【番外篇:快速排序的前世今生】目录
- 前言:
- ---------------起源---------------
- ---------------发展---------------
-
- [1. 早期版本:简单但不稳定](#1. 早期版本:简单但不稳定)
-
- [1960 年:初始版本](#1960 年:初始版本)
- [2. 基准值优化:打破最坏情况](#2. 基准值优化:打破最坏情况)
-
- [1970 年代:随机化基准](#1970 年代:随机化基准)
- [1970 年代末:三数取中法](#1970 年代末:三数取中法)
- 3.分区优化:减少递归开销
-
- [1977 年:三路快速排序](#1977 年:三路快速排序)
- [1980 年代:小数组优化](#1980 年代:小数组优化)
- [1997 年:内省排序](#1997 年:内省排序)
- [2009 年:双路快速排序](#2009 年:双路快速排序)
- ---------------实现---------------
- 一、实现:三路快速排序
- 二、实现:内省排序
- ---------------实践---------------
- [912. 排序数组(https://leetcode.cn/problems/sort-an-array/)](#912. 排序数组)
- ---------------结语---------------

往期《数据结构初阶》回顾:
【时间复杂度 + 空间复杂度】
【顺序表 + 单链表 + 双向链表】
【顺序表/链表 精选15道OJ练习】
【顺序栈 + 链式队列 + 循环队列】
【链式二叉树】
【堆 + 堆排序 + TOP-K】
【二叉树 精选9道OJ练习】
【八大排序------群英荟萃】
【八大排序------巅峰决战】
前言:
🎉Hi~小伙伴们!(ノ◕ヮ◕)ノ*:・゚✧
在上一集中,我们【沉浸式】围观了八大排序算法的巅峰对决🔥,经过多轮实测比拼⚔️,最终由快速排序摘得冠军🏆,成为当之无愧的"排序王者"👑
常言道:
"台上一分钟,台下十年功。"看似光鲜的冠军背后✨,必有一段不寻常的成长历程📈所以说快速排序能登上排序算法的巅峰,肯定也经历了从理论雏形到工程优化的漫长蜕变🌱
那么今天,我们就沿着时间的脉络⏳,走进快速排序的 "前世今生",探寻其诞生与发展的秘密吧(๑•̀ㅂ•́)و✧ 🔍!
---------------起源---------------
一、诞生:
快速排序(Quicksort):由英国计算机科学家托尼・霍尔(Tony Hoare)在 1960 年发明
- 当时霍尔年仅 25 岁,受英国国家物理实验室派遣,赴莫斯科国立大学研究机器翻译时,为了解决俄语词序的随机排列问题,灵光一现发明了快速排序。
- 1961 年,他在《计算机学报》(Communications of the ACM)上发表论文《Quicksort》,正式将这一算法引入学术界。
- 快速排序也被称为
"20 世纪十大算法"之一,霍尔因其贡献获得 1980 年图灵奖(Turing Award),评委会称其 "对算法理论和编程实践产生了深远影响"。- 因其平均性能优异且空间效率高,快速排序同时也是 C++ 标准库
std::sort、Java 标准库Arrays.sort的核心算法。
二、突破:
快速排序的关键突破:
分治策略:将数组分成两部分,通过选择一个 "基准值( p i v o t pivot pivot)",将小于基准的元素放在左边,大于基准的放在右边,再递归排序左右子数组。原址排序:无需额外存储大量中间数据,空间复杂度为 O ( l o g n ) O(log n) O(logn)(递归栈空间),适合处理大规模数据。
三、核心:
快速排序的三大法则:
基准(Pivot):随机选中一个元素作为分界线分区(Partition):把数组拆成「小值左子数组」和「大值右子数组」递归(recursion):对左右子数组重复上述操作"快速排序就像一位优雅的剑客------看似随意挥剑,实则每一击都将问题一分为二"
---------------发展---------------
快速排序的性能核心,在于每次单趟排序时基准值( k e y key key)对数组的划分效果
若每次选择的基准值都能将数组近乎二等分,其递归树就会形成均匀的满二叉树,此时算法性能最优
若每次选取的基准值都是数组中的最小值或最大值,数组会被划分为 0 0 0 个元素和 N − 1 N-1 N−1 个元素的子问题,时间复杂度将退化为 O ( N 2 ) O (N²) O(N2)
在实际应用中,有多种数据特性会显著影响快速排序对数组的划分效果,其中
数据有序性和重复元素分布是两个关键因素:
数据完全有序或近乎有序:当待排序数组呈现升序、降序,或大部分元素已处于有序状态时
- 若采用默认的固定基准选取策略(如:首元素),会导致每次分区极度不平衡 ------ 一侧子数组为空,另一侧包含全部剩余元素。
- 这将使快速排序的时间复杂度从理想的 O ( n l o g n ) O(nlog n) O(nlogn)退化为 O ( n 2 ) O(n^2) O(n2),性能大幅下降。
数组存在大量重复数据:当待排序数组中重复元素占比较高时
- 传统快速排序容易将重复值集中分配到某一个子数组中,造成分区失衡。
- 例如:若基准值恰好为重复元素,可能会使一侧子数组规模远大于另一侧,导致递归树深度增加,同样引发性能恶化。
快速排序的发展历程,本质上就是针对上述问题不断优化迭代的过程。
- 从
基准值随机化、三数取中解决数据有序性导致的最坏情况- 到
三路快速排序、双路快速排序专门应对重复数据场景每一次改进都在拓展快速排序的适用边界,使其在复杂数据环境下仍能保持高效稳定。
1. 早期版本:简单但不稳定
1960 年:初始版本
提出者 :英国 托尼・霍尔(Tony Hoare)
- 最初的快速排序采用固定基准值(如:第一个元素),这导致在最坏情况下(如:数组已排序)时间复杂度退化为 O ( n 2 ) O(n^2) O(n2)
- 尽管平均时间复杂度为 O ( n l o g n ) O(nlog n) O(nlogn),但实际应用中仍存在性能瓶颈。
2. 基准值优化:打破最坏情况
1970 年代:随机化基准
思想:随机选择基准值,而非固定位置(如:首元素)破局:将最坏情况(如:有序数组)的概率降至极低,确保实际应用中平均性能稳定,避免因数据分布导致的性能暴跌影响:使快速排序的平均性能更稳定,成为工业界标准实现的核心优化
1970 年代末:三数取中法
思想:取数组首、中、尾元素的中位数作为基准,减少极端数据,尤其在数组已经有序的情况下。破局:进一步优化有序、逆序或重复数据的分区效果,提升排序稳定性。影响:被早期 C 库qsort采用,成为工程实践中平衡数据分布的经典方法。
3.分区优化:减少递归开销
1977 年:三路快速排序
提出者 :荷兰 艾兹格·迪杰斯特拉(Edsger Dijkstra)
思想:将数组划分为 "小于基准"、"等于基准"、"大于基准" 三部分,对重复元素直接跳过递归,仅排序小于和大于基准的部分破局:处理大量重复元素(如:{3,3,2,3,4})时,时间复杂度优化为 O ( n ) O(n) O(n)(重复元素占比高时),避免无效递归影响:被 Pythonsorted()、C++std::stable_sort(部分实现)采用,成为处理重复数据的标准解法
1980 年代:小数组优化
思想:当子数组长度小于阈值(如:16)时,切换为插入排序(利用插入排序在小规模数据上的常数因子优势)破局:减少递归开销,提升小规模数据的排序速度,优化实际运行效率影响:成为所有高效排序算法的标配优化(如:归并排序、堆排序也采用类似策略),广泛应用于工业级代码
1997 年:内省排序
提出者 :美国 大卫・R・穆瑟(David R. Musser)
思想:结合快速排序、堆排序、插入排序:
- 递归深度超过 O ( l o g n ) O(log n) O(logn) 时(触发最坏情况预警),切换为
堆排序(确保最坏时间复杂度 O ( n l o g n ) O(nlog n) O(nlogn)- 子数组长度小于阈值时,切换为
插入排序破局:彻底解决快速排序的最坏情况问题,确保绝对稳定的 O ( n l o g n ) O(nlog n) O(nlogn) 时间复杂度,适用于所有数据分布影响:成为 C++std::sort的标准实现,奠定现代工业级排序算法的基础,被广泛应用于 C++ 标准库
2009 年:双路快速排序
提出者 :俄罗斯 弗拉基米尔・雅罗斯拉夫斯基(Vladimir Yaroslavskiy)
思想:使用两个基准值(通常取首、尾元素),将数组划分为三部分:<pivot1、[pivot1, pivot2]、>pivot2,减少递归深度破局:在均匀分布数据中,分区更平衡,递归次数更少,提升平均性能,尤其适用于基本数据类型排序影响:被 Java 7Arrays.sort(基本类型排序)采用,成为 JVM 排序的核心优化,提升 Java 语言的排序性能
---------------实现---------------
一、实现:三路快速排序
什么是三路快速排序?
三路快速排序(3-Way QuickSort):是快速排序的高效变种,专门用于处理含有大量重复元素的数组。
- 它通过将数组划分为三个部分(小于、等于和大于基准值的元素)来优化性能,相比传统快速排序能显著减少重复元素的重复比较和交换操作。
三路快速排序的核心思想是什么?
三路快速排序的核心思想:
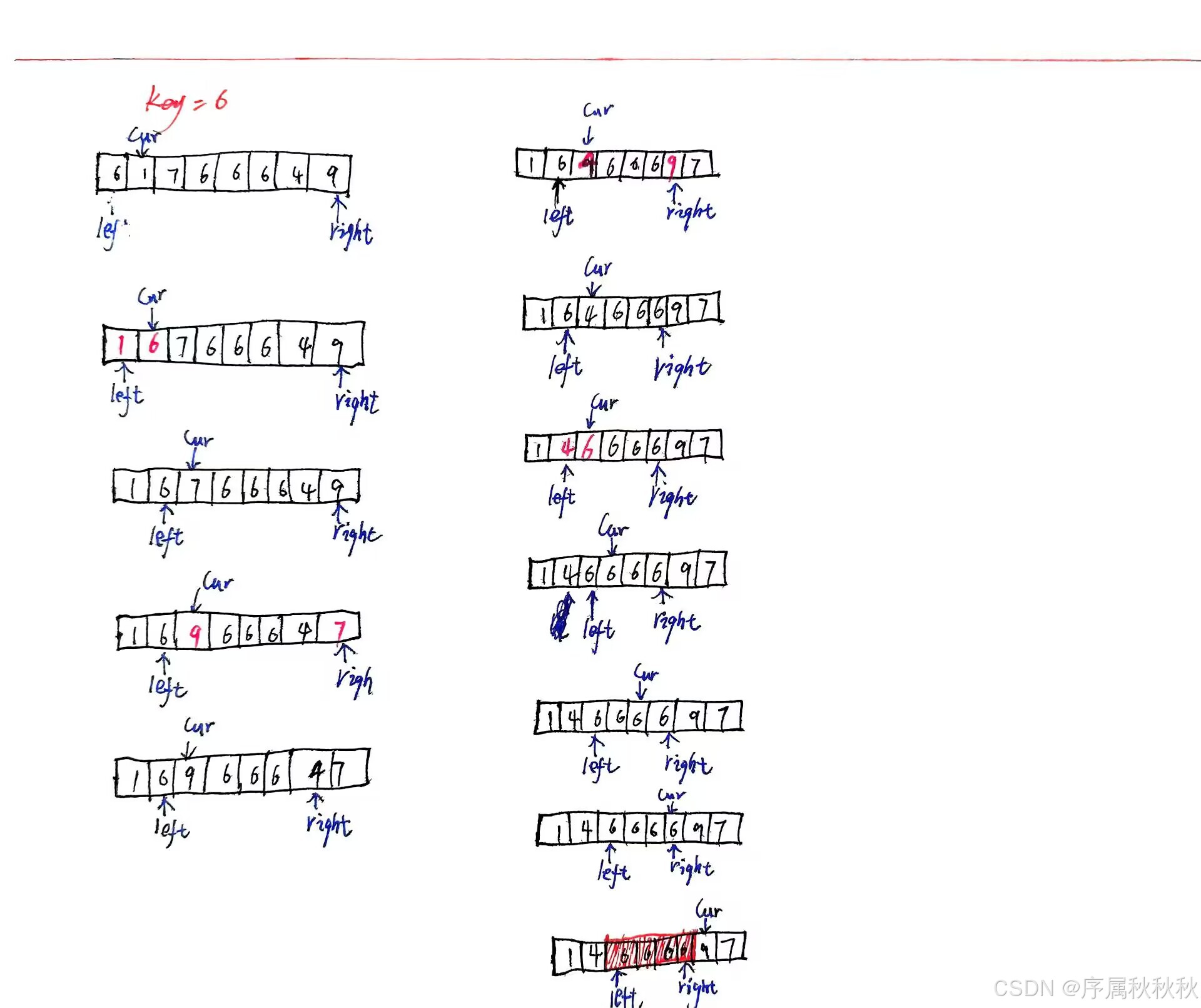
- 选择基准值 :取区间最左元素作为基准值,即:
key = a[left]- 初始化指针 :
lt = left:指向小于基准值区间的右边界(初始为基准值位置)gt = right:指向大于基准值区间的左边界(初始为区间末尾)cur = left + 1:当前遍历指针,从基准值右侧开始扫描- 遍历与交换(当
cur <= gt时循环) :
- 若acur < key:
- 将
a[cur]与a[lt]交换,使该元素进入小于区lt++(小于区右边界右移),cur++(继续扫描下一个元素)- 若acur > key:
- 将
a[i]与a[gt]交换,使该元素进入大于区gt--(大于区左边界左移),cur不移动(交换后的a[cur]需重新判断与key的大小关系)- 若acur == key:
- 直接跳过
i++(该元素留在等于区)- 递归排序 :
- 对小于区 (
left至lt - 1)递归调用三路快排- 对大于区 (
gt + 1至right)递归调用三路快排- 对等于区 (
lt至gt)无需处理,已自然有序
怎么实现三路快速排序?
温馨提示:下面的程序文件中,不仅包含我们接下来要实现的"三路快速排序",还涵盖了之前已实现的其他三个快速排序版本,所以说下面的文件中将会展示快速排序的四种实现版本:
Hoare版------快速排序lomuto版------快速排序挖坑版------快速排序三路划分版------快速排序
头文件:QuickSort3Way.h
c
#pragma once
//任务1:包含要使用的头文件
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <stdbool.h>
//任务2:定义三路划分的中间区间的结构体
typedef struct
{
//1.记录基准值的左边界
//2.记录基准值的右边界
int leftKeyIdx;
int rightKeyIdx;
}KeyWayIdx;
//任务2:声明工具函数
//1.数组中两个元素的交换
//2.数组的打印
void Swap(int* a, int* b);
void PrintArray(int* a, int n);
//任务3:声明快排的不同的分区算法的函数
//1.Hoare分区算法
//2.lomuto分区算法
//3.挖坑分区算法
//4.三路划分分区算法
int PartSort1(int* a, int left, int right);
int PartSort2(int* a, int left, int right);
int PartSort3(int* a, int left, int right);
KeyWayIdx QuickSort3Way(int* a, int left, int right);
//任务4:声明快速排序的函数
void QuickSort(int* a, int left, int right);实现文件:QuickSort3Way.c
c
#include "QuickSort3Way.h"
/*-----------------------工具函数-----------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/**
* @brief 打印数组
* @param a 数组指针
* @param n 数组长度
*/
//2.实现:"数组的打印"的工具函数
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
/*----------------------hoare对撞指针分区算法----------------------*/
/**
* @brief Hoare分区法(快速排序的核心分区算法)
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return int 返回基准值的最终位置
*
* @note 算法思想:
* 1. 选取最左元素作为基准值(key)
* 2. 从右向左找比key小的元素
* 3. 从左向右找比key大的元素
* 4. 交换这两个元素
* 5. 重复2-4直到左右指针相遇
* 6. 将基准值放到最终位置
*/
int PartSort1(int* a, int left, int right)
{
//1.直接选取最左左边的元素的作为基准值
int key = left;
//2.使用while循环遍历整个数组
while (left < right)
{
///2.1:从右向左找第一个小于基准值的元素
while (left < right && a[right] >= a[key])
{
right--;
}
//2.2:从左向右找第一个大于基准值的元素
while (left < right && a[left] <= a[key])
{
left++;
}
//注意:左右指针在借助基准值的索引找到要交换的元素之前,基准值的位置并未发生改变 ---> 我们使用a[key]还可以找到基准值,那么我们就可以使用key代表基准值的索引
Swap(&a[left], &a[right]);
}
//3.将基准值放在合适的位置上
Swap(&a[key], &a[left]);
//4.返回基准值的位置
return left;
}
/*----------------------------lomuto快慢指针分区算法----------------------------*/
/**
* @brief 前后指针分区法(快速排序的另一种分区实现)
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return int 返回基准值的最终位置
*
* @note 算法思想:
* 1. 选取最左元素作为基准值(key)
* 2. prev指向小于key的区域的最后一个元素
* 3. cur遍历整个分区
* 4. 当cur找到比key小的元素时,先移动prev再交换
* 5. 最后将基准值放到prev位置
*/
int PartSort2(int* a, int left, int right)
{
//1.定义一个变量记录基准值的索引
int key = left;
//2.定义一个慢指针:用于指向最后一个小于基准值的元素
int slow = left;
//3.定义一个快指针:用于遍历整个分区
int fast = left + 1;
//4.使用while循环遍历整个数组
while (fast <= right)
{
//4.1:当fast指针遍历到的元素小于基准值的时候的,将其交换到数组的左边
if (a[fast] < a[key])
{
if (a[fast] != a[slow]) //注意:避免不必要的交换
{
slow++; //注意:slow始终指向最后一个小于基准值(a[key])的元素
Swap(&a[fast], &a[slow]); //目的:将<基准值的a[fast]交换到slow指针指向的位置(因为:此时slow指针指向的位置的值一定>=key)
}
}
fast++; //当遍历到的元素的值 >= 基准值的时候,只需要将fast指针向后移动即可
}
//5.将基准值交换到最终的位置(未进行交换前:slow指向最后一个小于基准的元素)
Swap(&a[key], &a[slow]);
//6.返回当前基准值的下标
return slow;
}
/*--------------------------------挖坑分区算法--------------------------------*/
int PartSort3(int* a, int left, int right)
{
//1.进行基准值优化:随机化基准值的选取
int mid = left + (rand() % (right - left));
//2.将找到的基准值放在左边界
Swap(&a[left], &a[mid]);
//3.定义一个变量记录基准值(注意这里保存值而不是索引)
int key = a[left]; //特别注意:这的key存储的不再是基准值的下标,而是直接存储的基准值,这是为什么呢?(下面的注释博主有详细的解释,请继续往下看......)
//4.定义一个变量记录坑位
int hole = left;
//5.定义两个临时变量从区间的两端向中间进行扫描 ---> 高效地将数组分为两部分
int begin = left, end = right;
//6.进行分区
while (begin < end)
{
//6.1:从右向左寻找第一个小于基准的值
while (begin < end && a[end] >= key)
{
end--;
}
//6.2:找到后填左坑,end成为新坑
a[hole] = a[end]; //特别注意:这里while循环结束后并不是紧接又是一个while循环,而是做填坑、挖坑的操作,也恰恰是这个填坑、挖坑的操作使得基准值的下标已经发生了改变
hole = end; //所以说:我们下面就不可以使用a[key](假设:key存储的还是基准值的下标)的方式来得到基准值了,
//6.3:从左向右寻找第一个大于基准的值
while (begin < end && a[begin] <= key)
{
begin++;
}
//6.4:找到后填右坑,left成为新坑
a[hole] = a[begin];
hole = begin;
}
//7.最后将基准值填入最后的坑位
a[hole] = key;
//8.返回当前基准值的下标
return hole;
}
/*--------------------------------三路划分分区算法--------------------------------*/
/**
* @brief 三路划分快速排序的核心分区函数
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return KeyWayIdx 包含等于基准值区间的左右边界
*
* @details
* 将数组划分为三个部分:
* 1. [left, leftKeyIdx-1] 小于基准值
* 2. [leftKeyIdx, rightKeyIdx] 等于基准值
* 3. [rightKeyIdx+1, right] 大于基准值
*/
//3.实现:"三路划分快速排序"的算法
KeyWayIdx QuickSort3Way(int* a, int left, int right)
{
//1.选择最左边的元素作为基准值
int key = a[left];
//2.定义遍历数组的指针
int curr = left + 1;
//3.使用curr指针循环遍历数组
while (curr <= right)
{
//3.1:如果遍历到的当前元素 < 基准值,则将其交换到左边
if (a[curr] < key)
{
//3.1.1:
Swap(&a[curr], &a[left]); //注意:这里基准值的位置会发生改变,所以我们的key存储的基准值而不是基准值的下标
//3.1.2:
left++; //注意:这里基准值的下标会发生改变,所以我们的key存储的基准值而不是基准值的下标
//3.1.3:
curr++; //注意:这里可以直接将curr进行++的原因是 ---> 经过交换后此时a[curr]==key ,它已经处于正确的位置(中间区间)
//所以可以直接跳过(++cur),继续检查下一个元素
}
//3.2:如果遍历到的当前元素 > 基准值,则将其交换到右边
else if (a[curr] > key)
{
//3.2.1:
Swap(&a[curr], &a[right]);
//3.2.2:
right--;
//这里为什么没有curr++呢?----> 因为交换过来的元素还未检查(我们并不知道a[right]的值和基准值key的大小关系)
}
//3.3:
else
{
curr++; //当前元素等于基准值,直接跳过
}
}
//4.创建中间区间的结构体,并为其初始化
KeyWayIdx kwi;
kwi.leftKeyIdx = left;
kwi.rightKeyIdx = right;
return kwi;
}
/*---------------------------快排主函数(递归实现)---------------------------*/
void QuickSort(int* a, int left, int right)
{
//1.递归终止条件
if (left >= right) return;
//2.可以根据需要选择性的在这里添加小区间优化(比如:之前已经实现过了插入排序就可以在这里进行小区间优化了)
/*-------------------版本一:可以调用:hoare、lomuto、挖坑分区算法-------------------*/
//3.定义一个变量接收基准值的位置
//注:这里你可以使用你之前实现的任意的一个分区算法
/*-------------使用:hoare分区算法-------------*/
//int key = PartSort1(a, left, right);
/*-------------使用:lomuto分区算法-------------*/
//int key = PartSort2(a, left, right);
/*-------------使用:挖坑分区算法-------------*/
//int key = PartSort3(a, left, right);
//4.递归排序左右子区间
//QuickSort(a, left, key - 1);
//QuickSort(a, key + 1, right);
/*-------------------版本二:可以调用:三路划分分区算法-------------------*/
//3.定义一个结构体接受中间区间的结构体
KeyWayIdx kwi = QuickSort3Way(a, left, right);
//4.递归排序左右子区间
QuickSort(a, left, kwi.leftKeyIdx - 1);
QuickSort(a, kwi.rightKeyIdx + 1, right);
//注意:kwi.leftKeyIdx 到 kwi.rightKeyIdx 之间的元素已等于基准值,无需处理!
}测试文件:Test.c
c
#include "QuickSort3Way.h"
/*------------------------------------测试辅助函数------------------------------------*/
// 判断数组是否有序
bool isSorted(int* arr, int size)
{
for (int i = 0; i < size - 1; i++)
{
if (arr[i] > arr[i + 1])
{
return false;
}
}
return true;
}
// 生成随机数组
void generateRandomArray(int* arr, int size, int range)
{
srand((unsigned int)time(NULL));
for (int i = 0; i < size; i++)
{
arr[i] = rand() % range;
}
}
/*------------------------------------测试用例设计------------------------------------*/
/*-----------用例1:含重复元素的随机数组(三路快排优势场景)-----------*/
void testDuplicateElements()
{
printf("===== 测试重复元素数组 =====\n");
int arr[] = { 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过:重复元素数组已正确排序\n");
else
printf("测试失败:重复元素未正确处理\n");
printf("\n");
}
/*------------------用例2:全相同元素数组(边界测试)------------------*/
void testAllIdentical()
{
printf("===== 测试全相同数组 =====\n");
int arr[] = { 7, 7, 7, 7, 7, 7 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过:全相同数组保持有序\n");
else
printf("测试失败:全相同数组异常\n");
printf("\n");
}
/*------------------用例3:已排序数组(最佳情况测试)------------------*/
void testAlreadySorted()
{
printf("===== 测试已排序数组 =====\n");
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
{
printf("测试通过:已排序数组保持有序\n");
}
else
{
printf("测试失败:已排序数组被破坏\n");
}
printf("\n");
}
/*------------------用例4:逆序数组(最坏情况测试)------------------*/
void testReverseSorted()
{
printf("===== 测试逆序数组 =====\n");
int arr[] = { 9, 8, 7, 6, 5, 4, 3, 2, 1 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过:逆序数组已正确排序\n");
else
printf("测试失败:逆序数组未正确排序\n");
printf("\n");
}
/*------------------用例5:大数组性能测试(10万元素)------------------*/
void testLargeArrayPerformance()
{
printf("===== 大数组性能测试 =====\n");
const int size = 100000;
int* arr = (int*)malloc(size * sizeof(int));
generateRandomArray(arr, size, size / 10); // 刻意增加重复率
clock_t start = clock();
QuickSort(arr, 0, size - 1);
clock_t end = clock();
double elapsed = (double)(end - start) / CLOCKS_PER_SEC;
printf("排序%d个元素耗时: %.3f秒\n", size, elapsed);
if (isSorted(arr, size))
printf("排序结果正确\n");
else
printf("排序结果错误\n");
free(arr);
printf("\n");
}
/*------------------主测试函数------------------*/
int main()
{
// 核心功能测试
testDuplicateElements();
testAllIdentical();
testAlreadySorted();
testReverseSorted();
// 性能测试
testLargeArrayPerformance();
printf("====== 三路快速排序测试完成 ======\n");
return 0;
}运行结果
二、实现:内省排序
什么是内省排序?
内省排序(Introsort,也称内省式排序 introspective sort):是一种结合了快速排序、堆排序和插入排序优势的混合排序算法
- 主要用于解决快速排序在最坏情况下时间复杂度退化到 O ( n 2 ) O(n^2) O(n2) 的问题,同时保持快速排序在平均情况下的高效性。
- 它结合了快速排序 、堆排序 和插入排序 的优点,通过动态切换排序策略来确保在各种情况下都能达到 O ( n l o g n ) O(nlogn) O(nlogn) 的时间复杂度。
内省排序的核心思想是什么?
内省排序的核心思想 :通过监测递归深度来避免快速排序的最坏情况,具体策略如下:
快速排序为主:首先使用快速排序进行排序,利用其平均情况下的高效性 O ( n l o g n ) O(nlog n) O(nlogn)
堆排序切换:当递归深度超过一定阈值(通常为 2 l o g n 2logn 2logn, n n n 为待排序元素数量)时,说明数据可能退化为最坏情况(如:完全有序数组),此时切换为堆排序 。
- 堆排序的时间复杂度始终为 O ( n l o g n ) O(nlog n) O(nlogn),虽然常数因子较大,但能保证最坏情况下的性能。
插入排序优化:当待排序序列长度较小时(如:小于某个阈值,通常为 16 16 16),切换为插入排序,利用其在小规模数据下的高效性。
内省排序的算法步骤:确定递归深度阈值 :阈值通常设为 2 × log 2 n 2 \times \log_2 n 2×log2n( n n n 为数组长度),用于判断是否切换为堆排序
快速排序递归 :
- 选择基准值(如:三数取中法),将数组划分为左右两部分。
- 对左右子数组递归调用内省排序,同时记录当前递归深度。
- 若递归深度超过阈值,停止快速排序,转为堆排序。
堆排序处理 :对当前子数组构建最大堆,然后通过堆排序完成排序,确保最坏情况下时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
插入排序优化 :当子数组长度小于阈值(如: 16 16 16)时,直接使用插入排序,减少递归开销
怎么实现内省排序
头文件:IntroSort.h
c
#pragma once
//任务1:包含要使用的头文件
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <stdbool.h>
//任务2:声明工具函数
//1.数组中两个元素的交换
//2.数组的打印
//3.堆的向向下调整算法
void Swap(int* a, int* b);
void PrintArray(int* a, int n);
void AdjustDown(int* a, int parent, int n);
//任务3:声明内省排序以及其它的辅助排序
//1.快排进阶 ----> 内省排序
void QuickSort(int* a, int left, int right);
//2.内省排序的辅助排序:插入排序 + 堆排序
void InsertSort(int* a, int n);
void HeapSort(int* a, int n);实现文件:IntroSort.c
c
#include "IntroSort.h"
/*----------------------------------工具函数----------------------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/**
* @brief 打印数组
* @param a 数组指针
* @param n 数组长度
*/
//2.实现:"数组的打印"的工具函数
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
/**
* @brief 堆的向下调整算法(大顶堆)
* @param a 堆数组
* @param parent 需要调整的父节点索引
* @param n 堆的大小
*
* 算法功能:
* 1. 确保以parent为根的子树满足大顶堆性质
* 2. 若父节点小于子节点,则交换并继续向下调整
*
* 执行过程:
* 1. 从父节点出发,找到较大的子节点
* 2. 比较父子节点值,若父节点较小则交换
* 3. 循环执行直到满足堆性质或到达叶子节点
*
* 时间复杂度:O(logN)(树的高度)
*/
//3.实现:"堆的向下调整"辅助函数
void AdjustDown(int* a, int parent, int n)
{
//思路:向下调整的本质:是判断父节点的值和左右孩子的值的大小关系,并将父子关系不满足大根堆条件(孩子大于父亲)的情况进行交换调整
//所以我任务是
//任务1:找到父节点孩子中值最大的那个孩子
//任务2:判断父节点和孩子节点的大小关系,并进行调整
//1.先假设父节点的左孩子是值最大的孩子
int maxChild = (parent << 1) + 1;
//注意1:这里还用+1,因为这里是maxChild 和 parent 都是数组的下标
//注意2:位运算符的优先级比算数运算符的优先级小 ---> 一般情况下:如果位运算符我们不写在表达式的最后的话,都要添加()来提高优先级
//2.循环进行交换调整
while (maxChild < n) //当孩子的索引值 >= n 的时候,说明进行调整到不能在调整了
{
//3.确定父节点的值最大的孩子节点
if (maxChild + 1 < n && a[maxChild + 1] > a[maxChild])
{
maxChild = maxChild + 1;
}
//4.判断父节点和孩子节点的大小关系
if (a[parent] >= a[maxChild]) return;
else
{
//4.1: 交换
Swap(&a[parent], &a[maxChild]);
//4.2:更新
parent = maxChild;
//4.3:寻找
maxChild = (parent << 1) + 1;
}
}
}
/*------------------------------辅助排序:插入排序------------------------------*/
/**
* @brief 插入排序
* @param a 待排序数组
* @param n 数组长度
* @note 时间复杂度:
* 最坏O(N^2) - 逆序情况
* 最好O(N) - 已有序情况
*/
//1.实现:"插入排序"
void InsertSort(int* a, int n)
{
//1.外层的循环控制 ---> 记录当前数组中区间到那里已经是有序的了 (解释:循环变量i=n-2意味着"当前数组中区间为[0,n-1]范围中的元素现在已经是有序的了")
for (int i = 0; i <= n - 2; i++) //注:i虽然只能到n-2的但是当i=n-2的时候,我们正在处理的是下标为n-1位置的元素,也就是数组中的最后哦一个元素
{
//2.记录当前数组中已经有序区间的右下标
int end = i;
//3.取出我们要进行插入排序的元素
int tmp = a[end + 1];
//4.内层的循环控制 ---> 寻找我们要插入的位置
while (end >= 0)
{
//核心:前面元素的值大进行后移
if (a[end] > tmp)
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
//注意:因为end的值变为-1而退出的while循环的情况:意味着当前处理的这个元素的值比数组中区间为[0,end]的已经有序元素的任意一个元素的值都要小
a[end + 1] = tmp;
}
}
/*------------------------------辅助排序:堆排序------------------------------*/
/**
* @brief 堆排序算法实现
* @param a 待排序数组
* @param n 数组长度
*
* 算法特性:
* 1. 时间复杂度:
* - 建堆过程:O(N)
* - 排序过程:O(N*logN)
* - 总体:O(N*logN)
*
* *核心思想:
* - 将数组视为完全二叉树,建立大顶堆
* - 反复取出堆顶元素(最大值)放到数组末尾
* - 重新调整剩余元素维持堆结构
*/
//2.实现:"堆排序"
void HeapSort(int* a, int n)
{
/*------------------第一阶段:建堆------------------*/
//建堆的方法有两种:
//1.向上调整建堆
//2.向下调整建堆
//注:这两种方法有明显的性能差别,向下调整建堆算法的时间复杂度更小,使用的人也更多
//建堆本质:从堆中最后一个非叶子节点到堆顶节点逐个使用:向下调整算法
for (int i = (n - 1 - 1) >> 1; i >= 0; i--)
{
AdjustDown(a, i, n);
}
/*------------------第二阶段:将堆顶元素与末尾的元素进行交换 + 向下调整堆------------------*/
//1.定义一个变量记录当前堆中最后一个元素的在数组中的索引
int end = n - 1;
//2.循环进行第二阶段直到堆对应的数组中只剩下标为0的元素的值还没用进行交换的时候
while (end > 0)
{
//2.1:将堆顶元素与末尾的元素进行交换
Swap(&a[0], &a[end]);
//2.2:更新堆对应数组的容量 ---> (逻辑上:删除了堆顶元素)
end--;
//2.3:重新向下调整堆
AdjustDown(a, 0, end + 1);
}
}
/*------------------------------快排进阶 ---> 内省排序------------------------------*/
/**
* @brief 内省排序(IntroSort)算法
* @param a 待排序数组
* @param left 左边界
* @param right 右边界
* @param depth 当前递归深度
* @param defaultDepth 最大允许递归深度
*
* @note 内省排序是快速排序、堆排序和插入排序的混合算法:
* 1. 对小数组使用插入排序
* 2. 递归深度过大时使用堆排序避免最坏情况
* 3. 其他情况使用快速排序
*/
//实现:"快排进阶 ---> 内省排序"
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{
//1.处理特殊的情况:"区间中没有元素 + 区间中只有一个元素" (同是也是递归结束的条件)
if (left >= right) return;
//2.优化1"小区间优化:对小区间使用插入排序(阈值设为16)"
if (right - left + 1 < 16)
{
InsertSort(a + left, right - left + 1);
return;
}
//3.优化2:"递归深度优化:递归深度过大时改用堆排序,避免快速排序的最坏情况"
if (depth > defaultDepth)
{
HeapSort(a + left, right - left + 1);
return;
}
//4. 增加递归深度的计数
depth++;
//5.优化3:"随机选择基准值:避免快速排序的最坏情况"
int randKey = left + (rand() % (right - left));
//6.将基准值和数组中最左边的值进行交换
Swap(&a[randKey], &a[left]);
//7.定义一个变量记录基准值的索引
int key = left;
//8.定义一个慢指针:用于指向做后一个小于基准值的值
int slow = left;
//9.定义一个快指针:用于扫描整个区间
int fast = slow + 1;
//10.
while (fast <= right)
{
if (a[fast] < a[key] && ++slow != fast)
{
Swap(&a[fast], &a[slow]);
}
fast++;
}
//11.将基准值交换到最终的位置(未进行交换前:slow指向最后一个小于基准的元素)
Swap(&a[key], &a[slow]);
//12.更新当前基准值的下标
key = slow;
// 递归排序左右子数组:
IntroSort(a, left, key - 1, depth, defaultDepth);
IntroSort(a, key + 1, right, depth, defaultDepth);
}
/*---------------------------快速排序的包装函数---------------------------*/
/**
* @brief 快速排序的包装函数
* @param a 待排序数组
* @param left 左边界
* @param right 右边界
*/
void QuickSort(int* a, int left, int right)
{
//1.记录当前递归的深度
int depth = 0;
//2.记录2*logN的值
int logn = 0;
//3.计算 2*logN的值 ---> 用于判断递归深度是否过大,判断何时从快速排序切换到堆排序
for (int i = 1; i < right - left + 1; i *= 2)// 方法:找到最大的i使得2^i <= N
{
logn++;
}
//4.调用内省排序函数进行实际的排序
IntroSort(a, left, right, depth, logn * 2);
/*
* 为什么选择2*logN作为阈值?
* 1. 快速排序的平均递归深度是logN
* 2. 设置2*logN的阈值可以在保持快速排序高效性的同时
* 有效防止恶意构造的最坏情况
* 3. 当递归深度超过2*logN时,说明分区极度不平衡
* 此时切换为堆排序更安全
*/
}测试文件:Test.c
c
#include "IntroSort.h"
/*---------------------------------快排进阶:内省排序的测试---------------------------------*/
// 测试辅助函数:用于判断一个数组是否有序
bool isSorted(int* arr, int size)
{
for (int i = 0; i < size - 1; i++)
{
if (arr[i] > arr[i + 1])
{
return false;
}
}
return true;
}
/*------------------测试用例1:普通随机数组------------------*/
void testRandomArray()
{
printf("===== 测试随机数组 =====\n");
int arr[] = { 3, 1, 4, 1, 5, 9, 2, 6, 5, 3 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过: 数组已正确排序\n");
else
printf("测试失败: 数组未正确排序\n");
printf("\n");
}
/*------------------测试用例2:已排序数组------------------*/
void testSortedArray()
{
printf("===== 测试已排序数组 =====\n");
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过: 数组保持有序\n");
else
printf("测试失败: 数组顺序被破坏\n");
printf("\n");
}
/*------------------测试用例3:逆序数组------------------*/
void testReverseSortedArray()
{
printf("===== 测试逆序数组 =====\n");
int arr[] = { 9, 8, 7, 6, 5, 4, 3, 2, 1 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过: 数组已正确排序\n");
else
printf("测试失败: 数组未正确排序\n");
printf("\n");
}
/*------------------测试用例4:全相同元素数组------------------*/
void testUniformArray()
{
printf("===== 测试全相同数组 =====\n");
int arr[] = { 5, 5, 5, 5, 5, 5, 5, 5 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过: 数组保持有序\n");
else
printf("测试失败: 数组顺序被破坏\n");
printf("\n");
}
/*------------------测试用例5:小数组(小于16个元素)------------------*/
void testSmallArray()
{
printf("===== 测试小数组 =====\n");
int arr[] = { 7, 3 };
int size = sizeof(arr) / sizeof(arr[0]);
printf("排序前: ");
PrintArray(arr, size);
QuickSort(arr, 0, size - 1);
printf("排序后: ");
PrintArray(arr, size);
if (isSorted(arr, size))
printf("测试通过: 小数组已正确排序\n");
else
printf("测试失败: 小数组未正确排序\n");
printf("\n");
}
/*------------------测试用例6:大数组测试性能------------------*/
void testLargeArray()
{
printf("===== 测试大数组性能 =====\n");
const int size = 100000;
int* arr = (int*)malloc(size * sizeof(int));
if (arr == NULL)
{
perror("malloc fail");
return;
}
// 生成随机数组
srand((unsigned int)time(NULL));
for (int i = 0; i < size; i++)
{
arr[i] = rand() % size;
}
printf("开始排序%d个元素...\n", size);
clock_t start = clock();
QuickSort(arr, 0, size - 1);
clock_t end = clock();
double time_spent = (double)(end - start) / CLOCKS_PER_SEC;
if (isSorted(arr, size))
{
printf("测试通过: 大数组已正确排序\n");
printf("排序耗时: %.3f秒\n", time_spent);
}
else
{
printf("测试失败: 大数组未正确排序\n");
}
free(arr);
printf("\n");
}
int main()
{
//快排进阶 ---> 内省排序的测试函数
testRandomArray();
testSortedArray();
testReverseSortedArray();
testUniformArray();
testSmallArray();
testLargeArray();
printf("===== 所有测试完成 =====\n");
return 0;
}运行结果
---------------实践---------------
912. 排序数组
题目介绍

方法一:Hoare版------快速排序
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
/*-----------------------工具函数-----------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/*----------------------hoare对撞指针分区算法----------------------*/
/**
* @brief Hoare分区法(快速排序的核心分区算法)
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return int 返回基准值的最终位置
*
* @note 算法思想:
* 1. 选取最左元素作为基准值(key)
* 2. 从右向左找比key小的元素
* 3. 从左向右找比key大的元素
* 4. 交换这两个元素
* 5. 重复2-4直到左右指针相遇
* 6. 将基准值放到最终位置
*/
int PartSort1(int* a, int left, int right)
{
//1.进行基准值优化:随机化基准值的选取
int mid = left + (rand() % (right - left));
//2.将找到的基准值放在左边界
Swap(&a[left], &a[mid]);
//3.定义一个变量记录基准值的索引
int key = left;
//4.使用while循环遍历整个数组
while (left < right)
{
///4.1:从右向左找第一个小于基准值的元素
while (left < right && a[right] >= a[key])
{
right--;
}
//4.2:从左向右找第一个大于基准值的元素
while (left < right && a[left] <= a[key])
{
left++;
}
//注意:左右指针在借助基准值的索引找到要交换的元素之前,基准值的位置并未发生改变 ---> 我们使用a[key]还可以找到基准值,那么我们就可以使用key代表基准值的索引
Swap(&a[left], &a[right]);
}
//5.将基准值放在合适的位置上
Swap(&a[key], &a[left]);
//6.返回基准值的位置
return left;
}
/*---------------------------快排主函数---------------------------*/
void QuickSort(int* a, int left, int right)
{
//1.递归终止条件
if (left >= right) return;
//2.可以根据需要选择性的在这里添加小区间优化(比如:之前已经实现过了插入排序就可以在这里进行小区间优化了)
//3.定义一个变量接收基准值的位置
//注:这里你可以使用你之前实现的任意的一个分区算法
/*-------------使用:hoare分区算法-------------*/
int key = PartSort1(a, left, right);
//4.递归排序左右子区间
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
/*---------------------------测试接口函数---------------------------*/
int* sortArray(int* nums, int numsSize, int* returnSize)
{
QuickSort(nums,0,numsSize-1);
*returnSize = numsSize;
//注意:上面的这一行代码是必须要加上的,不要觉得returnSize这个变量的上面的我们就没有用过,
//这个参数没有任何的用,LeetCode多设计了一个没用的参数
//其实:这了参数是故意设计的,它大有用处,它是LeetCode评测系统的一个特殊设计------------常被称为"输出型参数"
//从的名字returnXXXX就可看出来,
//设计这个参数的目的是:告诉评判系统返回数组的长度
//即使你直接返回了输入数组nums,但是系统还是需要明确知道数组的有效长度(尤其是动态分配的数组)
//如果你没有返回数组的长度
//LeetCode的测试框架无法确定返回数组的长度,可能触发以下错误:
//1.返回 NULL 或未初始化值,导致判题系统无法正确读取结果
//2.引发内存访问异常(如:数组长度被误判为0)
return nums;
}
方法二:lomuto版------快速排序
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
/*-----------------------工具函数-----------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/*----------------------------lomuto快慢指针分区算法----------------------------*/
/**
* @brief 前后指针分区法(快速排序的另一种分区实现)
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return int 返回基准值的最终位置
*
* @note 算法思想:
* 1. 选取最左元素作为基准值(key)
* 2. prev指向小于key的区域的最后一个元素
* 3. cur遍历整个分区
* 4. 当cur找到比key小的元素时,先移动prev再交换
* 5. 最后将基准值放到prev位置
*/
int PartSort2(int* a, int left, int right)
{
//1.进行基准值优化:随机化基准值的选取
int mid = left + (rand() % (right - left));
//2.将找到的基准值放在左边界
Swap(&a[left], &a[mid]);
//3.定义一个变量记录基准值的索引
int key = left;
//4.定义一个慢指针:用于指向最后一个小于基准值的元素
int slow = left;
//5.定义一个快指针:用于遍历整个分区
int fast = left + 1;
//6.使用while循环遍历整个数组
while (fast <= right)
{
if (a[fast] < a[key] && ++slow != fast)
{
Swap(&a[slow], &a[fast]);
}
fast++;
}
//7.将基准值交换到最终的位置(未进行交换前:slow指向最后一个小于基准的元素)
Swap(&a[key], &a[slow]);
//8.返回当前基准值的下标
return slow;
}
/*---------------------------快排主函数---------------------------*/
void QuickSort(int* a, int left, int right)
{
//1.递归终止条件
if (left >= right) return;
//2.可以根据需要选择性的在这里添加小区间优化(比如:之前已经实现过了插入排序就可以在这里进行小区间优化了)
//3.定义一个变量接收基准值的位置
//注:这里你可以使用你之前实现的任意的一个分区算法
/*-------------使用:lomuto分区算法-------------*/
int key = PartSort2(a, left, right);
//4.递归排序左右子区间
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
/*---------------------------测试接口函数---------------------------*/
int* sortArray(int* nums, int numsSize, int* returnSize)
{
QuickSort(nums,0,numsSize-1);
*returnSize = numsSize;
//注意:上面的这一行代码是必须要加上的,不要觉得returnSize这个变量的上面的我们就没有用过,
//这个参数没有任何的用,LeetCode多设计了一个没用的参数
//其实:这了参数是故意设计的,它大有用处,它是LeetCode评测系统的一个特殊设计------------常被称为"输出型参数"
//从的名字returnXXXX就可看出来,
//设计这个参数的目的是:告诉评判系统返回数组的长度
//即使你直接返回了输入数组nums,但是系统还是需要明确知道数组的有效长度(尤其是动态分配的数组)
//如果你没有返回数组的长度
//LeetCode的测试框架无法确定返回数组的长度,可能触发以下错误:
//1.返回 NULL 或未初始化值,导致判题系统无法正确读取结果
//2.引发内存访问异常(如:数组长度被误判为0)
return nums;
}
方法三:挖坑版------快速排序
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
/*-----------------------工具函数-----------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/*--------------------------------挖坑分区算法--------------------------------*/
int PartSort3(int* a, int left, int right)
{
//1.进行基准值优化:随机化基准值的选取
int mid = left + (rand() % (right - left));
//2.将找到的基准值放在左边界
Swap(&a[left], &a[mid]);
//3.定义一个变量记录基准值(注意这里保存值而不是索引)
int key = a[left]; //特别注意:这的key存储的不再是基准值的下标,而是直接存储的基准值,这是为什么呢?(下面的注释博主有详细的解释,请继续往下看......)
//4.定义一个变量记录坑位
int hole = left;
//5.定义两个临时变量从区间的两端向中间进行扫描 ---> 高效地将数组分为两部分
int begin = left, end = right;
//6.进行分区
while (begin < end)
{
//6.1:从右向左寻找第一个小于基准的值
while (begin < end && a[end] >= key)
{
end--;
}
//6.2:找到后填左坑,end成为新坑
a[hole] = a[end]; //特别注意:这里while循环结束后并不是紧接又是一个while循环,而是做填坑、挖坑的操作,也恰恰是这个填坑、挖坑的操作使得基准值的下标已经发生了改变
hole = end; //所以说:我们下面就不可以使用a[key](假设:key存储的还是基准值的下标)的方式来得到基准值了,
//6.3:从左向右寻找第一个大于基准的值
while (begin < end && a[begin] <= key)
{
begin++;
}
//6.4:找到后填右坑,left成为新坑
a[hole] = a[begin];
hole = begin;
}
//7.最后将基准值填入最后的坑位
a[hole] = key;
//8.返回当前基准值的下标
return hole;
}
/*---------------------------快排主函数---------------------------*/
void QuickSort(int* a, int left, int right)
{
//1.递归终止条件
if (left >= right) return;
//2.可以根据需要选择性的在这里添加小区间优化(比如:之前已经实现过了插入排序就可以在这里进行小区间优化了)
//3.定义一个变量接收基准值的位置
//注:这里你可以使用你之前实现的任意的一个分区算法
/*-------------使用:挖坑分区算法-------------*/
int key = PartSort3(a, left, right);
//4.递归排序左右子区间
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
/*---------------------------测试接口函数---------------------------*/
int* sortArray(int* nums, int numsSize, int* returnSize)
{
QuickSort(nums,0,numsSize-1);
*returnSize = numsSize;
//注意:上面的这一行代码是必须要加上的,不要觉得returnSize这个变量的上面的我们就没有用过,
//这个参数没有任何的用,LeetCode多设计了一个没用的参数
//其实:这了参数是故意设计的,它大有用处,它是LeetCode评测系统的一个特殊设计------------常被称为"输出型参数"
//从的名字returnXXXX就可看出来,
//设计这个参数的目的是:告诉评判系统返回数组的长度
//即使你直接返回了输入数组nums,但是系统还是需要明确知道数组的有效长度(尤其是动态分配的数组)
//如果你没有返回数组的长度
//LeetCode的测试框架无法确定返回数组的长度,可能触发以下错误:
//1.返回 NULL 或未初始化值,导致判题系统无法正确读取结果
//2.引发内存访问异常(如:数组长度被误判为0)
return nums;
}
方法四:三路划分版------快速排序
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
/*---------------定义三路划分的中间区间的结构体---------------*/
typedef struct
{
//1.记录基准值的左边界
//2.记录基准值的右边界
int leftKeyIdx;
int rightKeyIdx;
}KeyWayIdx;
/*-----------------------工具函数-----------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/*--------------------------------三路划分分区算法--------------------------------*/
/**
* @brief 三路划分快速排序的核心分区函数
* @param a 待排序数组
* @param left 分区左边界
* @param right 分区右边界
* @return KeyWayIdx 包含等于基准值区间的左右边界
*
* @details
* 将数组划分为三个部分:
* 1. [left, leftKeyIdx-1] 小于基准值
* 2. [leftKeyIdx, rightKeyIdx] 等于基准值
* 3. [rightKeyIdx+1, right] 大于基准值
*/
//3.实现:"三路划分快速排序"的算法
KeyWayIdx QuickSort3Way(int* a, int left, int right)
{
//1.进行基准值优化:随机化基准值的选取
int mid = left + (rand() % (right - left));
//2.将找到的基准值放在左边界
Swap(&a[left], &a[mid]);
//3.选择最左边的元素作为基准值
int key = a[left];
//4.定义遍历数组的指针
int curr = left + 1;
//5.使用curr指针循环遍历数组
while (curr <= right)
{
//5.1:如果遍历到的当前元素 < 基准值,则将其交换到左边
if (a[curr] < key)
{
//5.1.1:
Swap(&a[curr], &a[left]); //注意:这里基准值的位置会发生改变,所以我们的key存储的基准值而不是基准值的下标
//5.1.2:
left++; //注意:这里基准值的下标会发生改变,所以我们的key存储的基准值而不是基准值的下标
//5.1.3:
curr++; //注意:这里可以直接将curr进行++的原因是 ---> 经过交换后此时a[curr]==key ,它已经处于正确的位置(中间区间)
//所以可以直接跳过(++cur),继续检查下一个元素
}
//5.2:如果遍历到的当前元素 > 基准值,则将其交换到右边
else if (a[curr] > key)
{
//5.2.1:
Swap(&a[curr], &a[right]);
//5.2.2:
right--;
//这里为什么没有curr++呢?----> 因为交换过来的元素还未检查(我们并不知道a[right]的值和基准值key的大小关系)
}
//5.3:
else
{
curr++; //当前元素等于基准值,直接跳过
}
}
//6.创建中间区间的结构体,并为其初始化
KeyWayIdx kwi;
kwi.leftKeyIdx = left;
kwi.rightKeyIdx = right;
return kwi;
}
/*---------------------------快排主函数---------------------------*/
void QuickSort(int* a, int left, int right)
{
//1.递归终止条件
if (left >= right) return;
//2.可以根据需要选择性的在这里添加小区间优化(比如:之前已经实现过了插入排序就可以在这里进行小区间优化了)
//3.定义一个结构体接受中间区间的结构体
KeyWayIdx kwi = QuickSort3Way(a, left, right);
//4.递归排序左右子区间
QuickSort(a, left, kwi.leftKeyIdx - 1);
QuickSort(a, kwi.rightKeyIdx + 1, right);
//注意:kwi.leftKeyIdx 到 kwi.rightKeyIdx 之间的元素已等于基准值,无需处理!
}
/*---------------------------测试接口函数---------------------------*/
int* sortArray(int* nums, int numsSize, int* returnSize)
{
QuickSort(nums,0,numsSize-1);
*returnSize = numsSize;
//注意:上面的这一行代码是必须要加上的,不要觉得returnSize这个变量的上面的我们就没有用过,
//这个参数没有任何的用,LeetCode多设计了一个没用的参数
//其实:这了参数是故意设计的,它大有用处,它是LeetCode评测系统的一个特殊设计------------常被称为"输出型参数"
//从的名字returnXXXX就可看出来,
//设计这个参数的目的是:告诉评判系统返回数组的长度
//即使你直接返回了输入数组nums,但是系统还是需要明确知道数组的有效长度(尤其是动态分配的数组)
//如果你没有返回数组的长度
//LeetCode的测试框架无法确定返回数组的长度,可能触发以下错误:
//1.返回 NULL 或未初始化值,导致判题系统无法正确读取结果
//2.引发内存访问异常(如:数组长度被误判为0)
return nums;
}
方法五:内省排序------快排进阶
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
/*----------------------------------工具函数----------------------------------*/
/**
* @brief 交换两个整数的值
* @param a 第一个整数的指针
* @param b 第二个整数的指针
*/
//1.实现:"数组中元素的交换"的工具函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
/**
* @brief 打印数组
* @param a 数组指针
* @param n 数组长度
*/
//2.实现:"数组的打印"的工具函数
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
/**
* @brief 堆的向下调整算法(大顶堆)
* @param a 堆数组
* @param parent 需要调整的父节点索引
* @param n 堆的大小
*
* 算法功能:
* 1. 确保以parent为根的子树满足大顶堆性质
* 2. 若父节点小于子节点,则交换并继续向下调整
*
* 执行过程:
* 1. 从父节点出发,找到较大的子节点
* 2. 比较父子节点值,若父节点较小则交换
* 3. 循环执行直到满足堆性质或到达叶子节点
*
* 时间复杂度:O(logN)(树的高度)
*/
//3.实现:"堆的向下调整"辅助函数
void AdjustDown(int* a, int parent, int n)
{
//思路:向下调整的本质:是判断父节点的值和左右孩子的值的大小关系,并将父子关系不满足大根堆条件(孩子大于父亲)的情况进行交换调整
//所以我任务是
//任务1:找到父节点孩子中值最大的那个孩子
//任务2:判断父节点和孩子节点的大小关系,并进行调整
//1.先假设父节点的左孩子是值最大的孩子
int maxChild = (parent << 1) + 1;
//注意1:这里还用+1,因为这里是maxChild 和 parent 都是数组的下标
//注意2:位运算符的优先级比算数运算符的优先级小 ---> 一般情况下:如果位运算符我们不写在表达式的最后的话,都要添加()来提高优先级
//2.循环进行交换调整
while (maxChild < n) //当孩子的索引值 >= n 的时候,说明进行调整到不能在调整了
{
//3.确定父节点的值最大的孩子节点
if (maxChild + 1 < n && a[maxChild + 1] > a[maxChild])
{
maxChild = maxChild + 1;
}
//4.判断父节点和孩子节点的大小关系
if (a[parent] >= a[maxChild]) return;
else
{
//4.1: 交换
Swap(&a[parent], &a[maxChild]);
//4.2:更新
parent = maxChild;
//4.3:寻找
maxChild = (parent << 1) + 1;
}
}
}
/*------------------------------辅助排序:插入排序------------------------------*/
/**
* @brief 插入排序
* @param a 待排序数组
* @param n 数组长度
* @note 时间复杂度:
* 最坏O(N^2) - 逆序情况
* 最好O(N) - 已有序情况
*/
//1.实现:"插入排序"
void InsertSort(int* a, int n)
{
//1.外层的循环控制 ---> 记录当前数组中区间到那里已经是有序的了 (解释:循环变量i=n-2意味着"当前数组中区间为[0,n-1]范围中的元素现在已经是有序的了")
for (int i = 0; i <= n - 2; i++) //注:i虽然只能到n-2的但是当i=n-2的时候,我们正在处理的是下标为n-1位置的元素,也就是数组中的最后哦一个元素
{
//2.记录当前数组中已经有序区间的右下标
int end = i;
//3.取出我们要进行插入排序的元素
int tmp = a[end + 1];
//4.内层的循环控制 ---> 寻找我们要插入的位置
while (end >= 0)
{
//核心:前面元素的值大进行后移
if (a[end] > tmp)
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
//注意:因为end的值变为-1而退出的while循环的情况:意味着当前处理的这个元素的值比数组中区间为[0,end]的已经有序元素的任意一个元素的值都要小
a[end + 1] = tmp;
}
}
/*------------------------------辅助排序:堆排序------------------------------*/
/**
* @brief 堆排序算法实现
* @param a 待排序数组
* @param n 数组长度
*
* 算法特性:
* 1. 时间复杂度:
* - 建堆过程:O(N)
* - 排序过程:O(N*logN)
* - 总体:O(N*logN)
*
* *核心思想:
* - 将数组视为完全二叉树,建立大顶堆
* - 反复取出堆顶元素(最大值)放到数组末尾
* - 重新调整剩余元素维持堆结构
*/
//2.实现:"堆排序"
void HeapSort(int* a, int n)
{
/*------------------第一阶段:建堆------------------*/
//建堆的方法有两种:
//1.向上调整建堆
//2.向下调整建堆
//注:这两种方法有明显的性能差别,向下调整建堆算法的时间复杂度更小,使用的人也更多
//建堆本质:从堆中最后一个非叶子节点到堆顶节点逐个使用:向下调整算法
for (int i = (n - 1 - 1) >> 1; i >= 0; i--)
{
AdjustDown(a, i, n);
}
/*------------------第二阶段:将堆顶元素与末尾的元素进行交换 + 向下调整堆------------------*/
//1.定义一个变量记录当前堆中最后一个元素的在数组中的索引
int end = n - 1;
//2.循环进行第二阶段直到堆对应的数组中只剩下标为0的元素的值还没用进行交换的时候
while (end > 0)
{
//2.1:将堆顶元素与末尾的元素进行交换
Swap(&a[0], &a[end]);
//2.2:更新堆对应数组的容量 ---> (逻辑上:删除了堆顶元素)
end--;
//2.3:重新向下调整堆
AdjustDown(a, 0, end + 1);
}
}
/*------------------------------快排进阶 ---> 内省排序------------------------------*/
/**
* @brief 内省排序(IntroSort)算法
* @param a 待排序数组
* @param left 左边界
* @param right 右边界
* @param depth 当前递归深度
* @param defaultDepth 最大允许递归深度
*
* @note 内省排序是快速排序、堆排序和插入排序的混合算法:
* 1. 对小数组使用插入排序
* 2. 递归深度过大时使用堆排序避免最坏情况
* 3. 其他情况使用快速排序
*/
//实现:"快排进阶 ---> 内省排序"
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{
//1.处理特殊的情况:"区间中没有元素 + 区间中只有一个元素" (同是也是递归结束的条件)
if (left >= right) return;
//2.优化1"小区间优化:对小区间使用插入排序(阈值设为16)"
if (right - left + 1 < 16)
{
InsertSort(a + left, right - left + 1);
return;
}
//3.优化2:"递归深度优化:递归深度过大时改用堆排序,避免快速排序的最坏情况"
if (depth > defaultDepth)
{
HeapSort(a + left, right - left + 1);
return;
}
//4. 增加递归深度的计数
depth++;
//5.优化3:"随机选择基准值:避免快速排序的最坏情况"
int randKey = left + (rand() % (right - left));
//6.将基准值和数组中最左边的值进行交换
Swap(&a[randKey], &a[left]);
//7.定义一个变量记录基准值的索引
int key = left;
//8.定义一个慢指针:用于指向做后一个小于基准值的值
int slow = left;
//9.定义一个快指针:用于扫描整个区间
int fast = slow + 1;
//10.
while (fast <= right)
{
if (a[fast] < a[key] && ++slow != fast)
{
Swap(&a[fast], &a[slow]);
}
fast++;
}
//11.将基准值交换到最终的位置(未进行交换前:slow指向最后一个小于基准的元素)
Swap(&a[key], &a[slow]);
//12.更新当前基准值的下标
key = slow;
// 递归排序左右子数组:
IntroSort(a, left, key - 1, depth, defaultDepth);
IntroSort(a, key + 1, right, depth, defaultDepth);
}
/*---------------------------快速排序的包装函数---------------------------*/
/**
* @brief 快速排序的包装函数
* @param a 待排序数组
* @param left 左边界
* @param right 右边界
*/
void QuickSort(int* a, int left, int right)
{
//1.记录当前递归的深度
int depth = 0;
//2.记录2*logN的值
int logn = 0;
//3.计算 2*logN的值 ---> 用于判断递归深度是否过大,判断何时从快速排序切换到堆排序
for (int i = 1; i < right - left + 1; i *= 2)// 方法:找到最大的i使得2^i <= N
{
logn++;
}
//4.调用内省排序函数进行实际的排序
IntroSort(a, left, right, depth, logn * 2);
/*
* 为什么选择2*logN作为阈值?
* 1. 快速排序的平均递归深度是logN
* 2. 设置2*logN的阈值可以在保持快速排序高效性的同时
* 有效防止恶意构造的最坏情况
* 3. 当递归深度超过2*logN时,说明分区极度不平衡
* 此时切换为堆排序更安全
*/
}
/*---------------------------测试接口函数---------------------------*/
int* sortArray(int* nums, int numsSize, int* returnSize)
{
QuickSort(nums,0,numsSize-1);
*returnSize = numsSize;
//注意:上面的这一行代码是必须要加上的,不要觉得returnSize这个变量的上面的我们就没有用过,
//这个参数没有任何的用,LeetCode多设计了一个没用的参数
//其实:这了参数是故意设计的,它大有用处,它是LeetCode评测系统的一个特殊设计------------常被称为"输出型参数"
//从的名字returnXXXX就可看出来,
//设计这个参数的目的是:告诉评判系统返回数组的长度
//即使你直接返回了输入数组nums,但是系统还是需要明确知道数组的有效长度(尤其是动态分配的数组)
//如果你没有返回数组的长度
//LeetCode的测试框架无法确定返回数组的长度,可能触发以下错误:
//1.返回 NULL 或未初始化值,导致判题系统无法正确读取结果
//2.引发内存访问异常(如:数组长度被误判为0)
return nums;
}
结果分析
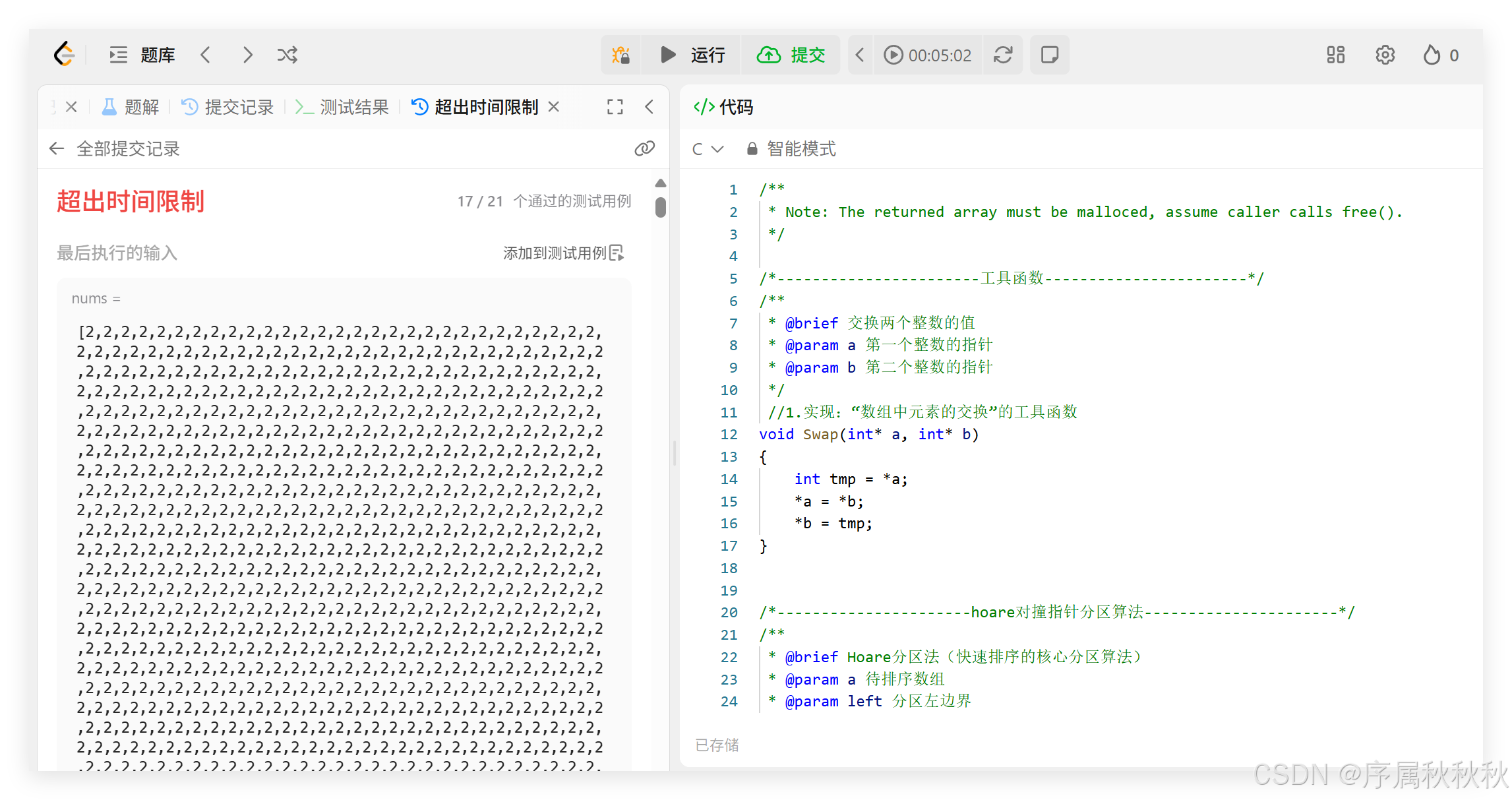
温馨提示:演示的前三个分区算法都进行了:"随机化基准"的优化,因为如果不这样做的话,没等遇到含有特殊数据的数组------大量重复数据的数组 ,在面对含有大量数据的数组的时候就超时了。
OJ分析:通过上面这道OJ的练习,我们可以总结出下面的一些信息:时间复杂度为 O ( N 2 ) O(N^2) O(N2) 的排序算法无法通过,并且当使用快排时,传统的 H o a r e Hoare Hoare 和 L o m u t o Lomuto Lomuto 方法也无法通过该题目。
- 这是因为:该题的测试用例中,不仅有数据量庞大的大数组,还有一些特殊数据的数组,比如:含有大量重复数据的数组。
而希尔排序、堆排序、归并排序则可以通过。
- 这是因为:堆排序、归并排序和希尔排序受数据样本的分布和形态影响较小。
- 但快排不同,由于快排需要选择基准值( k e y key key),如果每次基准值的选择都使得当趟分割结果很不均衡,就会出现效率退化的问题。
---------------结语---------------
从实验室中的理论构想,到工业界的标配工具,快速排序历经六十余年仍焕发活力。
它不仅是排序问题的高效解法,更蕴含着
分治、优化、随机化等算法设计思想,持续启发着计算机科学的发展。正如霍尔 本人所说:"
算法的价值不仅在于解决问题,更在于教会我们如何思考问题。"这或许就是快速排序留给后世最宝贵的遗产。
