1 引言
数据库查询优化是指通过一系列技术和策略,调整查询策略、数据结构及资源配置,以最小化资源消耗并最大化执行效率的技术过程。其核心目标是通过选择最优执行计划,减少磁盘I/O、CPU计算和网络传输开销,从而提升查询速度与系统性能。
2 关系查询处理与优化
关系查询处理是将用户提交的关系查询语句,如 SQL 语句,转化为数据库能理解和执行的操作序列。这通常包括词法语法分析,检查语句是否符合规范;查询优化器进行逻辑优化,对查询语句进行等价变换,选择更高效的执行路径,比如将复杂的子查询转换为连接操作;之后进行物理优化,确定具体的访问方法,如全表扫描、索引扫描等,以及连接算法,如嵌套循环连接、哈希连接等。
优化方面,通过合理设计索引,可加速数据检索;优化查询语句,避免不必要的复杂操作和全表扫描;合理设计表结构,减少数据冗余和复杂连接;数据库管理员还能通过调整数据库参数,如内存分配等,来提升查询处理效率,确保数据库高效运行。
2.1 关系数据库系统的查询处理
关系数据库系统的查询处理是将用户提交的查询请求(通常为 SQL 语句)转化为数据库能够实际执行的操作序列,并最终返回查询结果的过程,主要包括以下几个关键阶段:
- 查询分析
- 核心任务:将用户提交的SQL语句转换为可识别的内部结构(如语法树)。
- 词法分析:分解SQL语句为基本单元(如关键字、表名、列名)。
- 语法分析:验证语句是否符合SQL语法规则,例如检查括号匹配、关键字顺序等。
- 输出:生成语法树或解析树,作为后续处理的基础。
- 查询检查
- 语义验证:确保查询的语义合法性,包括:
- 对象存在性:检查表、列是否在数据字典中存在。
- 权限验证:确认用户是否有操作权限(如SELECT、JOIN权限)。
- 视图转换:将对视图的操作转换为对底层基本表的操作。
- 完整性约束:初步检查是否符合外键、唯一性等约束。
- 查询优化
- 优化目标:选择代价最低的执行计划,减少I/O、CPU和内存消耗。
- 代数优化(逻辑优化):基于关系代数规则重构查询逻辑,例如:
- 选择下推:尽早过滤无关数据。
- 投影合并:减少中间结果的数据量。
- 物理优化:结合数据分布和存储结构选择执行策略,例如:
- 索引选择:根据索引基数和选择性选择B+树或哈希索引。
- 连接策略:根据表大小选择嵌套循环(小表驱动)、哈希连接或排序合并。
- 代价估算:通过统计信息(如行数、索引选择性)评估不同计划的I/O和CPU成本。
- 查询执行
- 执行计划生成:优化器生成包含数据访问顺序、算法选择的具体指令。
- 数据访问算法:
- 全表扫描:适用于小表或无索引场景。
- 索引扫描:利用B+树等索引快速定位数据。
- 连接与聚合:
- 哈希连接:适合大表且内存充足的情况。
- 排序-合并:适用于已排序数据的高效连接。
- 聚合运算:通过GROUP BY和聚合函数(如SUM、COUNT)汇总数据。
- 结果返回:执行引擎逐行或批量返回结果,并释放临时资源(如内存缓存)。
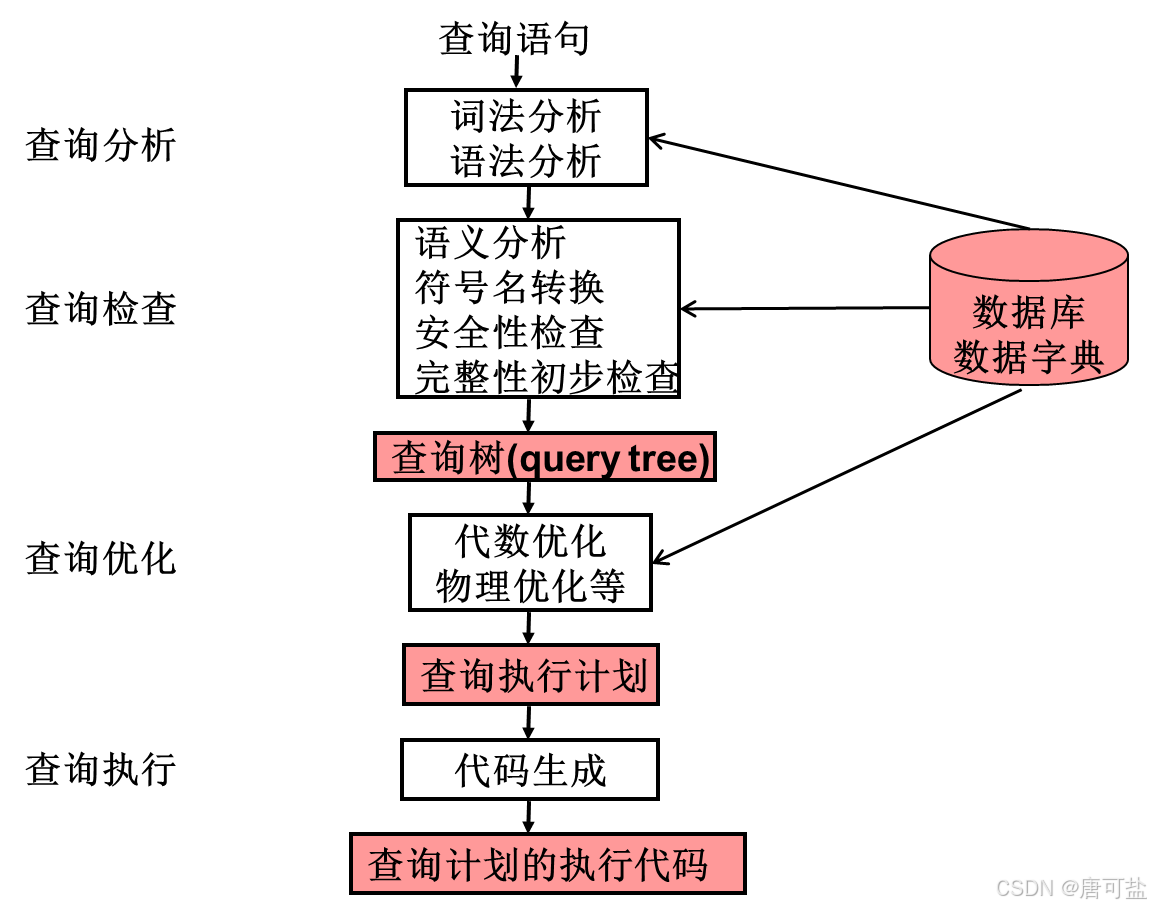
处理过程示意图
2.2 查询处理步骤
关系数据库系统的查询处理步骤主要包括以下五个关键阶段,各阶段协同工作以高效完成查询任务:
1. 查询分析
- 词法分析 :将用户输入的 SQL 语句分解为一个个有意义的单词或符号(词法单元)。例如,对于 SQL 语句
SELECT name FROM students WHERE age > 20;,会将其分解为SELECT、name、FROM、students、WHERE、age、>、20、;等词法单元。 - 语法分析:依据数据库系统定义的语法规则,检查分解后的词法单元是否构成合法的 SQL 语句结构。就像检查一个句子是否符合语法规则一样,确保语句的语法正确性。如果语法错误,会向用户返回相应的错误提示信息。
- 语义检查:进一步检查 SQL 语句的语义是否正确。例如,检查语句中引用的表名、列名是否存在,用户是否有访问这些表和列的权限等。
2. 查询检查
- 视图消解:如果查询中涉及视图,需要将视图定义中的查询语句与当前查询语句进行合并,转化为对基本表的查询。视图是一个虚拟表,其数据来源于基本表,视图消解的目的是将查询操作最终落实到基本表上。
- 安全性检查:确保用户只能访问其有权限的数据。数据库系统会根据用户的权限设置,对查询进行过滤,防止用户访问未经授权的数据。
3. 查询优化
- 逻辑优化:对查询语句进行等价变换,生成更高效的查询执行计划。例如,将复杂的子查询转换为连接操作,或者对查询条件进行合并、简化等。通过逻辑优化,可以减少查询过程中的计算量和数据访问量,提高查询效率。
- 物理优化:选择合适的物理操作算法和访问路径。这包括确定使用全表扫描、索引扫描还是其他扫描方式来获取数据,以及选择合适的连接算法(如嵌套循环连接、哈希连接、排序合并连接等)来处理表之间的连接操作。物理优化会根据数据库的统计信息(如表的大小、索引的分布情况等)来选择最优的执行方案。
4. 查询执行计划的生成
- 基于优化结果:根据查询优化阶段确定的逻辑和物理执行策略,生成具体的查询执行计划。执行计划详细描述了查询操作的步骤、顺序以及使用的算法和访问路径等信息,就像一份详细的施工图纸,指导数据库系统如何执行查询操作。
- 多种执行计划评估:在某些情况下,可能存在多种可行的执行计划,数据库系统会对这些执行计划进行评估和比较,选择预计执行成本最低的执行计划。
5. 查询执行
- 代码生成:根据生成的查询执行计划,数据库系统会生成可执行的代码或指令序列。这些代码或指令可以直接在数据库系统的执行引擎上运行。
- 执行引擎执行:执行引擎按照生成的代码或指令序列,从数据库中读取数据,进行相应的计算和处理。在执行过程中,执行引擎会按照执行计划中规定的步骤和算法,依次完成数据扫描、连接、过滤、排序等操作,最终将查询结果返回给用户。
2.3 实现查询操作示例
假设我们有一个名为"学生信息管理系统"的关系型数据库,其中包含一个名为"students"的表,该表存储了学生的基本信息,如学号(student_id)、姓名(name)、年龄(age)和所在班级(class)。现在,我们需要查询年龄大于20岁的学生姓名及其所在班级。
2.3.1 查询操作示例
1. 查询分析
- SQL语句 :
SELECT name, class FROM students WHERE age > 20; - 词法分析 :将SQL语句分解为词法单元:
SELECT、name、,、class、FROM、students、WHERE、age、>、20、;。 - 语法分析:检查这些词法单元是否构成合法的SQL查询语句结构。
- 语义检查:确认"students"表存在,且"name"、"class"和"age"是该表的有效列名。
2. 查询检查
- 视图消解:本示例不涉及视图,因此无需进行视图消解。
- 安全性检查:确认当前用户有权限查询"students"表的"name"、"class"和"age"列。
3. 查询优化
- 逻辑优化:假设"students"表在"age"列上有索引,优化器可能会选择使用索引扫描来快速定位年龄大于20岁的学生记录。
- 物理优化:根据表的统计信息,优化器决定使用索引扫描来访问"students"表,并通过简单的过滤操作来获取符合条件的记录。
4. 查询执行计划的生成
- 执行计划:使用索引扫描来访问"students"表,过滤出"age > 20"的记录,然后投影出"name"和"class"列。
5. 查询执行
- 代码生成:生成执行索引扫描和过滤操作的代码。
- 执行引擎执行:执行引擎按照执行计划,从"students"表中读取数据,使用索引快速定位年龄大于20岁的学生,然后返回这些学生的姓名和所在班级。
2.3.2 查询结果示例
假设"students"表中有以下数据:
| student_id | name | age | class |
|---|---|---|---|
| 1 | 张三 | 21 | 一班 |
| 2 | 李四 | 19 | 二班 |
| 3 | 王五 | 22 | 一班 |
执行查询后,返回的结果为:
| name | class |
|---|---|
| 张三 | 一班 |
| 王五 | 一班 |
说明:
- 目的:该查询的目的是找出年龄大于20岁的学生,并显示他们的姓名和所在班级。
- 优化效果:通过使用索引扫描,查询效率得到了提升,尤其是在"students"表数据量较大的情况下,索引可以显著减少需要扫描的数据量。
- 结果理解:返回的结果列表中,只有年龄大于20岁的学生(张三和王五)被列出,显示了他们的姓名和班级信息。
3 关系数据库系统的查询优化
3.1 查询优化概述
3.1.1 查询优化的重要性
- 提升性能:在大数据量场景下,未经优化的查询可能导致系统响应缓慢,甚至出现超时或崩溃。优化查询能显著减少查询执行时间,提高数据库的吞吐量,使系统能更高效地处理并发请求。
- 节约资源:优化后的查询可以减少数据库服务器的CPU、内存和I/O资源消耗,降低硬件成本,同时延长硬件设备的使用寿命。
- 改善用户体验:快速的查询响应能为用户提供更好的使用体验,特别是在需要实时数据的业务场景中,如在线交易、实时监控等。
3.1.2 查询优化的方法
- 逻辑优化
- 等价变换 :对查询语句进行逻辑等价转换,生成更高效的执行计划。例如,将复杂的子查询转换为连接操作,或者对查询条件进行合并、简化。
- 谓词下推:尽可能将过滤条件下推到靠近数据源的位置,减少中间结果集的大小。比如, 在多表连接查询中,先对单个表进行过滤,再进行连接操作。
- 等价变换 :对查询语句进行逻辑等价转换,生成更高效的执行计划。例如,将复杂的子查询转换为连接操作,或者对查询条件进行合并、简化。
- 物理优化
- 索引优化:合理创建和使用索引是提高查询性能的关键。为经常用于查询条件的列创建索引,可以加速数据检索。但索引也会增加写操作的开销,因此需要权衡索引的创建和维护成本。
- 选择合适的访问路径:根据表的统计信息,选择全表扫描、索引扫描或索引范围扫描等合适的访问方式。例如,对于小表,全表扫描可能更高效;对于大表,索引扫描通常是更好的选择。
- 连接算法选择:常见的连接算法有嵌套循环连接、哈希连接和排序合并连接。根据表的大小、连接条件和索引情况,选择最优的连接算法。
3.1.3 查询优化的实施步骤
- 收集统计信息:数据库系统需要收集表的行数、列的基数、索引的分布等统计信息,以便优化器能够准确评估不同执行计划的成本。
- 生成执行计划:优化器根据查询语句和统计信息,生成多个可能的执行计划。
- 评估执行计划:优化器使用成本模型对每个执行计划进行评估,选择预计执行成本最低的执行计划。
- 执行查询:按照选定的执行计划执行查询,并返回结果。
- 监控和调整:定期监控查询性能,分析查询日志,发现性能瓶颈。根据监控结果,对查询语句、索引或数据库配置进行调整和优化。
3.1.4 查询优化可能的影响
- 积极影响
- 性能提升:显著提高查询执行速度,减少系统响应时间,提高用户满意度。
- 资源利用率提高:降低数据库服务器的资源消耗,使系统能够处理更多的并发请求。
- 消极影响
- 过度优化:如果优化过度,可能会导致执行计划过于复杂,增加优化器的负担,反而降低查询性能。
- 索引维护成本:创建过多的索引会增加写操作的开销,影响数据库的写入性能,同时也会占用更多的存储空间。
- 兼容性问题:某些优化方法可能会影响查询的语义或与其他应用程序的兼容性,需要在优化前进行充分的测试。
关系数据库系统的查询优化是一个复杂而重要的过程,需要综合考虑查询语句、数据库结构、统计信息和系统资源等多个因素,以达到最佳的性能和资源利用效果。
3.2 查询优化实例
场景描述:学生信息管理系统包含学生基本信息、课程信息、成绩记录等核心数据。以下是优化后的数据库表结构设计,重点考虑查询性能优化。
数据库设计表示例:
sql
-- 学生基本信息表(主表)
CREATE TABLE students (
student_id VARCHAR(12) PRIMARY KEY, -- 学号,主键
name VARCHAR(50) NOT NULL,
gender CHAR(1) CHECK (gender IN ('M', 'F')),
birth_date DATE,
class_id VARCHAR(10) NOT NULL, -- 班级ID
admission_date DATE NOT NULL,
status VARCHAR(10) DEFAULT 'active' CHECK (status IN ('active', 'graduated', 'suspended')),
INDEX idx_class_id (class_id), -- 班级ID索引
INDEX idx_status (status) -- 状态索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 班级信息表
CREATE TABLE classes (
class_id VARCHAR(10) PRIMARY KEY,
class_name VARCHAR(50) NOT NULL,
department VARCHAR(50) NOT NULL,
grade YEAR NOT NULL,
advisor_id VARCHAR(12), -- 班主任学号
INDEX idx_department_grade (department, grade) -- 复合索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 课程信息表
CREATE TABLE courses (
course_id VARCHAR(8) PRIMARY KEY,
course_name VARCHAR(100) NOT NULL,
credit TINYINT UNSIGNED NOT NULL CHECK (credit BETWEEN 1 AND 5),
department VARCHAR(50) NOT NULL,
INDEX idx_department (department) -- 按学院查询课程的索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 成绩记录表(高频查询表)
CREATE TABLE scores (
id INT AUTO_INCREMENT PRIMARY KEY,
student_id VARCHAR(12) NOT NULL,
course_id VARCHAR(8) NOT NULL,
semester VARCHAR(10) NOT NULL, -- 学期,格式:2023-春
score DECIMAL(5,2) CHECK (score BETWEEN 0 AND 100),
gpa_value DECIMAL(3,2) CHECK (gpa_value BETWEEN 0 AND 4.0),
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (course_id) REFERENCES courses(course_id),
INDEX idx_student_course (student_id, course_id), -- 学生查成绩复合索引
INDEX idx_course_semester (course_id, semester), -- 课程按学期查询索引
INDEX idx_student_semester (student_id, semester) -- 学生按学期查成绩索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;3.2.1 查询优化实例
实例1:查询某班级所有学生信息(带分页)
原始查询:
sql
SELECT * FROM students WHERE class_id = 'CS2023-1';优化后查询:
sql
-- 使用覆盖索引,避免回表
SELECT student_id, name, gender, birth_date, status
FROM students
WHERE class_id = 'CS2023-1'
ORDER BY student_id
LIMIT 20 OFFSET 0;优化说明:
- 利用
idx_class_id索引快速定位班级学生 - 只选择必要字段,避免
SELECT * - 添加分页支持,避免大数据量返回
- 按student_id排序利用了主键索引的有序性
实例2:查询学生某学期成绩(高频查询)
原始查询:
sql
SELECT c.course_name, s.score, s.gpa_value
FROM scores s
JOIN courses c ON s.course_id = c.course_id
WHERE s.student_id = '20230001' AND s.semester = '2023-春';优化后查询:
sql
-- 使用复合索引idx_student_semester
EXPLAIN
SELECT c.course_name, s.score, s.gpa_value
FROM scores s FORCE INDEX (idx_student_semester)
JOIN courses c ON s.course_id = c.course_id
WHERE s.student_id = '20230001' AND s.semester = '2023-春';优化说明:
- 使用
idx_student_semester复合索引快速定位记录 - 使用
FORCE INDEX提示优化器选择最佳索引 EXPLAIN分析执行计划,确保索引生效
实例3:统计各学院平均GPA(大数据量统计)
原始查询:
sql
SELECT c.department, AVG(s.gpa_value) as avg_gpa
FROM scores s
JOIN students stu ON s.student_id = stu.student_id
JOIN courses c ON s.course_id = c.course_id
WHERE stu.status = 'active'
GROUP BY c.department;优化后查询:
sql
-- 创建物化视图(MySQL 8.0+可使用CTE或定期汇总表)
CREATE TABLE department_gpa_stats (
department VARCHAR(50) PRIMARY KEY,
avg_gpa DECIMAL(3,2),
student_count INT,
last_updated TIMESTAMP
);
-- 定期更新汇总表(可由定时任务执行)
INSERT INTO department_gpa_stats (department, avg_gpa, student_count, last_updated)
SELECT c.department, AVG(s.gpa_value), COUNT(DISTINCT s.student_id), NOW()
FROM scores s
JOIN students stu ON s.student_id = stu.student_id
JOIN courses c ON s.course_id = c.course_id
WHERE stu.status = 'active'
GROUP BY c.department
ON DUPLICATE KEY UPDATE
avg_gpa = VALUES(avg_gpa),
student_count = VALUES(student_count),
last_updated = VALUES(last_updated);
-- 查询时直接使用汇总表
SELECT department, avg_gpa
FROM department_gpa_stats
ORDER BY avg_gpa DESC;优化说明:
- 对大数据量统计创建定期更新的汇总表
- 避免实时JOIN和GROUP BY的高开销操作
- 汇总表可按需添加更多统计维度(如按年级、学期等)
实例4:查询学生未通过的课程(使用索引提示)
优化查询:
sql
-- 使用索引合并提示
SELECT /*+ INDEX_MERGE(s idx_student_course, idx_student_semester) */
s.student_id, c.course_name, s.semester
FROM scores s
JOIN courses c ON s.course_id = c.course_id
WHERE s.student_id = '20230001'
AND (s.score < 60 OR s.score IS NULL)
ORDER BY s.semester DESC;优化说明:
- 使用索引合并提示优化OR条件查询
- 按学期降序排列,最近学期优先显示
- 考虑添加"是否通过"计算列并建立索引
3.2.2 数据库配置优化
sql
-- 1. 调整InnoDB缓冲池大小(通常设为可用内存的50-70%)
SET GLOBAL innodb_buffer_pool_size = 4G;
-- 2. 优化排序缓冲区大小
SET GLOBAL sort_buffer_size = 4M;
SET GLOBAL read_rnd_buffer_size = 2M;
-- 3. 启用查询缓存(MySQL 8.0已移除,可在应用层实现)
-- SET GLOBAL query_cache_size = 64M;
-- SET GLOBAL query_cache_type = ON;
-- 4. 定期分析表以更新统计信息
ANALYZE TABLE students, classes, courses, scores;3.2.3 实际应用建议
- 索引策略:
- 对高频查询条件字段建立索引
- 对JOIN操作的关联字段建立索引
- 避免过度索引,定期审查索引使用情况
- 查询规范:
- 禁止使用SELECT *,明确指定所需字段
- 大数据量查询必须分页
- 复杂查询拆分为多个简单查询
- 监控与维护:
- 使用slow_query_log记录慢查询
- 定期使用EXPLAIN分析关键查询
- 对历史数据实施归档策略
- 应用层优化:
- 实现二级缓存(如Redis)缓存热点数据
- 对复杂统计使用预计算或物化视图
- 考虑读写分离架构
4、物理优化
物理优化聚焦于确定数据库中数据的存取路径与操作执行方式,以提升查询性能,核心在于基于启发式规则和代价优化来选择最优方案。
4.1 基于启发式规则的存取路径选择优化
启发式规则基于经验和实践总结,能快速筛选出可能高效的存取路径,虽不一定最优,但可大幅减少优化过程的计算量。以下为常见规则及存取路径选择示例:
- 全表扫描与索引扫描选择
- 规则:当查询条件涉及的列没有索引,或查询返回的数据量超过表中数据总量的 20% - 30%(具体比例因数据库系统而异)时,全表扫描可能更高效。因为此时使用索引需要多次 I/O 操作来获取数据,而全表扫描只需一次顺序读取。
- 示例:在一张有 1000 条记录的学生表中,要查询所有年龄大于 18 岁的学生。若年龄列没有索引,且预计符合条件的记录有 300 条,超过了 20% - 30% 的比例,那么数据库系统会选择全表扫描,直接顺序读取表中的所有记录,判断年龄是否大于 18 岁。
- 索引顺序扫描与索引范围扫描选择
- 规则 :如果查询条件是一个范围条件,如
>、<、BETWEEN等,且该列有索引,通常选择索引范围扫描。索引顺序扫描适用于等值查询,且查询结果在索引中是连续分布的情况。 - 示例:在学生表中,年龄列有索引。若查询年龄在 20 到 25 岁之间的学生,数据库系统会选择索引范围扫描,从索引中找到年龄为 20 的记录位置,然后依次扫描到年龄为 25 的记录位置,获取对应的主键值,再通过主键值到表中获取完整的学生信息。
- 规则 :如果查询条件是一个范围条件,如
- 连接操作存取路径选择
- 嵌套循环连接:适用于一个表较小,另一个表较大的情况。将小表作为外层循环,大表作为内层循环,对于外层表的每一行,在内层表中查找匹配的行。
- 哈希连接:当两个表都比较大,且连接条件上的数据分布比较均匀时,哈希连接是较好的选择。先将一个表构建成哈希表,然后用另一个表的连接列去哈希表中查找匹配的行。
- 排序合并连接:如果两个表都已经按照连接列排序,或者排序的代价较小,排序合并连接效率较高。先对两个表按照连接列进行排序,然后依次比较两个表的记录,找出匹配的行。
4.2 基于代价优化的物理优化
代价优化通过计算不同存取路径和操作执行方式的代价,选择代价最小的方案,从而提升数据库系统性能。代价通常用 I/O 操作次数、CPU 计算时间等指标来衡量。
- 代价估算方法
- I/O 代价估算:对于全表扫描,I/O 代价等于表所占的页数;对于索引扫描,I/O 代价等于索引所占的页数加上通过索引访问表数据所需的页数。
- CPU 代价估算:CPU 代价主要与数据的比较、计算等操作相关。例如,在查询条件中进行等值比较、范围比较等操作,都会产生一定的 CPU 代价。
- 降低运行代价的策略
- 选择合适的索引:为常用查询条件涉及的列创建索引,可以减少 I/O 操作次数。例如,在学生表中,为姓名、学号等常用查询字段创建索引,当查询特定学生信息时,数据库系统可以通过索引快速定位到对应的记录,避免了全表扫描。
- 优化连接顺序:在多表连接查询中,不同的连接顺序会导致不同的代价。通过计算不同连接顺序的代价,选择代价最小的连接顺序。例如,有三个表 A、B、C 进行连接,可以先连接表 A 和表 B,得到中间结果后再与表 C 连接,如果这种顺序的代价最小,就选择该顺序执行。
- 利用缓存:数据库系统通常有缓存机制,将经常访问的数据和索引页存储在缓存中。当再次访问这些数据时,可以直接从缓存中获取,避免了 I/O 操作,降低了代价。例如,频繁查询的学生信息可能会被缓存到内存中,后续查询时可以直接从内存读取。