基本概念
Apache Spark 是一个专为大规模数据处理而设计的快速、通用的计算引擎。它最初由加州大学伯克利分校的 AMP 实验室开发,后成为 Apache 顶级项目。Spark 采用内存计算,可将作业中间结果缓存于内存中,减少磁盘读写操作,在数据挖掘和机器学习等需要迭代计算的场景中表现出色。
核心组件
Spark 的核心组件包括:
-
Spark Core :实现了 Spark 的基本功能,如 RDD(弹性分布式数据集)、任务调度、内存管理等,是 Spark 的基础。
-
Spark SQL :用于操作结构化数据的程序包,支持 SQL 查询,能够与多种数据源集成,如 Hive、Avro、Parquet 和 JSON 等。
-
Spark Streaming :提供了对实时数据进行流式计算的组件,可处理来自多种数据源的实时数据流,如 Kafka、Flume 和 TCP 套接字。
-
MLlib :是 Spark 提供的机器学习功能的程序库,包含常见的机器学习算法,如分类、回归、聚类和推荐系统等。
-
GraphX :用于图计算的 API,适用于大规模图数据计算,支持常见的图算法,如 PageRank、连接组件和最短路径等。
安装部署
需要说明的是:Spark的image有官方版本和第三方版本(vmware的bitnami/spark等);官方版本在不使用Kubernetes的情况下,使用Docker无法以服务启动,只能进行交互式访问。
官方版启动命令:
ENTRYPOINT "/opt/entrypoint.sh"
bitnami/spark镜像启动命令:
ENTRYPOINT "/opt/bitnami/scripts/spark/entrypoint.sh"
官方镜像使用
拉取镜像:docker pull spark
链接:https://hub.docker.com/r/spark
Interactive Scala Shell
bash
docker run -it spark /opt/spark/bin/spark-shellInteractive Python Shell
bash
docker run -it spark:python3 /opt/spark/bin/pysparkInteractive R Shell
bash
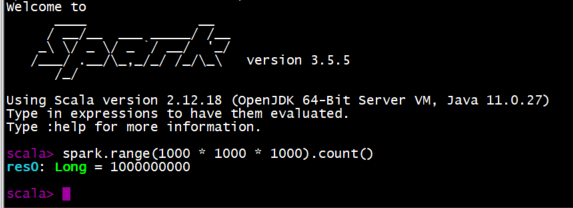
docker run -it spark:r /opt/spark/bin/sparkR运行如下命令调用,返回:Long = 1000000000
>>> spark.range(1000 * 1000 * 1000).count()
退出scala:
scala> :quit
bitnami/spark镜像使用
拉取镜像:docker pull bitnami/spark:3.5.5
链接:https://hub.docker.com/r/bitnami/spark
环境准备
bash
useradd spark
usermod -a -G docker spark
su - spark
mkdir -p ~/spark-cluster/{conf,data,ivy}
chmod 777 ~/spark-cluster/{conf,data,ivy}注: 这里需要完全放开权限,否则spark启动失败,镜像中使用了root组的rpmer用户拷贝文件到上述目录中。
定义docker-compose yaml规格文件
bash
cd spark-cluster/
cat >docker-compose.yaml <<EOF
services:
master:
image: bitnami/spark:3.5.5
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
environment:
- SPARK_MODE=master
- SPARK_MASTER_HOST=spark-master
- SPARK_RPC_AUTH_ENABLED=no
volumes:
- ./conf:/opt/bitnami/spark/conf
- ./data:/data
- ./ivy:/opt/bitnami/spark/ivy
networks:
- zookeeper-net
worker1:
image: bitnami/spark:3.5.5
container_name: spark-worker1
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKERMEMORY=2G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTH_ENABLED=no
volumes:
- ./conf:/opt/bitnami/spark/conf
- ./data:/data
- ./ivy:/opt/bitnami/spark/ivy
depends_on:
- master
networks:
- zookeeper-net
worker2:
image: bitnami/spark:3.5.5
container_name: spark-worker2
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKERMEMORY=2G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTH_ENABLED=no
volumes:
- ./conf:/opt/bitnami/spark/conf
- ./data:/data
- ./ivy:/opt/bitnami/spark/ivy
depends_on:
- master
networks:
- zookeeper-net
networks:
zookeeper-net:
external: true
EOF注: 我这里使用了已有的docker network:zookeeper-net,如果没有需要创建,或者修改docker-compose为已有network。
启动spark
bash
docker-compose up -d
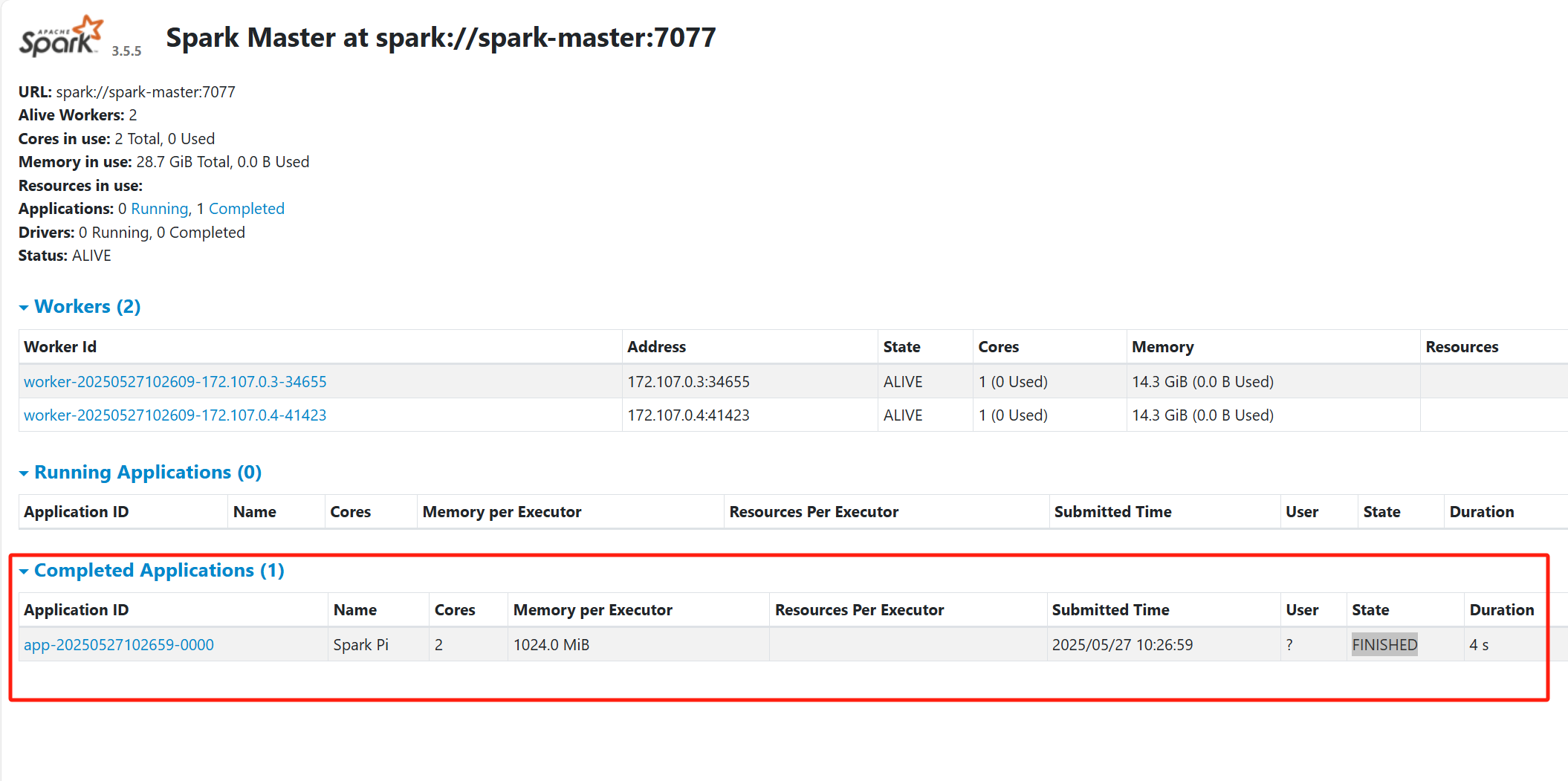
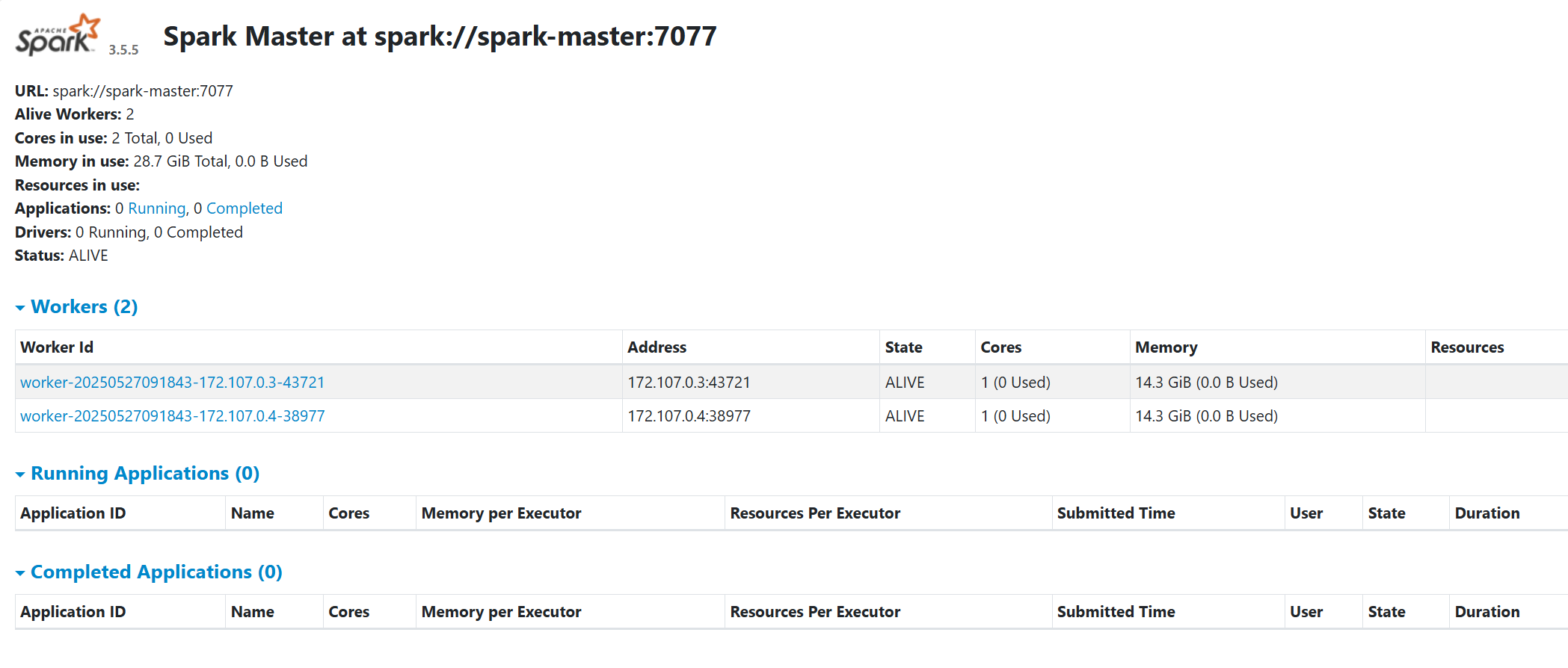
验证 Spark 运行状态
访问 Spark Master 的 Web UI,查看集群状态。默认情况下,Master 的 Web UI 运行在 8080 端口,可以通过以下命令查看:
bash
curl http://localhost:8080也可以直接浏览器访问:
日志查看
bash
docker-compose logs master worker1 worker2提交 Spark 作业
bash
docker exec -it spark-master /bin/bash
bash
spark-submit --master spark://spark-master:7077 \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.5.5.jar 10报错:
Exception in thread "main" java.lang.IllegalArgumentException: basedir must be absolute: ?/.ivy2/local at org.apache.ivy.util.Checks.checkAbsolute(Checks.java:48)
解决:
1、echo "spark.jars.ivy /opt/bitnami/spark/ivy" >> conf/spark-defaults.conf
2、重启spark
docker-compose down -v
docker-compose up -d
3、再次提交作业,成功完成。