YARN(Yet Another Resource Negotiator ,另一种资源协调者 )的基本架构,基于此来讲讲 Spark on YARN 的运行架构:
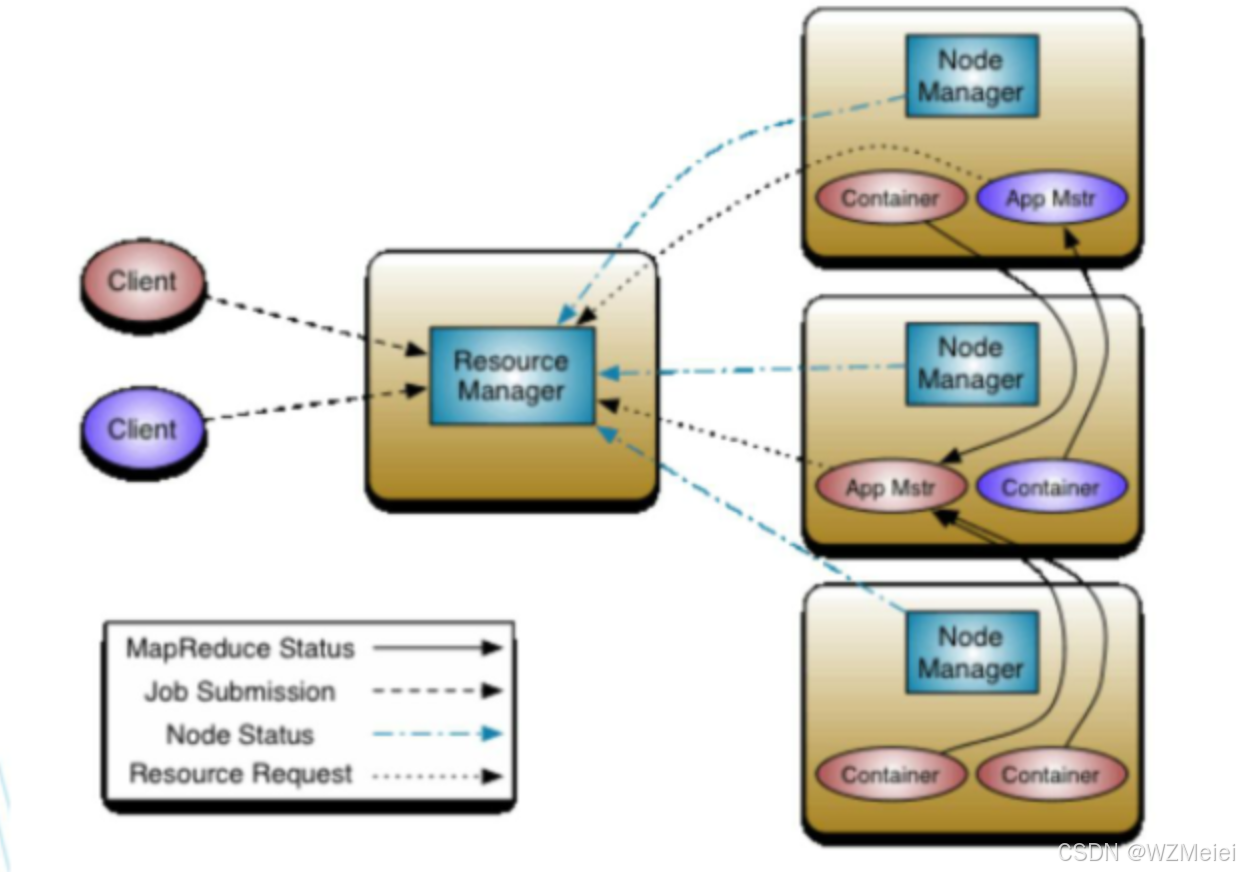
1. 总体架构
YARN 是 Hadoop 生态系统中负责集群资源管理和调度的组件。Spark on YARN 是将 Spark 应用程序运行在 YARN 资源管理框架之上,利用 YARN 来管理和分配资源,让 Spark 应用程序能更高效地在集群中运行。
2. 主要组件及其功能
- ResourceManager(资源管理器)
- 功能:YARN 的全局资源管理器,负责整个集群的资源管理和分配。它接收来自各个 NodeManager 的资源汇报,以及客户端提交的应用程序请求,并为应用程序分配资源。在 Spark on YARN 中,它为 Spark 应用程序分配运行所需的容器(Container)资源。
- 与其他组件交互:与 NodeManager 通信获取节点资源状态,与客户端交互接收应用提交请求,与 ApplicationMaster 协商资源分配。
- NodeManager(节点管理器)
- 功能:每个节点上的代理,负责管理本节点的资源(CPU、内存等)和容器生命周期。它接收 ResourceManager 的指令,启动、停止容器,监控容器资源使用情况,并向 ResourceManager 汇报节点状态和容器状态。在 Spark on YARN 中,它为 Spark 应用程序的执行分配和管理本地资源。
- 与其他组件交互:向 ResourceManager 汇报节点状态;根据 ResourceManager 指令管理容器;与 ApplicationMaster 协作执行容器相关操作。
- ApplicationMaster(应用程序主节点)
- 功能:每个应用程序在 YARN 中的实例,负责与 ResourceManager 协商资源,获取到资源后与 NodeManager 通信,启动和监控容器。对于 Spark 应用程序,它负责启动 Spark 的 Driver 程序,协调 Executor 容器的启动和资源分配,监控任务执行进度等。
- 与其他组件交互:向 ResourceManager 申请资源;与 NodeManager 交互启动和管理容器;与 Spark Driver 通信反馈任务执行状态。
- Container(容器)
- 功能:YARN 中资源的抽象,封装了一定量的资源(如 CPU、内存)。它是应用程序在节点上运行的环境,用于启动 ApplicationMaster 和 Executor 等进程。在 Spark on YARN 中,Executor 运行在 Container 中,负责执行具体的 Spark 任务。
- 与其他组件交互:由 NodeManager 创建和管理,根据 ApplicationMaster 的指令启动和停止,运行具体的应用程序代码。
3. 运行流程
-
客户端提交应用:用户通过 Spark 客户端提交 Spark 应用程序到 YARN 集群,提交请求发送给 ResourceManager。
-
ResourceManager 分配资源启动 ApplicationMaster:ResourceManager 收到请求后,为应用程序分配资源,在某个 NodeManager 上启动 ApplicationMaster 容器。
-
ApplicationMaster 申请资源:ApplicationMaster 启动后,向 ResourceManager 注册,并根据应用程序需求向 ResourceManager 申请更多资源(Container)。
-
NodeManager 启动容器:ResourceManager 根据资源情况分配 Container 给 ApplicationMaster,ApplicationMaster 与对应的 NodeManager 通信,让 NodeManager 启动包含 Spark Executor 的容器。
-
任务执行:Spark Driver 在 ApplicationMaster 中或单独的容器中运行,负责调度和监控任务,Executor 在各自容器中执行具体的 Spark 任务,完成数据处理。
-
任务完成:当所有任务执行完成,ApplicationMaster 向 ResourceManager 注销,释放资源,NodeManager 回收本地资源。