
目录
[代码和数据 与 PCB 在系统上的联动](#代码和数据 与 PCB 在系统上的联动)
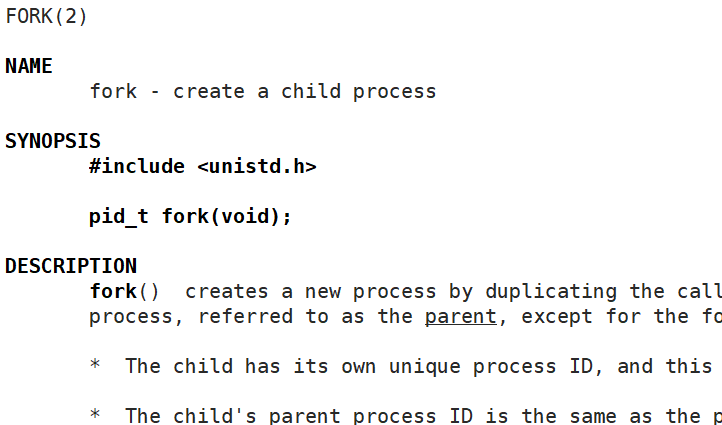
[pid & ppid](#pid & ppid)
进程是什么?
我们可以打开Windows中的任务管理器:
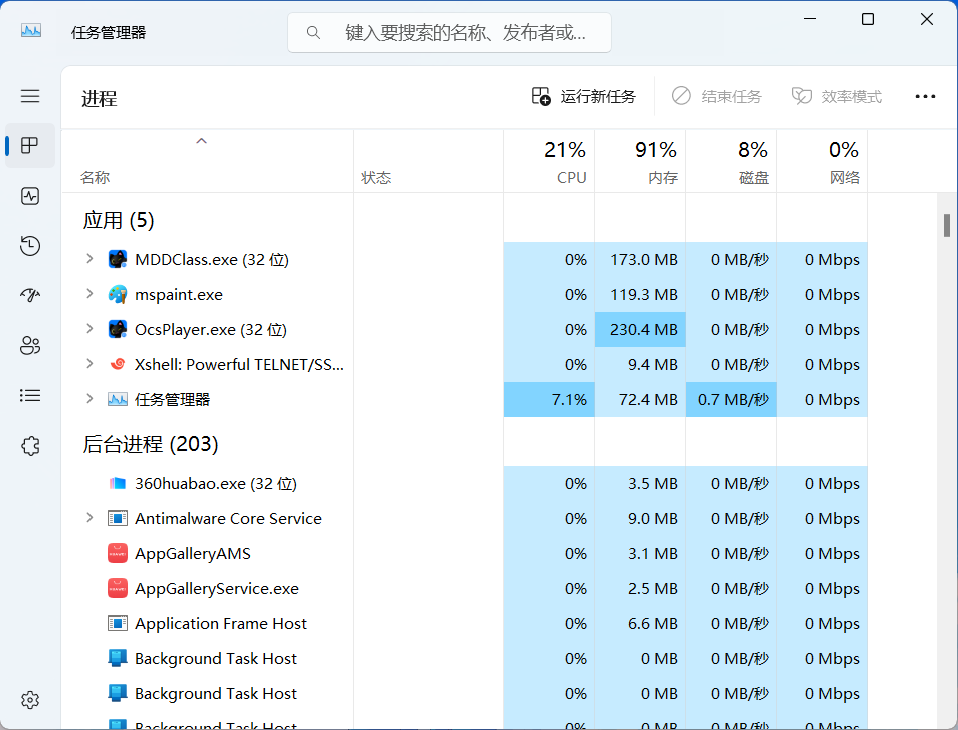
我们可以在上面看到,所有正在跑的程序都会在上面显示,这其实就都是一个个的进程
那么进程具体是什么?
首先,我们的代码如果要跑起来的话,就需要先加载到内存中,这是冯诺依曼体系结构规定的
那么当我们将数据和代码 加载到内存之后,这些数据和代码是否就是进程呢?
试想一下,你如何说你是一个学校的学生?因为你人在学校你就是了吗?那保安大叔也在学校里啊?你放假回家了就不是那个学校的学生了吗?显然不是,你是那个学校的学生,是因为你的信息在学校的教务系统里面被管理着
对于操作系统而言,我们光有代码和数据还不够,还需要将其管理起来,也就是:先描述,再组织
我们需要先用struct把进程给描述起来,接着就是将这一个个的struct用特定的数据结构管理起来
接着,我们对进程的管理,就转换成了对特定数据结构的管理
而我们用来描述进程的struct,就是PCB,也就是process control block(进程控制块)
但是PCB,是一个总称,而在Linux中则是task_struct,这就好比"奔驰"和"汽车",奔驰只是汽车中的一种,仅此而已
所以我们就可以得出结论了,也就是:
进程 = PCB + 代码和数据
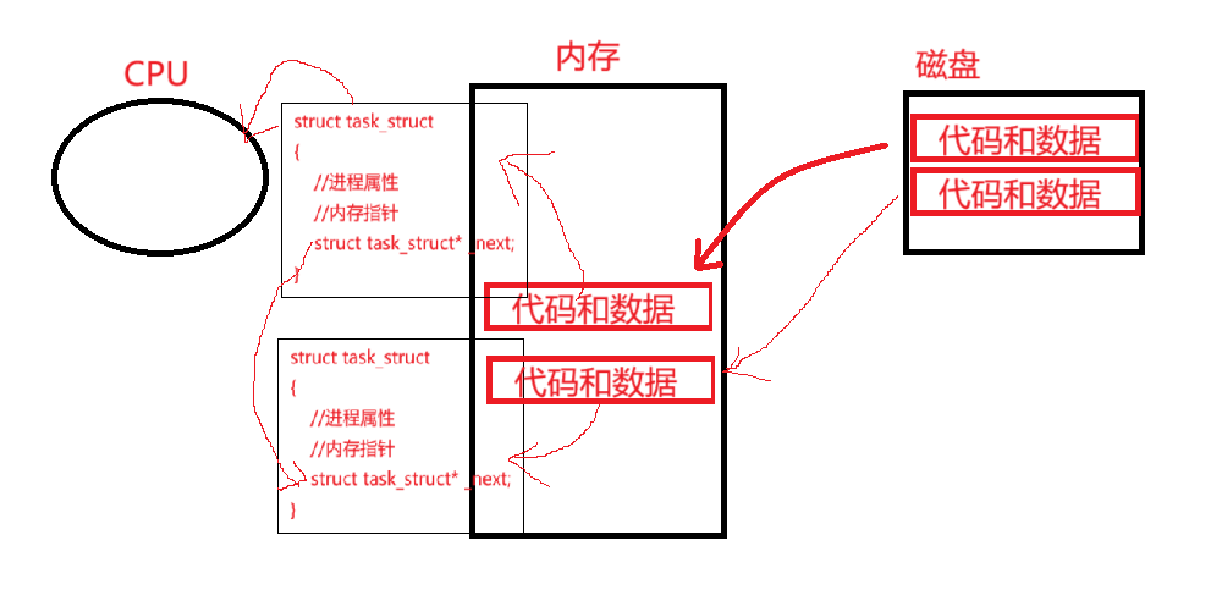
看这张图,代码和数据加载到内存中,然后task_struct中有内存指针可以指向这部分对应的代码和数据,接着CPU就对task_struct进行管理
以上就是进程的概念了,讲完了概念,我们来演示一遍代码和数据在系统中具体是怎么和PCB联动起来的
代码和数据 与 PCB 在系统上的联动
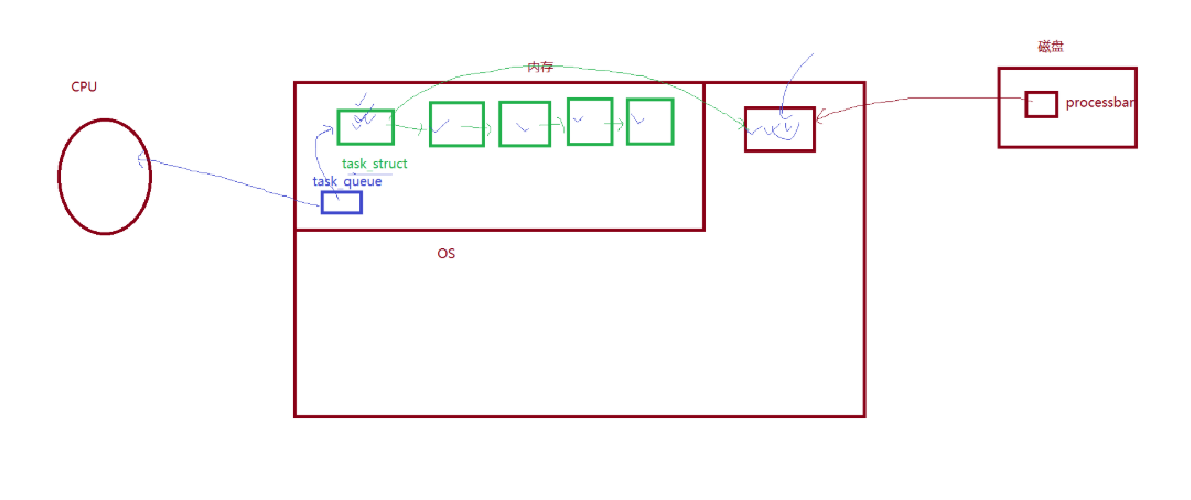
如上图,我们的代码数据是加载到了内存中的用户空间,而我们的PCB则是在内存中的内核空间中存着
这时有新的代码和数据进来内存了,我们就在内核空间中new一块空间出来,然后PCB中的内存指针指向对应的代码和数据,这样就能将这部分内容管理起来了
接着,我们系统中不断有进程需要创建,所以task_struct就不断变多
这些task_struct就全部链接起来(数据结构),这时候就将进程管理起来了
而后面如果涉及到进程调度,等待之类的,就都让CPU和内核处理了
pid & ppid
我们在Linux敲指令时,当我们想跑程序了,都会用 ./XXX 跑代码,而这个指令的本质就是运行进程
包括我们敲的ls、pwd、cd等等指令,都是启动了进程,只不过这些进程的开始到结束都比较快
而一个进程的属性中,必然会有自己的id,也就是pid,而每一个pid都是唯一的
如果我们想知道pid的话,我们有两个办法
第一个就是用指令:
ps ajx | head -1 && ps ajx | grep name
ls /proc/
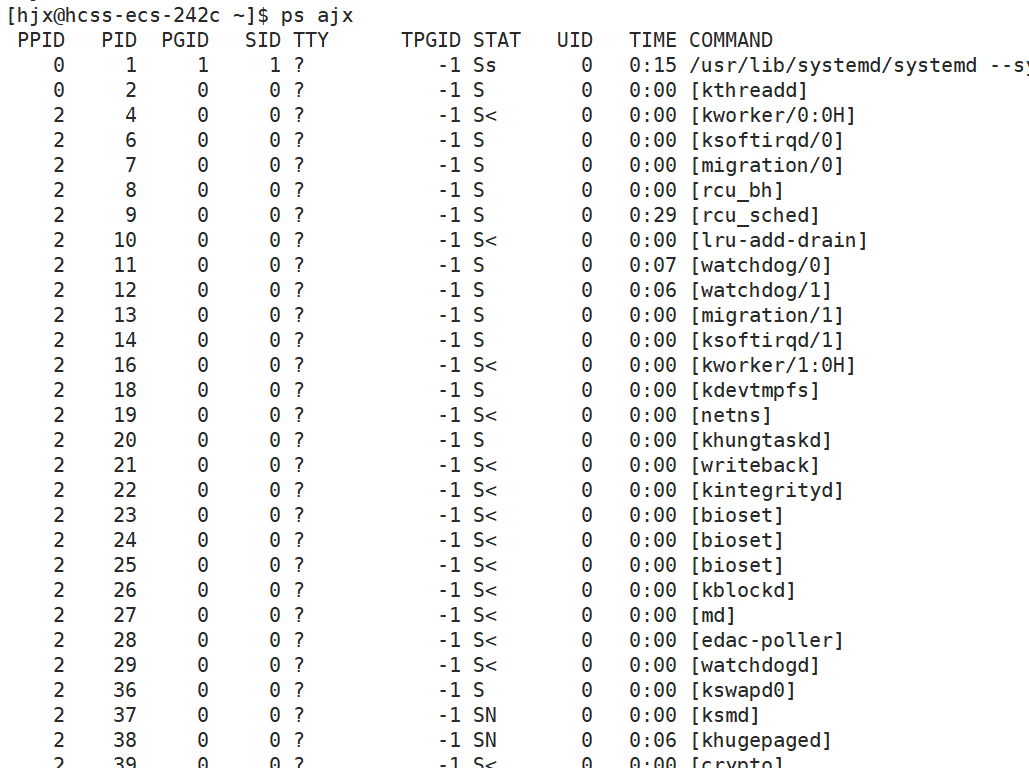
ps指令查我们具体某一个进程比较好,因为grep就是筛选用的

但如果想用代码查呢?
首先我们需要知道的是,只要你想知道pid,那么就一定只能在PCB中找
但是,PCB是被内核数据结构管理的,而我们用户是无法直接进内核查东西的,我们只能使用系统接口
而这时我们就有了一个系统接口:getpid()
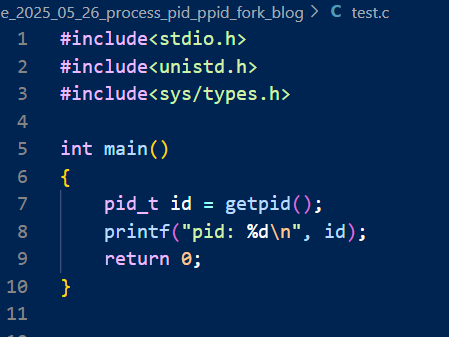
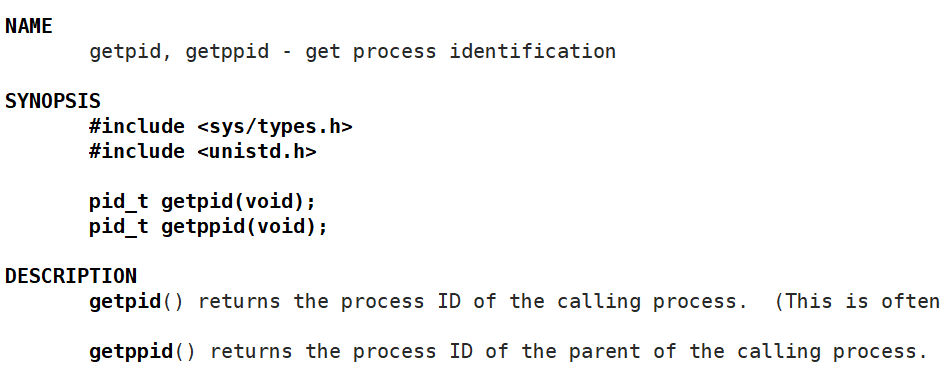

这个pid是哪个进程的pid呢?我们程序跑起来的时候就已经是一个进程了,所以就是那个跑起来的进程,而我们的进程最后结束了,所以就没法在外面用指令查到
同时,我们除了pid之外,还有一个ppid,第一个p就是parent的意思,也就是父进程
这也就意味着,我们每一个进程都是由另一个进程创建出来的,但是每一个进程之间互相不影响
那我们这个程序自始至终都没有看到父进程的影子,那我们的父进程会是谁呢?
我们先将父进程的id打印出来,接着我们再用ps命令进行查找,最后用grep命令最筛选:
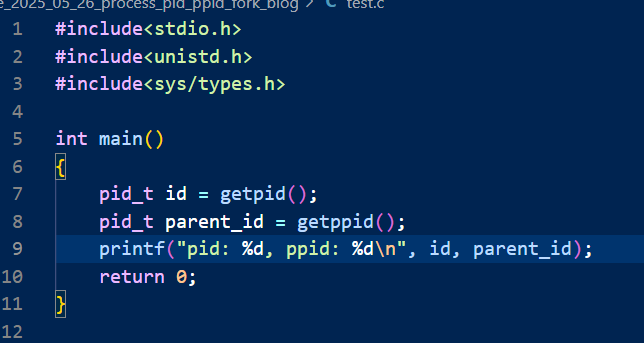
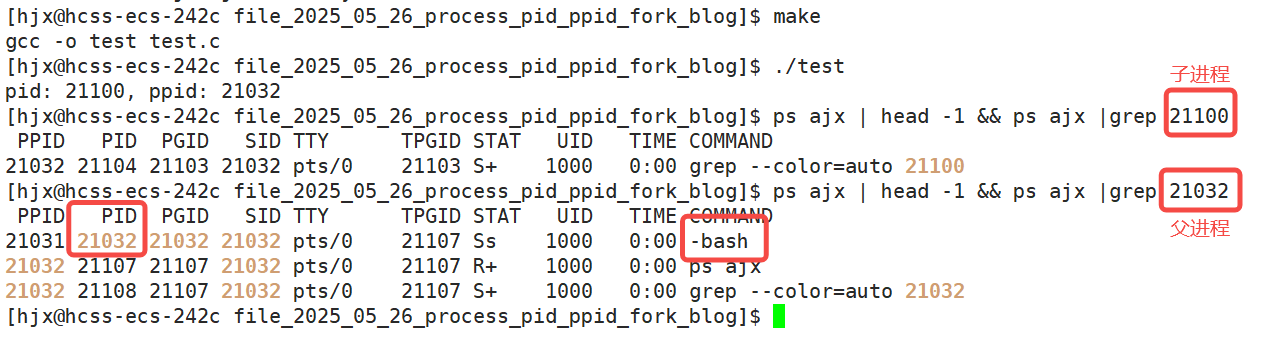
我们可以看到,启动我们程序的父进程就是bash,也就是我们的命令行解释器
创建子进程
同样的,创建子进程我们也是需要调用系统接口------fork
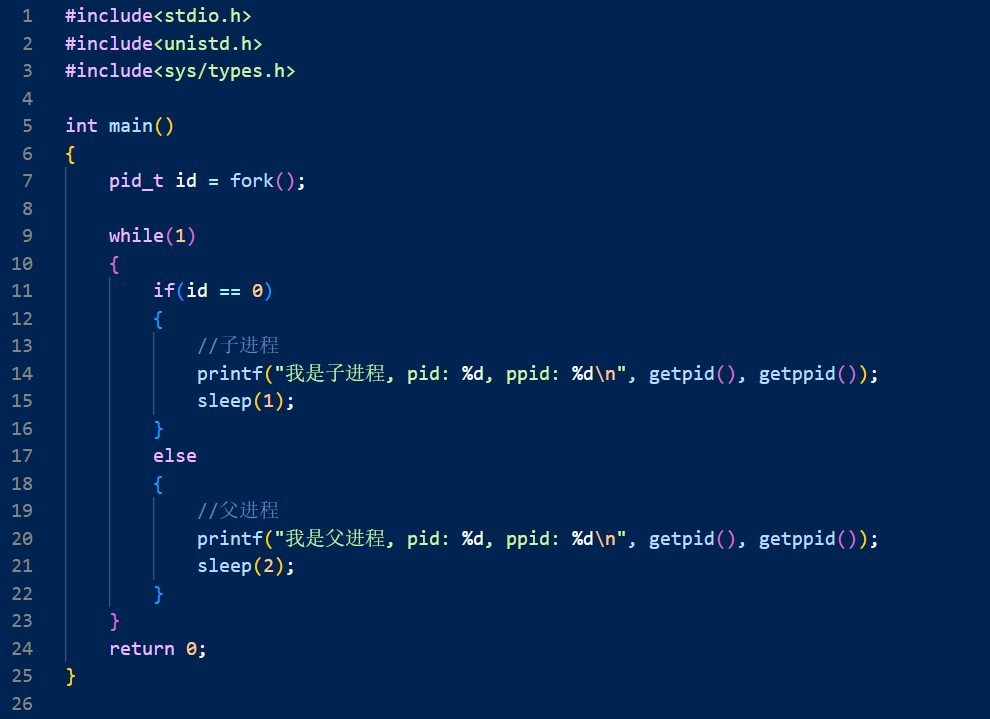
先来简单用一用,来看这样一段代码:
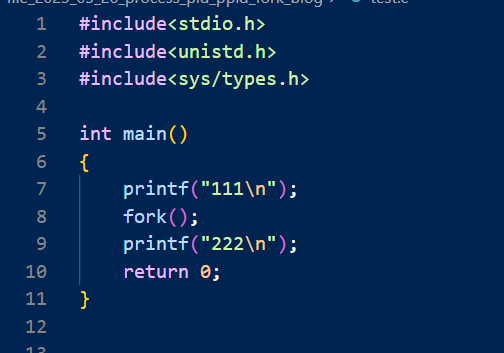
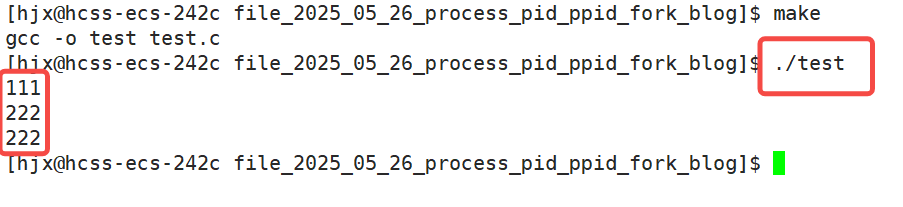
我们会看到,222居然被打印了两次,这是因为我们我们在fork之后,就已经有两个进程了,而两个进程之间是互相独立的
也就是说,fork之后,分了两个进程,一个打印了第一个222,一个打印了第二个222
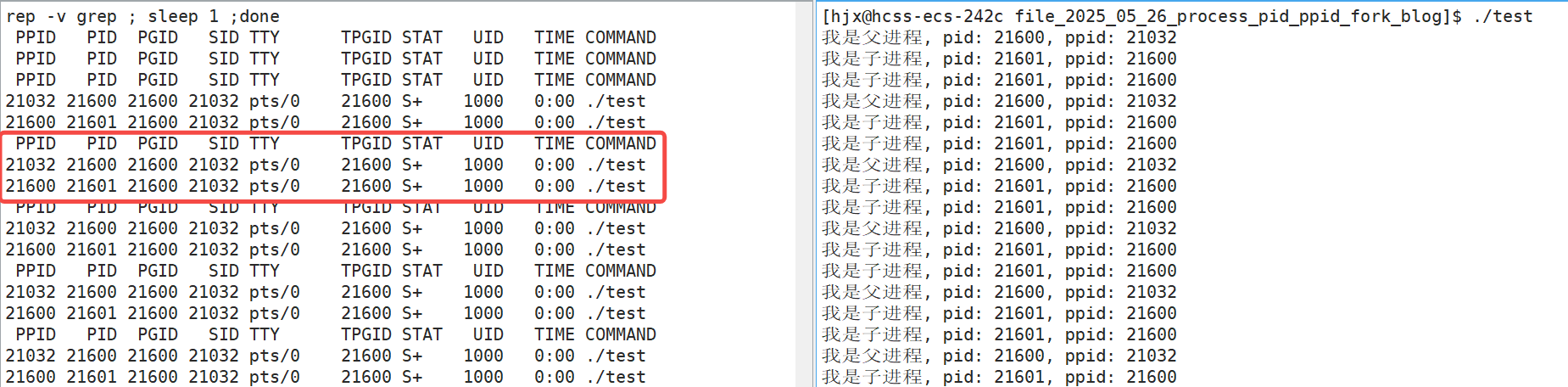
那我们怎么看到是否真的有两个进程呢?还是原来那个代码,只不过我们将其改成不断循环打印,如下:
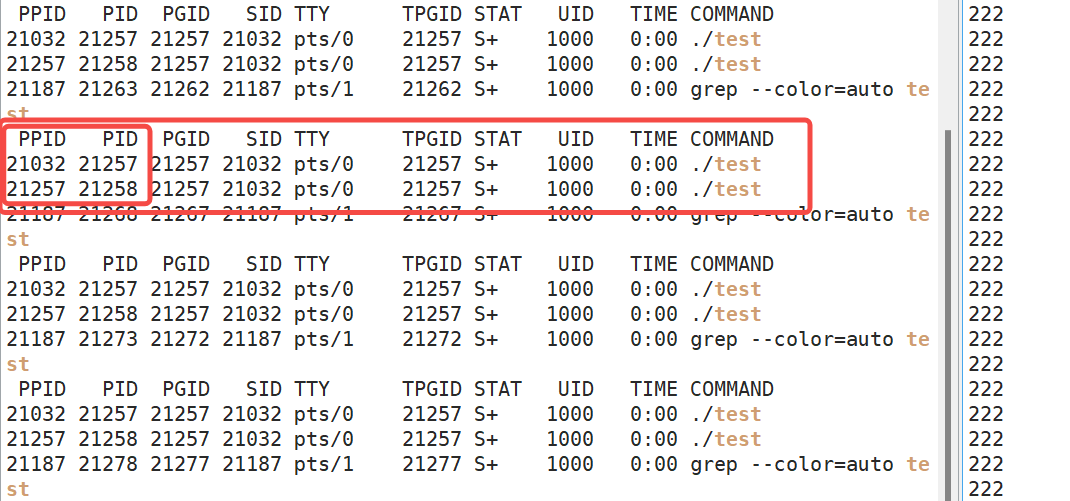
确实我们可以看到,在test运行的时候有两个进程,上面的是父进程,因为下面那个进程的ppid是他的pid
接下来我们就需要来好好讲讲fork这个函数了:
首先,我们的fork是有两个返回值的,创建完进程之后,如果创建成功,就将子进程的pid作为返回值返回给父进程,然后将 0 返回给子进程
如果没有成功创建子进程,那么fork就会将 -1 返回给父进程
听起来似乎很诡异,因为我们之前从来没有说一个函数返回两个返回值的情况,但是先不管那么多,我们先来写一个代码验证一下
顺便一提,我们为什么要有子进程呢?这是因为我们需要子进程帮我们处理不同的任务,这点我们目前暂时没处理过什么任务暂时无法理解,记着就行
现在来解释fork,为什么能返回两个参数呢?这是因为我们在fork返回也就是return的时候,我们前面的业务就已经做完了,也就是,进程已经创建出来了
那么我们的进程只需要用一下条件判断,就能知道哪个进程要返回哪个了
结语
这篇文章到这里就结束啦!!~( ̄▽ ̄)~*
如果觉得对你有帮助的,可以多多关注一下喔