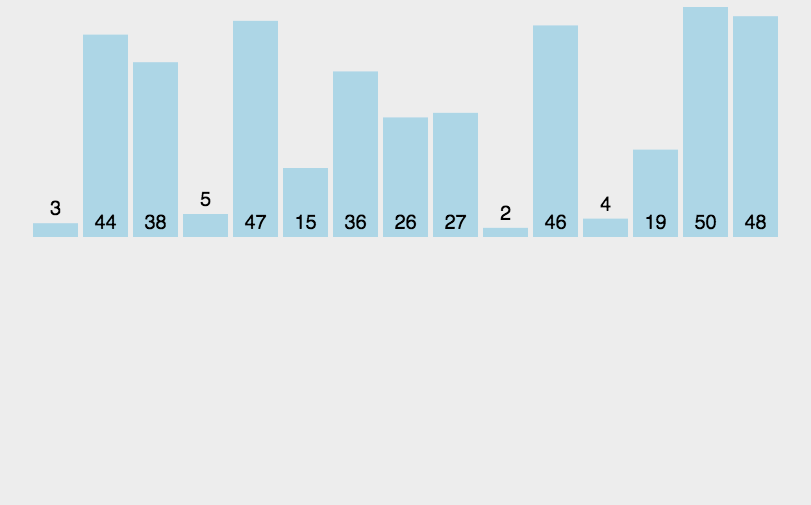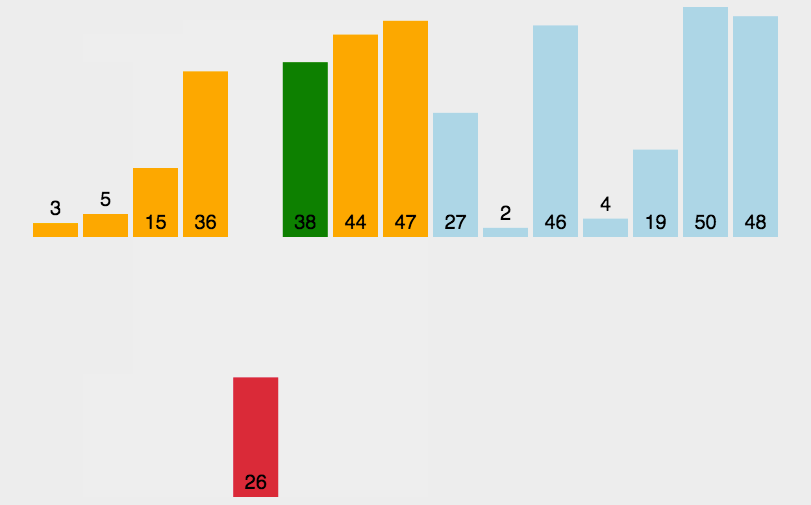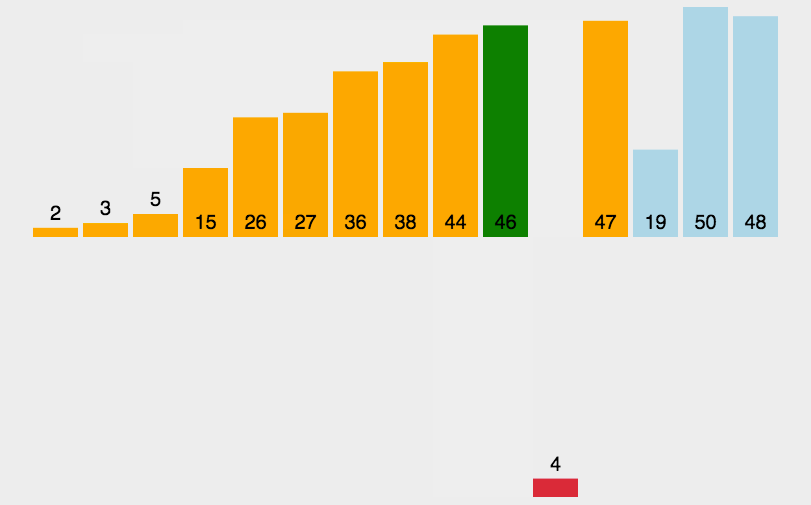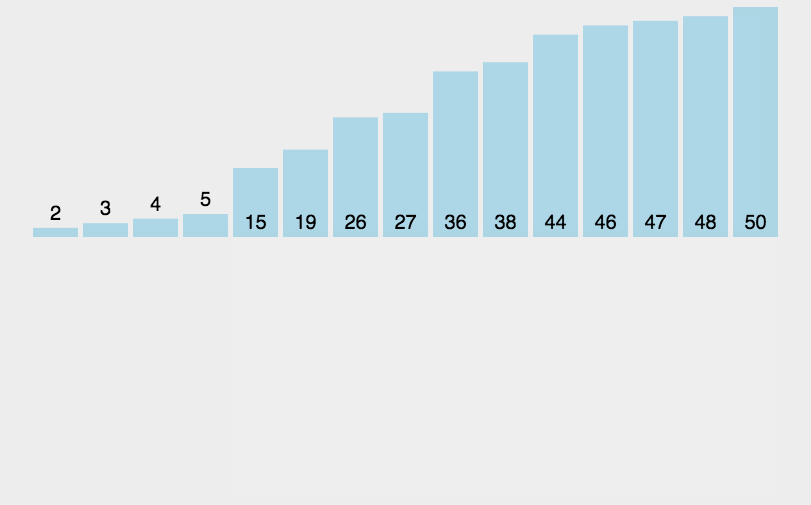
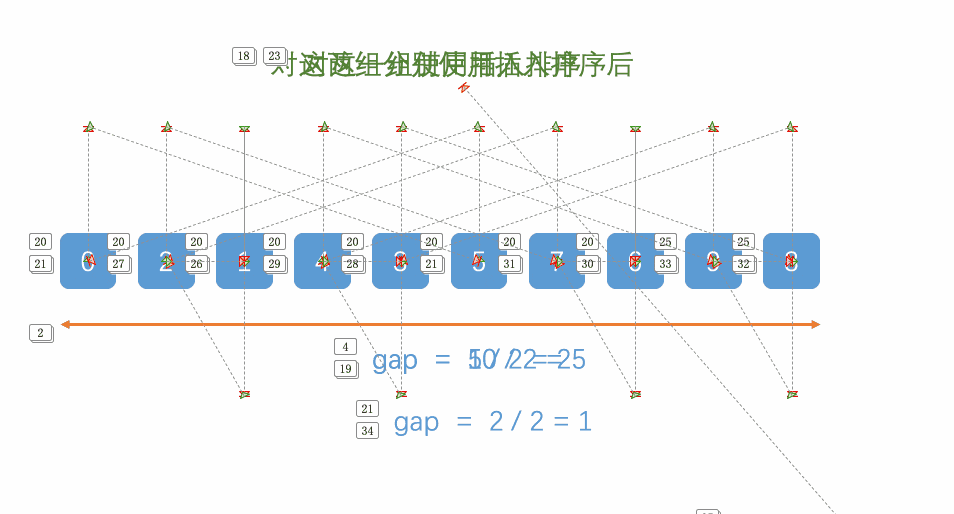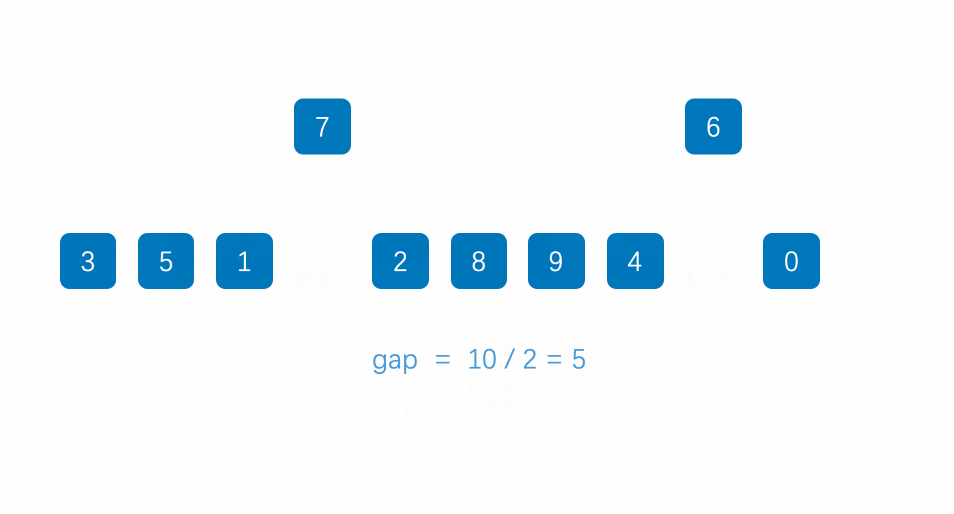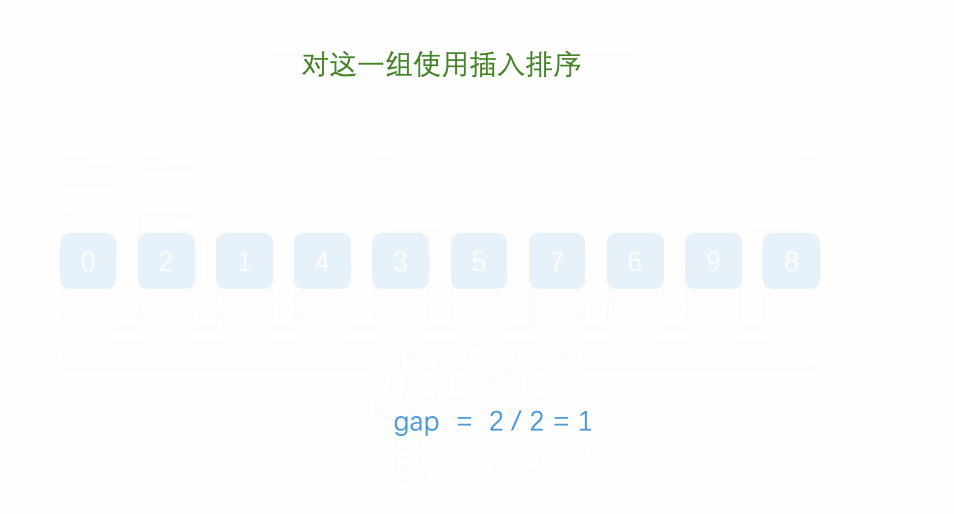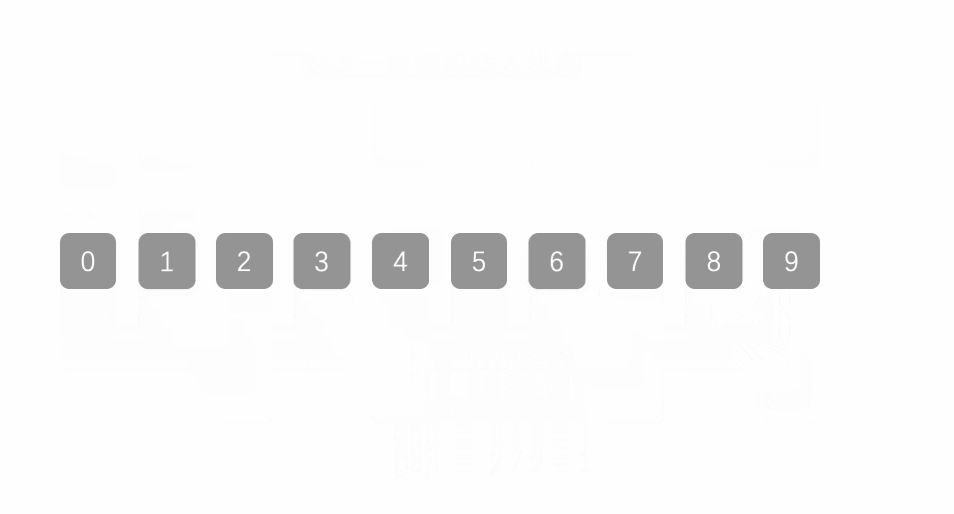
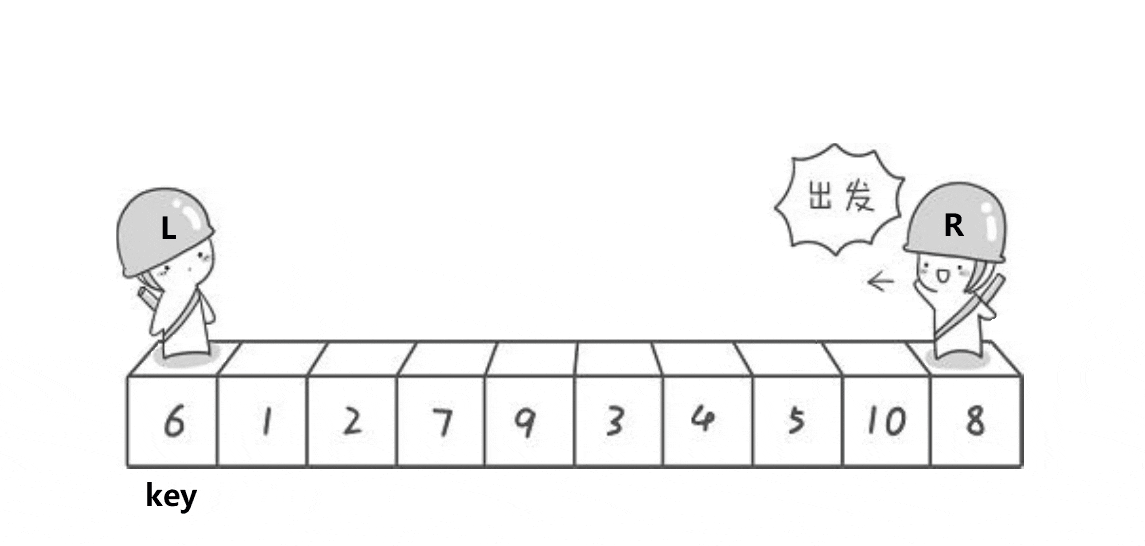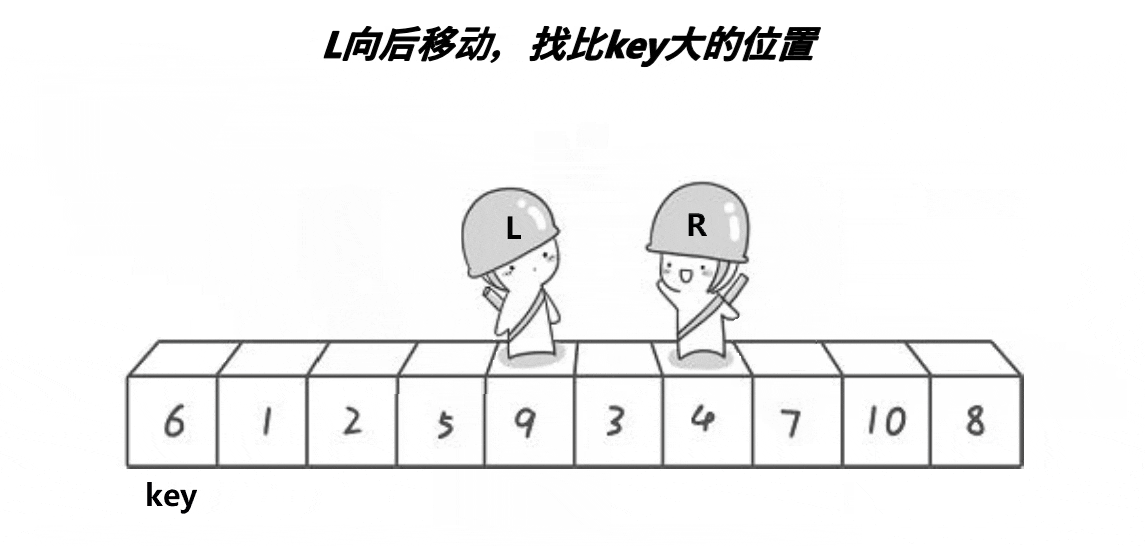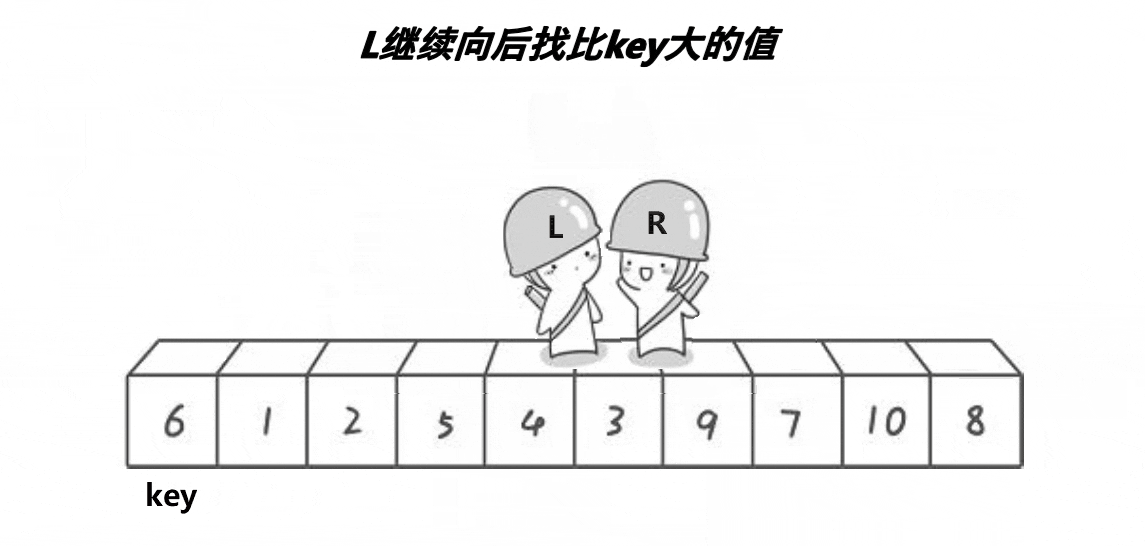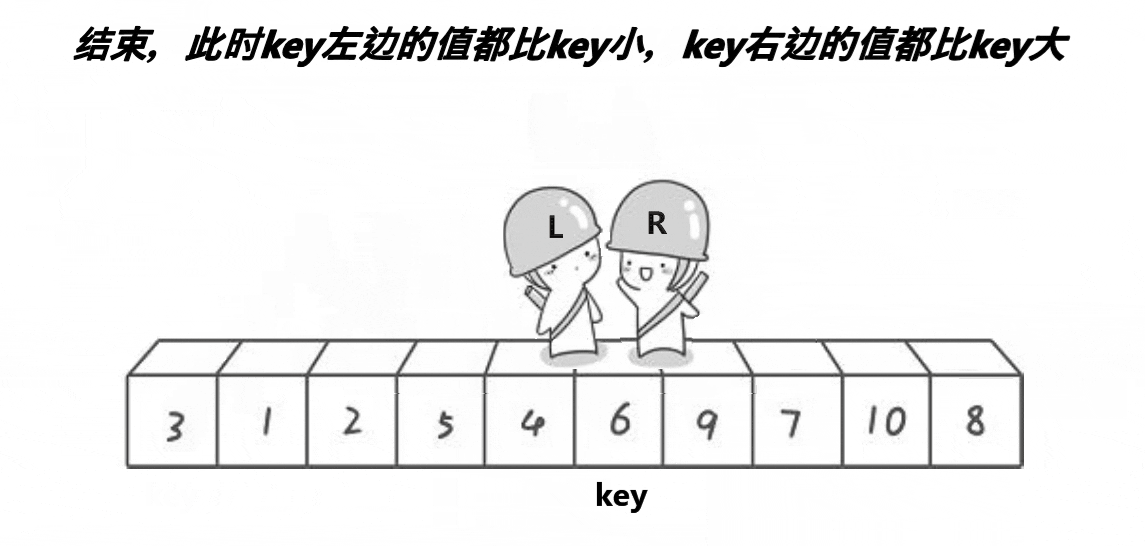
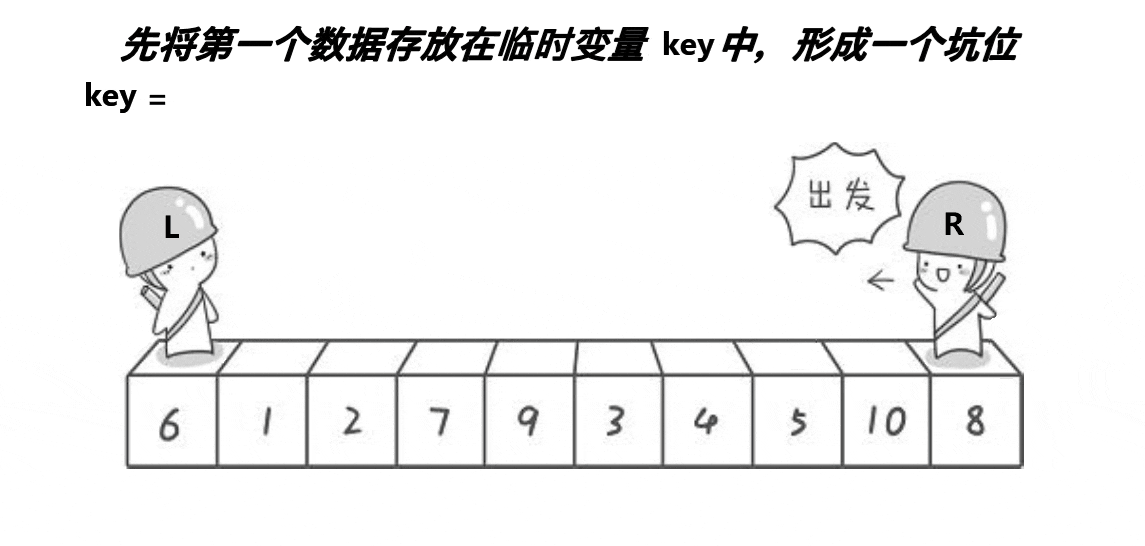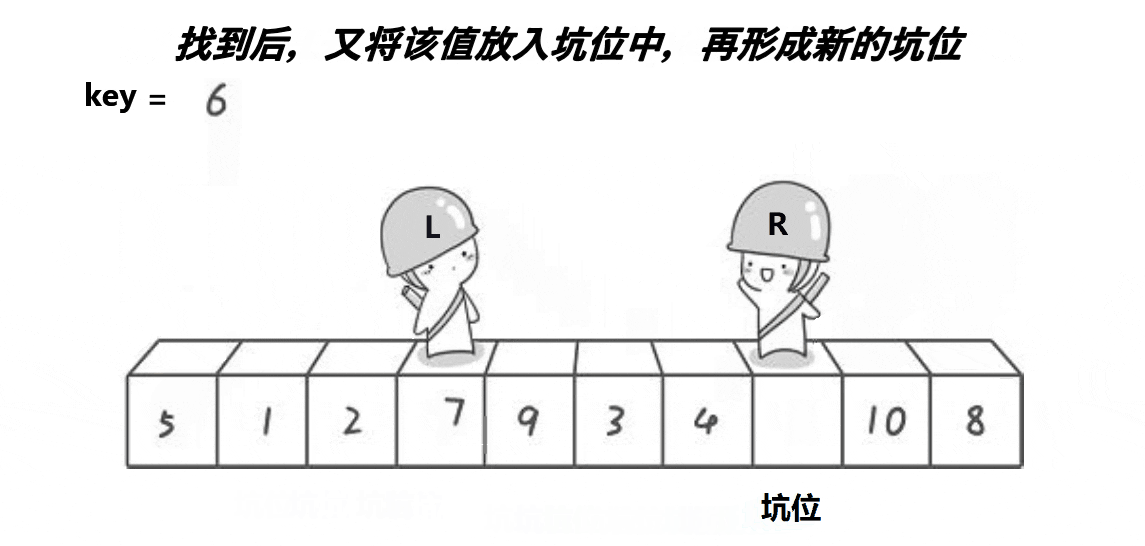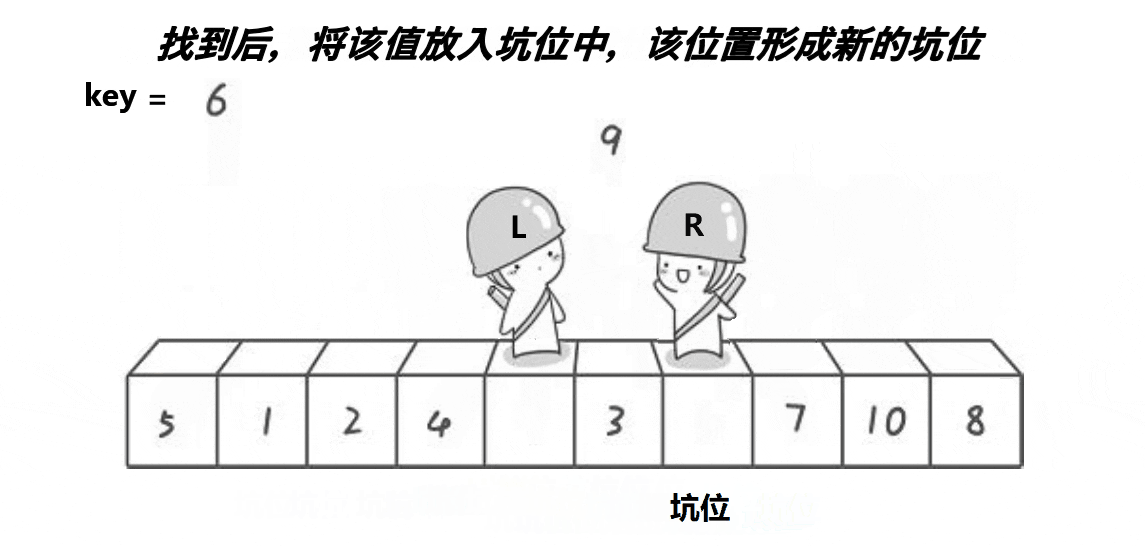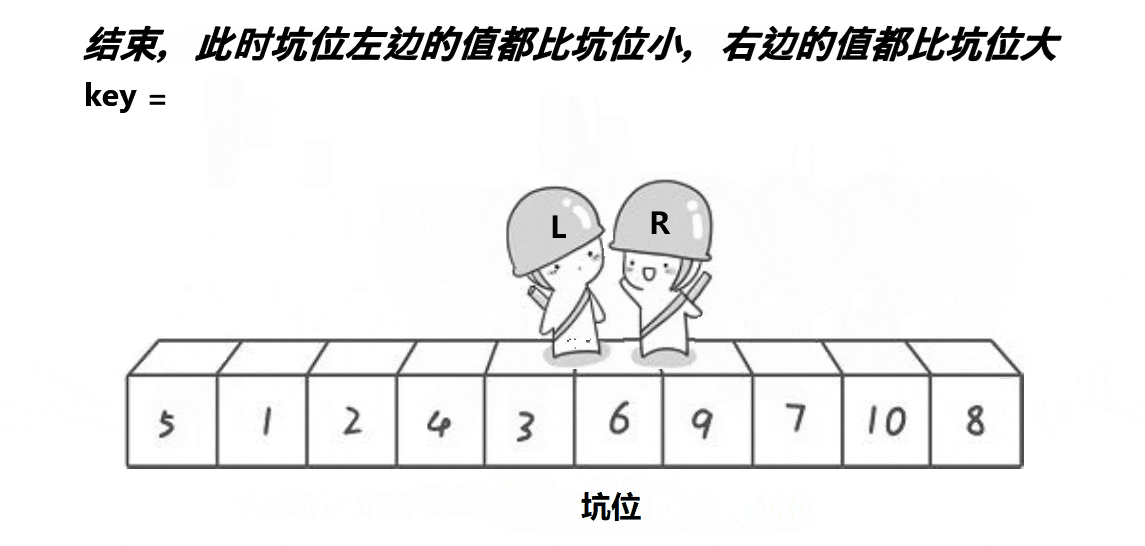
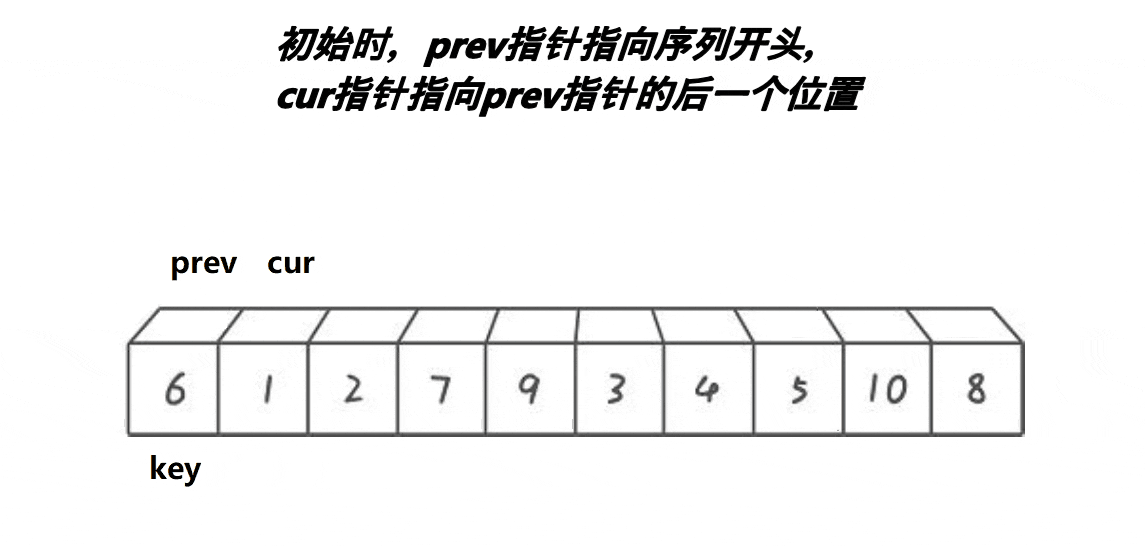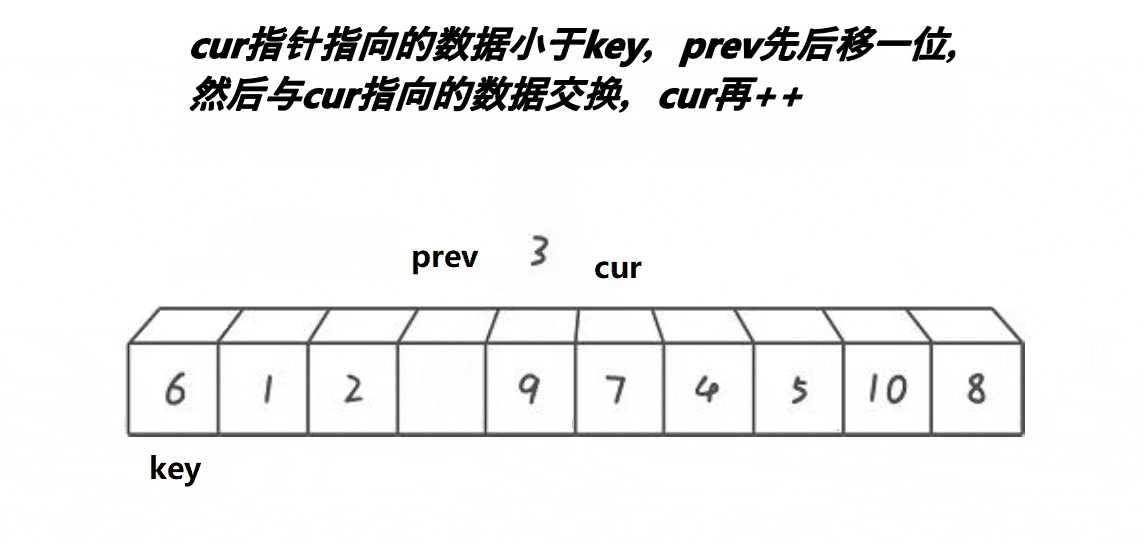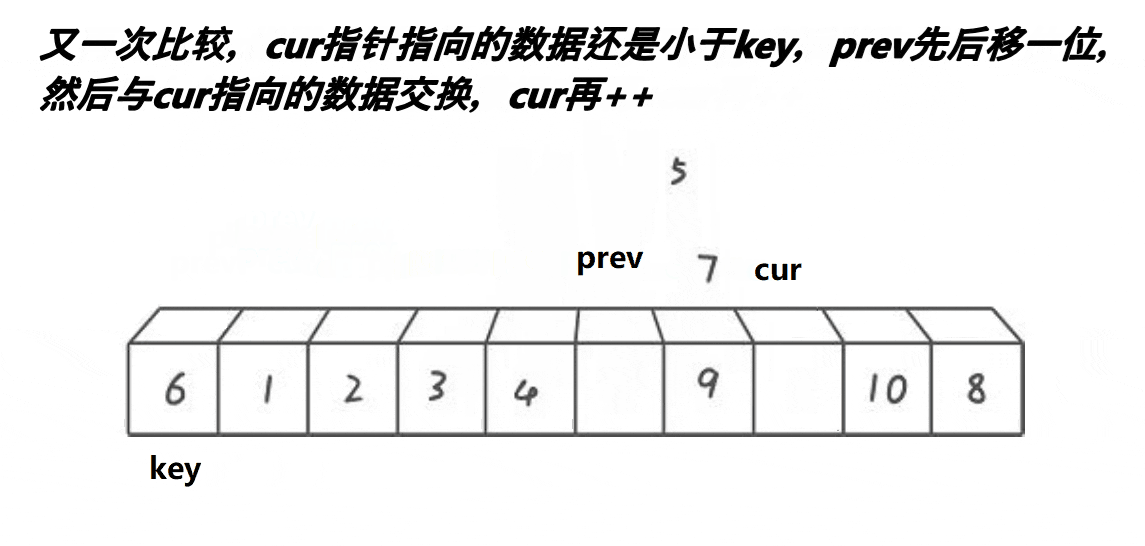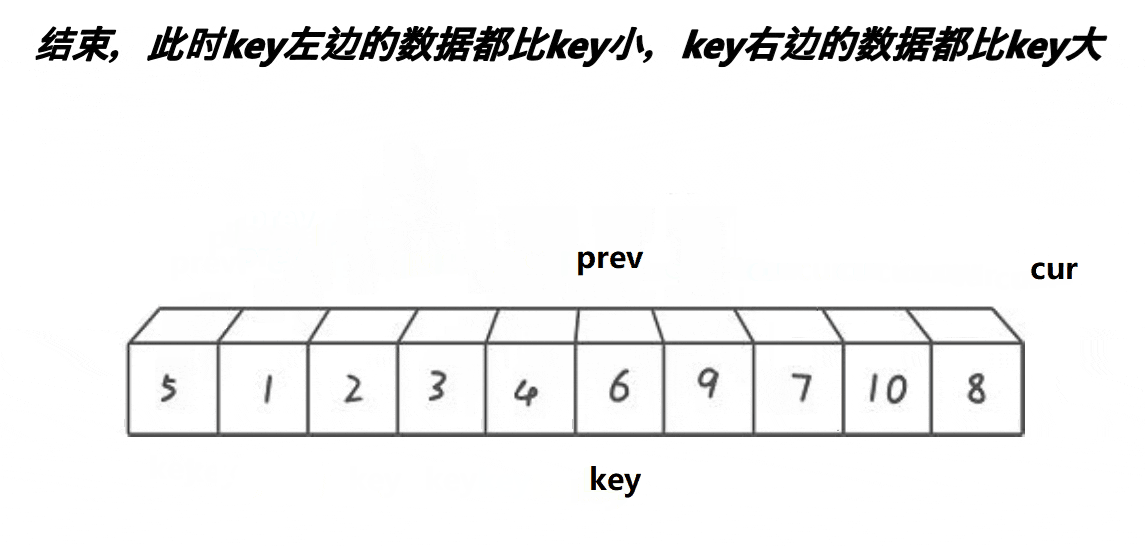
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个小于N的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作。当 gap == 1时,就相当整个序列被分到一组,进行一次直接插入排序,排序完成。
cpp复制代码
// O(N^1.3)
// 希尔排序
void ShellSort(int* a, int n) {
int gap = n;
while (gap > 1) {
// gap > 1时是预排序
// gap == 1时是插入排序
gap = gap / 3 + 1;// +1保证最后一个gap一定是1
for (int i = 0; i < n - gap; i++) {
int end = i;
int tmp = a[end + gap];
while(end >= 0){
if (tmp < a[end]) {
a[end + gap] = a[end];
end -= gap;
}
else {
break;
}
}
a[end + gap] = tmp;
}
}
}
// O(N^2)
// 选择排序
void SelectSort(int* a, int n) {
int begin = 0;
int end = n - 1;
while (begin < end) {
int mini = begin;
int maxi = end;
for (int i = begin; i <= end; i++) {
if (a[i] > a[maxi]) {
maxi = i;
}
if (a[i] < a[mini]) {
mini = i;
}
}
Swap(&a[mini], &a[begin]);
if (maxi == begin) {
maxi = mini;
}
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right) {
Stack st;
StackInit(&st);
StackPush(&st, right);
StackPush(&st, left);
while (!StackEmpty(&st)) {
int begin = StackTop(&st);
StackPop(&st);
int end = StackTop(&st);
StackPop(&st);
int keyi = PartSort2(a, begin, end);
if (end > keyi + 1) {
StackPush(&st, end);
StackPush(&st, keyi + 1);
}
if (begin < keyi - 1) {
StackPush(&st, keyi - 1);
StackPush(&st, begin);
}
}
StackDestroy(&st);
}
七、 归并排序
7.1 递归实现
思路:
不断的分割数据,让数据的每一段都有序(一个数据相当于有序)
当所有子序列有序的时候,在把子序列归并,形成更大的子序列,最终整个数组有序。
cpp复制代码
// 时间复杂度:O(N*logN)
// 空间复杂度:O(N)
// 归并排序递归实现
void _MergeSort(int* a, int* tmp, int left, int right) {
if (left == right) {
return;
}
int midi = (left + right) / 2;
_MergeSort(a, tmp, left, midi);
_MergeSort(a, tmp, midi + 1, right);
int begin1 = left;
int end1 = midi;
int begin2 = midi + 1;
int end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2) {
if (a[begin1] < a[begin2]) {
tmp[i++] = a[begin1++];
}
else {
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1) {
tmp[i++] = a[begin1++];
}
while (begin2 <= end2) {
tmp[i++] = a[begin2++];
}
memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n) {
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc");
exit(1);
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp == NULL;
}
7.2 非递归实现
cpp复制代码
// 归并排序非递归实现
void MergeSortNonR(int* a, int n) {
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc");
exit(1);
}
int gap = 1;
while (gap < n) {
for (int i = 0; i < n; i += 2 * gap) {
int begin1 = i;
int end1 = i + gap - 1;
int begin2 = i + gap;
int end2 = i + 2 * gap - 1;
if (begin2 > n - 1) {
break;
}
if (end2 > n - 1) {
end2 = n - 1;
}
int j = i;
while (begin1 <= end1 && begin2 <= end2) {
if (a[begin1] < a[begin2]) {
tmp[j++] = a[begin1++];
}
else {
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1) {
tmp[j++] = a[begin1++];
}
while (begin2 <= end2) {
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
tmp == NULL;
}
归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
时间复杂度:O(N*logN)
空间复杂度:O(N)
稳定性:稳定
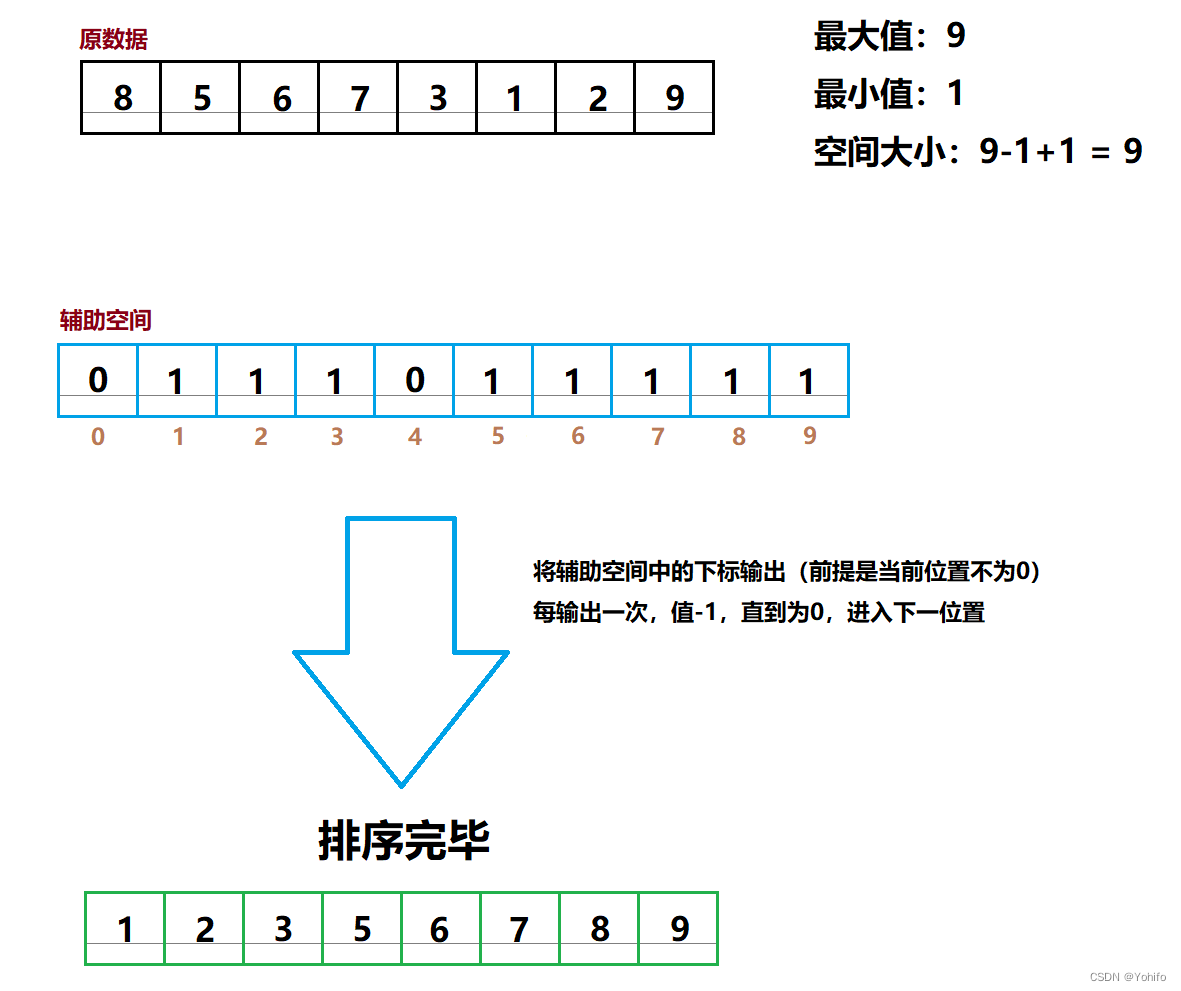
八、计数排序
一种特殊的排序,唯一种没有比较的排序(指没有前后比较,还是有交换的)
体现的是映射思维。
cpp复制代码
// 计数排序
void CountSort(int* a, int n) {
int max = a[0];
int min = a[0];
for (int i = 0; i < n; i++) {
if (a[i] > max) {
max = a[i];
}
if (a[i] < min) {
min = a[i];
}
}
int range = max - min + 1;
int* count = (int*)calloc(range, sizeof(int));
if (count == NULL)
{
perror("calloc");
exit(1);
}
for (int i = 0; i < n; i++) {
count[a[i] - min]++;
}
int j = 0;
for (int i = 0; i < range; i++) {
while (count[i]--) {
a[j] = i + min;
}
}
free(count);
count = NULL;
}