文章目录
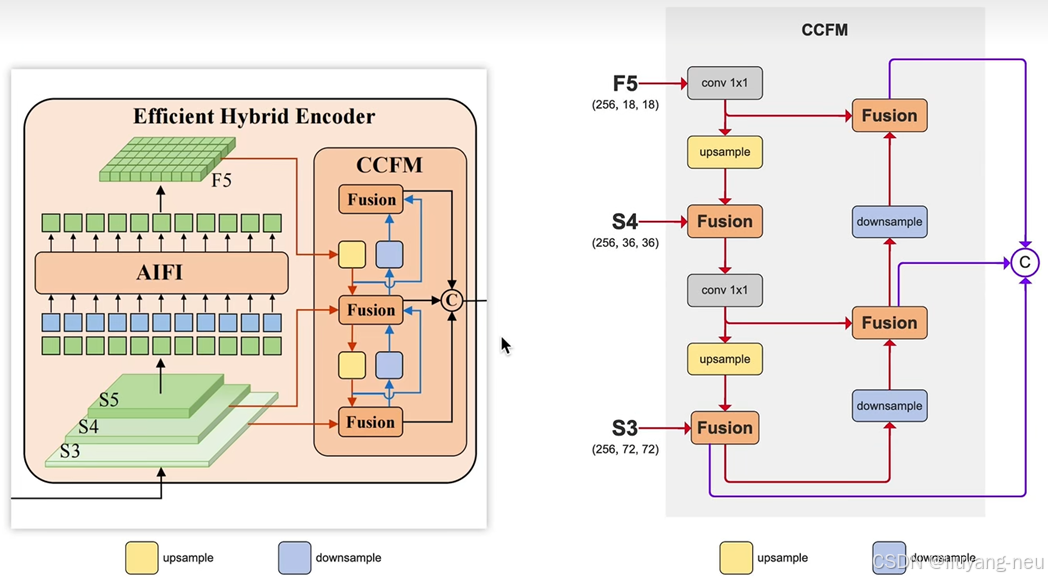
将DETR扩展到实时场景,提高了模型的检测速度。网络架构分为三部分组成:主干网络、混合编码器、带有辅助预测头的变换器编码器。具体来说,先利用主干网络的最后三个阶段的输出特征 {S3, S4,S5} 作为编码器的输入。混合编码器通过内尺度交互(intra-scaleinteraction)和跨尺度融合(cross-scale fusion)将多尺度特征转换成一系列图像特征。随后,采用loU感知查询选择(loU-aware query selection)从编码器输出序列中选择一定数量的图像特征,作为解码器的输入(初始对象查询)。最后,带有辅助预测头的解码器迭代优化对象查询,以生成类别和方框。解码器采用的是DINO的解码器结构,由6层dcoder layer组成,每层decoder layer包含self-attention和cross attention两部分。
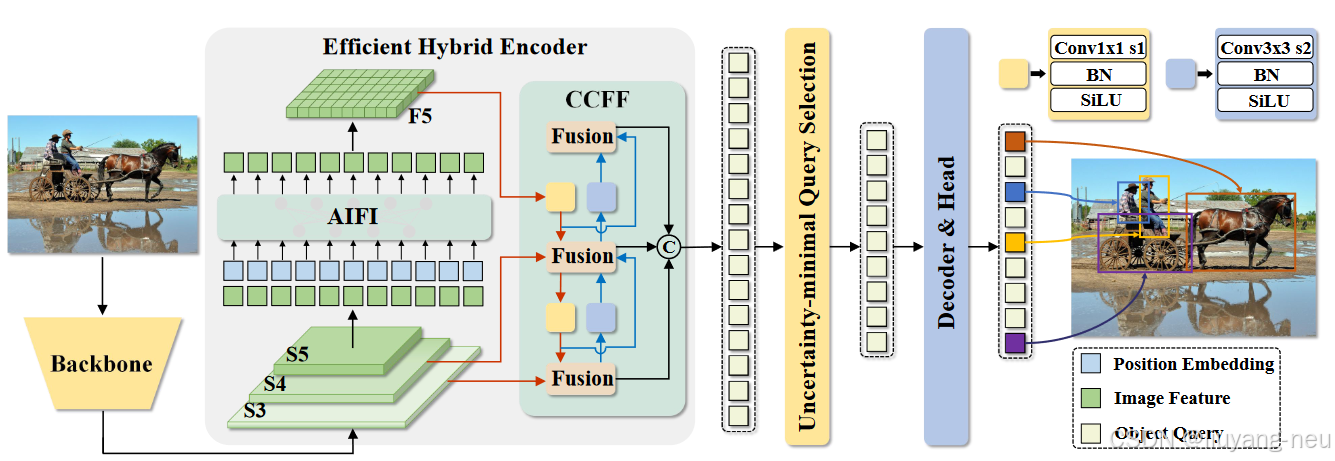
主干网络:
对于主干网络,RT-DETR采用CNN网络,如流行的ResNet系列,或者百度自家研发的HGNet。当然也可以采用如Vit系列的主干网络,虽然精度可能更高,但是速度不行CNN架构无疑是快于ViT架构的。因此,从实时性的角度出发,选择CNN架构来做特征提取还是有助于提高DETR系列的实时性,进而提升实用性------毫无疑问,这是阶段性的措施,不难想象,未来一定会有新架构全面------不论是性能还是推理速度------取代CNN架构。
和以往的检测器一样,RT-DETR也是从主干网络中抽取三个尺度的输出,其输出步长分别为8、16和32(输出步长output stride通常指的是网络中特征图的空间尺寸相对于输入图像的缩小比例)
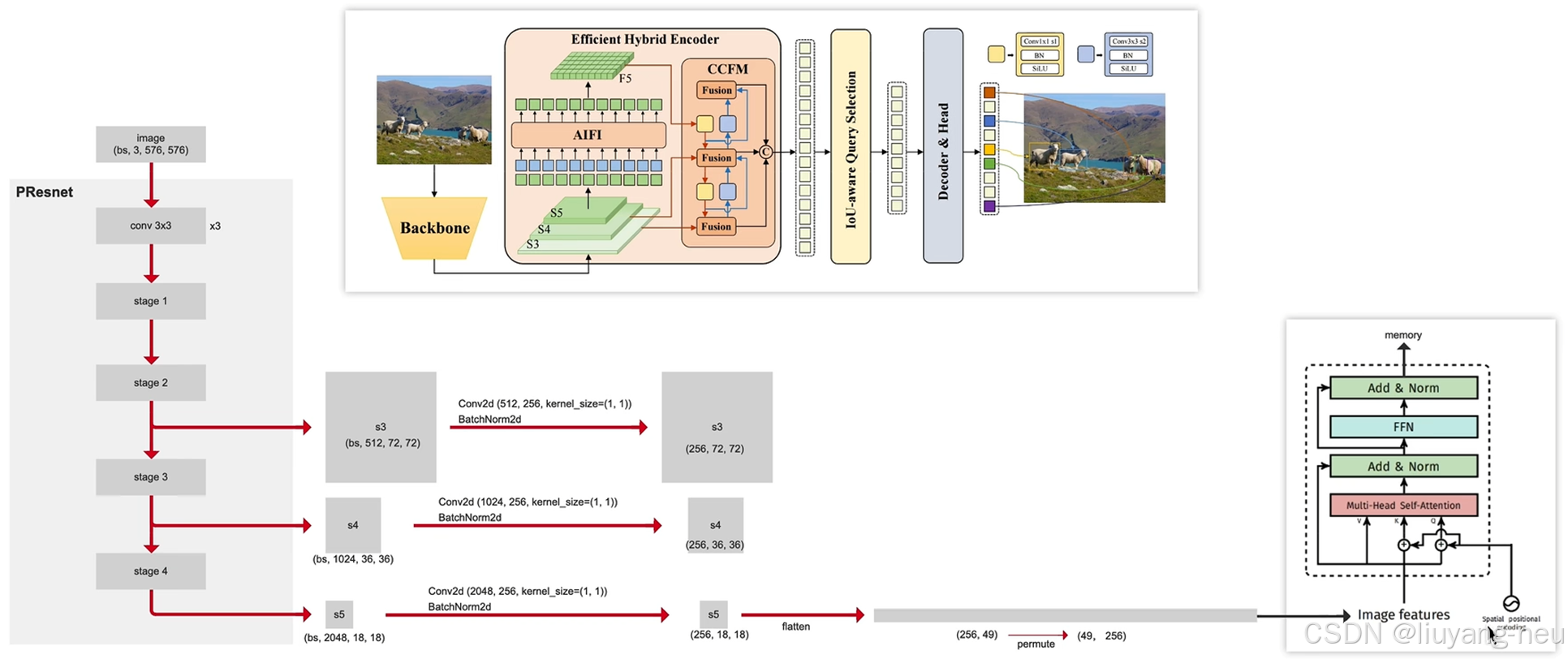
Encoder:
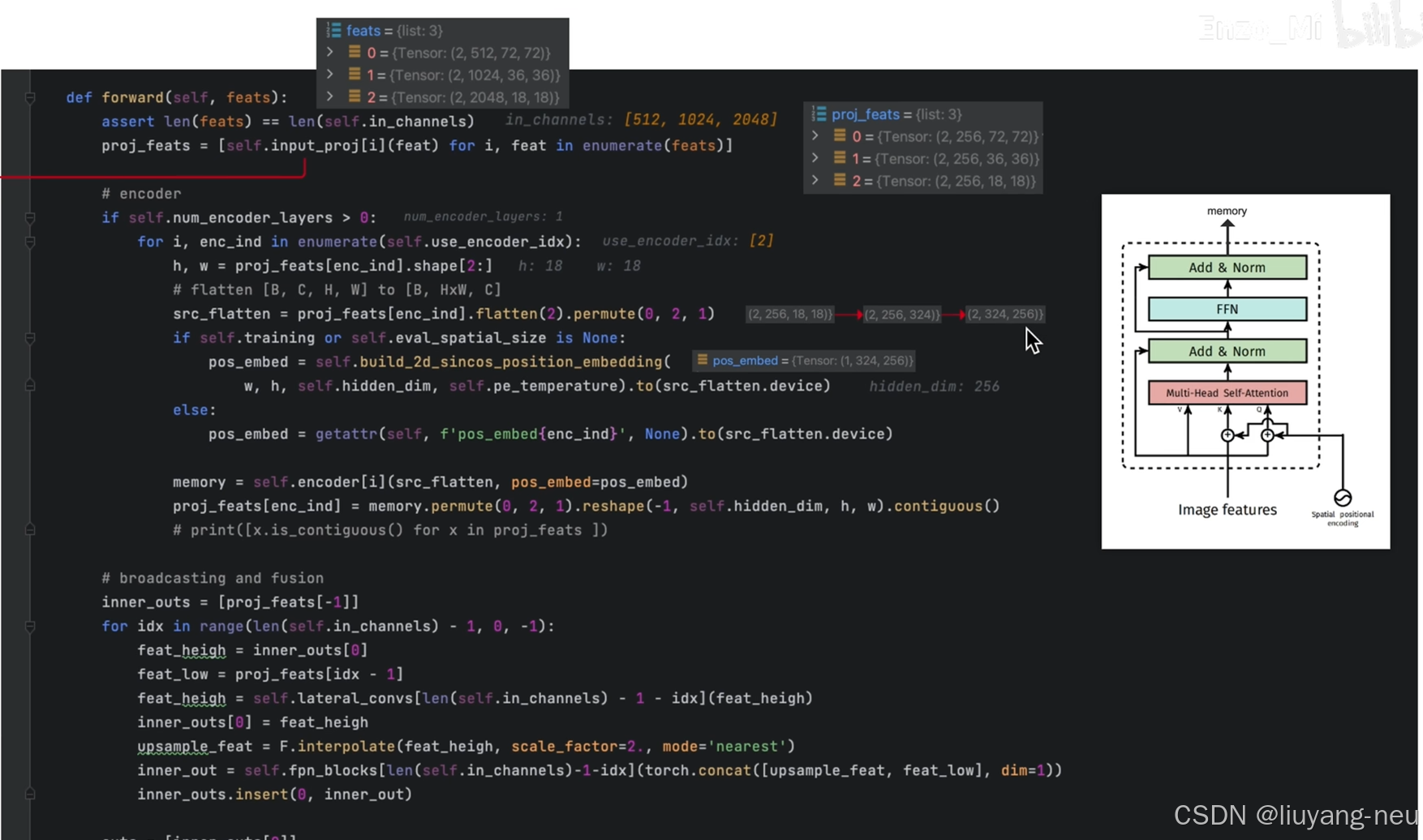
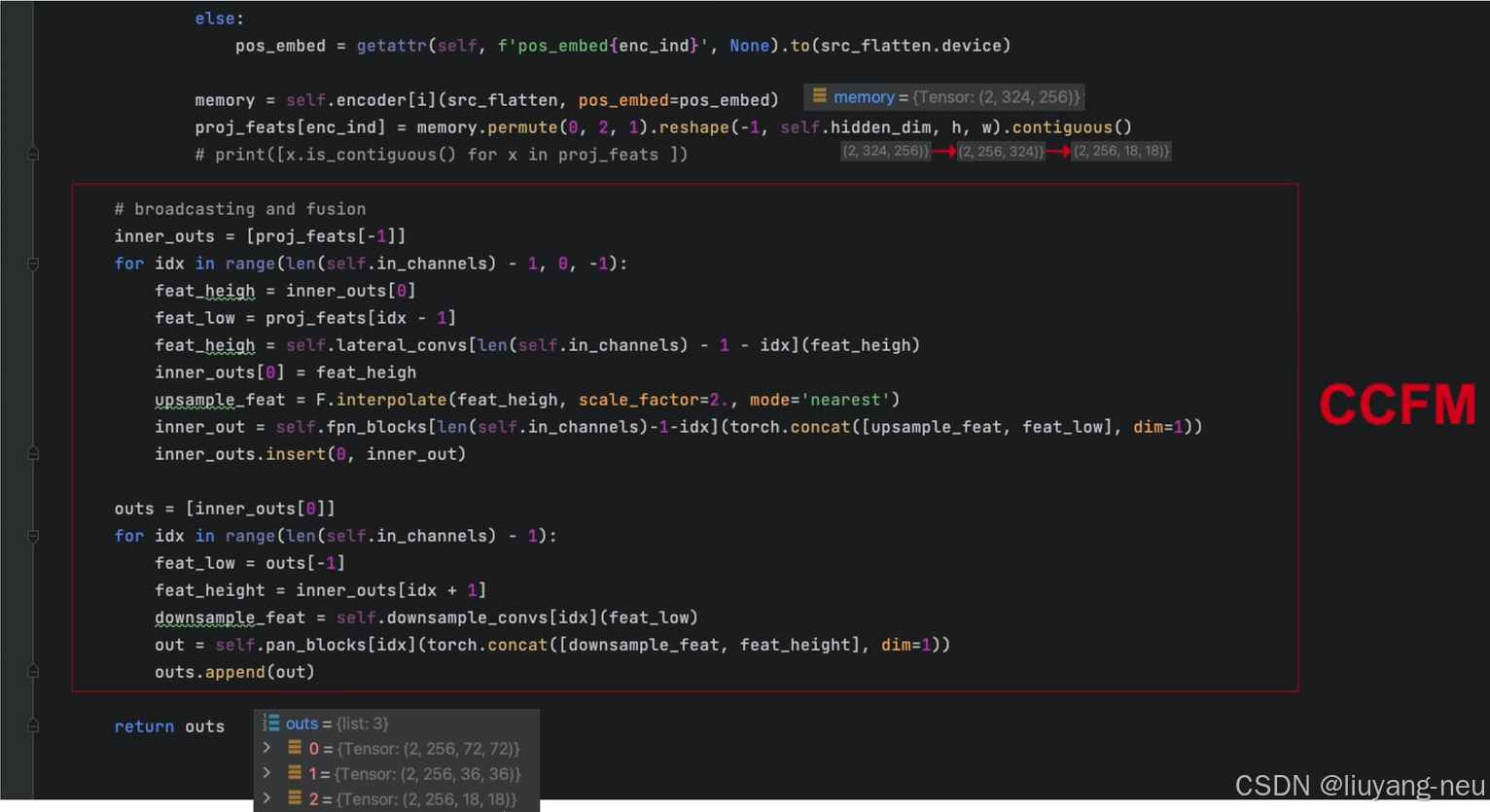
对于颈部网络,RT-DETR采用了一层Transformer的Encoder,只处理主干网络输出的 S5 特征,即AIFI(Attention-based Intra-scale Feature Interaction)模块。
首先,我们将二维的S5 特征拉成向量,然后交给AIFI模块处理,其数学过程就是多头自注意力与FFN,随后,我们再将输出调整回二维,记作 F5 ,以便去完成后续的所谓的"跨尺度特征融合。
之所以RT-DETR的AIFI只处理最后的S5 特征,是出于两点考虑:
- 一方面,以往的DETR,如Deformable DETR是将多尺度的特征展平成序列( RB×C×H×W→RB×N×C ),然后拼接到一起,构成一个序列很长的向量,随后再交给核心为self attention技术的Transformer encoder去做多尺度之间的特征交互,但这无疑会造成巨大的计算资源的消耗,毕竟self attention技术的平方计算复杂度一直是其广受诟病的缺陷之一;
- 另一方面,RT-DETR认为相较于较浅的S3 特征和S4 特征,S5 特征拥有更深、更高级、更丰富的语义特征,而self attention机制可能更关注特征的语义性,而非空间局部细节等,因此,作者团队认为不必让多尺度特征都放到一个篮子中去。
综上,作者团队认为只需将Encoder作用在空间尺寸不太大,信息语义程度有很高的S5 特征上即可,以此来平衡性能和速度------既可以大幅度地减小计算量、提高计算速度,又不会损伤到模型的性能。作者团队设计了若干对照组验证了这一点。
不确定性最小Query选择
Uncertainty-minimal Query Selection:
关于 Query Selection(查询向量选择),大家应该并不陌生,这个方法可谓在DETR领域大杀四方,如DAB-DETR对查询向量进行重构理解,将其解释为Anchor,DN-DETR通过查询降噪来应对匈牙利匹配的二义性所导致的训练时间长的问题,DINO提出从Encoder中选择Top-k特征进行学习等一系列方法,这都无疑向我们证明,查询向量很重要,选择好的Query能够让我们事半功倍。
在RT-DETR中,Query selection 的作用是从 Encoder 输出的特征序列中选择固定数量的特征作为 object queries ,其经过 Decoder 后由预测头映射为置信度和边界框。
DETR中的对象查询是一组可学习的嵌入,由解码器优化并由预测头映射到分类分数和边界框。然而,这些对象查询难以解释和优化,因为它们没有明确的物理含义。后续工作改进了对象查询的初始化,并将其扩展到内容查询和位置查询(锚点)。其中,提出了查询选择方案,它们共同的特点是利用分类分数从编码器中选择排名靠前的K个特征来初始化对象查询(或仅位置查询)。然而,由于分类分数和位置置信度的分布不一致,一些预测框虽有高分类分数,但与真实框(GT)不接近,这导致选择了分类分数高但loU分数低的框,而丢弃了分类分数低但loU分数高的框。这降低了检测器的性能。为了解决这个问题,我们提出了loU感知查询选择,通过在训练期间对模型施加约束,使其对loU分数高的特征产生高分类分数,对loU分数低的特征产生低分类分数。因此,模型根据分类分数选择的排名靠前的K个编码器特征的预测框,既有高分类分数又有高loU分数。我们重新制定了检测器的优化目标如下:
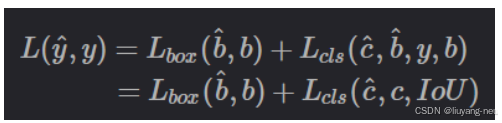
之所以使用IoU软标签,是因为按照以往的one-hot方式,完全有可能出现"当定位还不够准确的时候,类别就已经先学好了"的"未对齐"的情况,毕竟类别的标签非0即1。但如果将IoU作为类别的标签,那么类别的学习就要受到回归的调制,只有当回归学得也足够好的时候,类别才会学得足够好,否则,类别不会过快地先学得比回归好,因此后者显式地制约着前者。在使用了这个技巧后,显然训练过程中,类别的标签不再是此前的0和1离散值,而是0~1的连续值。
Decoder网络:
RT-DETR选择了基于cross attention的Transformer decoder,并连接若干MLP作为检测头,因此,RT-DETR无疑是DETR架构。具体来说,RT-DETR选择DINO的decoder,使用了具体线性复杂度的deformable attention,同时,在训练阶段,使用到了DINO的"去噪思想"来提升双边匹配的样本质量,加快训练的收敛速度。整体来看,RT-DETR的检测头几乎就是把DINO的照搬了过来,当然,其中的一些边边角角的操作给抹掉了,尽可能达到"精简"的目的。
部分图片截取自b站 Enzo_Mi