【生物信息学】k-mer的基本概念及应用
0.introduction
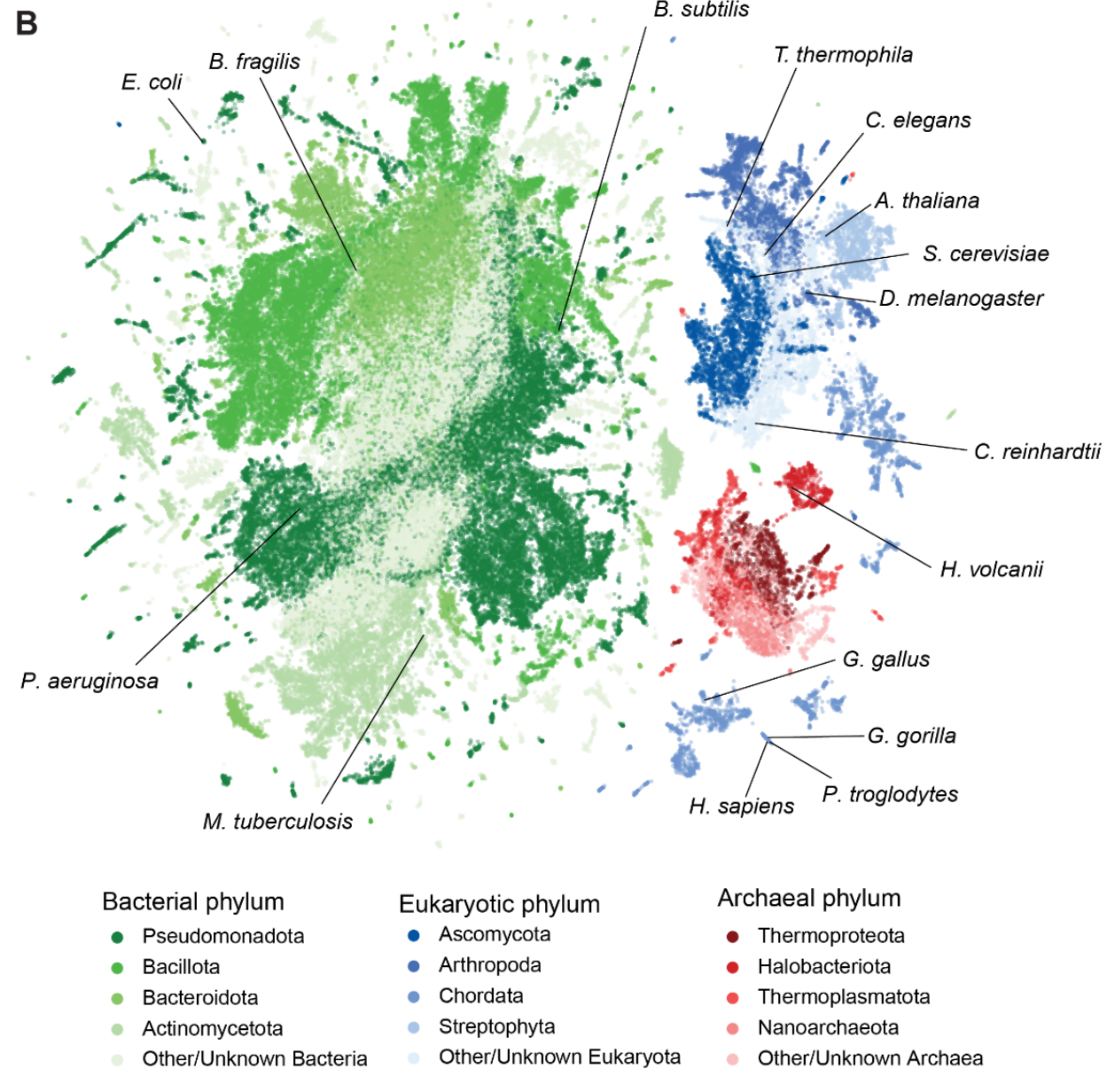
在 Evo 2 论文中,有一张图展示了基于不同物种基因组 K-mer 特征的 UMAP 嵌入结果,因此专门查阅了 K-mer 相关概念以深入了解其含义。
1. k-mer的定义
k-mer通常被定义为长度为k 的连续核酸序列(或氨基酸序列)片段,以序列ATCGATCAC为例:
3-mers:
sequence: ATCGATCAC
3-mer #0: ATC
3-mer #1: TCG
3-mer #2: CGA
3-mer #3: GAT
3-mer #4: ATC
3-mer #5: TCA
3-mer #6: CAC4-mers:
sequence: ATCGATCAC
4-mer #0: ATCG
4-mer #1: TCGA
4-mer #2: CGAT
4-mer #3: GATC
4-mer #4: ATCA
4-mer #5: TCAC由此可见长度为 L 的序列中,会有 L−k+1 个 k-mers。值得注意的是,在双链DNA中常将正反互补序列 视为同一k-mer,以减少冗余,此时取该k-mer及其反向互补序列中字典序较小者作为规范k-mer ,例如ATC和GAT的规范 k-mer是ATC。
2. k-mer的生物学意义
1-mer可以用于评估整体碱基组成(GC 含量);2-mer可捕捉简单双核苷酸偏好(如 CpG 岛);3-mer则与密码子使用偏好高度相关;k ≥ 4时特异性越来越强,常用于捕捉更长序列基序与重复,如转录因子结合位点(6--8-mer )、滑动重复( 2--6-mer)。
特别地,某些k-mer在所有已知基因组中缺失 (称为nullomer),这些"缺失序列"可能具有生物学意义,被用于疾病检测、疫苗设计等领域。(病原体可能通过缺失特定的k-mer来逃避宿主免疫系统的识别。例如,病毒可能避免表达某些特定的抗原表位,以减少被宿主免疫系统识别的机会。)
大部分工具默认选择奇数k值,如果 k 为偶数,可能存在某个 k-mer 本身等于其反向互补(如回文序列"TCGCGA"),这会让方向判断和配对操作复杂化
。很多工具常使用31 ,是因为31是能用 64 位整数编码的最大奇数 k 值。现代计算机对 64 位运算支持良好,31-mers 在哺乳动物基因组乃至细菌数据库中既足够具有特异性,又有大量唯一 k-mers,因此成为启发式标准。
3. k-mer的生物学应用
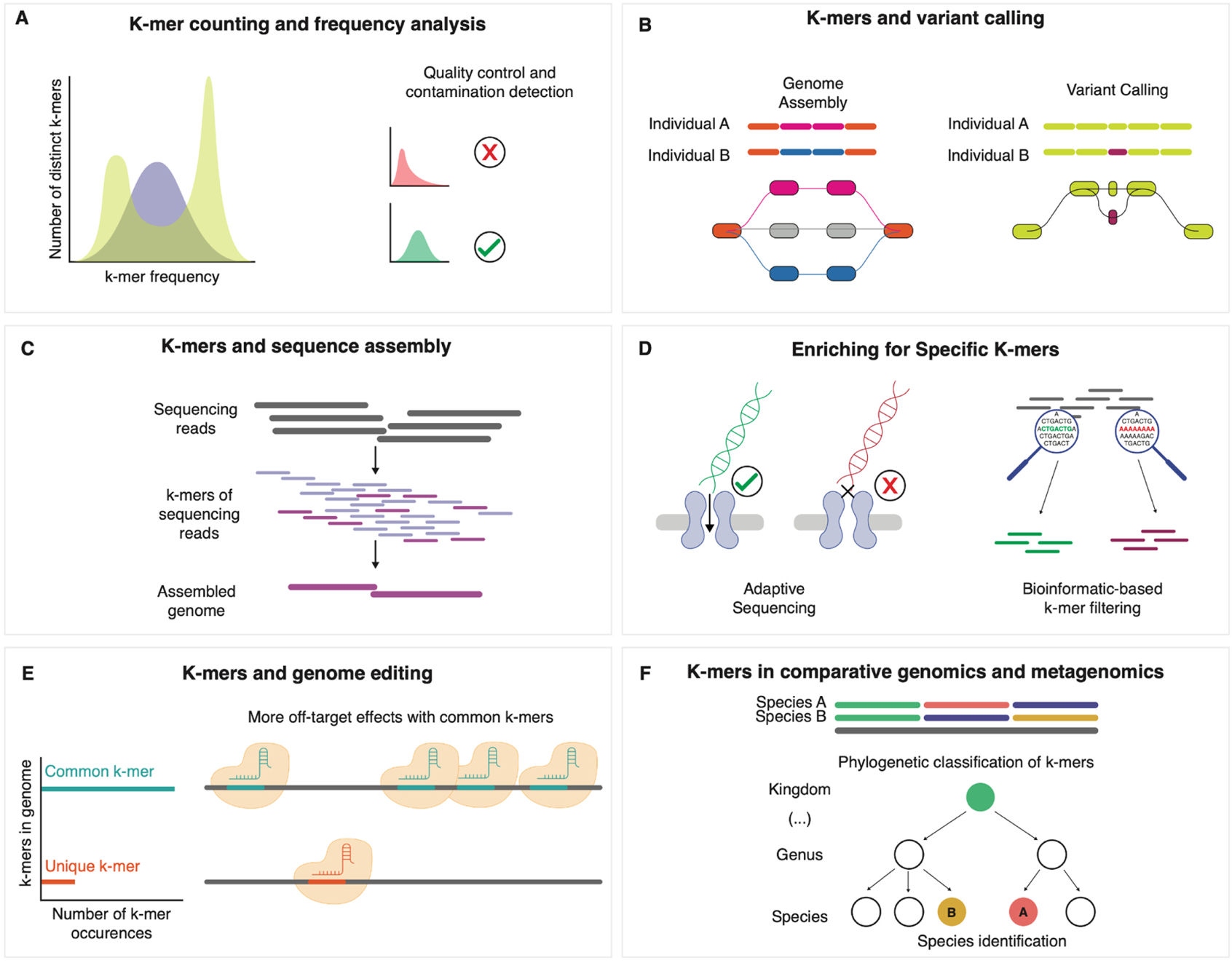
K-mer计数和频率分析
低质量的区域可能会导致特定k-mer频率的异常。通过检查k-mer频率分布,可以发现这些区域,并通过去除这些区域或校正数据来提高测序质量。
K-mer与变异检测
在变异检测中,k-mer帮助识别基因组之间的差异,如单核苷酸多态性(SNP)和其他遗传变异。
K-mer与序列组装
使用较长的碱基的k-mer大小来聚类、排序和定位基因组组装片段,,可以有效地将重叠的序列拼接起来,并通过k-mer计数发挥错误校正作用。
特定K-mer的富集
自适应测序可以通过聚焦特定的k-mer模式来富集感兴趣的区域。类似地,基于生物信息学的k-mer筛选可以用于去除不相关的k-mer或富集感兴趣的序列,从而帮助专注于最相关的基因组区域进行进一步研究。
K-mer与基因组编辑
常见的k-mer如果作为引导序列使用,可能会导致更多的脱靶效应。而使用独特的k-mer可以减少脱靶效应,从而提高基因组编辑的精确度。
K-mer在比较基因组学和元基因组学中的应用
通过分析不同物种的k-mer分布,可以根据共享的k-mer模式对基因组进行分类(例如古菌和细菌物种展示单峰谱,而四足动物则呈现多峰谱),帮助物种的鉴定,并理解它们的进化关系。
4. Evo 2 原文的应用
原文中"To better separate the domains, k-mer composition vectors were multiplied by 2 for archaeal species and by 3 for eukaryotic species."原文中讲古细菌和真核细胞的向量k-mer放大n倍,并不是一种常见的做法,主要还是为了将他们分开更好的可视化展示有哪些物种,UMAP图本身没有什么特别的意义。