存储系统概述
Apache DolphinScheduler 的存储系统提供统一接口 ,支持跨多种存储后端(如本地文件系统、云存储)进行文件存取。其核心功能是管理工作流和任务所需的资源文件(如脚本、JAR包、配置文件),并通过抽象底层存储技术,实现无缝切换存储方案而无需修改应用代码。
架构设计
存储系统采用插件化架构,通过标准化 API 屏蔽不同存储实现的差异,确保资源操作的统一性。以下是核心架构模型:
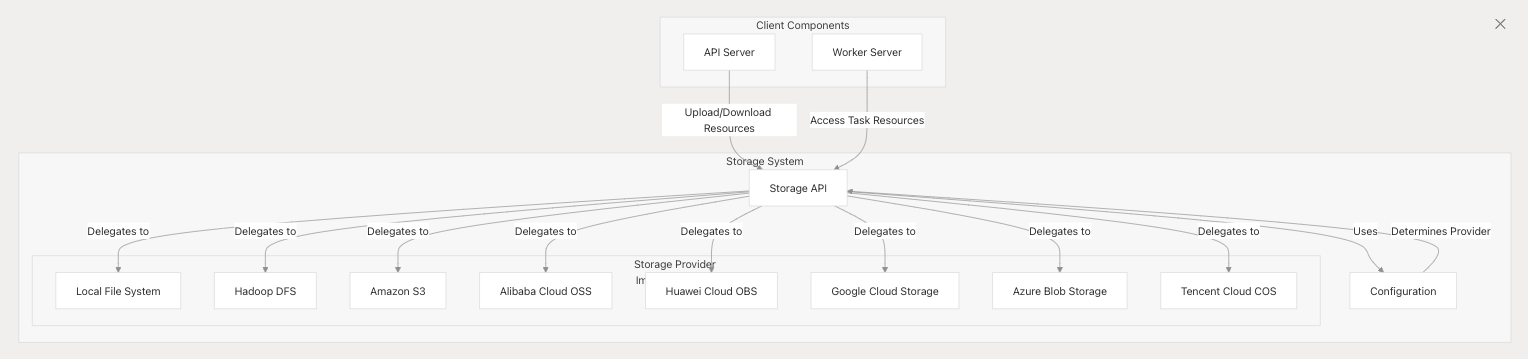
支持的存储类型
| 存储类型 | 描述 | 使用场景 |
|---|---|---|
| LOCAL | 服务器本地文件系统 | 开发测试、单节点部署 |
| HDFS | Hadoop分布式文件系统 | 基于Hadoop生态的生产环境 |
| S3 | 亚马逊S3或兼容S3协议的存储 | AWS云环境或S3兼容存储 |
| OSS | 阿里云对象存储服务 | 阿里云部署环境 |
| GCS | 谷歌云存储 | Google Cloud Platform部署 |
| ABS | Azure Blob存储 | Microsoft Azure云环境 |
| OBS | 华为云对象存储服务 | 华为云部署 |
| COS | 腾讯云对象存储 | 腾讯云部署 |
插件架构实现
存储功能通过插件化设计实现,让用户可以轻松进行拓展和维护。
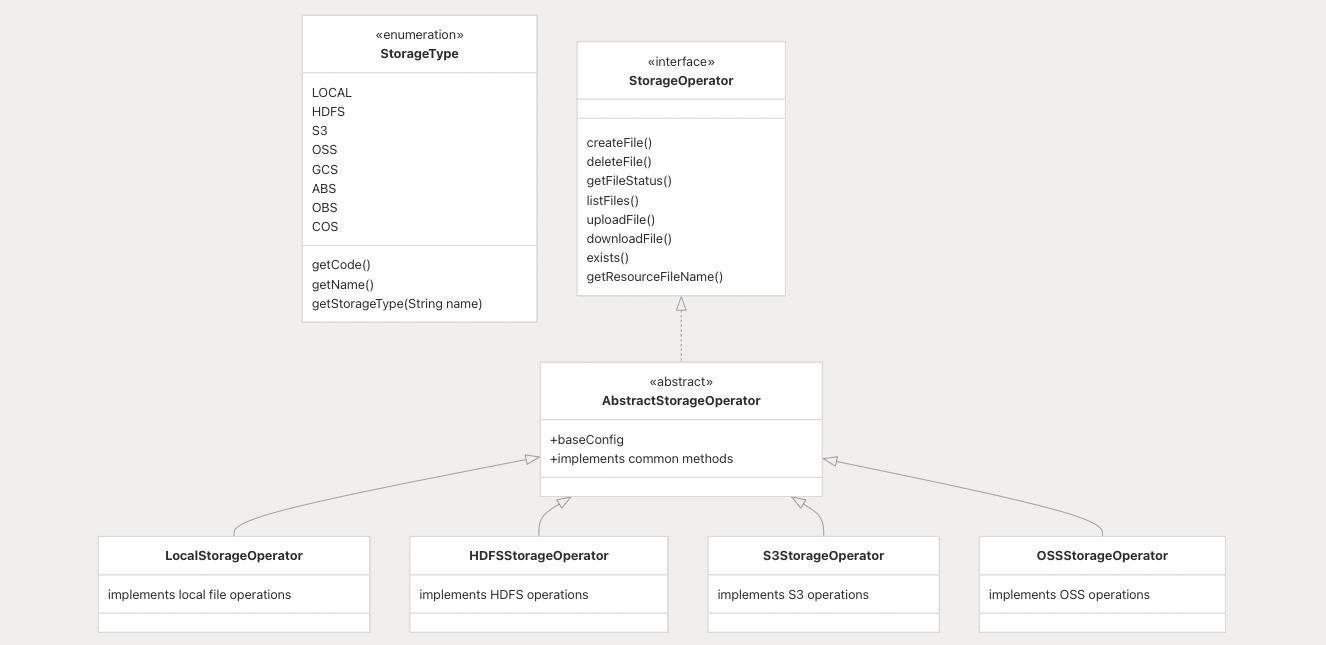
配置与部署
配置文件路径:dolphinscheduler-common/src/main/resources/common.properties。
基础配置
在 common.properties 中定义存储类型及基础路径:
properties
# 存储类型:LOCAL, HDFS, S3, OSS, GCS, ABS, OBS, COS
resource.storage.type=LOCAL
# 资源存储基础路径
resource.storage.upload.base.path=/tmp/dolphinscheduler 配置加载流程
DolphinScheduler 启动时按以下逻辑初始化存储操作器:
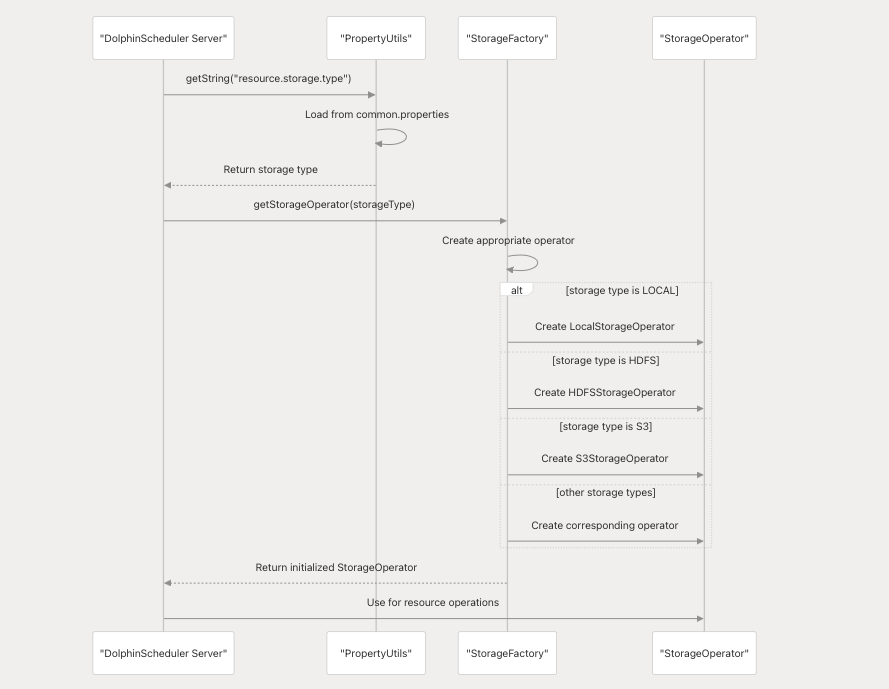
存储类型配置示例
1. 本地存储(LOCAL)
properties
resource.storage.type=LOCAL
resource.storage.upload.base.path=/data/dolphinscheduler 注意:多节点部署时,需使用共享存储(如NFS)确保文件一致性。
2. HDFS存储
properties
resource.storage.type=HDFS
# HDFS地址
resource.hdfs.fs.defaultFS=hdfs://namenode:8020
# HDFS用户
resource.hdfs.root.user=hdfs Kerberos认证扩展配置:
properties
resource.hdfs.kerberos.enable=true
resource.hdfs.kerberos.principal=hdfs@EXAMPLE.COM
resource.hdfs.kerberos.keytab=/etc/security/keytabs/hdfs.keytab 3. 亚马逊S3存储
properties
resource.storage.type=S3 aws.yaml 中配置S3连接参数:
yaml
aws:
s3:
credentials.provider.type: AWSStaticCredentialsProvider
access.key.id: <access-key>
access.key.secret: <secret-key>
region: us-east-1
bucket.name: dolphinscheduler
endpoint: s3.amazonaws.com 4. 其他云存储
- 阿里云OSS :配置
resource.storage.type=OSS,需指定oss.endpoint和访问密钥。 - 华为云OBS :配置
resource.storage.type=OBS,需设置obs.endpoint及区域信息。 - 腾讯云COS :配置
resource.storage.type=COS,需定义cos.region和桶名称。
资源数据库表结构
除了实际文件存储,DolphinScheduler 还会在数据库中维护资源的元数据。相关数据库表包括:
- 资源元数据表:存储资源相关信息(如名称、路径、所有者等)。
- 资源-用户关系表:定义资源访问权限。
组件间集成关系
存储系统通过以下方式与 DolphinScheduler 其他模块交互:
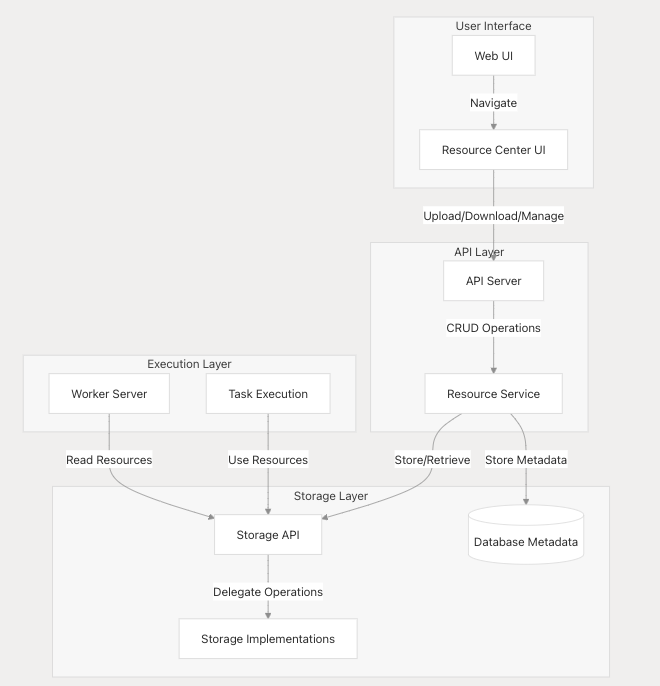
存储类型选型建议
核心考量因素
| 因素 | 说明 |
|---|---|
| 单节点 vs 多节点 | 单节点部署可用 LOCAL;多节点需用 HDFS 或云存储(如S3、OSS)。 |
| 性能 | LOCAL 性能最佳但无分布式能力;HDFS 适合本地集群;云存储适合云环境。 |
| 可靠性 | 云存储提供高持久性;本地 HDFS 需配置副本策略(如3副本)。 |
| 集成成本 | 已有 Hadoop 集群或云环境时,优先选择对应存储方案以减少适配成本。 |
| 费用 | 云存储按存储量、请求次数计费;本地存储需硬件和维护成本。 |
配置最佳实践
-
配置一致性
确保所有 DolphinScheduler 节点(API Server 和 Worker)的
common.properties中存储配置完全一致,避免因配置差异导致资源路径错误。 -
权限管理
- 运行 DolphinScheduler 的系统用户需有存储后端的读写权限(如HDFS用户、S3 Bucket策略)。
- 云存储建议使用最小权限原则(如仅允许特定目录的操作)。
-
共享存储
分布式部署时,必须使用共享存储(如
HDFS、S3),禁止使用LOCAL,否则不同节点无法访问同一资源。 -
安全性
- 敏感信息(如S3密钥)通过加密配置或环境变量传递,避免明文写入文件。
- 定期轮换云存储访问密钥。
-
备份策略
- 对关键资源(如生产环境脚本)启用版本控制或定期快照。
- 结合存储后端特性实现自动备份(如S3版本控制、HDFS快照)。
本文为AI生成,仅供参考,如需具体配置示例或进一步技术细节,可参考官方文档对应章节。