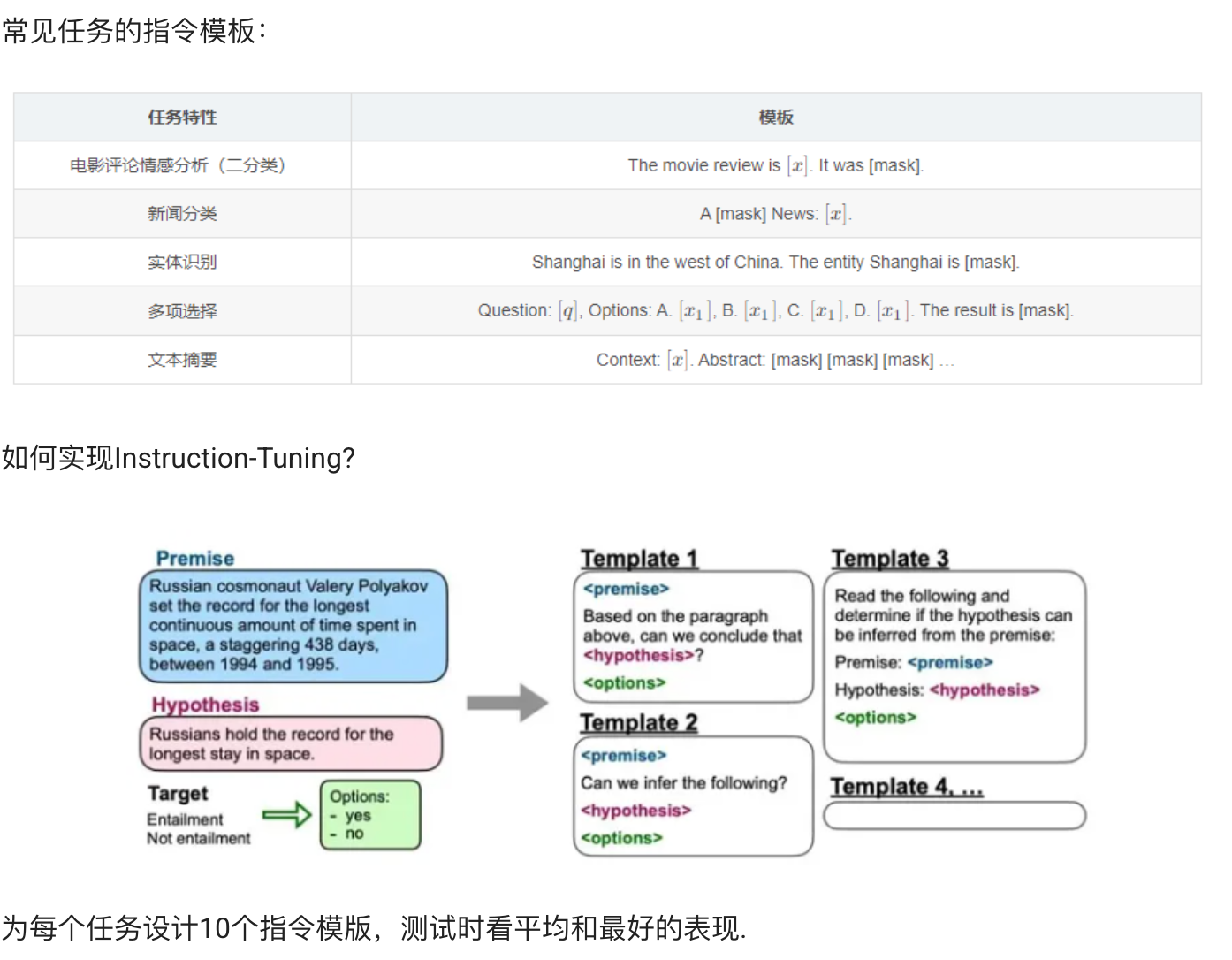
一段话看懂
对百亿乃至千亿参数的大语言模型(LLM)来说,"让模型做好题"有两条主线:
-
提示工程 ------0 参数就能用,关键是给出"好提示"。
-
In-Context Learning(ICL) :把少量"示例→答案"塞进同一次输入,靠语言模型的补全能力直接推理 。
-
Instruction-Tuning:先用大量"指令→答案"微调,让模型学会"听指令" 。
-
Chain-of-Thought(CoT):提示或输出里写下推理过程,显著提升算术/逻辑正确率 。
-
-
参数高效微调(PEFT) ------只改千分之几权重,让同一基座模型快速"贴题"。常见做法:Prefix/Prompt-Tuning、Adapter-Tuning、LoRA 及 QLoRA 。(下篇讲解)
三招提示法+三类 PEFT 共同撑起 2025 年企业级 LLM 落地:前者解决"怎么问",后者解决"如何接线"。
1 三种提示工程
| 方法 | 最早工作 | 一句话原理 | 痛点 |
|---|---|---|---|
| ICL | GPT-3 (2020) | 把 K 条「示例+答案」放在测试样本前;模型当作长文本,一次性补全 | 模板敏感,结果方差大 |
| Instruction-Tuning | Google FLAN (2022) | 用多任务「指令→答案」再训练一次,让模型学会"看到指令就执行" | 需要额外微调一次,成本较高 |
| CoT | Chain-of-Thought Prompting (2022) | 在提示或输出里显式书写中间推理步骤,模型再输出答案 | 只有"大模型"才显著生效,响应更长 |
2 GPT-Style 中文伪代码
说明:已安装 openai 并设置 OPENAI_API_KEY。仅保留最小必要字段,演示核心逻辑。
下面把 6 种常见提示技巧 全部改写成「ChatCompletion 消息列表」风格(system / user / assistant)
说明
• 代码仍可直接运行(需 openai & 已配置 OPENAI_API_KEY)。
• 仅展示核心逻辑,异常捕获 / 分页等可按需添加。
• 若用国产大模型,只需把 model= 改成对应名称即可。
1.In-Context Learning(Few-shot 示例)
python
import openai, textwrap
system_msg = "你是一位精准的中英翻译助手。"
# 把 2 条演示 + 1 条测试都写进同一个 user 消息
user_prompt = textwrap.dedent("""
示例:把中文翻译成英文。
输入:你好
输出:hello
示例:把中文翻译成英文。
输入:再见
输出:goodbye
示例:把中文翻译成英文。
输入:销售
输出:
""").strip()
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":user_prompt}],
temperature=0.0
)
print(rsp.choices[0].message.content.strip()) # → sell2.Instruction-Tuning
python
system_msg = "你是一位精准的中英翻译助手。"
user_msg = "请把"销售"翻译为英文,只给结果。"
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":user_msg}],
temperature=0.2
)
print(rsp.choices[0].message.content.strip()) # → sell3.Chain-of-Thought(Few-shot 中文算术)
python
import openai, textwrap
system_msg = "你是一位善于逐步推理的数学助理。"
cot_demo = textwrap.dedent("""
问:小明有 5 支铅笔,又买 2 盒,每盒 3 支,一共多少支?
答:让我们一步一步思考:
1. 原来 5 支。
2. 2 × 3 = 6 支。
3. 5 + 6 = 11 支。
因此答案是 11。
""").strip()
problem = "问:盒子里有 12 本书,又放进去 7 本,现在多少本?\n答:让我们一步一步思考:"
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":cot_demo + "\n\n" + problem}],
temperature=0.2
)
print(rsp.choices[0].message.content.strip())
# 典型输出(含推理步骤,最后给 19)4.Self-Consistency(CoT × 多次采样投票)
python
import openai, collections, re
system_msg = "你是一位善于逐步推理的数学助理。"
question = "问:盒子里有 12 本书,又放进去 7 本,现在多少本?\n答:让我们一步一步思考:"
def ask_once():
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":question}],
temperature=0.7 # ↑ 提高随机性
)
return rsp.choices[0].message.content
extract_num = lambda txt: int(re.findall(r"\d+", txt)[-1]) # 取答案里的数字
votes = [extract_num(ask_once()) for _ in range(5)]
answer = collections.Counter(votes).most_common(1)[0][0]
print("多数票答案 =", answer) # 多数票 19 更稳5.ReACT (Reason + Act + Tool Calls)
python
import openai, textwrap
system_msg = "你可以调用工具 SEARCH[],如果需要外部信息请先思考再调用工具。"
user_prompt = textwrap.dedent("""
问题:成吉思汗是哪一年去世?
Thought: 我需要具体年份。
Action: SEARCH[成吉思汗 去世 年份]
Observation: 1227 年 8 月 25 日
Thought: 信息已足够。
Action: ANSWER[1227]
""").strip()
rsp = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":user_prompt}],
temperature=0
)
print(rsp.choices[0].message.content.strip())
# 模型应按 Thought → Action → Observation → ANSWER 的格式续写⚙️ 如需真正执行搜索,可结合 functions 或外部检索 API;这里为演示写死 Observation 内容。
6.Tree-of-Thought(单分支简化示例)
python
import openai
system_msg = "你是一位善于枚举多种解法并选择最优的规划助理。"
root_state = ("目标:用 1, 2, 3, 7 通过四则运算得到 9。\n"
"当前状态:[] 当前结果:0\n"
"请给出一步扩展及新的中间结果,只输出 '步骤: ...' 和 '结果: ...'。")
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":system_msg},
{"role":"user", "content":root_state}],
temperature=0.3
)
print(rsp.choices[0].message.content.strip())
# 真实 ToT 会递归展开多分支并打分;此处只示范首步格式技巧对照速查
| 场景 | 推荐技巧 | 把它写进 messages**...** |
|---|---|---|
| 零代码改模型,快速 Demo | Few-shot ICL | 多条示例塞进同一个 user |
| RAG / API 服务 | Instruction-Tuning 基座 | system 给角色,user 写指令 |
| 算术 / 逻辑推理 | CoT ± Self-Consistency | user 里带示例或加"让我们一步一步思考" |
| 需要外部检索 | ReACT / 检索-CoT | 在推理链中显式写 Action: SEARCH... |
| 多方案规划 | Tree-of-Thought | 逐步展开分支,选最高分答案 |
一句话:把示例、指令或推理链放进 messages 就能"零修改"驱动 GPT 系列及国产指令模型;若需要更稳、更强,可再叠加 Self-Consistency、ReACT、ToT 这些 2023--2025 年的新玩法。
一句话 :提示工程已从"塞几条示例"升级到"让模型自己思考、检索甚至搜索分支";配合国产指令+CoT 预烤模型,2025 年企业可在 0 参数 到 极小参数之间自由切换,把复杂推理跑上云端或手机端。
核心 takeaway 2020 -- 2022 解决了"链式提示可提升推理";
2023 -- 2024 把链式提示接上 检索 / 工具 / 自演化,并完成了 国产模型预烤;
2025 的关键词是 "端侧 & 量化" ------ 指令 + CoT 已嵌入轻量基座,零参数即可本地运行。
近两年来,随着Prompt-Tuning技术的发展,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至是零样本的性能也能够极大地被激发出来,得益于这些模型的 参数量足够大 ,训练过程中使用了 足够多的语料 ,同时设计的 预训练任务足够有效 。最为经典的大规模语言模型则是2020年提出的GPT-3,其拥有大约1750亿的参数,且发现只需要设计合适的模板或指令即可以 实现免参数训练的零样本学习 。
2022年底到2023年初,国内外也掀起了AIGC的浪潮,典型代表是OpenAI发布的ChatGPT、GPT-4大模型,Google发布的Bard以及百度公司发布的文心一言等。超大规模模型进入新的纪元,而这些轰动世界的产物,离不开强大的Prompt-Tuning技术。本文默认以GPT-3为例,介绍几个面向超大规模的Prompt-Tuning方法,分别为:
- 上下文学习 In-Context Learning(ICL) :直接挑选少量的训练样本作为该任务的提示;
- 指令学习 Instruction-Tuning :构建任务指令集,促使模型根据任务指令做出反馈;
- 思维链 Chain-of-Thought(CoT) :给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
1. In-Context Learning(上下文学习)
In-Context learning(ICL)最早在GPT-3中提出, 旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果。
常用的In-context learning方法包括:
- zero-shot learning
- 定义: 给出任务的描述, 然后提供测试数据对其进行预测, 直接让预训练好的模型去进行任务测试.
- 示例: 向模型输入"这个任务要求将中文翻译为英文. 销售->", 然后要求模型预测下一个输出应该是什么, 正确答案应为"sell".
- one-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入一个样本做指导. 相当于在预训练好的结果和所要执行的任务之间, 给一个例子, 告诉模型英语翻译为法语, 应该这么翻译.
- 示例: 向模型输入"这个任务要求将中文翻译为英文. 你好->hello, 销售->", 然后要求模型预测下一个输出应该是什么, 正确答案应为"sell".
- few-shot learning
- 定义: 在预训练和真正翻译的样本之间, 插入多个样本(一般10-100条)做指导. 相当于在预训练好的结果和所要执行的任务之间, 给多个例子, 告诉模型应该如何工作.
- 示例: 向模型输入"这个任务要求将中文翻译为英文. 你好->hello, 再见->goodbye, 购买->purchase, 销售->", 然后要求模型预测下一个输出应该是什么, 正确答案应为"sell".
目前In-context Learning依然与普通的fine-tuning有一定差距,且预测的结果方差很大,同时也需要花费时间考虑template的构建。
2. Instruction-Tuning(指令学习)
面向超大规模模型第二个Prompt技术是指令学习。其实Prompt-Tuning本质上是对下游任务的指令,简单的来说:就是告诉模型需要做什么任务,输出什么内容。上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示。因此,在对大规模模型进行微调时,可以为各种类型的任务定义指令,并进行训练,来提高模型对不同任务的泛化能力。
什么是Instruction-Tuning? 让我们先抛开脑子里的一切概念,把自己当成一个模型。我给你两个任务:
- 1.带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!
- 2.判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差
- 你觉得哪个任务简单?想象一下:做判别是不是比做生成要容易?Prompt就是第一种模式,Instruction就是第二种。
Instruction-Tuning和Prompt-Tuning的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于:
- Prompt是去激发语言模型的**补全能力**,比如给出上半句生成下半句、或者做完形填空。
- Instruction-Tuning则是激发语言模型的**理解能力**,通过给出更明显的指令/指示,让模型去理解并做出正确的action.
- Promp-Tuningt在没有精调的模型上也能有一定效果,但是Instruct-Tuning则必须对模型精调,让模型知道这种指令模式。
举例说明:
- 例如在对电影评论进行二分类的时候,最简单的提示模板(Prompt)是". It was mask.",但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板(加上Instruction),例如"The movie review is . It was mask.",然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为指令Instruction.
3. Chain-of-Thought(思维链)
思维链 (Chain-of-thought,CoT) 的概念是在 Google 的论文 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" 中被首次提出。思维链(CoT)是一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能,如算术推理、常识推理和符号推理。
CoT 没有像 ICL 那样简单地用输入输出对构建提示,而是结合了中间推理步骤,这些步骤可以将最终输出引入提示。简单来说,思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习(即通过x1,y1,x2,y2,....xtest作为输入来让大模型补全输出ytest),思维链多了中间的推导提示。
以一个数学题为例:
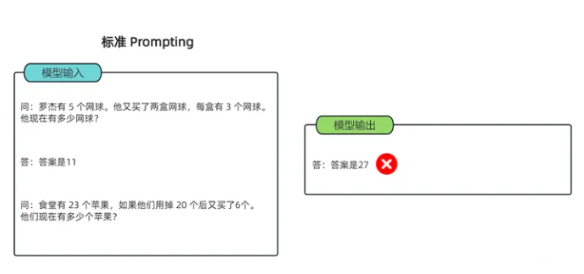
- 可以看到模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。CoT 做的就是这件事,示例如下:
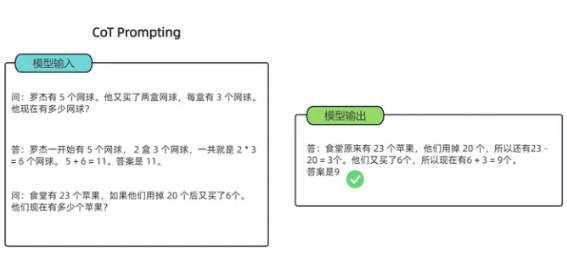
-
可以看到,类似的算术题,思维链提示会在给出答案之前,还会自动给出推理步骤:
"罗杰先有5个球,2盒3个网球等于6个,5 + 6 = 11" "食堂原来有23个苹果,用了20个,23-20=3;又买了6个苹果,3+6=9
上述例子证明了思维链提示给出了正确答案,而直接给出答案的传统提示学习,结果是错的,连很基本的数学计算都做不好。简单来说,语言模型很难将所有的语义直接转化为一个方程,因为这是一个更加复杂的思考过程,但可以通过中间步骤,来更好地推理问题的每个部分。
CoT分类:
- Few-shot CoT :是 ICL 的一种特殊情况,它通过融合 CoT 推理步骤,将每个演示〈input,output〉扩充为〈input,CoT,output〉。
- Zero-shot CoT:与 Few-shot CoT 不同 在 prompt 中不包括人工标注的任务演示。相反,它直接生成推理步骤,然后使用生成的 CoT 来导出答案。(其中 LLM 首先由 "Let's think step by step" 提示生成推理步骤,然后由 "Therefore, the answer is" 提示得出最终答案。他们发现,当模型规模超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,显示出显著的涌现能力模式)。
一个有效的思维链应该具有以下特点:
- 逻辑性:思维链中的每个思考步骤都应该是有逻辑关系的,它们应该相互连接,从而形成一个完整的思考过程。
- 全面性:思维链应该尽可能地全面和细致地考虑问题,以确保不会忽略任何可能的因素和影响。
- 可行性:思维链中的每个思考步骤都应该是可行的,也就是说,它们应该可以被实际操作和实施。
- 可验证性:思维链中的每个思考步骤都应该是可以验证的,也就是说,它们应该可以通过实际的数据和事实来验证其正确性和有效性。
4 相关阅读 / 引用
-
GPT-3 Few-shot 原论文
-
Google FLAN 系列 Instruction-Tuning
-
Chain-of-Thought Prompting 原论文
-
Google Scaling Instruction-Tuned Models 博文
-
"Let's think step by step" Zero-shot CoT 示范
-
OpenAI ChatCompletion API 文档(temperature & messages)
-
Anthropic CoT Demo Notebook
-
FLAN-T5 互动教程
-
Google Symbol Tuning 研究提高 ICL 稳定性
-
OpenAI 产品文档主页
一句话:提示工程关心"问得巧不巧",PEFT 关心"改得省不省";选好工具,你就能在 0 参数到极小参数之间自由切换,把 LLM 落到业务场景。