完整内容请看文章最下面的推广群
2025电工杯数学建模竞赛 A题保姆级分析完整思路+代码+数据教学
2025电工杯 A题保姆级教程思路分析
DS数模-全国大学生电工数学建模(电工杯) A题保姆级教程思路分析
A题:光伏电站发电功率日前预测问题
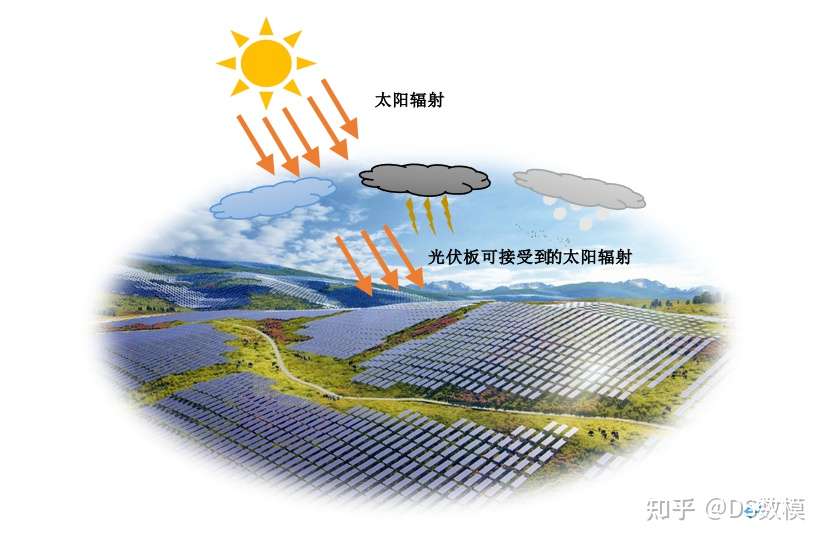
下面我将以背景介绍、数据集分析、问题分析的步骤来给大家讲解A题的具体思路。
1 背景介绍
光伏电站发电功率的日前预测是新能源并网管理中的核心问题。由于光伏发电依赖于太阳辐照度,其输出功率受气象条件(如云量、温度、雾霾)和地理因素(经纬度、海拔、倾角)的显著影响,导致功率波动性大。这种波动会对电网稳定性造成威胁,例如功率失衡和频率波动。因此,电力调度部门需要通过高精度的日前预测(24-48小时)提前制定调度计划,以保障电网安全运行
主要研究:1 长周期与短周期特性分析:结合理论辐照计算与实际功率偏差,揭示季节性变化(如太阳倾角)和日内波动(如云层变化)对发电的影响。2 预测模型构建:利用历史功率数据或融合数值天气预报(NWP)信息提升预测精度。3 空间降尺度验证:探索精细化气象预报(如千米级到百米级)对预测的改进潜力。
这里需要注意几点:主要是数据集的搜集:

2 气象不确定性:短时云层变化难以被NWP完全捕捉,需通过时序模型或集成学习缓解。
3 空间异质性:光伏电站覆盖面积可能小于NWP网格尺度,需降尺度技术提高局部预报精度。
4 多因素耦合:需同时建模辐照、温度、季节等非线性关系,可能引入注意力机制或特征交叉。
2 数据集分析
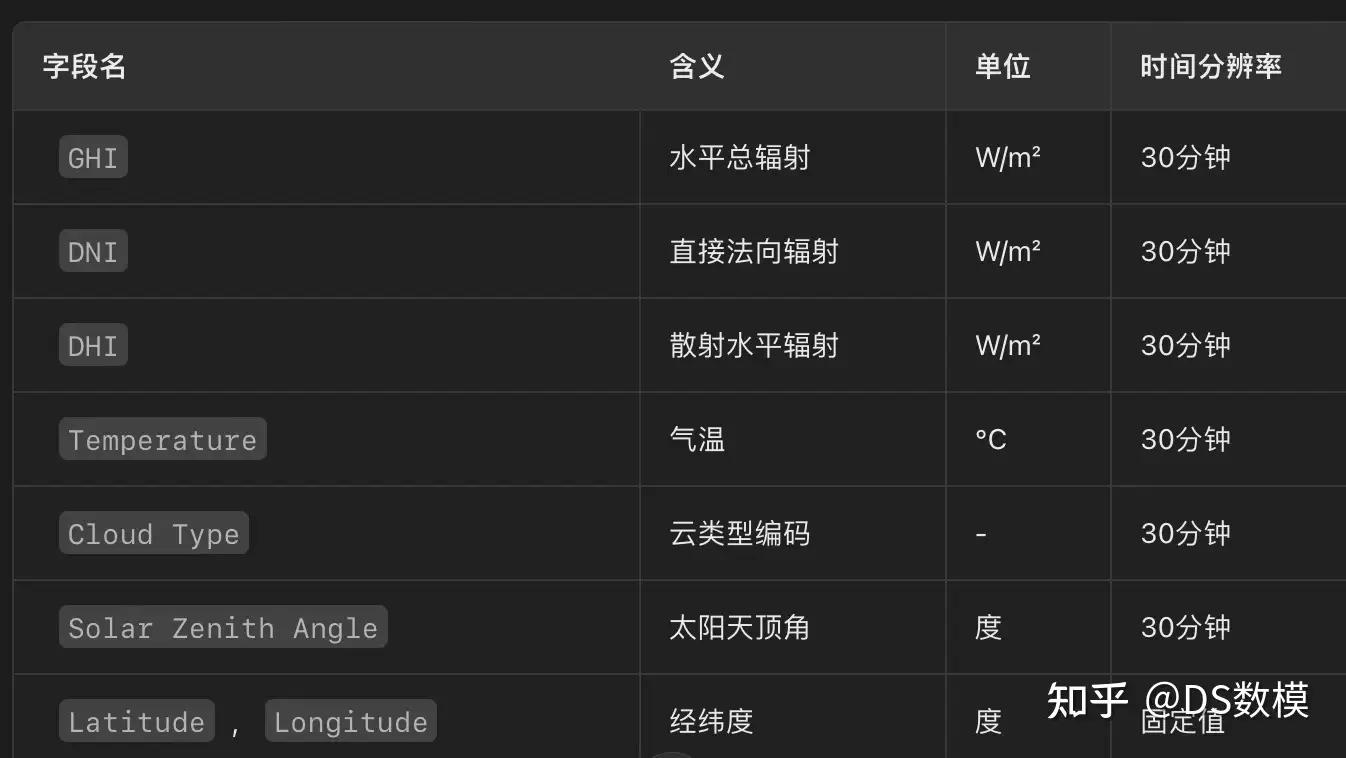
根据题目要求,需选择包含 历史发电功率 和 NWP数据(数值天气预报) 的公开数据集,且需满足以下条件:
- 时间分辨率:15分钟
- 时间跨度:至少1年
- NWP属性:气温、辐射、云量等
- 地理信息:经纬度、海拔、倾角(可选)
数据集1: NSRDB (美国国家太阳能辐射数据库)
数据集2: GEFCom2014 (全球能源预测竞赛2014)
https://www.kaggle.com/datasets/boltzmannbrain/gefcom2014
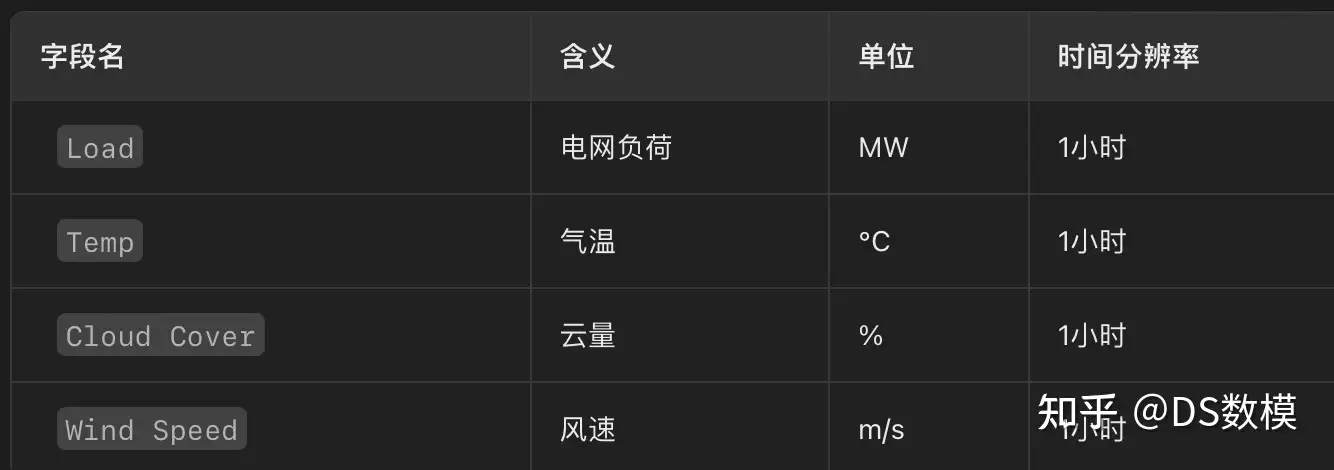
预处理需求:
- 时间分辨率从1小时插值到15分钟(需结合时序模型如Prophet)。
- 需补充太阳辐射数据(如从NSRDB融合)。
数据预处理流程
以 NSRDB + PVOutput 为例,预处理步骤如下:
import pandas as pd
import numpy as np
# 加载NSRDB辐射数据
nsrdb = pd.read_csv('nsrdb_data.csv', parse_dates=['Time'], index_col='Time')
# 加载PVOutput实际发电功率数据
pv_data = pd.read_csv('pv_output.csv', parse_dates=['Time'], index_col='Time')
# 合并数据集(按时间对齐)
df = pd.merge(nsrdb, pv_data, left_index=True, right_index=True, how='inner')
# 线性插值
df_15min = df.resample('15T').interpolate(method='linear')
# 检查缺失值比例
print(df_15min.isnull().sum())
# 填充缺失值(前后填充)
df_15min.fillna(method='ffill', inplace=True)
df_15min.fillna(method='bfill', inplace=True)
from pvlib import solarposition
# 计算太阳位置(天顶角、方位角)
location = {'latitude': df_15min['Latitude'][0], 'longitude': df_15min['Longitude'][0]}
sun_pos = solarposition.get_solarposition(df_15min.index, **location)
df_15min['zenith'] = sun_pos['zenith']
df_15min['azimuth'] = sun_pos['azimuth']
# 计算理论发电功率(假设装机容量为10MW)
C = 10 # MW
df_15min['P_theoretical'] = C * df_15min['GHI'] / 1000 # GHI单位为W/m²,需归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
features = ['GHI', 'Temperature', 'zenith', 'azimuth', 'Cloud Type']
df_15min[features] = scaler.fit_transform(df_15min[features]) # 提取月份信息
df_15min['month'] = df_15min.index.month
# 定义测试月份(2,5,8,11月最后一周)
test_months = [2, 5, 8, 11]
test_mask = df_15min['month'].isin(test_months) & \
(df_15min.index >= df_15min.index - pd.DateOffset(days=7))
train_data = df_15min[~test_mask]
test_data = df_15min[test_mask]代码说明:

3 问题分析
问题一分析与求解:
建模目标
通过对比 理论可发功率 和 实际发电功率,分析光伏电站的 季节性变化(长周期)和 日内波动(短周期)特性,并量化气象、地理等因素对发电功率的影响。
建模过程:


算法推荐:
- 太阳辐照模型:
- PVLIB-Python:用于计算太阳位置、倾斜面辐照度和理论功率。
- Bird模型:复杂辐照计算(考虑大气透射率)。
- 时序分析工具:
- STL分解(Seasonal-Trend Decomposition):分离长周期趋势和短周期波动。
- 傅里叶变换:检测周期性信号(如日/年周期)。
- 偏差归因分析:
- 多元线性回归:量化气象变量(云量、温度)对偏差率的影响。
- 随机森林特征重要性:识别关键影响因素。
注意的点:

后续思路、代码等持续更新。
其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!