在数据分析中,我们经常会看到带有时间属性的数据,比如股价波动,各种商品销售数据,网站的网络用户活跃度等。一般来说,根据需求我们会分为两种,分析历史数据的特点和预测未来时间段的数据。
移动平均
移动平均的原理是用几天的数据作为一个窗口,根据权重乘以值得出预测该天的数据。我们以分析销售数据作为例子:
R
set.seed(123)
weeks <- 1:15
sales <- round(5000 + cumsum(rnorm(15, sd=300))) # 随机波动
ma3_forecast <- stats::filter(sales, rep(1/3,3), sides=1)
# 预测第16周
next_week <- tail(ma3_forecast,1)
plot(weeks, sales, type="o", ylim=c(4000,6000),
main="便利店周销售额预测", ylab="销售额", xlab="周数")
lines(weeks, ma3_forecast, col="red", type="o")
points(16, next_week, col="red", pch=19)
abline(v=15.5, lty=2)
text(16, next_week, labels=paste("预测:",round(next_week)), pos=4)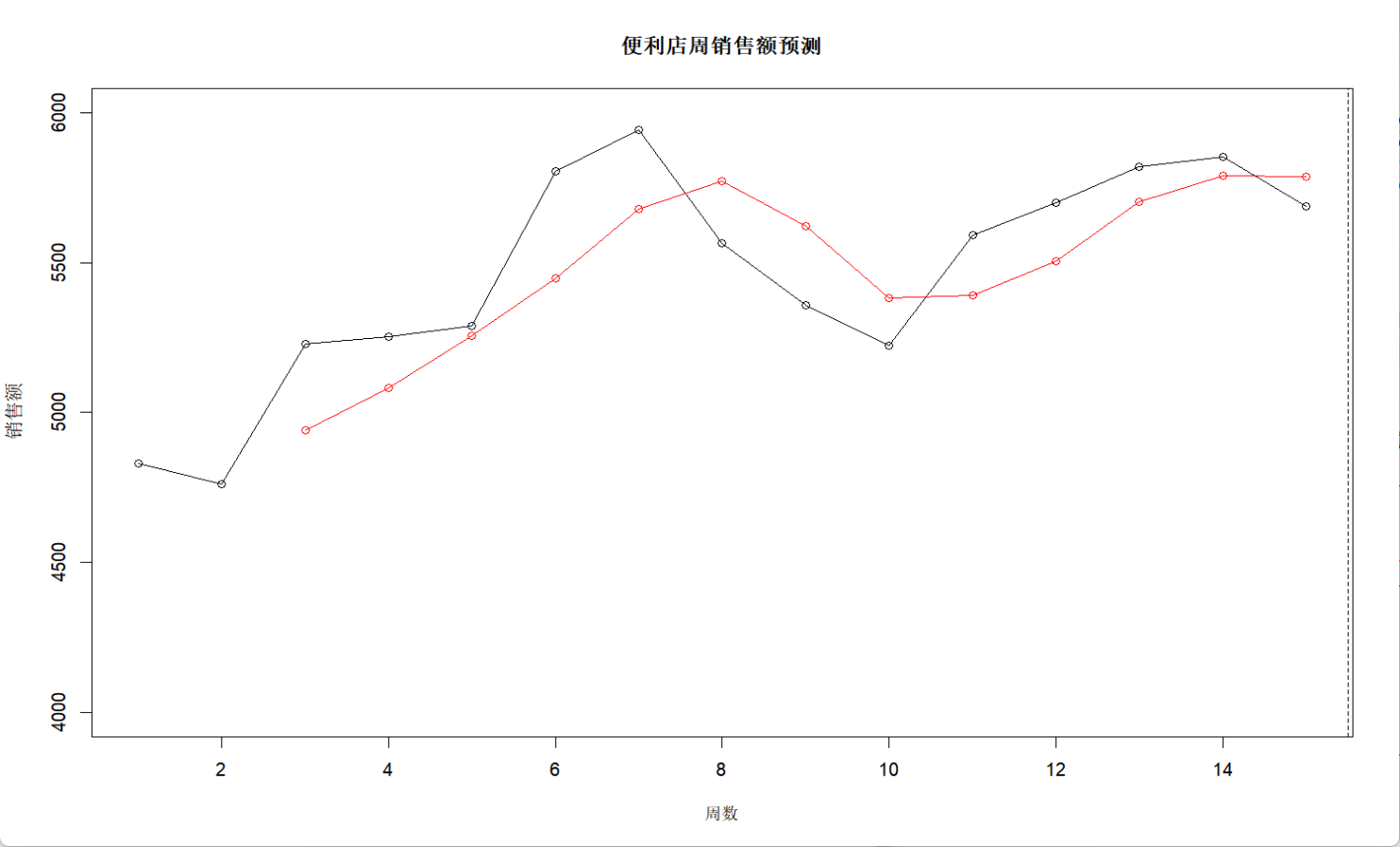
这里由于是要进行预测数据,代码里的语法选择了sides=1,意思是用历史数据来预测,图中的红点是基于历史数据生成的对于预测点,从这里我们可以观察到红色曲线像是往右偏移了的灰色曲线,这表明了如果简单的用历史数据去预测,那么预测得到的数据的特点会具有滞后性。
接下来我们来看看研究过去的体温数据的例子:
R
set.seed(123)
days <- 1:14
true_temp <- 36.5 + 0.1 * sin(2 * pi * days/7) # 真实体温有轻微周波动
measured_temp <- true_temp + rnorm(14, sd=0.3) # 测量误差
ma3 <- stats::filter(measured_temp, rep(1/3, 3), sides=2)
plot(days, measured_temp, type="o", col="gray",
main="每日体温监测", ylab="体温(℃)", xlab="天数") # 原始数据
lines(days, true_temp, col="green", lwd=2) # 平滑后的趋势
lines(days, ma3, col="red", lwd=2, type="o")
legend("topright",
legend=c("测量值", "真实值", "3天移动平均"),
col=c("gray", "green", "red"), lty=1, pch=c(1,NA,1))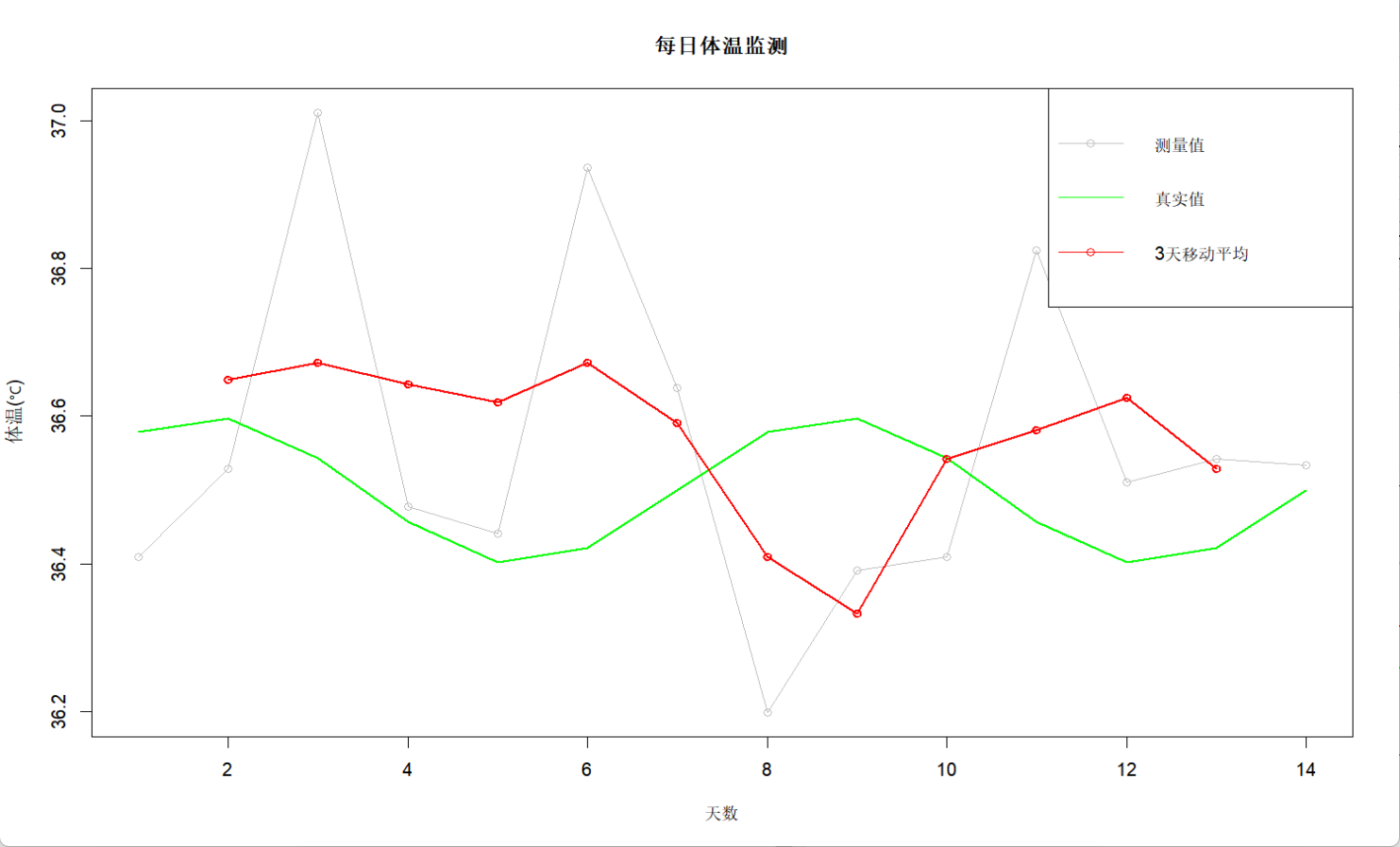
在这里我们用的是sides=2,表示中心平均,也就是三个数据的权重相同,当然了,如果数据本身特殊,也可以用不等量权重weight <- c(0.2,0.5,0.3),注意最左边的是最靠近预测天数的那一个数据点。之所以分析历史数据时我们用中心平均,是因为这样利用了前后信息,可以从数据点的下一个数据得出反馈。此外,通过比较原始数据与平滑数据的偏差,如果某点的偏差远大于其他点(如超出2倍标准差),我们也可以借机对其进行异常标记。像股价分析问题中,用中心化平滑股价波动,如果某天价格大幅度偏离平滑线,那就有可能是市场异常事件导致的。