Q1: Redis为什么这么快?
Redis速度快主要有四个核心原因。首先是基于内存操作,所有数据都存储在内存中,避免了磁盘I/O的开销,内存读写速度比磁盘快几万倍。其次采用单线程模型,避免了多线程环境下的线程切换和锁竞争带来的性能损耗。再者是优秀的底层数据结构设计,比如哈希表、跳跃表等高效数据结构,保证了各种操作的时间复杂度。最后是采用多路复用I/O模型,通过epoll等机制同时处理多个客户端连接,在等待某个连接的同时可以处理其他连接的请求,大大提升了整体吞吐量。
Q2: Redis都有哪些数据类型,分别适用什么场景?
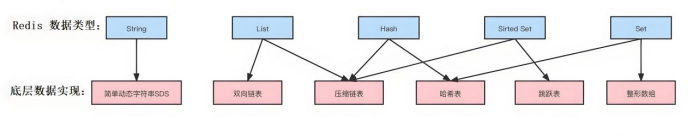
Redis有五种基本数据类型。String字符串是最基础的类型,适用于缓存用户信息、session存储,还可以存储数字进行计数器操作。List列表是有序可重复的,常用来实现消息队列和存储时间线数据。Hash哈希结构特别适合存储对象信息,比如用户详情、商品信息,还有购物车场景,可以用用户ID作为key,商品ID和数量作为field-value。Set集合保证元素唯一性和无序性,适合去重和实现点赞、关注等功能。Sorted Set有序集合在Set基础上增加了score排序功能,是实现排行榜、热门推荐的最佳选择。
Q3: Sorted Set的底层是怎么实现的?
Sorted Set的底层实现会根据数据量动态选择不同的数据结构。

当数据量较小时,具体是元素个数小于128个且所有元素长度都小于64字节时,会使用压缩列表ziplist存储,这种方式内存占用小,遍历效率高。
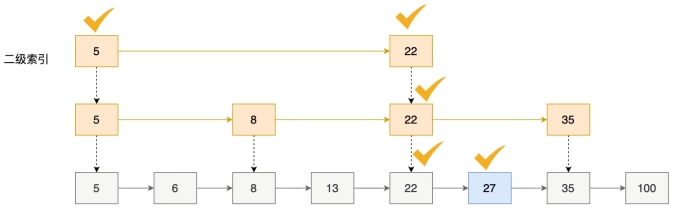
当超过这个阈值时,就会转换为跳跃表skiplist实现。跳跃表是一种概率型数据结构,通过多层索引实现快速查找,平均时间复杂度是O(log n),最坏情况是O(n)。每个节点维护指向不同层级的指针,查找时从最高层开始,逐层下降,这样既保证了查找效率,又支持范围查询操作。
Q4: 为什么Redis不用B+树而用跳表?
这个问题其实是Redis和MySQL设计理念的差异体现。MySQL使用B+树是因为数据存储在磁盘上,需要考虑磁盘I/O的成本,B+树的设计让叶子节点存储数据,非叶子节点存储索引,每次读取一个磁盘页就能获取一个节点的所有数据,并且叶子节点之间有指针连接,这样能最大限度减少磁盘I/O次数。而Redis的数据完全在内存中,不涉及磁盘I/O,内存访问速度是磁盘的百万倍,这种情况下跳表就更有优势了。跳表的实现比B+树简单很多,而且在内存环境下性能更好,维护成本也更低,所以Redis选择了跳表。
Q5: Redis可以用来做什么?
Redis的应用场景非常广泛。最常见的是作为缓存,将热点数据存储在内存中,减少对后端数据库的访问压力,大幅提升系统性能。还可以作为消息队列使用,利用List的push和pop操作实现简单队列,或者使用发布订阅功能实现更复杂的消息传递,实现系统解耦和异步处理。在分布式系统中,Redis还能实现分布式锁,使用SETNX命令可以保证同一时间只有一个进程获取锁,避免并发修改导致的数据不一致,不过生产环境建议使用Redisson等成熟框架实现可重入锁。另外Redis在计数器、排行榜、分布式会话管理等场景都有很好的应用,比如我之前项目中就用Redis存储AI对话的会话信息,用会话ID作为key,对话内容以JSON格式存储。
Q6: Redis的持久化机制有哪些?
Redis提供了三种持久化方案。RDB快照是将某个时间点的内存数据完整保存到磁盘,文件紧凑,恢复速度快,但可能会丢失最后一次快照后的数据。AOF日志是记录每个写操作命令,数据丢失风险小,文件可读性好,但文件相对较大,恢复速度较慢。Redis 4.0后推出了混合持久化方案,这是目前推荐的方式,它结合了RDB和AOF的优点,在AOF重写时,会把重写那一刻之前的内存以RDB格式写入AOF文件开头,后续的增量数据以AOF格式追加,这样既保证了快速启动,又最大程度减少了数据丢失风险。不过这种方案也有缺点,就是实现复杂度高,需要维护两种格式,AOF文件的可读性也会下降。
Q7: Redis集群了解吗?
Redis提供了三种集群方案。主从复制是最基础的,一个主节点负责写操作,多个从节点负责读操作,通过数据同步保证一致性,主要解决读压力问题。哨兵模式在主从基础上增加了高可用性,哨兵节点监控主从状态,当主节点故障时自动进行故障转移,选举新的主节点。Redis Cluster是官方的分布式解决方案,支持数据自动分片,通过一致性哈希将数据分散到不同节点,每个节点既可以是主节点也可以是从节点,支持横向扩展和故障自动转移,是大规模分布式场景的首选方案。
Q8: 缓存常见问题怎么解决?
缓存使用中主要有三个经典问题。缓存穿透是指请求的数据既不在缓存也不在数据库中,每次请求都会穿透到数据库,解决方案是缓存空值或使用布隆过滤器。缓存击穿是指热点数据过期的瞬间大量请求直接打到数据库,可以通过设置热点数据永不过期或使用互斥锁重建缓存来解决。缓存雪崩是指大量缓存同时过期,解决方案包括设置随机过期时间、使用多级缓存、限流降级等。
另外还有缓存一致性问题,可以通过延时双删、消息队列异步更新等方式来保证缓存和数据库的数据一致性。