽象、更复杂的非线性关系和组合。
这种"升维"本质上是为了增加数据的"表现力"。它让数据具备了在更高层次上被线性模型理解的能力,从而能够捕捉到低维中隐藏的复杂非线性模式。
4. 平衡的艺术
我们已经遍历了维度的凶险与神奇。从"维度灾难"带来的数据稀疏和计算困境,到"偏差与方差"所揭示的模型失衡,再到"降维"的精准提炼和"升维"的巧妙拓展。至此,一个清晰的结论浮出水面:维度管理的核心,是一门寻求平衡的艺术。
4.1. 升维与降维的平衡
你可以把模型看作一个信息处理的通道。如果这个通道的"瓶颈"太宽,信息自由流淌,连噪声都一并灌入,那就会导致过拟合 。反之,如果瓶颈太窄,关键信息都堵在外面,无法进入,那就会导致欠拟合 。这里的"瓶颈"既可以理解为模型的参数量 ,也可以理解为数据经过处理后的有效信息维度。
- 升维与信息"扩容": 我们通过非线性升维,就像是为这个信息通道 "扩容" ,增加了更多的管道和弯道,让原本纠缠不清的数据在高维空间中得以"舒展",从而能学习到更深层次、更抽象的特征表示。这为模型提供了强大的 "表现力" ,让它能理解更复杂的模式。
- 降维与信息"精炼": 而降维,则是在这种扩容之后,对信息进行 "精炼"和"压缩" 。它剔除冗余和噪声,将最有价值的、最本质的信息汇聚到更少的维度中。这提升了数据的 "精准表达" ,让模型在更高效、更稳定的环境中进行学习,从而避免过拟合,并提高泛化能力。
所以,我们并非一味地增大参数量或信息维度,也不是盲目地进行信息压缩。真正的智慧在于:先通过策略性的升维,赋予模型足够的"感知"复杂模式的能力;再通过智慧的降维,将这些复杂模式提炼为简洁、鲁棒的"表达"。
4.2. 结语
维度,既是机器学习的挑战,亦是它的机遇。理解并娴熟运用"升维"与"降维"的艺术,是我们驾驭数据复杂性、构建强大泛化模型的核心所在。它要求我们不仅能看到数据的表象,更能洞察其内在的结构与信息流转。
你的模型,是否也正面临着维度的挑战?或许,是时候重新审视你与维度之间的关系了。