图机器学习(8)------经典监督图嵌入算法
-
- [0. 前言](#0. 前言)
- [1. 监督图嵌入分类](#1. 监督图嵌入分类)
- [2. 基于特征的方法](#2. 基于特征的方法)
- [3. 浅层嵌入方法](#3. 浅层嵌入方法)
-
- [3.1 标签传播算法](#3.1 标签传播算法)
- [3.2 标签扩散算法](#3.2 标签扩散算法)
0. 前言
监督学习 (Supervised Learning, SL) 代表了大多数实际机器学习 (Machine Learning, ML) 任务的应用场景。得益于日益高效的数据采集,带标签数据集已经非常普遍。对于图数据同样如此,在图数据中,标签可以分配给节点、社群,甚至整个图结构。此时的任务就是学习输入数据与标签(也称为目标或标注)之间的映射函数。
例如,给定一个表示社交网络的图,我们可能需要预测哪些用户(节点)将会注销账户。通过基于历史数据训练图机器学习模型,根据用户数月后是否注销账户,将其标记为"忠实用户"或"流失用户"。本节将探讨监督学习的概念及其在图数据上的应用,我们还将系统介绍主要的监督式图嵌入方法。
1. 监督图嵌入分类
在监督学习 (Supervised Learning, SL) 中,训练集由一系列有序对 (x, y) 组成,其中 x 是输入特征集合(通常是定义在图上的信号),y 是对应的输出标签。机器学习模型的目标是学习一个函数,将每个 x 值映射到 y 值。常见的监督任务包括预测大型社交网络中用户属性,或预测分子特性(每个分子都可表示为图结构)。
然而有时并非所有样本都能获得标签。这种情况下,数据集通常由少量带标签样本和大量无标签样本组成。针对这种场景提出的半监督学习 (semi- SL, SSL) 算法,旨在利用已有标签信息所反映的标签依赖关系,从而学习无标签样本的预测函数。
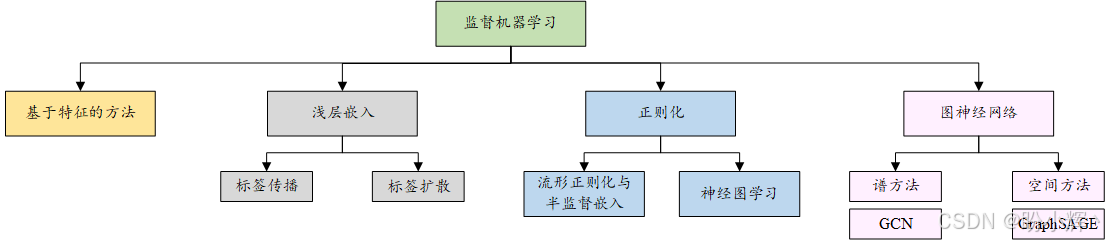
关于监督图机器学习技术可以归纳为四大类,包括基于特征的方法、浅层嵌入方法、正则化方法和图神经网络 (Graph Neural Network, GNN),如以下图所示:
2. 基于特征的方法
在图数据上应用机器学习有一种简单而有效的方法------将编码函数视为简单的嵌入查找。处理监督任务时,利用图属性是最直接的方式之一。我们已经学习过如何通过结构属性来描述图(或图中的节点),这些属性本质上都是图本身重要信息的"编码"。
在传统监督学习中,任务是找到将实例的描述性特征映射到特定输出的函数。这些特征需要精心设计,确保其具有足够的代表性来学习目标概念。就像花瓣数量和萼片长度可以很好地描述花朵,描述图结构时我们可以依赖平均度数、全局效率和特征路径长度等指标。这种方法分为两步:
- 选择一组具有描述性的优质图属性
- 将这些属性作为传统机器学习算法的输入
但"优质描述属性"并无统一定义,其选择完全取决于待解决的具体问题。我们可以通过计算多种图属性,然后利用特征选择筛选信息量最大的特征。
为了了解如何应用这种基本方法,我们使用 PROTEINS 数据集进行监督图分类任务。PROTEINS 数据集包含多个表示蛋白质结构的图,每个图都有标签指示该蛋白质是否为酶。
(1) 首先,加载数据集:
python
import torch
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
from IPython.display import display, HTML
# 加载 PROTEINS 数据集
dataset = TUDataset(root='data/PROTEINS', name='PROTEINS')(2) 使用 networkx 计算图属性,为此首先需要将图转换为 networkx 格式,然后为每个图计算全局度量指标进行描述。本节中,选择了边数量、平均聚类系数和全局效率这三个指标,但我们也可以尝试计算其他图属性指标:
python
from torch_geometric.utils import to_networkx
# 转换为 NetworkX 图并计算指标
metrics = []
for data in dataset:
# 转换为 NetworkX 图
G = to_networkx(data, to_undirected=True) # PROTEINS 是无向图
# 计算指标
num_edges = G.number_of_edges()
cc = nx.average_clustering(G)
eff = nx.global_efficiency(G)
metrics.append([num_edges, cc, eff])
# 转换为 numpy 数组
metrics = np.array(metrics)
labels = np.array([data.y.item() for data in dataset], dtype=int)(3) 利用 scikit-learn 创建训练集和测试集。在本节中,使用 70% 的数据集作为训练集,其余的作为测试集:
python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(metrics, labels, test_size=0.3)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)(4) 训练机器学习算法。本节选择支持向量机 (support vector machine, SVM),更精确地说,具体而言,该 SVM 经过训练可最小化预测标签与实际标签(真实值)之间的差异:
python
from sklearn import svm
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
clf = svm.SVC()
clf.fit(X_train_scaled, y_train)
y_pred = clf.predict(X_test_scaled)
print('Accuracy', accuracy_score(y_test,y_pred))
print('Precision', precision_score(y_test,y_pred))
print('Recall', recall_score(y_test,y_pred))
print('F1-score', f1_score(y_test,y_pred))输出结果如下所示:
shell
Accuracy 0.7544910179640718
Precision 0.8433734939759037
Recall 0.5035971223021583
F1-score 0.6306306306306306我们采用准确率 (Accuracy)、精确率 (Precision)、召回率 (Recall) 和 F1 分数 (F1-score) 来评估算法在测试集上的表现。最终获得了约 85% 的精确率,对于这种基础任务而言已属不错的结果。
3. 浅层嵌入方法
浅层嵌入方法属于图嵌入技术的子集,其特点是为有限的输入数据学习节点、边或图的表征,这类方法无法泛化到训练集之外的实例。在开始讨论之前,明确监督和无监督浅嵌入算法的区别非常重要。
无监督和监督嵌入方法之间的主要区别本质上在于其解决的任务目标:无监督浅层嵌入算法旨在学习图结构、节点或边表征以构建清晰的聚类,而监督式算法则致力于优化预测任务(如节点分类、标签预测或图分类)的解决方案。
本节将详细解析几种典型的监督式浅层嵌入算法,并通过 Python 演示其应用。
3.1 标签传播算法
标签传播算法 (label propagation algorithm) 是一种广泛应用于数据科学中的半监督算法,通常用于解决节点分类任务。更具体地说,其核心机制是将已知节点的标签传播至其相邻节点,或传播至从该节点出发高概率可达的节点。
该算法的基本原理非常直观:给定包含已标注和未标注节点的图结构,已标注节点将其标签传播到最有可能被访问的节点。下图展示了一个包含标注与未标注节点的图示例:
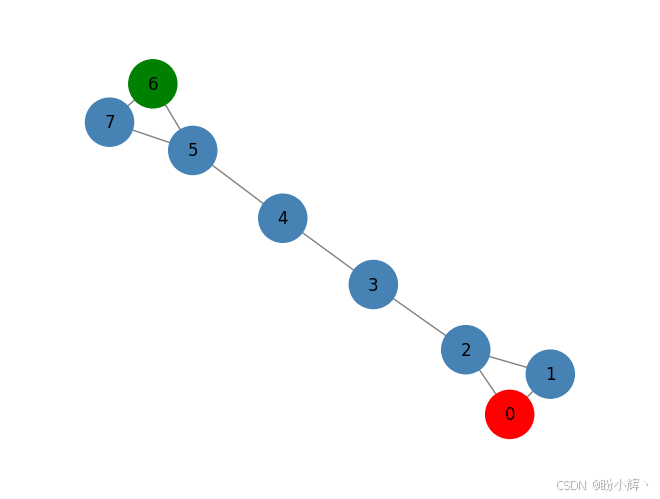
如上图所示,该算法将利用已标注节点(节点 0 和节点 6 )的信息,计算转移到其他未标注节点的概率。与已标注节点之间转移概率最高的未标注节点将继承该节点的标签。
设有图 G = ( V , E ) G=(V,E) G=(V,E),标签集为 Y = { y 1 , . . . , y p } Y=\{y_1,...,y_p\} Y={y1,...,yp}。由于算法采用半监督学习机制,仅有部分节点会被预先标注。定义 A ∈ R ∣ V ∣ × ∣ V ∣ A ∈ \mathbb R^{|V|×|V|} A∈R∣V∣×∣V∣ 表示输入图 G G G 的邻接矩阵, D ∈ R ∣ V ∣ × ∣ V ∣ D ∈ \mathbb R^{|V|×|V|} D∈R∣V∣×∣V∣为对角度矩阵,其元素 d i j ∈ D d_{ij}\in D dij∈D 满足::
d i j = { 0 i ≠ j d e g ( v i ) i = j d_{ij}=\left\{ \begin{aligned} &0 & \quad i\neq j\\ °(v_i) & \quad i=j \end{aligned} \right . dij={0deg(vi)i=ji=j
换句话说,度矩阵中唯一非零的元素是对角线元素,其值为节点度数值。上图的对角度矩阵如下所示:
D = 2 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 2 D=\begin{bmatrix} 2&0&0&0&0&0&0&0\\ 0& 2& 0& 0& 0& 0& 0& 0\\ 0& 0& 3& 0& 0& 0& 0& 0\\ 0& 0& 0& 2& 0& 0& 0& 0\\ 0& 0& 0& 0& 2& 0& 0& 0\\ 0& 0& 0& 0& 0& 3& 0& 0\\ 0& 0& 0& 0& 0& 0& 2& 0\\ 0& 0& 0& 0& 0& 0& 0& 2 \end{bmatrix} D= 2000000002000000003000000002000000002000000003000000002000000002
以上矩阵展示了给定起始节点时到达终止节点的概率,该矩阵中仅对角线元素包含非零值,这些值表示对应节点的度数。我们还需要引入转移矩阵 L = D − 1 A L = D^{-1}A L=D−1A,该矩阵定义了节点间的转移概率------具体而言,矩阵元素 l i j ∈ L l_{ij}\in L lij∈L 表示从节点 v i v_i vi 转移到节点 v j v_j vj 的概率。上图中对应结构的转移矩阵 L L L 如下:
L = 0. 0.5 0.5 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0.33 0.33 0. 0.33 0. 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0. 0.33 0. 0.33 0.33 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0.5 0.5 0. L=\begin{bmatrix} 0.& 0.5& 0.5 & 0. & 0. &0. & 0. & 0.\\ 0.5& 0.& 0.5 & 0. & 0. &0. & 0. & 0.\\ 0.33& 0.33& 0.& 0.33& 0.&0.& 0.& 0. \\ 0. & 0. & 0.5 & 0. & 0.5 &0. & 0. & 0. \\ 0. & 0. & 0. & 0.5 & 0. &0.5 & 0. & 0. \\ 0. & 0.& 0.& 0.& 0.33&0.& 0.33&0.33\\ 0. & 0. & 0. & 0. & 0. &0.5 & 0. & 0.5 \\ 0. & 0. & 0. & 0. & 0. &0.5 & 0.5 & 0. \end{bmatrix} L= 0.0.50.330.0.0.0.0.0.50.0.330.0.0.0.0.0.50.50.0.50.0.0.0.0.0.0.330.0.50.0.0.0.0.0.0.50.0.330.0.0.0.0.0.0.50.0.50.50.0.0.0.0.0.330.0.50.0.0.0.0.0.330.50.
以上矩阵显示了从起始节点到达终止节点的概率。例如矩阵第一行显示:从节点 0 出发,仅有 50% 的概率到达节点 1 和节点 2。若定义 Y 0 Y^0 Y0 为初始标签分配矩阵,则通过转移矩阵 L L L 计算的标签分配概率可表示为 Y 1 = L Y 0 Y^1=LY^0 Y1=LY0。上图对应结构的 Y 1 Y^1 Y1 矩阵计算结果如下所示:
Y 1 = 0. 0.5 0.5 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0.33 0.33 0. 0.33 0. 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0. 0.33 0. 0.33 0.33 0. 0. 0. 0. 0. 0.5 0. 0.5 0. 0. 0. 0. 0. 0.5 0.5 0. ∗ 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 = 0 0 0.5 0 0.33 0 0 0 0 0 0 0.33 0 0 0 0.5 Y^1=\begin{bmatrix} 0.& 0.5& 0.5 & 0. & 0. &0. & 0. & 0.\\ 0.5& 0.& 0.5 & 0. & 0. &0. & 0. & 0.\\ 0.33& 0.33& 0.& 0.33& 0.&0.& 0.& 0. \\ 0. & 0. & 0.5 & 0. & 0.5 &0. & 0. & 0. \\ 0. & 0. & 0. & 0.5 & 0. &0.5 & 0. & 0. \\ 0. & 0.& 0.& 0.& 0.33&0.& 0.33&0.33\\ 0. & 0. & 0. & 0. & 0. &0.5 & 0. & 0.5 \\ 0. & 0. & 0. & 0. & 0. &0.5 & 0.5 & 0. \end{bmatrix}*\begin{bmatrix} 1&0\\ 0&0\\ 0&0\\ 0&0\\ 0&0\\ 0&0\\ 0&1\\ 0&0\\ \end{bmatrix}= \begin{bmatrix} 0&0\\ 0.5&0\\ 0.33&0\\ 0&0\\ 0&0\\ 0&0.33\\ 0&0\\ 0&0.5\\ \end{bmatrix} Y1= 0.0.50.330.0.0.0.0.0.50.0.330.0.0.0.0.0.50.50.0.50.0.0.0.0.0.0.330.0.50.0.0.0.0.0.0.50.0.330.0.0.0.0.0.0.50.0.50.50.0.0.0.0.0.330.0.50.0.0.0.0.0.330.50. ∗ 1000000000000010 = 00.50.3300000000000.3300.5
从矩阵中可以看到,使用转移矩阵后,节点 1 和节点 2 被分配标签 [1 0] 的概率分别为 0.5 和 0.33,节点 5 和节点 6 被分配标签 [0 1] 的概率分别为 0.33 和 0.5。
此外,如果我们进一步分析以上矩阵,可以发现两个关键问题:
- 当前方案仅能对节点
[1 2]和[5 7]进行标签概率分配 - 节点
0和6的初始标签与 Y 0 Y^0 Y0 定义不一致
为了解决第一个问题,算法采用迭代计算策略:在每次迭代 t t t 中,通过转移矩阵 L L L 更新标签分布:
Y t = L Y t − 1 Y^t = LY^{t-1} Yt=LYt−1
当满足某个条件时,算法停止迭代。第二个问题通过标签传播算法解决,在每次迭代结果中强制保持已标注节点的初始值,例如将结果矩阵的第一行锁定为 [1 0],第七行锁定为 [0 1]。
在本节,我们对 scikit-learn 库中 LabelPropagation 类进行改进。这一改进主要基于以下考量:原 LabelPropagation 类要求输入数据必须为特征矩阵格式(矩阵的行代表样本,列代表特征),这与图数据的原生结构存在本质差异。
在模型拟合 (fit) 操作执行前,原 LabelPropagation 类会通过 _build_graph 函数内部构建图结构。该函数采用参数化核方法(可选 k 近邻算法 kNN 或径向基函数,通过 _get_kernel 函数实现),将输入数据集转换为图表示形式。这种转换使得原始数据被重构为邻接矩阵表达的图结构,其中,每个节点是一个样本(输入矩阵的行),每条边代表样本间的关联关系。
在本节中,由于输入数据本身即为图结构,我们特别设计了可直接处理 networkx 图对象的 GraphLabelPropagation 类。创建一个名为 GraphLabelPropagation 的新类来实现,它扩展了 ClassifierMixin、BaseEstimator 和 ABCMeta 基类:
python
class GraphLabelPropagation(ClassifierMixin, BaseEstimator, metaclass=ABCMeta):
@_deprecate_positional_args
def __init__(self, max_iter=30, tol=1e-3):
self.max_iter = max_iter
self.tol = tol
def predict(self, X):
probas = self.predict_proba(X)
return self.classes_[np.argmax(probas, axis=1)].ravel()
def predict_proba(self, X):
check_is_fitted(self)
return self.label_distributions_
def _validate_data(self, X, y):
if not isinstance(X, nx.Graph):
raise ValueError("Input should be a networkX graph")
if not len(y) == len(X.nodes()):
raise ValueError("Label data input shape should be equal to the number of nodes in the graph")
return X, y
@staticmethod
def build_label(x,classes):
tmp = np.zeros((classes))
tmp[x] = 1
return tmp
def fit(self, X, y):
X, y = self._validate_data(X, y)
self.X_ = X
check_classification_targets(y)
D = [X.degree(n) for n in X.nodes()]
D = np.diag(D)
# label construction
# construct a categorical distribution for classification only
unlabeled_index = np.where(y==-1)[0]
labeled_index = np.where(y!=-1)[0]
unique_classes = np.unique(y[labeled_index])
self.classes_ = unique_classes
Y0 = np.array([self.build_label(y[x], len(unique_classes))
if x in labeled_index else np.zeros(len(unique_classes)) for x in range(len(y))])
A = inv(D)*np.asmatrix(nx.to_numpy_array(G))
Y_prev = Y0
it = 0
c_tool = 10
while it < self.max_iter & c_tool > self.tol:
Y = A*Y_prev
#force labeled nodes
Y[labeled_index] = Y0[labeled_index]
it +=1
c_tol = np.sum(np.abs(Y-Y_prev))
Y_prev = Y
self.label_distributions_ = Y
return selffit(X, y) 函数接收两个输入参数:一个 networkx 图对象 X 和一个代表各节点标签的数组 y,未标注节点的标签值应设为 -1。while 循环执行实际的计算。具体地说,它在每次迭代时计算 Y t Y^t Yt 值,并强制要求解中已标注节点的值保持其原始输入值不变。算法将持续进行计算,直至满足以下两个停止条件:
- 迭代次数:算法持续执行,直至达到预设的迭代次数
- 解的容差阈值:当连续两次迭代所得解( y t − 1 y^{t-1} yt−1 与 y t y_t yt )的绝对差值小于设定阈值时终止计算
应用该算法:
python
glp = GraphLabelPropagation()
y = np.array([-1 for x in range(len(G.nodes()))])
y[0] = 1
y[6] = 0
glp.fit(G,y)
tmp = glp.predict(G)
print(glp.predict_proba(G))结果如下所示,从最终的概率分配矩阵中,可以看到初始标记节点的概率为 1,这是由于算法的约束,并且"靠近"标记节点的节点会得到它们的标签:
shell
[[0. 1. ]
[0.05338542 0.90006109]
[0.11845743 0.8081115 ]
[0.31951678 0.553297 ]
[0.553297 0.31951678]
[0.8081115 0.11845743]
[1. 0. ]
[0.90006109 0.05338542]]3.2 标签扩散算法
标签扩散算法 (label spreading algorithm) 是另一种半监督浅层嵌入算法。它是为克服原始标签传播的限制而构建的------初始标签的不可变性。在原始算法中,初始标签在训练过程中不可更改,每次迭代都被强制保持原始值。当初始标注存在误差或噪声时,这种约束可能导致错误结果在整个图中传播。
为解决这一局限,标签扩散算法放松了对原始标注数据的约束,允许已标注节点在训练过程中改变其标签。
设 G = ( V , E ) G=(V,E) G=(V,E) 为一个图, Y = { y 1 , . . . , y p } Y=\{y_1,...,y_p\} Y={y1,...,yp} 为标签集合(由于是半监督算法,仅部分节点具有标签), A ∈ R ∣ V ∣ × ∣ V ∣ A\in \mathbb R^{|V|\times|V|} A∈R∣V∣×∣V∣ 和 D ∈ R ∣ V ∣ × ∣ V ∣ D\in \mathbb R^{|V|\times|V|} D∈R∣V∣×∣V∣ 分别为图 G G G 的邻接矩阵和对角度矩阵。与计算概率转移矩阵不同,标签扩散算法使用归一化图拉普拉斯矩阵,其定义如下:
L = D − 1 / 2 A D − 1 / 2 L=D^{-1/2}AD^{-1/2} L=D−1/2AD−1/2
与原始算法类似,该矩阵可视为对整个图连接关系的紧凑低维表示。通过以下 networkx 代码可轻松计算该矩阵:
python
from scipy.linalg import fractional_matrix_power
D_inv = fractional_matrix_power(D, -0.5)
L = D_inv*np.asmatrix(nx.to_numpy_array(G))*D_inv计算结果如下所示:
L = 0. 0.5 0.40824829 0. 0. 0. 0. 0. 0.5 0. 0.40824829 0. 0. 0. 0. 0. 0.40824829 0.40824829 0. 0.40824829 0. 0. 0. 0. 0. 0. 0.40824829 0. 0.5 0. 0. 0. 0. 0. 0. 0.5 0. 0.40824829 0. 0. 0. 0. 0. 0. 0.40824829 0. 0.40824829 0.40824829 0. 0. 0. 0. 0. 0.40824829 0. 0.5 0. 0. 0. 0. 0. 0.40824829 0.5 0. L=\begin{bmatrix} 0.&0.5&0.40824829&0.&0.&0.&0.&0. \\ 0.5&0.&0.40824829&0.&0.&0.&0.&0. \\ 0.40824829&0.40824829&0.&0.40824829&0.&0.&0.&0. \\ 0.&0.&0.40824829&0.&0.5&0.&0.&0. \\ 0.&0.&0.&0.5&0.&0.40824829&0.&0.\\ 0.&0.&0.&0.&0.40824829&0.&0.40824829&0.40824829\\ 0.&0.&0.&0.&0.&0.40824829&0.&0.5 \\ 0.&0.&0.&0.&0.&0.40824829&0.5&0. \end{bmatrix} L= 0.0.50.408248290.0.0.0.0.0.50.0.408248290.0.0.0.0.0.408248290.408248290.0.408248290.0.0.0.0.0.0.408248290.0.50.0.0.0.0.0.0.50.0.408248290.0.0.0.0.0.0.408248290.0.408248290.408248290.0.0.0.0.0.408248290.0.50.0.0.0.0.0.408248290.50.
原始标签传播算法与标签扩散算法的核心差异在于标签提取函数的设计。设 Y 0 Y^0 Y0 为初始标签分配,利用 L L L 矩阵计算各节点标签分配概率的公式如下:
Y 1 = α L Y 0 + ( 1 − α ) Y 0 Y^1=\alpha LY^0+(1-\alpha)Y^0 Y1=αLY0+(1−α)Y0
与原始算法类似,标签扩散同样采用迭代计算框架。算法将执行 n n n 次迭代,在第 t t t 次迭代时的解为:
Y t = α L Y t − 1 + ( 1 − α ) Y 0 Y^t=\alpha LY^{t-1}+(1-\alpha)Y^0 Yt=αLYt−1+(1−α)Y0
当满足特定条件时迭代终止。需要重点说明方程中的 ( 1 − α ) Y 0 (1-\alpha)Y^0 (1−α)Y0 项:标签扩散算法不再强制要求解中的标注元素保持初始值,而是通过正则化参数 α ∈ ( 0 , 1 ] α∈(0,1] α∈(0,1] 动态调节原始解在每次迭代中的权重影响。这种机制使我们能够显式控制初始解的"质量"及其对最终结果的影响程度。
与原始标签传播算法类似,基于 scikit-learn 库的 LabelSpreading 类,实现改进版的 GraphLabelSpreading 类------通过继承 GraphLabelPropagation 类实现,仅需重写 fit() 方法:
python
class GraphLabelSpreading(GraphLabelPropagation):
@_deprecate_positional_args
def __init__(self, max_iter=30, tol=1e-3, alpha=0.6):
self.alpha = alpha
super().__init__(max_iter, tol)
def fit(self, X, y):
X, y = self._validate_data(X, y)
self.X_ = X
check_classification_targets(y)
D = [X.degree(n) for n in X.nodes()]
D = np.diag(D)
D_inv = np.matrix(fractional_matrix_power(D,-0.5))
L = D_inv*np.asmatrix(nx.to_numpy_array(G))*D_inv
# label construction
# construct a categorical distribution for classification only
unlabeled_index = np.where(y==-1)[0]
labeled_index = np.where(y!=-1)[0]
unique_classes = np.unique(y[labeled_index])
self.classes_ = unique_classes
Y0 = np.array([self.build_label(y[x], len(unique_classes))
if x in labeled_index else np.zeros(len(unique_classes)) for x in range(len(y))])
Y_prev = Y0
it = 0
c_tool = 10
while it < self.max_iter & c_tool > self.tol:
Y = self.alpha*(L*Y_prev)+((1-self.alpha)*Y0)
it +=1
c_tol = np.sum(np.abs(Y-Y_prev))
Y_prev = Y
self.label_distributions_ = Y
return selffit() 函数接受一个 networkx 图对象 X 和一个表示节点标签的数组 y (未标注节点以 -1 表示)。while 循环在每次迭代时计算 Y t Y^t Yt 值,并通过参数 α α α 加权控制初始标签的影响力。算法采用迭代次数和两个连续解之间的差异作为停止标准。
应用算法:
python
gls = GraphLabelSpreading(max_iter=1000)
y = np.array([-1 for x in range(len(G.nodes()))])
y[0] = 1
y[6] = 0
gls.fit(G,y)
tmp = gls.predict(G)
print(gls.predict_proba(G))
draw_graph(G, nodes_label=tmp+1, node_size=1200)输出结果如下所示:
shell
[[0.00148824 0.50403871]
[0.00148824 0.19630098]
[0.00471728 0.18369265]
[0.01591722 0.05001252]
[0.05001252 0.01591722]
[0.18369265 0.00471728]
[0.50403871 0.00148824]
[0.19630098 0.00148824]]从结果可以看出,标签扩散算法的输出结果与原始标签传播算法的结果形态相似,但在标签分配概率上存在显著差异。具体表现为:初始已标注节点(节点 0 和 6 )的标签概率降至 0.5,而原始算法中该概率恒为 1。这种差异正是正则化参数 α α α 对初始标签影响力进行加权控制的结果。