第三部分:文本分类
python
import pandas as pd
books = pd.read_csv("/content/books_cleaned.csv")
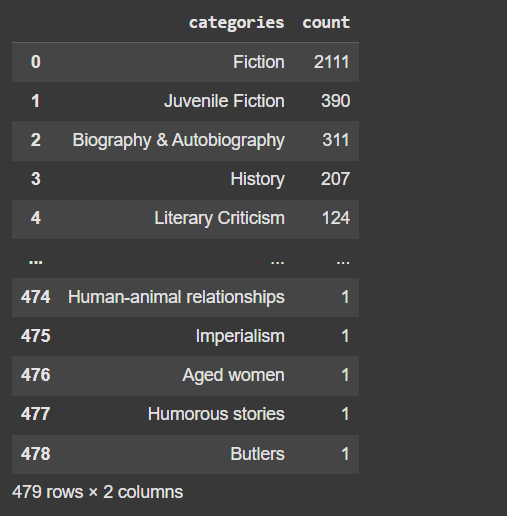
books["categories"].value_counts().reset_index()books"categories".value_counts()
→ 统计 books 数据框中 categories 列的各类别出现的次数,结果是一个按出现频率排序的 Series
.reset_index()
→ 将 value_counts() 结果从 Series 转换为 DataFrame,并把类别变成一列
python
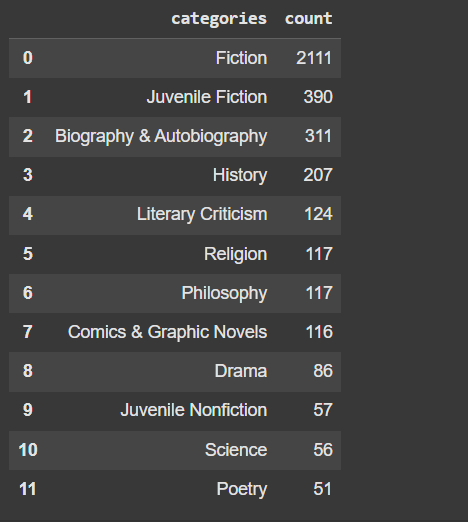
books["categories"].value_counts().reset_index().query("count > 50")筛选出 出现次数大于 50 的类别。
python
books[books["categories"] == "Juvenile Fiction"]在 categories 列中,找出值等于 "Juvenile Fiction" 的行
python
books[books["categories"] == "Juvenile Nonfiction"]
python
category_mapping = {'Fiction' : "Fiction",
'Juvenile Fiction': "Children's Fiction",
'Biography & Autobiography': "Nonfiction",
'History': "Nonfiction",
'Literary Criticism': "Nonfiction",
'Philosophy': "Nonfiction",
'Religion': "Nonfiction",
'Comics & Graphic Novels': "Fiction",
'Drama': "Fiction",
'Juvenile Nonfiction': "Children's Nonfiction",
'Science': "Nonfiction",
'Poetry': "Fiction"}
books["simple_categories"] = books["categories"].map(category_mapping)key(原始类别):来自 books 数据框中的 categories 列,例如 "Fiction"、"Biography & Autobiography"。
value(简化类别):你希望把原始类别重新归类到更简单、更高层次的分类标签,例如 "Fiction"、"Nonfiction" 或 "Children's Fiction"。
对 books"categories" 列进行遍历:
- 如果 categories 中的值(例如 "Fiction")存在于 category_mapping 字典中,就返回对应的新值(例如 "Fiction")。
- 如果没有匹配的 key,结果会是 NaN(缺失值)。
python
books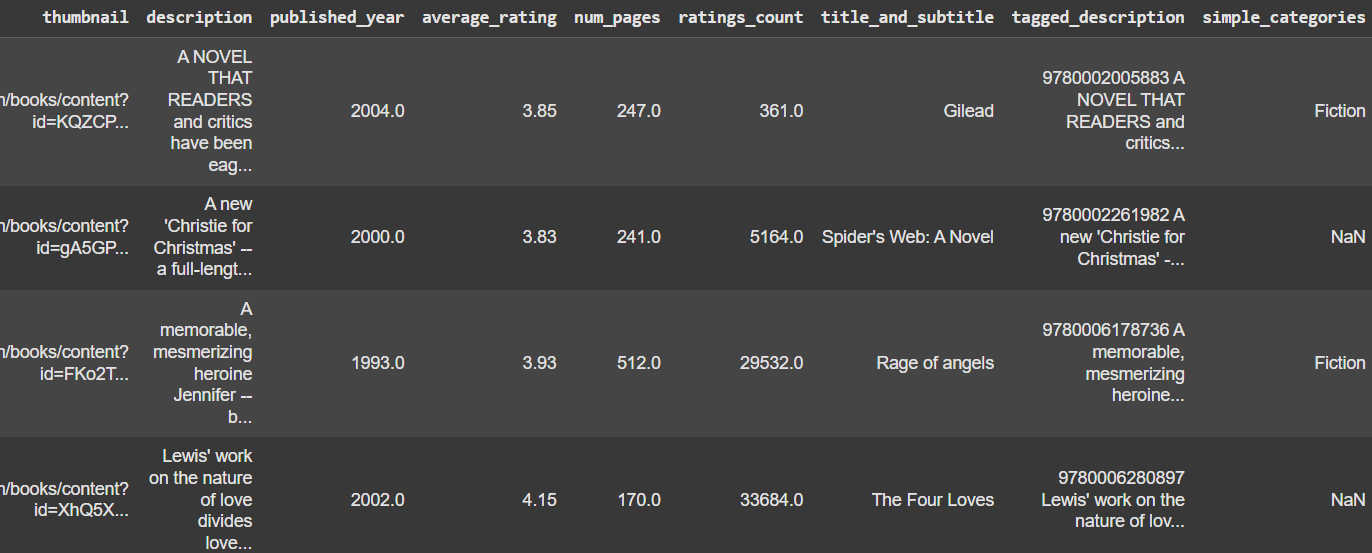
python
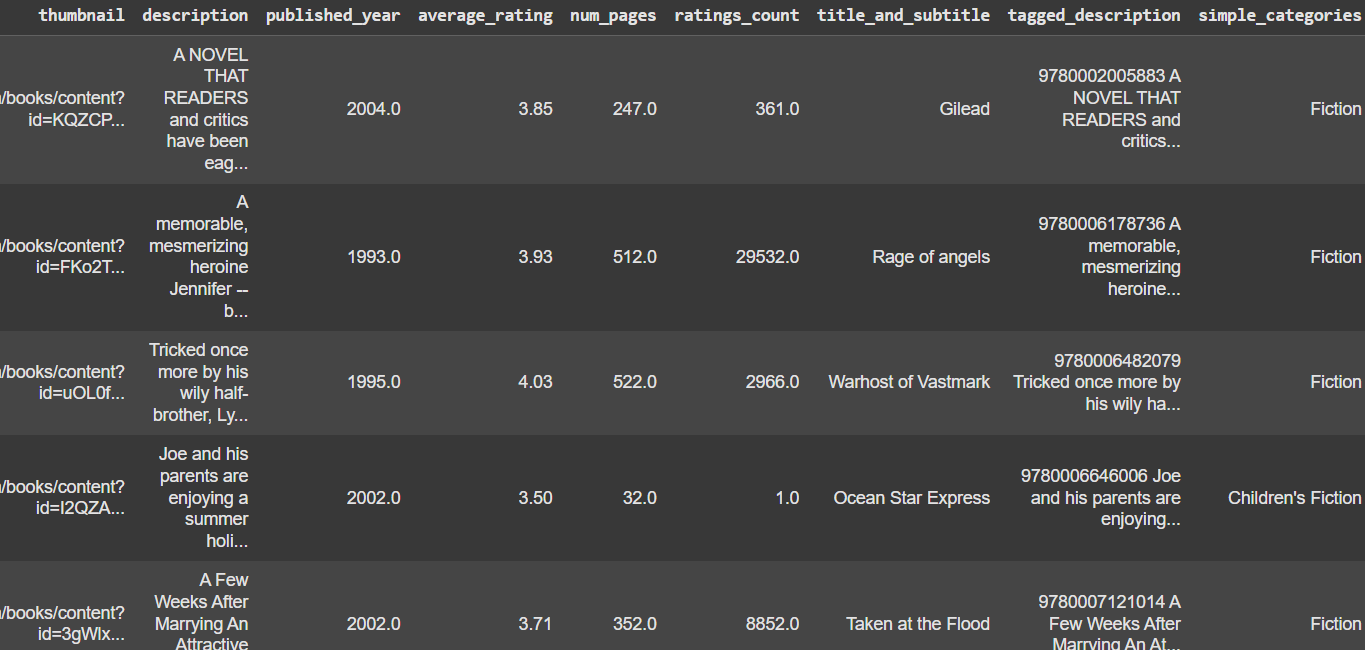
books[~(books["simple_categories"].isna())]books"simple_categories".isna()
这一部分会检查 books DataFrame 中的 "simple_categories" 列,是否有缺失值(NaN)。
返回结果是一个布尔序列(True 表示是缺失值,False 表示不是缺失值)。
~ 是 按位取反(逻辑非)运算符:
把 True 变为 False
把 False 变为 True
这行代码会 筛掉缺失了简化类别的行,保留那些已经被成功分类的图书记录。
python
from transformers import pipeline
fiction_categories = ["Fiction", "Nonfiction"]
pipe = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli",
device=0)
sequence = books.loc[books["simple_categories"] == "Fiction", "description"].reset_index(drop=True)[0]
pipe(sequence, fiction_categories)从 Hugging Face 的 transformers 库中引入 pipeline。
pipeline 是一个高层封装,可以快速加载模型进行推理任务,比如文本分类、问答、生成等。
定义一个分类标签列表,表示想要区分的两大类:
"Fiction"(小说类)
"Nonfiction"(非小说类)
创建一个 零样本分类 (zero-shot classification) 管道。
使用 Hugging Face 预训练模型 facebook/bart-large-mnli
device=0 表示使用第一个 GPU,如果没有 GPU,这里可以省略或设为 -1 来用 CPU。
从 books 表格中,选出 simple_categories 为 "Fiction" 的图书描述 (description 列)。
.reset_index(drop=True):重新编号索引。
0:选择第一行的 description 内容,作为 sequence(文本内容)。
传入这段书籍描述和标签列表 "Fiction", "Nonfiction"。
模型会基于 BART-large-MNLI 判断:
这段描述属于 "Fiction" 还是 "Nonfiction"?
bash
{'sequence': 'A NOVEL THAT READERS and critics have been eagerly anticipating for over a decade, Gilead is an astonishingly imagined story of remarkable lives. John Ames is a preacher, the son of a preacher and the grandson (both maternal and paternal) of preachers. It's 1956 in Gilead, Iowa, towards the end of the Reverend Ames's life, and he is absorbed in recording his family's story, a legacy for the young son he will never see grow up. Haunted by his grandfather's presence, John tells of the rift between his grandfather and his father: the elder, an angry visionary who fought for the abolitionist cause, and his son, an ardent pacifist. He is troubled, too, by his prodigal namesake, Jack (John Ames) Boughton, his best friend's lost son who returns to Gilead searching for forgiveness and redemption. Told in John Ames's joyous, rambling voice that finds beauty, humour and truth in the smallest of life's details, Gilead is a song of celebration and acceptance of the best and the worst the world has to offer. At its heart is a tale of the sacred bonds between fathers and sons, pitch-perfect in style and story, set to dazzle critics and readers alike.',
'labels': ['Fiction', 'Nonfiction'],
'scores': [0.8438267111778259, 0.15617327392101288]}
python
import numpy as np
max_index = np.argmax(pipe(sequence, fiction_categories)["scores"])
max_label = pipe(sequence, fiction_categories)["labels"][max_index]
max_label调用 Hugging Face 的零样本分类管道 pipe() 进行推理
取出 scores 部分(一个列表,表示每个标签的概率分数)。
np.argmax() 找出最大分数的索引。
根据最大索引 max_index,从 labels 列表中取出对应的标签。
bash
Fiction
python
def generate_predictions(sequence, categories):
predictions = pipe(sequence, categories)
max_index = np.argmax(predictions["scores"])
max_label = predictions["labels"][max_index]
return max_labelsequence:待分类的文本字符串。
categories:分类标签列表,例如 "Fiction", "Nonfiction"。
调用 Hugging Face 的 zero-shot-classification 管道模型。
输入 sequence 和 categories,得到推理结果
从 predictions 中取出 scores 列表。
np.argmax() 找到分数最高的索引。
根据最大分数的索引 max_index,从 labels 中取出对应的标签。
python
from tqdm import tqdm
actual_cats = []
predicted_cats = []
for i in tqdm(range(0, 300)):
sequence = books.loc[books["simple_categories"] == "Fiction", "description"].reset_index(drop=True)[i]
predicted_cats += [generate_predictions(sequence, fiction_categories)]
actual_cats += ["Fiction"]-
创建一个空列表,用于存储实际类别标签(ground truth),这里就是 "Fiction"。
创建一个空列表,用于存储模型预测的类别标签。
-
从 books DataFrame 中,筛选出 simple_categories 等于 "Fiction" 的行。
只取出 description(图书描述文本)列。
使用 .reset_index(drop=True) 重置索引(防止原始索引的干扰)。
然后用 i 取出第 i 条描述文本,赋值给 sequence。
-
调用 generate_predictions 函数对 sequence 进行预测。
fiction_categories 是分类标签列表(例如:"Fiction", "Nonfiction")。
得到预测结果,例如 "Fiction" 或 "Nonfiction"。
把结果以列表形式 \[\] 添加到 predicted_cats 列表中。
例如:predicted_cats += "Fiction"。
-
循环结束后,actual_cats 会是一个长度为 300 的列表,全部都是 "Fiction"。
predicted_cats 会是一个长度为 300 的列表,存放模型预测的标签结果(可能是 "Fiction" 或 "Nonfiction")。
python
for i in tqdm(range(0, 300)):
sequence = books.loc[books["simple_categories"] == "Nonfiction", "description"].reset_index(drop=True)[i]
predicted_cats += [generate_predictions(sequence, fiction_categories)]
actual_cats += ["Nonfiction"]筛选 simple_categories 列为 "Nonfiction" 的行。
只取出 description 列(图书的描述文字)。
reset_index(drop=True) 重置索引,防止原始索引带来的干扰。
通过 i 取出第 i 条文本,赋值给 sequence。
调用 zero-shot 模型(generate_predictions 函数),对 sequence 进行预测,判断它是 "Fiction" 还是 "Nonfiction"。
把预测结果(例如 "Nonfiction")追加到 predicted_cats 列表中。
因为我们处理的是 simple_categories 为 "Nonfiction" 的文本,所以实际标签肯定是 "Nonfiction"。
每次循环都加一个 "Nonfiction"。
python
predictions_df = pd.DataFrame({"actual_categories": actual_cats, "predicted_categories": predicted_cats})
predictions_df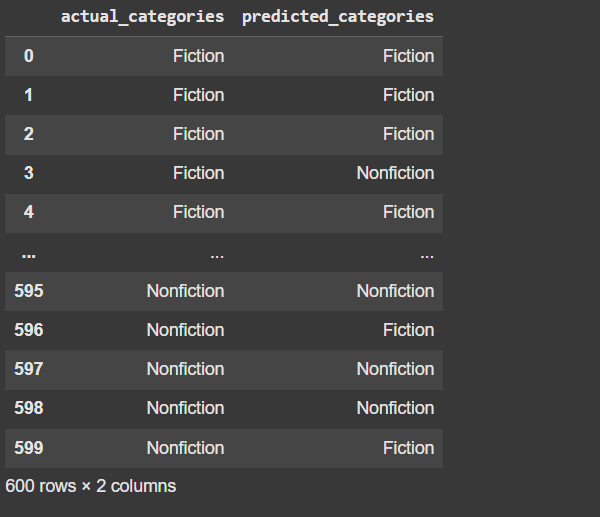
python
predictions_df["correct_prediction"] = (
np.where(predictions_df["actual_categories"] == predictions_df["predicted_categories"], 1, 0)
)np.where(条件, 值1, 值2) 是一个 Numpy 条件判断函数,表示:
如果 条件 为 True,返回 值1。
如果 条件 为 False,返回 值2。
如果预测的类别和实际类别相同,返回 True;
否则,返回 False。
python
predictions_df["correct_prediction"].sum() / len(predictions_df)
bash
np.float64(0.7783333333333333)
python
isbns = []
predicted_cats = []
missing_cats = books.loc[books["simple_categories"].isna(), ["isbn13", "description"]].reset_index(drop=True)isbns:用于存储需要补充分类的 ISBN 编号。
predicted_cats:用于存储 预测的类别(比如 Fiction / Nonfiction)。
这两个列表通常用来收集后续的预测结果和对应的 ISBN。
books"simple_categories".isna()
筛选出 simple_categories 这一列 缺失值(NaN) 的行。
这表示 这本书没有被归类为 Fiction / Nonfiction / Children's Fiction / Children's Nonfiction 等简化分类。
books.loc..., \["isbn13", "description"]
从筛选出来的书中,只取出两列数据:
isbn13(书的 ISBN 编号)
description(书的描述)
.reset_index(drop=True)
重置行索引。
drop=True 表示删除原有的索引,不保留原索引列,直接生成从 0 开始的新索引。
python
for i in tqdm(range(0, len(missing_cats))):
sequence = missing_cats["description"][i]
predicted_cats += [generate_predictions(sequence, fiction_categories)]
isbns += [missing_cats["isbn13"][i]]取出 missing_cats 中第 i 行的 description。
这个 sequence 是要进行 文本分类 的文本输入。
调用之前定义的 generate_predictions 函数:
传入 sequence(文本描述)。
传入 fiction_categories(分类标签列表:"Fiction", "Nonfiction")。
函数会返回一个预测的标签(如 "Fiction" 或 "Nonfiction")。
+= 表示将预测结果 追加到 predicted_cats 列表 中。
取出 missing_cats 第 i 行的 isbn13,并追加到 isbns 列表中。
这样,isbns 和 predicted_cats 就一一对应,形成了 每本书的 ISBN → 预测分类 的配对。
python
missing_predicted_df = pd.DataFrame({"isbn13": isbns, "predicted_categories": predicted_cats})
missing_predicted_df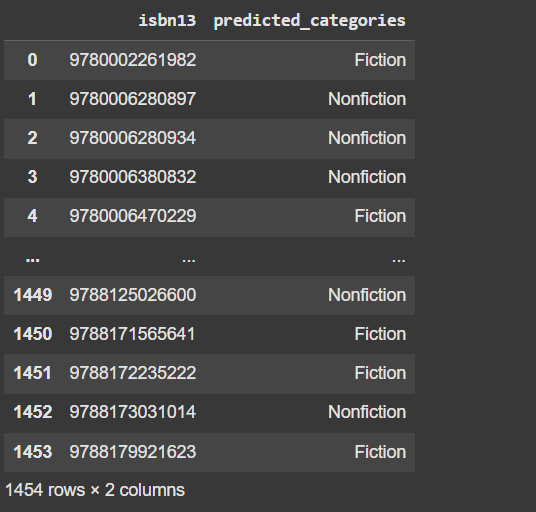
python
books = pd.merge(books, missing_predicted_df, on="isbn13", how="left")
books["simple_categories"] = np.where(books["simple_categories"].isna(), books["predicted_categories"], books["simple_categories"])
books = books.drop(columns = ["predicted_categories"])
bookspd.merge():把两个 DataFrame 合并在一起。
合并的对象:
books:原始书籍数据。
missing_predicted_df:包含 isbn13 和 predicted_categories 的预测结果 DataFrame。
on="isbn13":按照 isbn13(每本书的唯一标识)来匹配。
how="left":以 books 为基准,保持所有原有行,预测结果根据匹配的 isbn13 合并进来。如果某行 isbn13 在 missing_predicted_df 中没有匹配,就会得到 NaN。
如果 books"simple_categories" 是缺失值 (NaN),就用 books"predicted_categories" 填补。
否则,保持原值不变。
预测结果 predicted_categories 已经用完了(填补完分类后),就不需要再保留了。
所以通过 drop() 删除掉这列,保持数据整洁。
python
books[books["categories"].str.lower().isin([
"romance",
"science fiction",
"scifi",
"fantasy",
"horror",
"mystery",
"thriller",
"comedy",
"crime",
"historical"
])]把 books 数据表的 categories 列(图书类别)全部转换为小写形式。
这样做的目的是为了避免因大小写不同导致匹配失败,比如 "Romance" 和 "romance" 被视为不同。
判断 categories 列的值是否存在于我们指定的列表中(例如 "romance"、"fantasy" 等)。
isin() 的作用是:
如果当前行的类别在这个列表里,就返回 True。
否则返回 False。
外层的 books... 就是通过布尔索引,筛选出满足条件的行(即类别在指定列表中的行)。
最终得到的结果是一个 只包含这些类别书籍 的子集。
python
books.to_csv("books_with_categories.csv", index=False)