文章目录
- 摘要
- [1 引言](#1 引言)
- [2 相关工作](#2 相关工作)
- [3 方法](#3 方法)
-
- [3.1 HmSDF 表示](#3.1 HmSDF 表示)
- [3.2 区域聚合](#3.2 区域聚合)
- [3.3. 变形场](#3.3. 变形场)
- [3.4. 遮挡感知可微分渲染](#3.4. 遮挡感知可微分渲染)
- [3.5 训练](#3.5 训练)
-
- [3.5.1 训练策略](#3.5.1 训练策略)
- [3.5.2 重建损失](#3.5.2 重建损失)
- [3.5.3 正则化限制](#3.5.3 正则化限制)
- [4. 实验](#4. 实验)
-
- [4.1 定量评估](#4.1 定量评估)
- [4.2 定性评价](#4.2 定性评价)
- [4.3 消融研究](#4.3 消融研究)
- [4.4 应用程序](#4.4 应用程序)
- [5 结论](#5 结论)

摘要
我们介绍 D 3 D^{3} D3人,一种从单目视频中重建动态解耦数字人体几何的方法。过去的单目视频人体重建主要集中在重建未解耦的衣服人体或仅重建服装,使得其难以直接应用于动画制作等应用中。重建解耦的衣服和身体的挑战在于衣服对身体造成的遮挡。为此,在重建过程中必须确保可见区域的细节和不可见区域的合理性。我们提出的方法结合显式和隐式表示 对解耦的衣服人体进行建模,利用显式表示的鲁棒性和隐式表示的灵活性 。具体来说,我们将可见区域重建为SDF,并提出一种新颖的人类流形符号距离场(hmSDF)来分割可见衣服和可见身体,然后合并可见和不可见身体。广泛的实验结果表明,与现有的重建方案相比, D 3 D^{3} D3可以实现人体穿着不同服装的高质量解耦重建,并可以直接应用于服装转移和动画。
1 引言
衣着人体重建长期以来一直是图形学和计算机视觉领域的研究热点,在虚拟现实、增强现实、全息通信、电影制作、游戏开发等诸多领域有着广泛的应用。相比需要众多摄像机和艺术家进行建模的电影级重建,从单目视频中重建高质量的衣着人体对一般用户来说更具实用价值。在远程呈现和虚拟试穿等场景中,使用的3D化身应该易于访问、视觉逼真且易于编辑,包括对服装和姿势的修改。因此,如何利用单目视频重建高保真、解耦的衣着人体表示仍然是一个长期存在的研究问题。**通过解耦重建,**可以将服装与人体分离,从而实现对不同服装风格、姿势和体型的高效调整和编辑。这种解耦不仅增强了三维重建的灵活性和实用性,还提高了细节特征的真实感,为虚拟角色的个性化和动态交互提供了更大的潜力。
我们的目标是开发一种从单眼视频中解耦和重建穿着衣服的人体的方法。然而,这是一项非常具有挑战性的任务,因为1)单目视频仅提供单视图2D图像信息,缺乏直接的3D深度感知,2)真实拍摄的视频包含各种服装样式、不规则纹理和复杂的人体姿势,3)被衣服遮挡的身体部位在输入视频中不可见,这也对重建提出了很大的挑战。现有方法可分为显式表达方法和隐式表达方法。其中,显式表达方法通常依赖于预先获取的模板。一些方法15、16、56使用扫描仪,而其他方法2、28、41依赖于参数模型19、34,重建质量主要取决于模型的表示能力。隐式表示方法9,14,20,22,42使用NeRF37或SDF40来模拟穿着衣服的人体,但它们通常会产生不可分割的整体或表现出平均的几何质量。
我们提出了一种解耦的人体重建方案,命名为 D 3 D^{3} D3-人类(动态解耦数字人类),它结合了显式和隐式表示来解决模板生成的主要挑战和动态变形。在解耦的人体重建中,生成服装模板特别具有挑战性。传统方法,例如基于参数模型28或特征线45的方法,严重依赖先验,限制了它们可以表示的服装类型。虽然隐式无符号距离场(UDF)表示5,13,31,33提供了一些解决方案,但当单视图监督受到限制时,它们的表现不佳(参见实验4.3)。对于可见区域,受GShell32和DMTet52的启发,我们在非解耦的衣服人体表面上定义了一个可优化的人体流形有符号距离场(hmSDF),以将服装与身体分开。据我们所知,这是第一种可以在没有任何3D服装先验的情况下从单目动态人体视频中重建服装几何形状的方法,仅使用易于获得的2D人体解析分割46。对于身体的不可见区域,我们采用SMPL34模型的相应区域的显式表示,以确保身体形状的合理性以及与可见区域的无缝集成。这种方法能够对穿着衣服的人体进行详细和解耦的重建。
我们基于单目视频重建穿着各种服装的不同人体,以展示我们方法的能力。与现有的需要一天多20,45,54进行重建的方法相比, D 3 D^{3} D3-人类在更短的时间(约20分钟)内重建了服装和身体的解耦模板,并在几个小时内完成了完整的序列,实现了具有竞争力的重建精度。此外,我们展示了动画制作和服装转移中的应用示例,以展示广泛的应用解耦表示的可复制性。总之,本文的贡献包括以下几个方面:
-
提出了一种结合显式和隐式表示的混合重建方法,能够从单目视频中重建高质量、解耦的服装和人体。
-
对于可见区域的穿着衣服的人体,我们引入了一种新颖的表示,hmSDF,它可以通过易于获得的 2D 人体解析准确地分割 3D 衣服和身体,而无需任何 3D 衣服先验。
-
重建的解耦服装和人体可以轻松应用于动画制作和服装转移应用,提供逼真和详细的几何质量。
提出想法算贡献、实现想法算贡献、解决了什么实际问题,能够应用哪些领域算贡献
2 相关工作
衣服人体的解耦表示。大多数方法将穿着衣服的人体几何形状重建为一个整体,包括像网格 2,3、点云 36,57、SDF 6,20,39 和占用 48,49 这样的表示。这些重建方法在可见区域保持了良好的细节,但对于动画和服装转移等应用不方便。更有效的方法是独立地表示衣服和身体,将它们建模为解耦的、分层的表示。GALA 27 和 ClothCap 44 利用 3D 分割分别从 3D 和 4D 扫描中获得单独的衣服和身体网格,这种方法受到获取扫描数据的高成本的限制。神经 ABC 5 基于 UDF(无符号距离函数)表示构建了解耦的人体和衣服参数化模型,但其对细节的重建是有限的。SCARF 9 从视频序列中重建了穿着衣服的人体的混合表示,但是 NeRF 37 对衣服的表示在几何效果上是有限的。其他一些方法专注于重建衣服 7,8,19,47,58,这允许通过使用 SMPL 34 作为底层身体来解耦;然而,这些方法中的身体通常缺乏细节。
从单视图图像重建。传统方法通过在参数空间 24,29,30 内通过优化或回归将参数化人体模型拟合到单视图图像进行重建。拟合的有效性在很大程度上取决于参数化模型的表示能力。像 SMPL 34 和 SCAPE 4 这样的模型可以在没有衣服的情况下重建底层身体。一些方法 7,8,19 可以重建衣服并使用 SMPL 模型来表示底层身体,实现了穿着衣服的人体的完整重建。还有一些模型同时代表衣服和底层身体,包括统一建模 6,39 和分层建模 5 的方法。基于参数的重建方法可以很容易地产生看似合理的穿着衣服的人体形象,但一般缺乏细节。针对单个图像的方法可以逐帧重建视频;然而,它们往往无法确保帧间一致性,例如缺乏帧到帧的一致性,或者可能导致结果不流畅。
从单目视频重建。从视频输入中重建3D穿衣人体通常依赖于运动和变形线索来恢复可变形的3D表面。早期的作品获得了特定于演员的操纵模板15,16,56或使用参数模型作为先验2。许多努力9,22,41-43,54,基于NeRF37和3DGS25,从动态视频中重建可动画的人体化身,主要侧重于渲染效果,但几何重建的质量并不理想。14,20,53重建了高质量的穿衣人体几何形状,但服装和下面的身体是不可分离的。DGarment28和REC-MV45重建了动态服装,不包括身体。我们的方法可以在确保几何质量的同时重建解耦的服装和下面的身体。
3 方法
给定一个包含N帧的单目视频,它描绘了一个穿着衣服的人在运动, I t ∣ t = 1 , . . . , N {I_{t} | t=1, ..., N} It∣t=1,...,N D 3 D^{3} D3-人类的目标是在不使用3D服装模板先验的情况下重建高保真、解耦和时空连续的服装和底层身体网格 G t ∣ t = 1 , . . . , N {G_{t} | t=1, ..., N} Gt∣t=1,...,N。为了实现最大的真实感,视频捕获的观察区域,如暴露的头部和衣服,应该非常详细地重建;模糊的区域,如被衣服覆盖的身体部位或被身体遮挡的身体部位,应该尽可能合理地重建。(有些细节、有些粗糙)
为了实现这些目标,我们将隐式表示的灵活性与显式表示的鲁棒性和快速渲染能力相结合,以达到最佳效果。值得注意的是,可以通过闭合曲线将水密穿着衣服的人的表面分割成衣服和身体部位 。因此,我们首先利用图像和人类解析分割序列信息来重建可见区域中分离的衣服和身体网格。然后,在SMPL34的帮助下,我们完成了不可见的身体区域,并生成解耦的衣服和身体模板 。最后,额外使用正常信息来共同优化衣服和身体,以增强细节。图2说明了我们方法的整体管道。
3.1 HmSDF 表示
在本节中,我们定义了服装模板 G c G_{c} Gc和身体模板 G b G_{b} Gb在规范空间中。考虑到被服装遮挡的身体部位在视频中是不可见的,我们进一步将服装和身体分为可见的身体 S b S_{b} Sb、不可见的身体 U b U_{b} Ub和可见的服装 S c S_{c} Sc。通过侦察后的分割获得可见的身体 S b S_{b} Sb利用SMPL模型构建整体衣身,同时完成不可见体 M b M_{b} Mb,可见体和不可见体合并形成体模板 G b G_{b} Gb
可见的服装和身体由混合表示52表示,它结合了四面体网格网格 ( V T , T ) (V_{T}, T) (VT,T)和神经隐式有符号距离函数 s η ( x ) s_{\eta}(x) sη(x),其中 x ∈ V T x \in V_{T} x∈VT和 s η ( x ) s_{\eta}(x) sη(x)是具有可学习权重n的神经网络, S b ∪ S c S_{b} \cup S_{c} Sb∪Sc的表面可以用 S η = x ∈ R 3 ∣ s η ( x ; η ) = 0 S_{\eta}={x \in \mathbb{R}^{3} | s_{\eta}(x ; \eta)=0} Sη=x∈R3∣sη(x;η)=0表示,网格可以使用遵循GShell32的方法提取。
由于重构的水密布人体 S η = S b ∪ S c S_{\eta}=S_{b} \cup S_{c} Sη=Sb∪Sc,我们在 S η S_{\eta} Sη上定义一个连续可微的映射 ν : S η → R \nu: S_{\eta} \to \mathbb{R} ν:Sη→R来表征一个点是否属于 S b S_{b} Sb或 S c S_{c} Sc:
ν ( x ) = { < 0 , ∀ x ∈ I n t e r i o r ( S b ) , = 0 , ∀ x ∈ λ , > 0 , ∀ x ∈ I n t e r i o r ( S c ) , \nu(x)= \begin{cases}<0, & \forall x \in Interior\left(S_{b}\right), \\ =0, & \forall x \in \lambda, \\ >0, & \forall x \in Interior\left(S_{c}\right),\end{cases} ν(x)=⎩ ⎨ ⎧<0,=0,>0,∀x∈Interior(Sb),∀x∈λ,∀x∈Interior(Sc),
其中λ表示 S b S_{b} Sb和 S c S_{c} Sc之间的边界线。我们将2表示为人类流形有符号距离场,称为hmSDF。这不同于GShell中mSDF的定义,它只考虑位于开放表面内的点。相比之下,我们的方法考虑hmSDF(可见服装和身体)两侧的点。
3.2 区域聚合
理想情况下,一个优化的hmSDF函数2应该准确地分割可见的服装 S c S_{c} Sc和身体 S b S_{b} Sb,但是由于每一帧的人类解析掩码中的不准确以及帧之间的不一致,不准确可能发生在边界线λ,如图3所示。当不准确发生在 ν ( x ) = 0 \nu(x)=0 ν(x)=0的邻域时,它会导致 S b ′ S_{b}' Sb′和 S c ′ S_{c}' Sc′的分割区域包含孔,并创建不希望的分割区域 S b ′ ′ S_{b}^{\prime \prime} Sb′′和 S c ′ ′ S_{c}^{\prime \prime} Sc′′。 S b ′ ′ S_{b}^{\prime \prime} Sb′′和 S c ′ ′ S_{c}^{\prime \prime} Sc′′中包含的小片段不可避免地与其他子图断开连接。
我们从输入图像中获取每个类别的连通分支个数,由于错误分类的连通分支的顶点通常较少,因此可以通过使用深度优先搜索方法计算每个连通分支的顶点个数来确定每个子图的类别 S b ′ S_{b}' Sb′、 S c ′ S_{c}' Sc′、 S b ′ ′ S_{b}^{\prime \prime} Sb′′和 S c ′ ′ S_{c}^{\prime \prime} Sc′′,通过如下聚合可以获得正确的 S b S_{b} Sb和 S c S_{c} Sc:
S b = m e r g e ( S b ′ , S c ′ ′ ) , ( 1 ) S_{b}=merge\left(S_{b}', S_{c}''\right), (1) Sb=merge(Sb′,Sc′′),(1)
S c = m e r g e ( S c ′ , S b ′ ′ ) . ( 2 ) S_{c}=merge\left(S_{c}', S_{b}''\right) . (2) Sc=merge(Sc′,Sb′′).(2)
3.3. 变形场
我们在算法1中演示了 S b S_{b} Sb和 S c S_{c} Sc的聚合过程。
与以前的方法20,45类似,我们使用基于SMPL的线性混合蒙皮(LBS)方法来建模大型基于骨骼运动的变形,并采用非刚性变形场来模拟细微变形。然而,一个关键的区别是服装和身体遵循不同的运动规则。因此,我们使用两个独立的非刚性变形场来分别模拟服装和身体的非刚性变形。
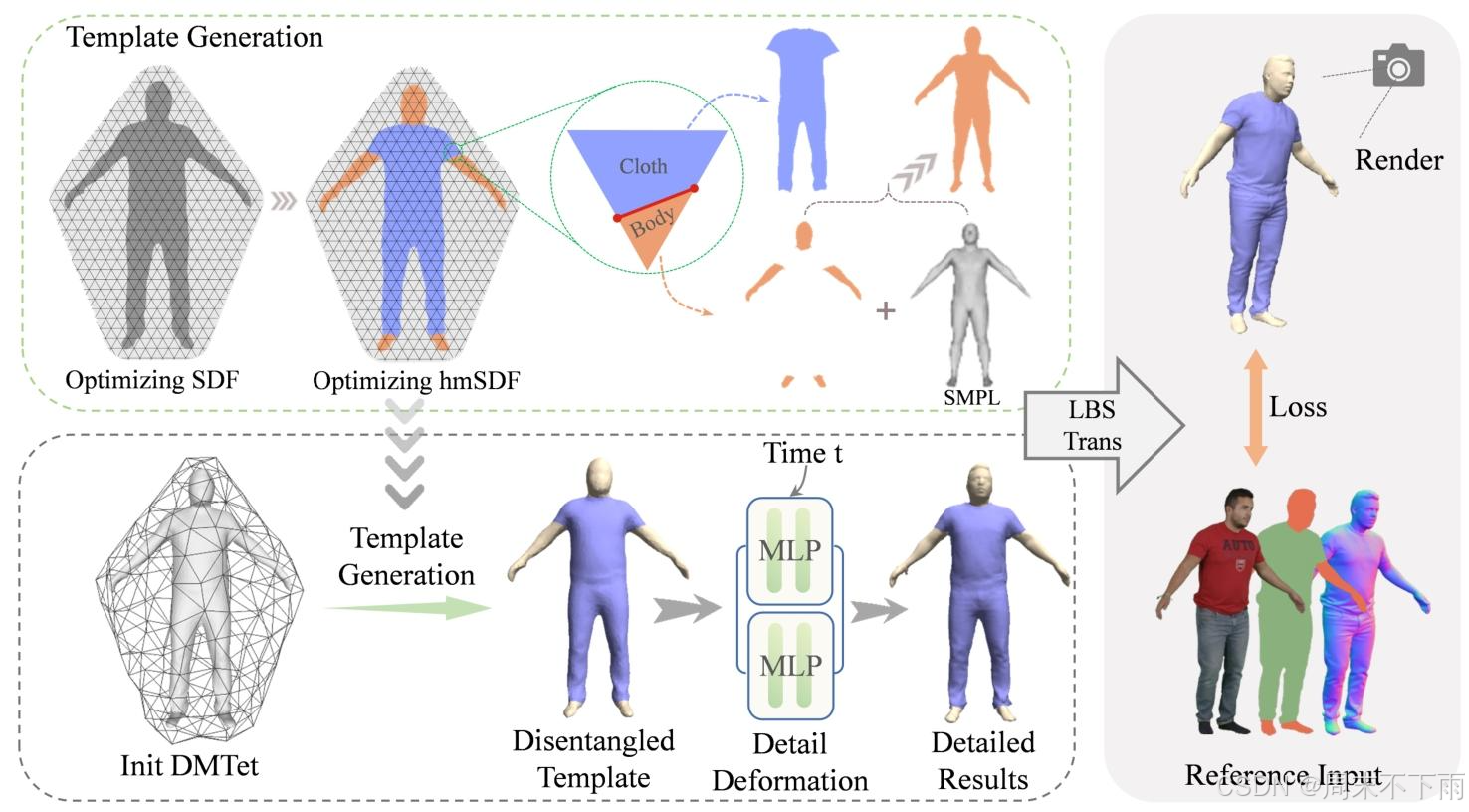
图2. D 3 D^{3} D3概述-人类。优化过程分为两个步骤:模板生成和详细变形。对象被初始化为DMTet52表示,并被优化以形成一个完整的穿着衣服的人。一个可优化的HmSDF函数,分别为身体和衣服网格的每一帧建模详细变形。最后,使用前向LBS变形将网格转换到观察到的空间,由图像、法线贴图监督,并使用可微渲染器解析蒙版。分离衣服和身体区域,缺失的部分由SMPL填充。生成解开的模板后,我们使用两个MLP
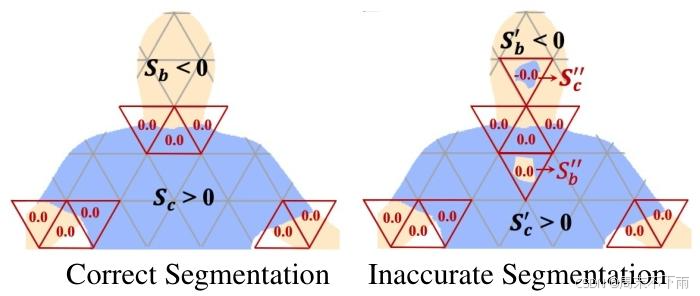
分割结果, S b S_{b} Sb和 S c S_{c} Sc正确分割身体和图3。区域聚合示意图。对于正确的分割布。对于不准确的分割结果, S c ′ ′ S_{c}^{\prime \prime} Sc′′应该与 S b ′ S_{b}' Sb′合并, S b ′ ′ S_{b}^{\prime \prime} Sb′′应该与 S c ′ S_{c}' Sc′合并
| 步骤 | 操作(区域聚合算法) |
|---|---|
| 输入 | 直接从X获得的初始分割 S b 0 S^0_b Sb0和 S c 0 S^0_c Sc0; S b S_b Sb和 S c S_c Sc正确的子图数量分别为 o 1 o_1 o1和 o 2 o_2 o2 |
| 1 | 计算 S b 0 S^0_b Sb0的所有连通子图 Q b Q_b Qb |
| 2 | 计算 S c 0 S^0_c Sc0的所有连通子图 Q c Q_c Qc |
| 3 | 根据顶点数量对 Q b Q_b Qb进行排序 |
| 4 | 根据顶点数量对 Q c Q_c Qc进行排序 |
| 5 | 根据 o 1 o_1 o1从 Q b Q_b Qb中提取 S b ′ S'_b Sb′和 S b ′ ′ S''_b Sb′′ |
| 6 | 根据 o 2 o_2 o2从 Q c Q_c Qc中提取 S c ′ S'_c Sc′和 S c ′ ′ S''_c Sc′′ |
| 7 | 通过公式(1)和(2)得到 S b S_b Sb和 S c S_c Sc,并过滤掉重复点 |
| 输出 | 无孔洞和碎片的 S b S_b Sb和 S c S_c Sc |
非刚性变形。由于自由度有限,LBS变形只能模拟大变形,无法表示较小的细节,如衣服的褶皱。因此,对于细节变形,我们使用两个MLP来模拟服装和人体的非刚性变形。D是非刚性变形的MLP:
x t = D ( x , h t , E ( x ) ; ϕ ) , x^{t}=D\left(x, h^{t}, E(x) ; \phi\right), xt=D(x,ht,E(x);ϕ),
其中x是正则空间中的点, x t x^{t} xt是t帧中变形后的点, h t h^{t} ht是t帧对应的潜码,和ل是需要优化的网络参数,对于服装和身体,网络和参数是独立独立的。
LBS变形 。线性混合蒙皮(LBS)变形模型基于骨骼变形从规范空间到观察空间的转换。给定SMPL形状参数β和位姿参数 θ t \theta_{t} θt,LBS变形W可以写成:
G ′ ( β , θ t ) = W ( D ( x ) , β , θ t , W ( x ) ) , G'\left(\beta, \theta_{t}\right)=W\left(D(x), \beta, \theta_{t}, \mathcal{W}(x)\right), G′(β,θt)=W(D(x),β,θt,W(x)),
其中 D ( x ) D(x) D(x)表示服装和身体的非刚性变形, W ( x ) W(x) W(x)是基于SMPL计算x的蒙皮权重的方法,我们参考一些服装模拟方法11,51计算蒙皮权重,对于服装和身体两者,我们使用共享蒙皮变形模型。
3.4. 遮挡感知可微分渲染
可微分渲染用于将观察空间中的几何图形渲染为2D,这允许在2D监督下计算损失。遵循一些可微分渲染方法17,32,38,我们利用可微分光栅化方法来渲染网格。与体积渲染方法相比,基于光栅化的渲染支持显式网格的可微分渲染,并提供更好的时间和内存效率。
对于穿着衣服的身体,身体和衣服之间可能会发生遮挡,这会导致在从同一视点渲染衣服的可见区域时发生遮挡。因此,仅渲染衣服网格以获得服装蒙版可能会产生与监督信号不一致的结果,如图4所示。为了解决这个问题,我们标记了衣服和身体的面部,同时渲染它们。然后我们使用光栅化生成遮挡感知2D标签,其中身体标签的有效区域是身体蒙版 M b M_{b} Mb,而衣服标签的有效区域是衣服蒙版 M c M_{c} Mc

图4.面罩遮挡显示从左到右:捕获的衣着人的彩色图像,从SAM2获得的完整衣着身体面罩46,从SAM2获得的衣着面罩,仅渲染服装网格获得的面罩,渲染完整衣着身体网格后有效服装区域的面罩。
3.5 训练
3.5.1 训练策略
我们的方法由两个阶段组成:模板生成和细节变形优化。在模板生成阶段,我们利用hmSDF直接从面具监督中学习服装模板,而不依赖于3D服装先验。在这个阶段,仅通过LBS实现变形,并通过RGB损失、面具损失、Eikonal损失、鼓励开孔和正则化孔来优化参数。在细节变形阶段,我们引入了一个额外的感知法向损失作为重建项,而正则化通过碰撞惩罚和几何正则化来优化非刚性变形。
3.5.2 重建损失
我们通过以下目标最小化渲染结果和输入图像之间的差异:
RGB损失 。在渲染的RGB图像和监督图像之间计算 L 1 L_{1} L1。我们计算所有有效像素P如下,
L c o l o r = 1 ∣ P ∣ ∑ p ∈ P ( 1 b ( p ) ⋅ L m s e ( I b , I ^ b ) + 1 c ( p ) ⋅ L m s e ( I c , I ^ c ) ) , \begin{aligned} L_{color }=\frac{1}{|P|} \sum_{p \in P} & \left(1_{b}(p) \cdot L_{mse}\left(I_{b}, \hat{I}{b}\right)\right. \\ & \left.+1{c}(p) \cdot L_{mse}\left(I_{c}, \hat{I}_{c}\right)\right), \end{aligned} Lcolor=∣P∣1p∈P∑(1b(p)⋅Lmse(Ib,I^b)+1c(p)⋅Lmse(Ic,I^c)),
其中 1 ( p ) \mathbb{1}(p) 1(p)表示当前像素点P所属的类别,当 1 b ( p ) \mathbb{1}{b}(p) 1b(p)为真时,像素p属于本体;当 1 c ( p ) \mathbb{1}{c}(p) 1c(p)为真时,像素p属于布料。 1 b ( p ) \mathbb{1}{b}(p) 1b(p)和 1 c ( p ) \mathbb{1}{c}(p) 1c(p)可以同时为真,也可以只有一个为真,具体取决于用于监督的掩模。 I b I_{b} Ib为本体渲染的RGB图像, I c I_{c} Ic为服装渲染的RGB图像, I ^ b \hat{I}{b} I^b为本体实况RGB图像, I ^ c \hat{I}{c} I^c为服装的地面实况RGB图像。
蒙版丢失。虽然在RGB图像监督中已经删除了不相关的背景,但独立添加的蒙版损失会进一步限制边缘的准确性,正如,
L m a s k = 1 ∣ P ∣ ∑ p ∈ P ( 1 b ( p ) ⋅ L m s e ( M b , M ^ b ) + 1 c ( p ) ⋅ L m s e ( M c , M ^ c ) ) , \begin{aligned} L_{mask }= & \frac{1}{|P|} \sum_{p \in P}\left(\mathbb{1}{b}(p) \cdot L{mse}\left(M_{b}, \hat{M}{b}\right)\right. \\ & \left.+\mathbb{1}{c}(p) \cdot L_{mse}\left(M_{c}, \hat{M}_{c}\right)\right), \end{aligned} Lmask=∣P∣1p∈P∑(1b(p)⋅Lmse(Mb,M^b)+1c(p)⋅Lmse(Mc,M^c)),
其中 M ^ b \hat{M}{b} M^b是身体的地面实况面罩, M ^ c \hat{M}{c} M^c是服装的地面实况面罩。
感知法线损失。我们通过Sapiens26获得图像的法线作为地面实况,以利用在大规模人体数据上训练的先验信息。渲染法线和监督法线需要归一化并与观察空间对齐。我们使用感知损失18,23以进一步增强渲染法线的有效性。
L p e r = ∑ i ∥ ϕ i ( N ) − ϕ i ( N ^ ) ∥ 2 , L_{per }=\sum_{i}\left\| \phi_{i}(\mathcal{N})-\phi_{i}(\hat{\mathcal{N}})\right\| ^{2}, Lper=i∑ ϕi(N)−ϕi(N^) 2,
其中N是渲染法线, N ^ \hat{N} N^是地面实况法线, ϕ i ( ∗ ) \phi_{i}(*) ϕi(∗)表示MobileNetV2网络中第i层的激活50。
3.5.3 正则化限制
Eikonal损失。为了确保合理的有符号距离场,我们在优化SDF时在每个四面体顶点的SDF值的梯度9中添加一个Eikonal项12:
L e i k = ∑ u ∈ V T ( ∥ g u ∥ 2 − 1 ) 2 . L_{eik}=\sum_{u \in V_{T}}\left(\left\| g_{u}\right\| _{2}-1\right)^{2} . Leik=u∈VT∑(∥gu∥2−1)2.
鼓励开孔。在视点有限的情况下,有必要仅使用图像信息来识别开口位置。我们通过采用类似于32的正则化术语来鼓励hmSDF开口,
L h o l e = ∑ u : ν ( u ) ≥ 0 L h u b e r ( ν ( u ) ) . L_{hole }=\sum_{u: \nu(u) \geq 0} L_{huber }(\nu(u)) . Lhole=u:ν(u)≥0∑Lhuber(ν(u)).
孔洞正则化。为了避免过大的开口,我们对当前视点可见的所有点施加约束
L r e g − h o l e = ∑ u : ν ( u ) = 0 L h u b e r ( ν ( u ) − ϵ 1 ) , L_{reg-hole }=\sum_{u: \nu(u)=0} L_{huber }\left(\nu(u)-\epsilon_{1}\right), Lreg−hole=u:ν(u)=0∑Lhuber(ν(u)−ϵ1),
其中 ϵ 1 \epsilon_{1} ϵ1是正标量。
碰撞惩罚。这确保了衣服不会穿透下面的身体,灵感来自11,51。我们将其实施为
L c o l l i s i o n = ∑ v e r t i c e s k c o l l i s i o n m a x ( ϵ 2 − d ( x ) , 0 ) 3 . ( 9 ) L_{collision }=\sum_{vertices } k_{collision } max \left(\epsilon_{2}-d(x), 0\right)^{3} . (9) Lcollision=vertices∑kcollisionmax(ϵ2−d(x),0)3.(9)
特别是,当两层之间的距离太近时,渲染会产生计算错误,因此 ϵ 2 \epsilon_{2} ϵ2的值设置为0.005。
几何正则化 。为了确保优化受到约束,我们鼓励生成平滑变形的结果。受Worchel等人55的启发,我们添加了正态一致性项 L n c o n s i s t L_{n_consist } Lnconsist和拉普拉斯项 L a p l a c i a n Laplacian Laplacian
4. 实验
我们进行定性和定量实验来证明 D 3 D^{3} D3的有效性。对于定性实验,我们使用来自PeopleSnapshot2和SelfRecon20的受试者。对于定量实验,我们使用SelfRecon构建的合成数据集。它为网格提供准确的地面实况。此外,我们对UDF和hmSDF的讨论以及感知法向损失的有效性进行了消融研究,并展示了在服装转移和基于物理的动画制作中的应用。
4.1 定量评估
由于没有公开的真实数据集可用于评估从单目视频中解耦的衣着人重建的几何质量,我们使用了SelfRecon20提供的四个合成数据集,每个数据集包含几何地面实况和渲染的视频。由于这些处理后的数据不是REC-MV45的开源数据,我们手动标记分割点并使用官方工具生成特征线。我们还使用CLO3D1将衣服和身体从源数据中分离出来进行定量评估。我们报告每个方法结果的衣服、身体和完整的衣着人的倒角距离(CD)。对于不支持解耦的方法,我们只报告完整的衣着人的CD。我们在图5中展示了定量比较的可视化,并在表1中报告了指标。结果表明,我们的方法在指标中取得了最佳结果,提供了详细准确的视觉效果,并且能够正确地将人体和服装解耦。
4.2 定性评价
我们将我们的方法与能够从图像序列中重建穿着衣服的人体的方法进行比较,使用来自PeopleSnapshot2数据集的几个序列和来自SelfRecon20的一个序列来包括裙装类别。对于所有方法,我们从完全旋转中提取连续帧,并呈现图8中第一帧的比较结果。补充材料中提供了额外的顺序结果和讨论。
正如我们所看到的,REC-MV45可以准确地重建服装,但缺乏我们的方法所实现的详细级别。由于REC-MV中缺乏对身体的进一步优化,直接使用SMPL导致网格穿透。BCNet19重建了可以直接使用SMPL作为底层身体的服装;然而,它只支持具有一致服装类别的重建,并且几乎缺乏所有细节。DELTA10增强了基于SCARF9的头部细节,并允许直接解耦重建服装和身体。但是,由于它对服装使用了NeRF37表示,因此无法提取平滑的几何形状,导致服装几何形状中出现大量伪影。SelfRecon20使用SDF表示来重建具有正确形状但缺乏细节的穿着衣服的人体。GoMAvata54采用了Gaussian-on-Mesh表示,从而产生相对粗糙的网格。这两种方法都无法实现衣服与身体的解耦。
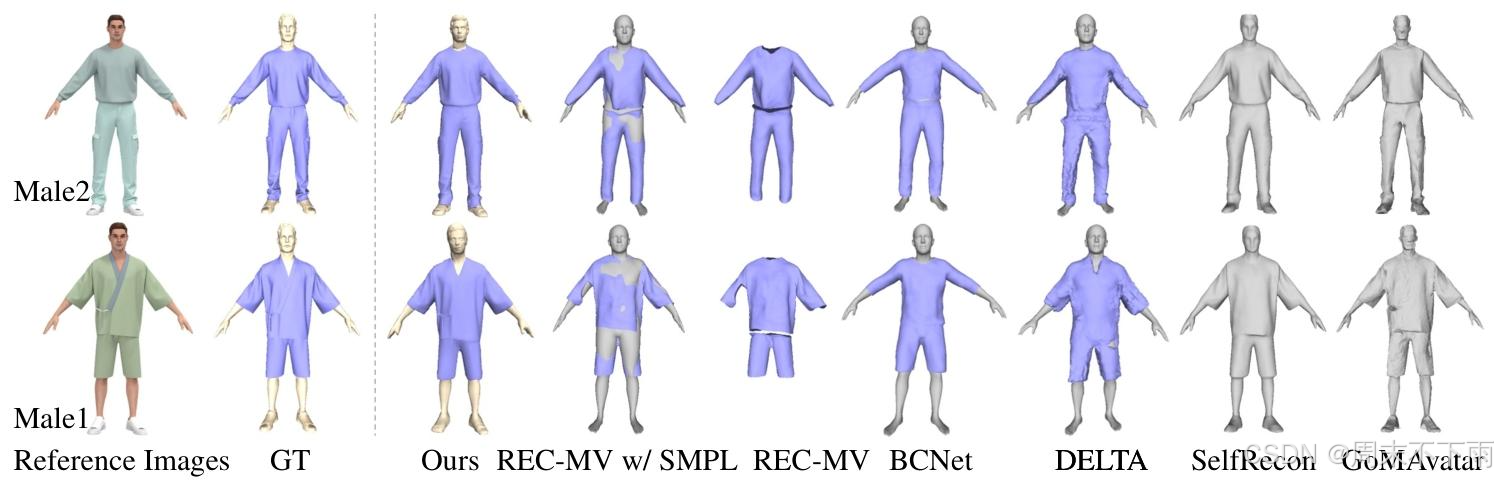
图5.所提出方法与REC-MV45、BCNet19、DELTA10、SelfRecon20和GoMAvata54的定量比较我们使用紫色来可视化可以与身体脱钩的服装,对于REC-MV和BCNet,添加了SMPL34作为身体,以显示穿着衣服的人的完整重建。
表1.跨四个合成序列的定量比较。我们报告重建表面(cm)与地面实况之间的倒角距离(CD)。对于REC-MV、BCNet、DELTA和我们的方法,我们分别报告服装、身体和全衣人体的CD。对于SelfRecon和GoMavator,我们只报告全衣人体的CD。单位为 e − 3 e^{-3} e−3。我们突出最佳值和次最佳值。我们在图5中显示了Male1和Male2,在补充材料中显示了Women ale1和Women ale3。
| Method | Female1 | Female1 | Female1 | Female3 | Female3 | Female3 | Male1 | Male1 | Male1 | Male2 | Male2 | Male2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clothing | Body | All | Clothing | Body | All | Clothing | Body | All | Clothing | Body | All | |
| REC-MV 45 | 1.416 | 1.789 | 1.148 | 0.930 | 2.082 | 1.461 | 0.614 | 1.945 | 0.619 | 0.693 | 1.201 | 0.616 |
| BCNet 19 | 1.685 | 10.252 | 5.561 | 4.571 | 10.112 | 5.681 | 2.589 | 6.236 | 4.802 | 2.007 | 4.109 | 2.853 |
| DELTA 10 | 2.177 | 0.973 | 1.388 | 2.173 | 0.820 | 0.915 | 1.327 | 1.498 | 1.702 | 1.884 | 1.073 | 1.132 |
| SelfRecon 20 | - | - | 3.420 | - | - | 2.249 | - | - | 1.310 | - | - | 1.454 |
| GoMavatar 54 | - | - | 7.319 | - | - | 5.058 | - | - | 2.382 | - | - | 3.163 |
| Ours | 1.065 | 0.966 | 0.959 | 1.109 | 0.742 | 0.636 | 0.478 | 0.321 | 0.270 | 0.355 | 0.325 | 0.279 |
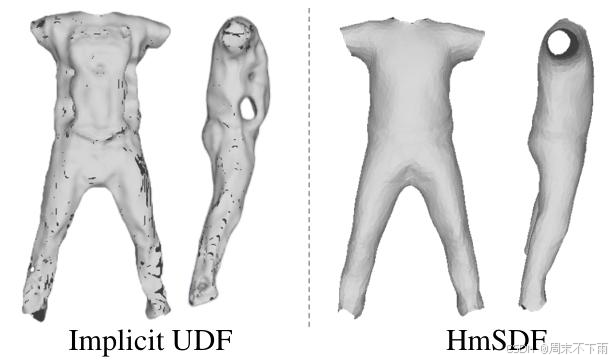
图6.使用具有变形场21和hmSDF的隐式UDF33对服装重建的消融研究,应用于来自PeopleSnapshot2数据集的男性3-休闲数据。
与这些方法相比,我们的方法成功地将服装与身体分离,同时保持更丰富的详细级别。
4.3 消融研究
隐式UDF还是hmSDF?几篇文章5,8,32,33通过使用隐式无符号距离字段(UDF)来表示具有未定义类别的服装来演示结果,利用来自网格或多视图图像的密集监督。然而,我们发现,由于单视图动态人体重建提供的监督有限,UDF难以产生稳健的结果,如图6所示。UDF重建导致许多小洞,腹部区域的一个大洞,并且未能在袖口处创建开口。相比之下,hmSDF实现了准确的服装形状。

图7.正常损耗的消融研究。参考输入包括法线和图像。顶行显示渲染的法线,底行显示渲染的网格。类别,利用来自网格或多视图图像的密集监督。然而,我们发现,由于单视图动态人体重建提供的监督有限,UDF难以产生稳健的结果,如图6所示。UDF重建导致许多小洞,腹部区域的一个大洞,并且未能在袖口处创建开口。相比之下,hmSDF实现了准确的服装形状。
尽管UDF使用网络对形状和pos进行建模UDF具有较强的表示能力,但仍存在一定的问题:(1)UDF在0级集是不可微的。虽然已经针对网格提取和多视图重建问题提出了几种解决方案13,31,33,但UDF在0级集附近仍然敏感,监督信号差的区域可能会导致侦察构造失败。(2)隐式UDF提取曲面的能力有限。隐式UDF13的曲面提取仅限于流形曲面35,隐式表示中非流形的区域可能无法提取。(3)UDF强大的表示能力降低了其抗噪声能力;例如,腹部区域的大洞是由服装面罩中的遮挡引起的。遮挡的一个例子如图4所示。
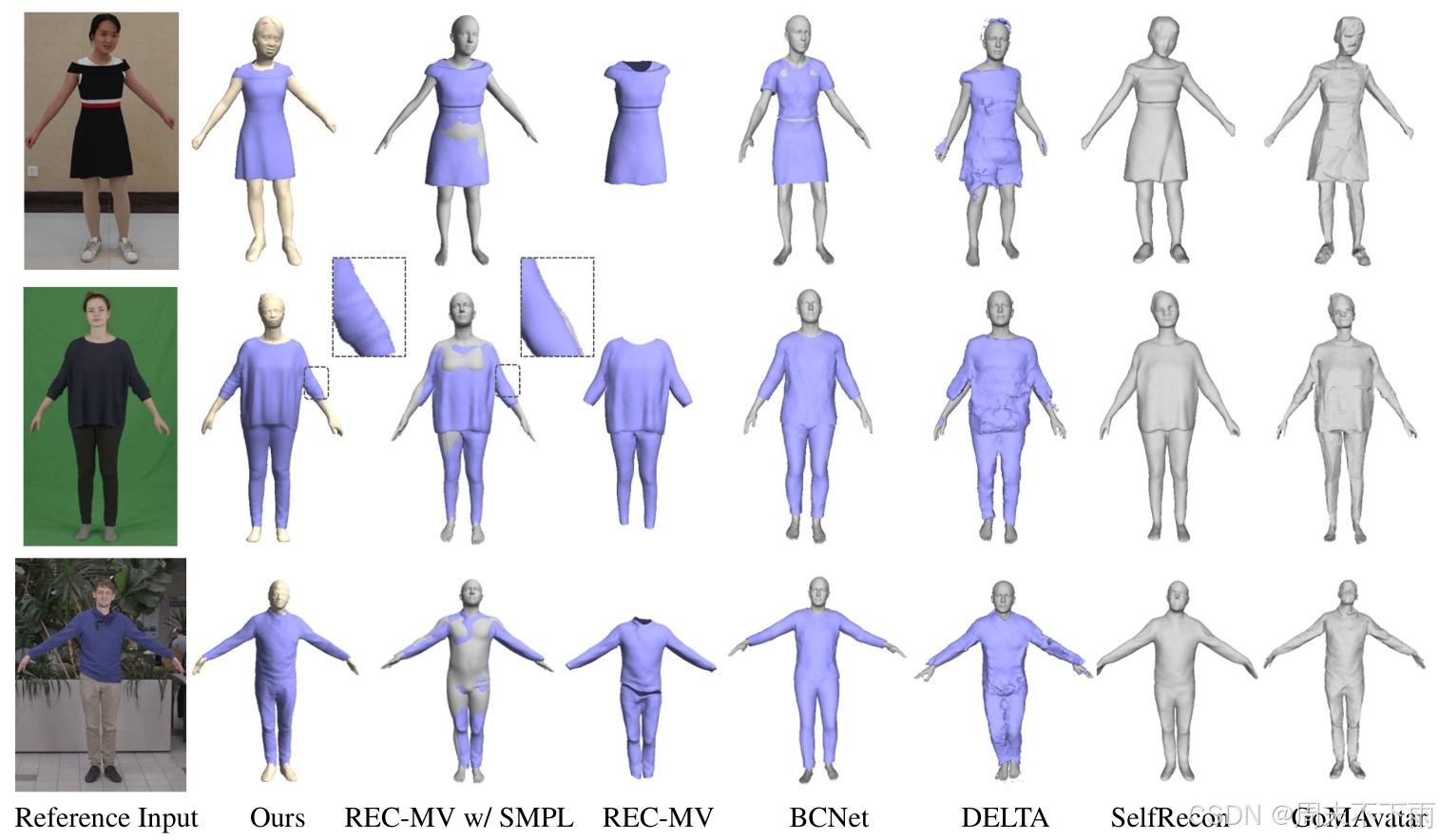
图8.定性比较。我们的方法与真实图像序列上的其他方法的比较。
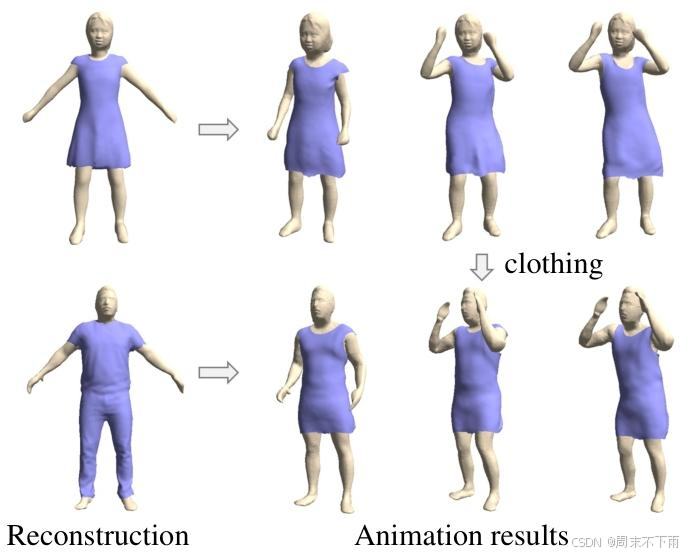
图9.解耦重建应用程序。重建的服装和身体可以使用物理模拟方法进行动画处理。此外,服装可以轻松交换以创建具有不同服装的动画。
感知法向损失。我们试图去除法向一致性损失,并用均方误差和角误差代替它。虽然法向一致性损失侧重于特征一致性,并可以产生感知一致的结果,但均方误差和角误差侧重于点向特征,这可能会导致不太平滑的结果。我们在图7中显示了正常渲染结果。计算渲染法线和参考法线之间的余弦或MSE损失会导致粗糙和嘈杂的重建。另一方面,使用感知法向损失会产生更平滑的结果,从而保留参考图像的特征和细节。
4.4 应用程序
我们演示了解耦重建后的服装转移和基于物理的动画的应用。结果如图9所示。
服装转移。由于我们的模型能够重新构建解耦的服装和人体,服装转移可以通过分别重建两个穿着衣服的人体并交换他们的服装来实现。
基于物理的动画。重建的服装和身体几何形状可以与基于物理的模拟方法一起使用,以创建更逼真的动画。与非解耦重建20相比,这使得服装和身体之间的运动难以建立,我们使用HOOD11来创建更真实的服装细节。
5 结论
我们引入了 D 3 D^{3} D3人,一种可以直接从短的单目视频中重建解耦的服装和身体的方法。通过利用显式表示的鲁棒性和隐式表示的灵活性, D 3 D^{3} D3人确保了详细特征的重建,同时保持了被服装遮挡的身体部位的合理性。为了实现3D服装与身体的分离,我们提出了一种定义在人体上的名为hmSDF的新颖表示,它能够仅使用2D人体解析获得3D分割,而没有任何3D服装先验。由于这种新颖的方法,我们能够以更少的计算时间实现具有竞争力的重建精度,同时确保了服装和身体的解耦。解耦的重建结果可以很容易地用于详细的动画制作和服装转移。我们的 D 3 D^{3} D3-人类只需使用一台相机即可创建高质量且易于编辑的人体几何图形,为广泛采用许多应用提供了技术基础,例如高度可编辑的数字头像创建、全息通信。
看下来就是做了一个单目视频的人体分割重建,对于不可见部分使用SMLP进行补全。对于定性定量,定性就是使用一堆模型的结果对比图,定量就是对参数性能的比较情况。
对于分割还是使用的是gshell那一套