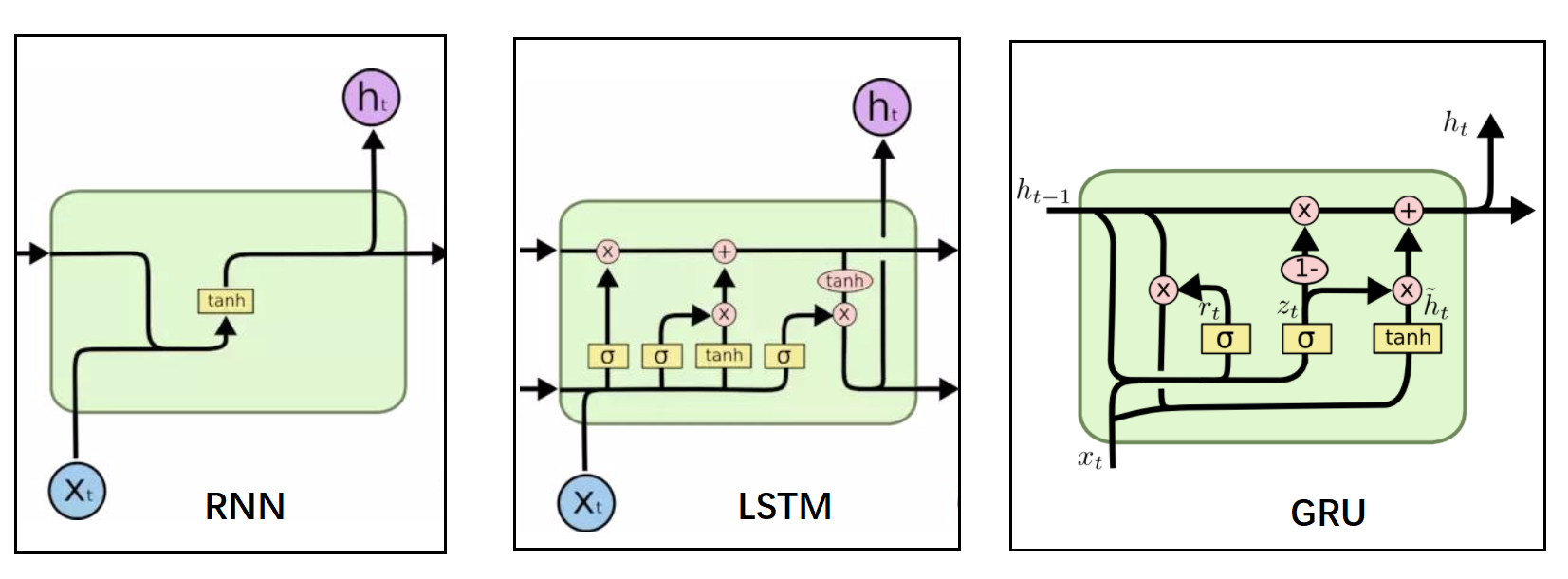
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 设置随机种子以确保结果可重复
torch.manual_seed(42)
# 示例:加载和预处理 Jena Climate 数据集(假设数据已加载到一个 NumPy 数组中)
# 在实际应用中,你需要根据实际情况加载和处理数据
data = np.random.rand(1000, 14) # 假设有 1000 个时间点,14 个特征
# 数据归一化
data_mean = data.mean(axis=0)
data_std = data.std(axis=0)
data = (data - data_mean) / data_std
# 定义时间序列数据集
class TimeSeriesDataset(Dataset):
def __init__(self, data, seq_length):
self.data = data
self.seq_length = seq_length
def __len__(self):
return len(self.data) - self.seq_length
def __getitem__(self, idx):
x = self.data[idx:idx + self.seq_length, :-1] # 输入特征:除最后一个特征外的所有特征
y = self.data[idx + self.seq_length, -1] # 目标:最后一个特征作为预测目标
return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.float32)
seq_length = 24 # 序列长度,例如过去 24 个小时的数据
dataset = TimeSeriesDataset(data, seq_length)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义 LSTM 模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :]) # 使用最后一个时间步的输出进行预测
return out
input_size = data.shape[1] - 1 # 输入特征数
hidden_size = 64 # 隐藏层单元数
output_size = 1 # 输出特征数(预测目标)
model = LSTMModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
train_loss = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
loss = criterion(outputs, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
train_loss += loss.item() * x_batch.size(0)
train_loss = train_loss / len(train_loader.dataset)
model.eval()
test_loss = 0
with torch.no_grad():
for x_batch, y_batch in test_loader:
outputs = model(x_batch)
loss = criterion(outputs, y_batch.unsqueeze(1))
test_loss += loss.item() * x_batch.size(0)
test_loss = test_loss / len(test_loader.dataset)
print(f'Epoch {epoch + 1}/{num_epochs}, Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}')
# 预测
model.eval()
with torch.no_grad():
test_inputs = data[-seq_length:, :-1].astype(np.float32)
test_inputs = torch.tensor(test_inputs).unsqueeze(0)
predicted = model(test_inputs)
predicted = predicted.item() * data_std[-1] + data_mean[-1] # 反归一化
# 打印预测结果
print(f'Predicted value: {predicted:.4f}')
# 可视化结果(示例)
plt.figure(figsize=(10, 6))
plt.plot(data[-100:, -1] * data_std[-1] + data_mean[-1], label='True Values')
plt.plot(len(data) - 1, predicted, 'ro', label='Predicted Value')
plt.xlabel('Time')
plt.ylabel('Temperature')
plt.title('Temperature Prediction')
plt.legend()
plt.show()