机器学习入门核心算法:逻辑回归(Decision Tree)
- 一、算法逻辑
-
-
- [1.1 基本概念](#1.1 基本概念)
- [1.2 算法流程](#1.2 算法流程)
-
- 二、算法原理与数学推导
-
-
- [2.1 特征选择指标](#2.1 特征选择指标)
-
- 信息熵(ID3算法)
- [信息增益(Information Gain)](#信息增益(Information Gain))
- 信息增益率(C4.5算法)
- 基尼系数(CART算法)
- [2.2 决策树生成算法](#2.2 决策树生成算法)
- [2.3 剪枝处理](#2.3 剪枝处理)
-
- 三、模型评估
-
-
- [3.1 评估指标](#3.1 评估指标)
- [3.2 学习曲线分析](#3.2 学习曲线分析)
-
- 四、应用案例
-
-
- [4.1 鸢尾花分类](#4.1 鸢尾花分类)
- [4.2 金融风控评分卡](#4.2 金融风控评分卡)
-
- 五、经典面试题
- 六、高级优化技术
-
-
- [6.1 多变量决策树](#6.1 多变量决策树)
- [6.2 增量学习](#6.2 增量学习)
- [6.3 异构决策树](#6.3 异构决策树)
-
- 七、最佳实践指南
-
-
- [7.1 参数调优建议](#7.1 参数调优建议)
- [7.2 特征处理技巧](#7.2 特征处理技巧)
-
- 总结与展望
一、算法逻辑
1.1 基本概念
决策树是一种树形结构监督学习算法,通过递归地将特征空间划分为互不重叠的区域来完成分类或回归任务。核心组成元素:
- 根节点:包含全体数据的起始节点
- 内部节点:表示特征判断条件的分支节点
- 叶节点:存放最终决策结果的终端节点
关键特点:
- 天然支持可解释性(白盒模型)
- 可处理数值型和类别型数据
- 通过树深度控制模型复杂度
1.2 算法流程
构建决策树的递归过程:
- 选择当前最优划分特征
- 根据特征取值分割数据集
- 对每个子集重复上述过程直到:
- 节点样本纯度达到阈值
- 达到最大树深度
- 样本数量小于分裂阈值
决策过程可视化:
python
是否年龄>30?
├── 是 → 是否有房产?
│ ├── 是 → 批准贷款
│ └── 否 → 拒绝贷款
└── 否 → 收入>50k?
├── 是 → 批准贷款
└── 否 → 拒绝贷款二、算法原理与数学推导
2.1 特征选择指标
信息熵(ID3算法)
衡量数据集混乱程度:
E n t ( D ) = − ∑ k = 1 K p k log 2 p k Ent(D) = -\sum_{k=1}^K p_k \log_2 p_k Ent(D)=−k=1∑Kpklog2pk
其中 p k p_k pk为第 k k k类样本的比例
信息增益(Information Gain)
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D, a) = Ent(D) - \sum_{v=1}^V \frac{|D^v|}{|D|} Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
缺点:偏向选择取值多的特征
信息增益率(C4.5算法)
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain\_ratio(D, a) = \frac{Gain(D, a)}{IV(a)} Gain_ratio(D,a)=IV(a)Gain(D,a)
其中固有值:
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ IV(a) = -\sum_{v=1}^V \frac{|D^v|}{|D|} \log_2 \frac{|D^v|}{|D|} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
基尼系数(CART算法)
G i n i ( D ) = 1 − ∑ k = 1 K p k 2 Gini(D) = 1 - \sum_{k=1}^K p_k^2 Gini(D)=1−k=1∑Kpk2
基尼指数:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini\index(D, a) = \sum{v=1}^V \frac{|D^v|}{|D|} Gini(D^v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
2.2 决策树生成算法
ID3算法伪代码:
python
def create_tree(D, A):
if D中样本全属于同一类别C:
return 叶节点标记为C
if A = ∅ or D在所有特征上取值相同:
return 叶节点标记为D中最多类
选择最优划分特征a*
生成分支节点:
for a*的每个取值v:
Dv = D中在a*上取值为v的子集
if Dv为空:
分支标记为D中最多类
else:
递归调用create_tree(Dv, A-{a*})
return 分支节点2.3 剪枝处理
预剪枝(Pre-pruning)
在树生成过程中提前停止分裂:
- 设置最大深度
max_depth - 设置节点最小样本数
min_samples_split - 设置信息增益阈值
min_impurity_decrease
后剪枝(Post-pruning)
生成完整树后进行剪枝:
- 计算节点经验熵:
C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha}(T) = C(T) + \alpha |T| Cα(T)=C(T)+α∣T∣- C ( T ) C(T) C(T):模型对训练数据的预测误差
- ∣ T ∣ |T| ∣T∣:叶节点个数
- 自底向上递归剪枝,选择使 C α C_{\alpha} Cα最小的子树
三、模型评估
3.1 评估指标
| 任务类型 | 常用指标 | 计算公式 |
|---|---|---|
| 分类 | 准确率、F1 Score、AUC | A c c u r a c y = T P + T N N Accuracy = \frac{TP+TN}{N} Accuracy=NTP+TN |
| 回归 | MSE、MAE、R² | M S E = 1 n ∑ ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum(y_i-\hat{y}_i)^2 MSE=n1∑(yi−y^i)2 |
3.2 学习曲线分析
过拟合识别:
python
训练集准确率:0.98
测试集准确率:0.72
→ 模型过拟合解决方案:
- 增加剪枝强度
- 减少树的最大深度
- 使用集成方法(如随机森林)
四、应用案例
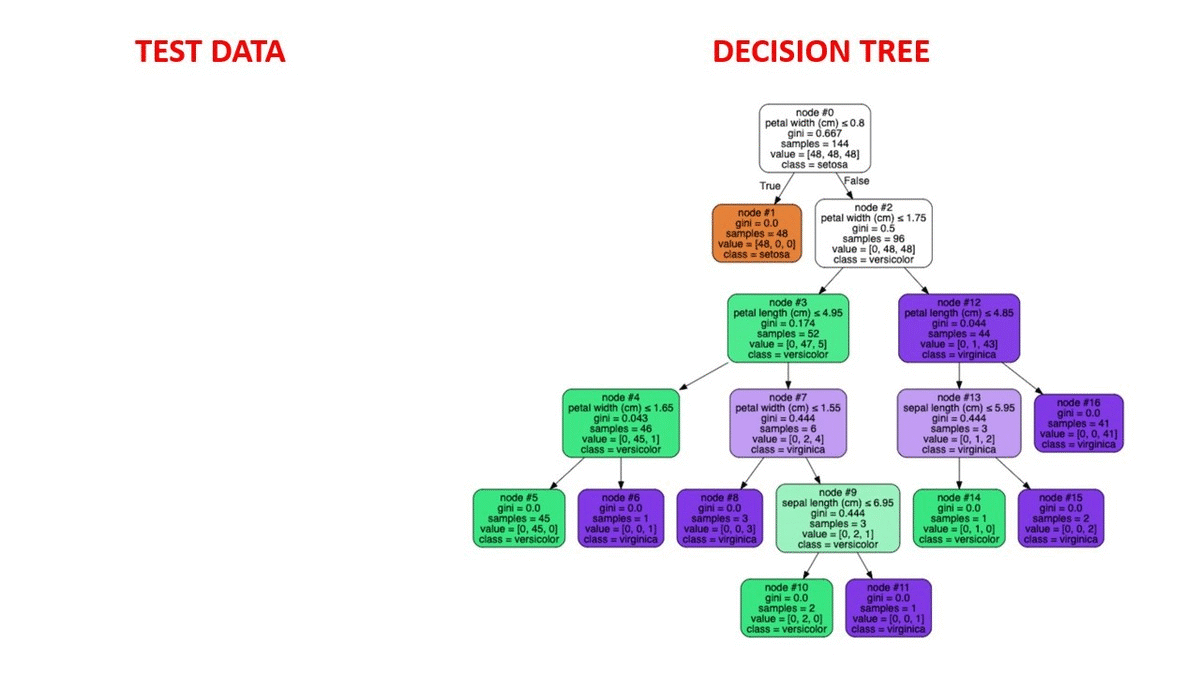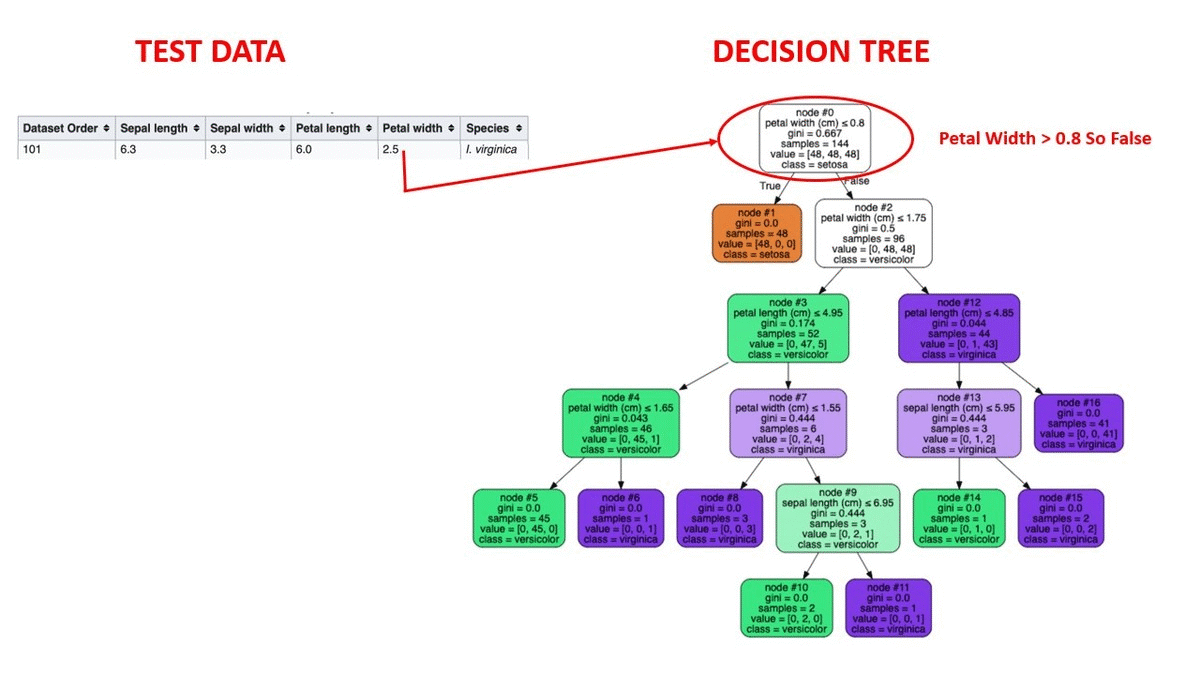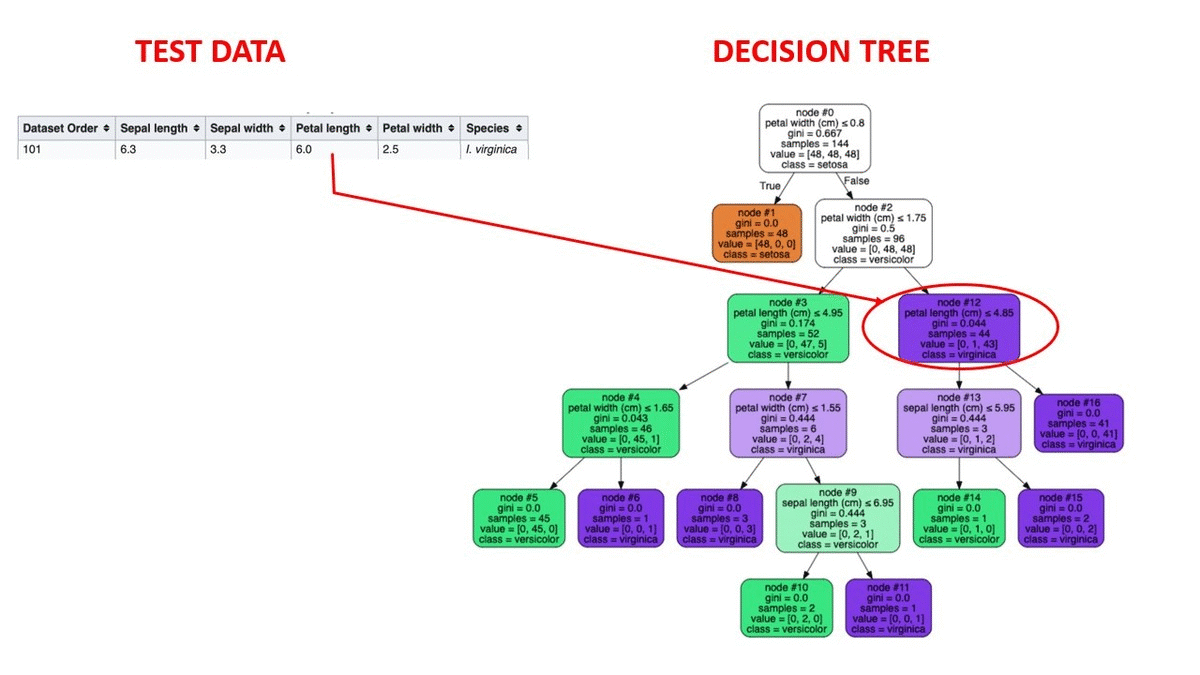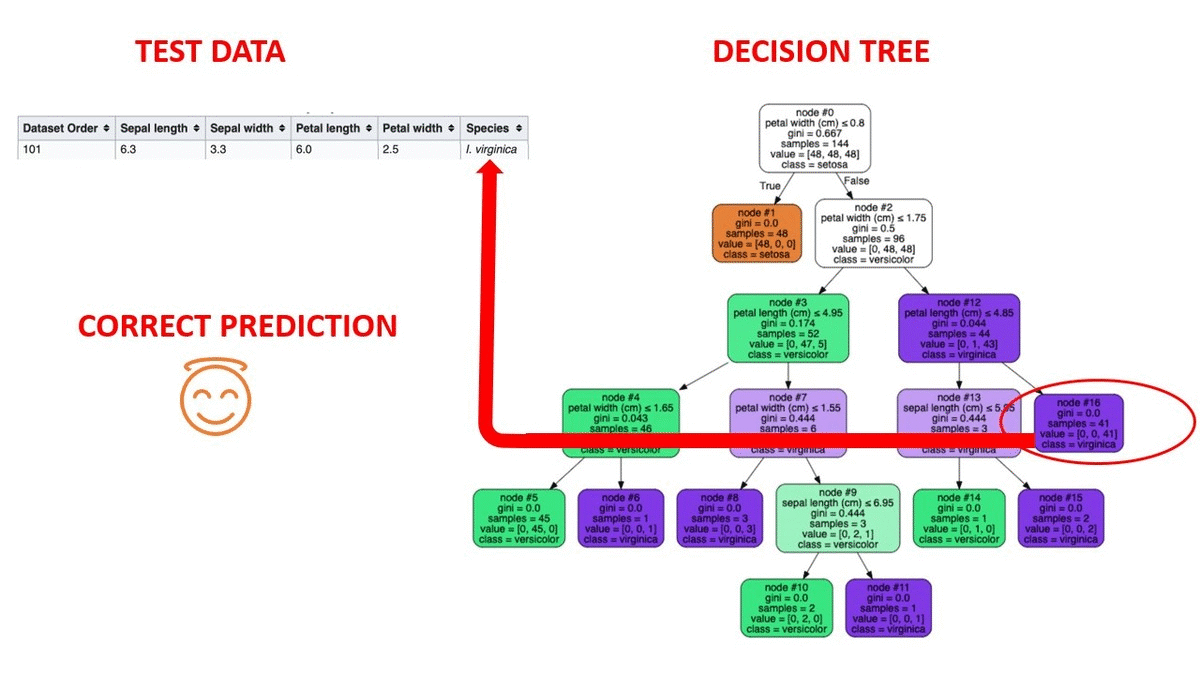
4.1 鸢尾花分类
数据集 :150个样本,4个特征(花萼长宽、花瓣长宽)
实现代码:
python
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
iris = load_iris()
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(iris.data, iris.target)
# 可视化决策树
from sklearn.tree import plot_tree
plot_tree(clf, feature_names=iris.feature_names)模型效果:
- 准确率:0.96
- 关键分裂特征:花瓣长度(Petal length)
4.2 金融风控评分卡
业务场景 :信用卡申请风险评估
特征工程:
- WOE编码处理类别变量:
W O E i = ln ( B a d i / T o t a l B a d G o o d i / T o t a l G o o d ) WOE_i = \ln\left(\frac{Bad_i/TotalBad}{Good_i/TotalGood}\right) WOEi=ln(Goodi/TotalGoodBadi/TotalBad) - IV值筛选特征:
I V = ∑ ( B a d % − G o o d % ) × W O E IV = \sum (Bad\% - Good\%) \times WOE IV=∑(Bad%−Good%)×WOE
模型输出:
- 高风险客户识别率:82%
- KS值:0.48
五、经典面试题
问题1:ID3、C4.5、CART的区别?
对比分析:
| 算法 | 分裂标准 | 任务类型 | 树结构 | 缺失值处理 |
|---|---|---|---|---|
| ID3 | 信息增益 | 分类 | 多叉树 | 不支持 |
| C4.5 | 信息增益率 | 分类 | 多叉树 | 支持 |
| CART | 基尼系数/MSE | 分类/回归 | 二叉树 | 支持 |
问题2:如何处理连续特征?
解决方案:
- 排序所有特征值: a 1 , a 2 , . . . , a n a_1, a_2,...,a_n a1,a2,...,an
- 计算候选划分点:
T a = { a i + a i + 1 2 ∣ 1 ≤ i ≤ n − 1 } T_a = \left\{\frac{a_i + a_{i+1}}{2} | 1 \leq i \leq n-1\right\} Ta={2ai+ai+1∣1≤i≤n−1} - 选择使指标最优的划分点:
G a i n ( D , a , t ) = E n t ( D ) − ∣ D l ∣ ∣ D ∣ E n t ( D l ) − ∣ D r ∣ ∣ D ∣ E n t ( D r ) Gain(D, a, t) = Ent(D) - \frac{|D^l|}{|D|}Ent(D^l) - \frac{|D^r|}{|D|}Ent(D^r) Gain(D,a,t)=Ent(D)−∣D∣∣Dl∣Ent(Dl)−∣D∣∣Dr∣Ent(Dr)
问题3:决策树的优缺点?
优势分析:
- 直观易懂,可视化效果好
- 无需数据归一化
- 自动特征选择
主要缺点:
- 容易过拟合
- 对样本扰动敏感
- 忽略特征间相关性
六、高级优化技术
6.1 多变量决策树
在非叶节点使用线性组合进行划分:
∑ i = 1 d w i x i > t \sum_{i=1}^d w_i x_i > t i=1∑dwixi>t
优势:能捕捉特征间交互作用
6.2 增量学习
支持在线更新决策树:
- 保留历史划分结构
- 仅更新统计量
- 动态调整分裂点
6.3 异构决策树
混合不同分裂标准:
- 上层使用信息增益率
- 下层使用基尼指数
七、最佳实践指南
7.1 参数调优建议
| 参数 | 推荐值范围 | 作用说明 |
|---|---|---|
| max_depth | 3-10 | 控制模型复杂度 |
| min_samples_split | 10-100 | 防止过拟合 |
| ccp_alpha | 0.01-0.1 | 后剪枝强度 |
7.2 特征处理技巧
- 类别变量:优先使用目标编码而非One-Hot
- 缺失值:采用代理分裂(Surrogate Splits)
- 高基数特征:进行分箱处理
总结与展望
决策树作为基础机器学习算法,具有模型直观 、训练高效的特点,在金融风控、医疗诊断等领域广泛应用。随着技术的发展,决策树的改进方向包括:
- 与神经网络结合(如深度森林)
- 自动化特征工程
- 分布式计算优化