200. 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
"1","1","1","1","0",
"1","1","0","1","0",
"1","1","0","0","0",
"0","0","0","0","0"
]
输出:1
示例 2:输入:grid = [
"1","1","0","0","0",
"1","1","0","0","0",
"0","0","1","0","0",
"0","0","0","1","1"
]
输出:3
把访问过的岛屿插满旗子------避免重复访问和无限递归
题解参见:灵茶山艾府
- 【思路】
python
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
m, n = len(grid), len(grid[0]) # 不用修改,所以不用在dfs中nonlocal声明
def dfs(i: int, j: int) -> None:
# 出界,或者不是 '1',就不再往下递归
if i < 0 or i >= m or j < 0 or j >= n or grid[i][j] != '1':
return
grid[i][j] = '2' # 插旗!避免来回横跳无限递归
dfs(i, j - 1) # 向左
dfs(i, j + 1) # 向右
dfs(i - 1, j) # 向上
dfs(i + 1, j) # 向下
res = 0
for i, row in enumerate(grid):
for j, val in enumerate(row):
if val == '1':
dfs(i, j) # 把此元素val所在岛屿上插满旗子,这样后面遍历到的 '1' 一定是新的岛
res += 1
return res- 时间复杂度 O(mn)
- 空间复杂度 O(mn)
994. 腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
值 0 代表空单元格;
值 1 代表新鲜橘子;
值 2 代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
示例 1:
输入:grid = \[2,1,1,1,1,0,0,1,1]
输出:4
示例 2:输入:grid = \[2,1,1,0,1,1,1,0,1]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
示例 3:输入:grid = \[0,2]
输出:0
解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
BFS
以下题解搬运自:灵茶山艾府
看示例 1:
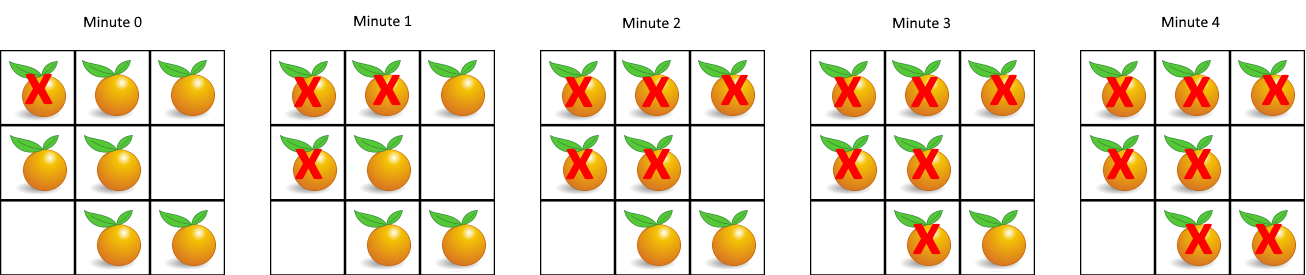
- 统计所有初始就腐烂的橘子的位置,加到列表 q 中,现在 q=(0,0)。
- 初始化答案 ans=0。模拟橘子腐烂的过程,不断循环,直到没有新鲜橘子,或者 q 为空。
- 答案加一,在第 ans=1 分钟,遍历 q 中橘子的四方向相邻的新鲜橘子,把这些橘子腐烂,q 更新为这些橘子的位置,现在 q=(0,1),(1,0)。
- 答案加一,在第 ans=2 分钟,遍历 q 中橘子的四方向相邻的新鲜橘子,把这些橘子腐烂,q 更新为这些橘子的位置,现在 q=(0,2),(1,1)。
- 答案加一,在第 ans=3 分钟,遍历 q 中橘子的四方向相邻的新鲜橘子,把这些橘子腐烂,q 更新为这些橘子的位置,现在 q=(2,1)。
- 答案加一,在第 ans=4 分钟,遍历 q 中橘子的四方向相邻的新鲜橘子,把这些橘子腐烂,q 更新为这些橘子的位置,现在 q=(2,2)。
- 由于没有新鲜橘子,退出循环。
为了判断是否有永远不会腐烂的橘子(如示例 2),我们可以统计初始新鲜橘子的个数fresh。在 BFS 中,每有一个新鲜橘子被腐烂,就把fresh减一,这样最后如果发现fresh>0,就意味着有橘子永远不会腐烂,返回−1。
代码实现时,在 BFS 中要将 grid[i][j]=1 的橘子修改成 2(或者其它不等于 1 的数),这可以保证每个橘子加入 q 中至多一次。如果不修改,我们就无法知道哪些橘子被腐烂过了,比如示例 1 中 (0,1) 去腐烂 (1,1),而 (1,1) 在此之后又重新腐烂 (0,1),如此反复,程序就会陷入死循环。读者可以注释掉下面代码中的 grid[i][j] = 2 这行代码试试。
- 【步骤】
- 第一步:初始化
- 用
fresh统计新鲜橘子的总数 - 用列表
q统计所有腐烂的橘子位置 - 初始化时间计数器
res = 0
- 用
- 第二步:BFS遍历
- 外层循环:当队列不为空且还有新鲜橘子时继续
- 时间递增:每轮循环开始时
res+= 1,代表过了一分钟 - 当前层处理:
- 保存当前队列中的所有腐烂橘子(代表这一分钟开始时已经腐烂的橘子)
- 清空队列,准备存放下一分钟新腐烂的橘子
- 四方向扩散:
- 对每个当前腐烂的橘子,检查其四个相邻位置
- 如果相邻位置是新鲜橘子,则:
- 将其标记为腐烂(
grid[i][j] = 2) - 新鲜橘子数量减一(
fresh -= 1) - 将新腐烂的橘子加入队列
- 将其标记为腐烂(
- 第三步:返回结果
- 如果还有新鲜橘子剩余,说明有橘子永远不会腐烂,返回
-1 - 否则返回所用的时间
res
- 如果还有新鲜橘子剩余,说明有橘子永远不会腐烂,返回
- 第一步:初始化
python
class Solution:
def orangesRotting(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
fresh = 0
q = []
# 初始状态统计
for i, row in enumerate(grid):
for j, val in enumerate(row):
if val == 1:
fresh += 1 # 统计新鲜橘子个数
elif val == 2:
q.append((i, j)) # 一开始就腐烂的橘子
res = 0
while q and fresh: # 开始计时
res += 1 # 每轮时间加一
tmp = q
q = [] # 清空上一轮的腐烂位置,不然腐烂过的位置会重新腐烂
for x, y in tmp:
for i, j in (x - 1, y), (x + 1, y), (x, y - 1), (x, y + 1): # 本轮腐烂范围
if 0 <= i < m and 0 <= j < n and grid[i][j] == 1: # 若是新鲜橘子
fresh -= 1 # 就使其腐烂
grid[i][j] = 2
q.append((i, j))
return -1 if fresh else res- 时间复杂度 O(mn)
- 空间复杂度 O(mn)
207. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 a_i则 必须 先学习课程 b_i 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = \[1,0]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:输入:numCourses = 2, prerequisites = \[1,0,0,1]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
三色标记法
此题解搬运自:灵茶山艾府
- 【题意】给你一个有向图,判断图中是否有环。 (把每个
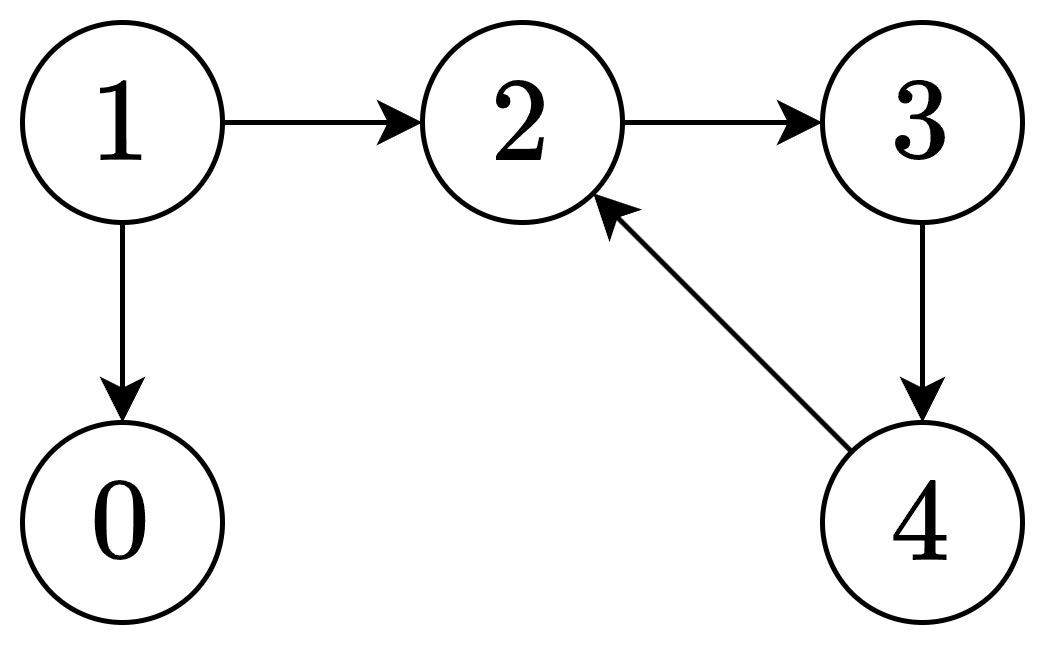
prerequisites[i]=[a,b]看成一条有向边b→a,构建一个有向图g:若图中有环,则说明不可能完成任务("互为先修课"))。 - 【如何找环?】例如下图
1→2→3→4→2,走到4的时候,发现下一个节点2在递归栈中("正在访问中"),那么就找到了环。
- 【三色标记法】对于每个节点 x,都定义三种颜色值(状态值):
- 0:节点 x 尚未被访问到。
- 1:节点 x 正在访问中,dfs(x) 尚未结束。
- 2:节点 x 已经完全访问完毕,dfs(x) 已返回。
- 【⚠误区】不能只用两种状态表示节点「没有访问过」和「访问过」。例如上图,我们先 dfs(0),再 dfs(1),此时 1 的邻居 0 已经访问过,但这并不能表示此时就找到了环。
- 【步骤】
- 建图:把每个
prerequisites[i]=[a,b]看成一条有向边b→a,构建一个有向图g。 - 创建长为
numCourses的颜色数组colors,所有元素值初始化成0。 - 遍历
colors,如果colors[i]=0,则调用递归函数dfs(i)。 - 执行
dfs(x):- 首先标记
colors[x]=1,表示节点x正在访问中。 - 然后遍历
x的邻居y。如果colors[y]=1,则找到环,返回true。如果colors[y]=0(没有访问过)且dfs(y)返回了true,那么dfs(x)也返回true。 - 如果没有找到环,那么先标记
colors[x]=2,表示x已经完全访问完毕,然后返回false。
- 首先标记
- 如果
dfs(i)返回true,那么找到了环,返回false。 - 如果遍历完所有节点也没有找到环,返回
true。
- 建图:把每个
python
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
g = [[] for _ in range(numCourses)]
for a, b in prerequisites:
g[b].append(a)
colors = [0] * numCourses
# 返回 True 表示找到了环
def dfs(x: int) -> bool:
colors[x] = 1 # x 正在访问中
for y in g[x]:
if colors[y] == 1 or colors[y] == 0 and dfs(y):
return True # 找到了环
colors[x] = 2 # x 完全访问完毕
return False # 没有找到环
for i, c in enumerate(colors):
if c == 0 and dfs(i):
return False # 有环
return True # 没有环- 时间复杂度 O(n+m),其中 n 是 numCourses,m 是 prerequisites 的长度。每个节点至多递归访问一次,每条边至多遍历一次。
- 空间复杂度 O(n+m)。存储 g 需要 O(n+m) 的空间。
208. 实现 Trie (前缀树)
力扣题目链接
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
输入
"Trie", "insert", "search", "search", "startsWith", "insert", "search"
\[\], \["apple"\], \["apple"\], \["app"\], \["app"\], \["app"\], \["app"\]
输出
null, null, true, false, true, null, true
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
- 1 <= word.length, prefix.length <= 2000
- word 和 prefix 仅由小写英文字母组成
- insert、search 和 startsWith 调用次数 总计 不超过 3 * 104 次
从二叉树到26叉树
以下题解参见:灵茶山艾府
- 【思路】待补充
python
class Node:
__slots__ = 'son', 'end'
def __init__(self):
self.son = {}
self.end = False
class Trie:
def __init__(self):
self.root = Node()
def insert(self, word: str) -> None:
cur = self.root
for c in word:
if c not in cur.son: # 无路可走?
cur.son[c] = Node() # 那就造路!
cur = cur.son[c]
cur.end = True
def find(self, word: str) -> int:
cur = self.root
for c in word:
if c not in cur.son: # 道不同,不相为谋
return 0
cur = cur.son[c]
# 走过同样的路(2=完全匹配,1=前缀匹配)
return 2 if cur.end else 1
def search(self, word: str) -> bool:
return self.find(word) == 2
def startsWith(self, prefix: str) -> bool:
return self.find(prefix) != 0- 时间复杂度:初始化为 O(1) ,insert 为 O(n∣Σ∣) ,其余为 O(n) ,其中
n是word的长度,∣Σ∣=26是字符集合的大小。注意创建一个节点需要 O(∣Σ∣) 的时间(如果用的是数组)。 - 空间复杂度:O(qn∣Σ∣) 。其中
q是insert的调用次数。