使用scikit-learn库对乌克兰冲突事件数据集进行多维度分类分析
背景
在现代冲突研究中,对冲突事件进行多维度分析和可视化可以帮助我们更好地理解冲突的模式、趋势和影响因素。本次作业将使用开源冲突数据,构建一个完整的机器学习分类流程,从数据预处理到模型构建,再到结果可视化,全面展示如何使用scikit-learn库处理多维度分类问题。
数据说明
本次使用的是2022-2025年乌克兰冲突事件数据集,该数据集包含了从2022年俄乌战争开始到2025年初乌克兰境内的详细地理定位冲突事件。数据集包含以下重要字段:
- event_id_cnty:事件标识符
- event_date:事件日期
- year:事件发生年份
- time_precision:时间精度
- disorder_type:冲突类型
- event_type:事件类型(如战斗、爆炸/远程攻击等)
- sub_event_type:子事件类型
- actor1:主要参与方
- assoc_actor_1:关联参与方1
- inter1:参与方1类型代码
- actor2:次要参与方
- assoc_actor_2:关联参与方2
- inter2:参与方2类型代码
- interaction:参与方交互类型代码
- civilian_targeting:是否针对平民
- admin1/2/3:行政区域划分(省/州、区、市/镇)
- location:地点名称
- latitude/longitude:地理位置坐标
- fatalities:死亡人数
- timestamp:数据记录时间戳
需求
本次要求使用scikit-learn库对乌克兰冲突事件数据集进行多维度分类分析,具体包括:
- 数据预处理:清洗数据、处理缺失值、特征编码
- 特征工程:选择和构建有意义的特征集
- 模型构建:使用随机森林算法构建分类模型,预测事件类型
- 模型评估:计算模型准确率、精确率、召回率等指标
- 结果可视化:使用PCA降维和t-SNE可视化分类结果
代码说明
实现一个完整的多维度分类分析流程,主要包含以下几个部分:
-
数据加载与预处理:读取CSV文件,处理缺失值,提取时间特征(月份、季度)
-
特征工程:
- 选择与事件类型预测相关的特征
- 对分类特征进行标签编码
- 对数值特征进行标准化处理
-
模型构建与训练:
- 使用随机森林算法构建分类模型
- 训练模型预测事件类型
-
模型评估:
- 计算模型准确率、精确率、召回率和F1分数
- 生成并可视化混淆矩阵
-
特征重要性分析:
- 计算并展示各特征对分类结果的重要性
- 可视化特征重要性排序
-
结果可视化:
- 使用PCA降维展示数据的实际分类情况
- 使用t-SNE降维展示模型的预测分类结果
通过这个完整的流程,你可以了解如何使用scikit-learn进行多维度分类分析,并通过可视化直观地理解分类结果和特征重要性。
使用说明
- 请将代码中的
file_path变量替换为你实际的CSV文件路径 - 运行代码后,会在当前目录生成三个可视化图片文件
- 代码中的特征选择和模型参数可以根据实际需求进行调整
- 如需增加更多特征或改进模型性能,可以扩展
feature_engineering和train_model函数
安装依赖
bash
pip install --upgrade numpy pandas matplotlib seaborn scikit-learn loky导包
python
# 先设置环境变量,避免CPU核心数警告
import os
# 设置使用的CPU核心数(根据实际情况调整,建议为逻辑核心数的一半)
os.environ["LOKY_MAX_CPU_COUNT"] = "4"
# 导入必要的库
import pandas as pd # 用于数据处理和分析
import numpy as np # 用于数值计算
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.preprocessing import LabelEncoder, StandardScaler # 用于特征编码和标准化
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # 模型评估指标
from sklearn.decomposition import PCA # 主成分分析,用于降维
from sklearn.manifold import TSNE # t-SNE算法,用于高维数据可视化
import matplotlib.pyplot as plt # 绘图库
import seaborn as sns # 高级数据可视化库
# 配置matplotlib支持中文字体和LaTeX数学符号
plt.rcParams.update({
# 优先使用中文字体,同时保留serif用于LaTeX数学符号
"font.family": ["SimHei", "serif"],
"mathtext.fontset": "cm", # 使用Computer Modern字体渲染数学符号
"axes.unicode_minus": False, # 解决负号显示问题
"text.usetex": False, # 不强制使用外部LaTeX,依赖matplotlib内置渲染
})步骤1: 加载数据
python
# 步骤1: 加载数据
def load_data(file_path):
"""加载冲突事件数据"""
try:
data = pd.read_csv(file_path)
print(f"数据加载成功,共{len(data)}条记录,{len(data.columns)}个字段")
return data
except FileNotFoundError:
print(f"错误:文件 {file_path} 不存在")
return None
python
# 文件路径 - 需要替换为实际数据文件路径
file_path = 'data/06/russia_ukraine_conflict.csv'
# 步骤1: 加载数据
data = load_data(file_path)数据加载成功,共154251条记录,31个字段步骤2: 数据预处理
python
# 步骤2: 数据预处理
def preprocess_data(data):
"""预处理冲突事件数据"""
# 复制数据,避免修改原始数据
df = data.copy()
# 处理缺失值
print("处理缺失值...")
# 对于分类变量,用最频繁的值填充
for col in df.select_dtypes(include=['object']).columns:
# 避免链式赋值和inplace=True
df[col] = df[col].fillna(df[col].mode()[0])
# 对于数值变量,用中位数填充
for col in df.select_dtypes(include=['int64', 'float64']).columns:
if df[col].isnull().sum() > 0:
# 避免链式赋值和inplace=True
df[col] = df[col].fillna(df[col].median())
# 将event_date转换为日期格式
df['event_date'] = pd.to_datetime(df['event_date'])
# 从日期中提取月份和季度作为新特征
df['month'] = df['event_date'].dt.month
df['quarter'] = df['event_date'].dt.quarter
return df
python
# 步骤2: 数据预处理
preprocessed_data = preprocess_data(data)处理缺失值...步骤3: 特征工程
python
# 步骤3: 特征工程
def feature_engineering(df):
"""特征工程处理"""
# 选择用于分析的特征
selected_features = [
'disorder_type', 'time_precision', 'interaction', 'civilian_targeting',
'admin1', 'latitude', 'longitude', 'fatalities', 'month', 'quarter'
]
# 目标变量:事件类型
target_variable = 'event_type'
# 提取特征和目标变量
X = df[selected_features].copy()
y = df[target_variable].copy()
# 对分类特征进行编码
categorical_features = X.select_dtypes(include=['object']).columns
for feature in categorical_features:
le = LabelEncoder()
X[feature] = le.fit_transform(X[feature])
# 对目标变量进行编码
le_target = LabelEncoder()
y_encoded = le_target.fit_transform(y)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
return X_scaled, y_encoded, X.columns, le_target
python
# 步骤3: 特征工程
X, y, feature_names, target_encoder = feature_engineering(preprocessed_data)步骤4: 划分训练集和测试集
python
# 步骤4: 划分训练集和测试集
def split_data(X, y):
"""划分训练集和测试集"""
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集大小: {len(X_train)}, 测试集大小: {len(X_test)}")
return X_train, X_test, y_train, y_test
python
# 步骤4: 划分训练集和测试集
X_train, X_test, y_train, y_test = split_data(X, y)训练集大小: 123400, 测试集大小: 30851步骤5: 模型训练
python
# 步骤5: 模型训练
def train_model(X_train, y_train):
"""训练随机森林分类模型"""
# 创建随机森林分类器
model = RandomForestClassifier(
n_estimators=100, # 树的数量
max_depth=10, # 树的最大深度
random_state=42, # 随机种子,保证结果可重现
n_jobs=-1 # 使用所有CPU核心
)
# 训练模型
model.fit(X_train, y_train)
return model
python
# 步骤5: 模型训练
model = train_model(X_train, y_train)步骤6: 模型评估
python
# 步骤6: 模型评估
def evaluate_model(model, X_test, y_test, target_encoder):
"""评估模型性能"""
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
# 打印分类报告
target_names = target_encoder.classes_
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=target_names))
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=target_names, yticklabels=target_names)
plt.xlabel('预测类别')
plt.ylabel('实际类别')
plt.title('混淆矩阵')
plt.tight_layout()
plt.savefig('confusion_matrix.png')
plt.show()
plt.close()
return accuracy
python
# 步骤6: 模型评估
accuracy = evaluate_model(model, X_test, y_test, target_encoder)
print("混淆矩阵图已保存为'confusion_matrix.png'")模型准确率: 0.9114
分类报告:
precision recall f1-score support
Battles 0.77 0.92 0.84 7830
Explosions/Remote violence 0.97 0.91 0.94 23021
accuracy 0.91 30851
macro avg 0.87 0.91 0.89 30851
weighted avg 0.92 0.91 0.91 30851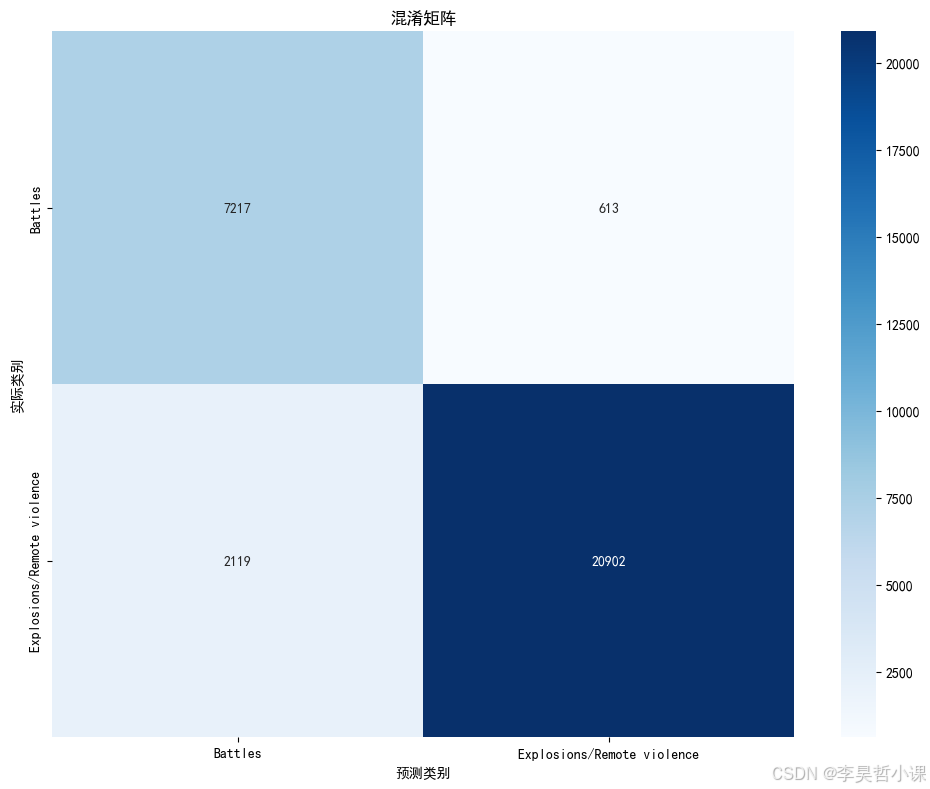
混淆矩阵图已保存为'confusion_matrix.png'
步骤7: 特征重要性分析
python
# 步骤7: 特征重要性分析
def feature_importance_analysis(model, feature_names):
"""分析特征重要性"""
# 获取特征重要性
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
# 打印特征重要性排名
print("\n特征重要性排名:")
for f in range(len(feature_names)):
print(f"{f + 1}. {feature_names[indices[f]]} ({importances[indices[f]]:.4f})")
# 绘制特征重要性图
plt.figure(figsize=(12, 6))
plt.title('特征重要性')
plt.bar(range(len(feature_names)), importances[indices], align='center')
plt.xticks(range(len(feature_names)), [feature_names[i] for i in indices], rotation=90)
plt.xlim([-1, len(feature_names)])
plt.tight_layout()
plt.savefig('feature_importance.png')
plt.show()
plt.close()
python
# 步骤7: 特征重要性分析
feature_importance_analysis(model, feature_names)
print("特征重要性图已保存为'feature_importance.png'")特征重要性排名:
1. interaction (0.6118)
2. longitude (0.1800)
3. latitude (0.0971)
4. fatalities (0.0726)
5. admin1 (0.0236)
6. month (0.0084)
7. quarter (0.0040)
8. time_precision (0.0024)
9. civilian_targeting (0.0000)
10. disorder_type (0.0000)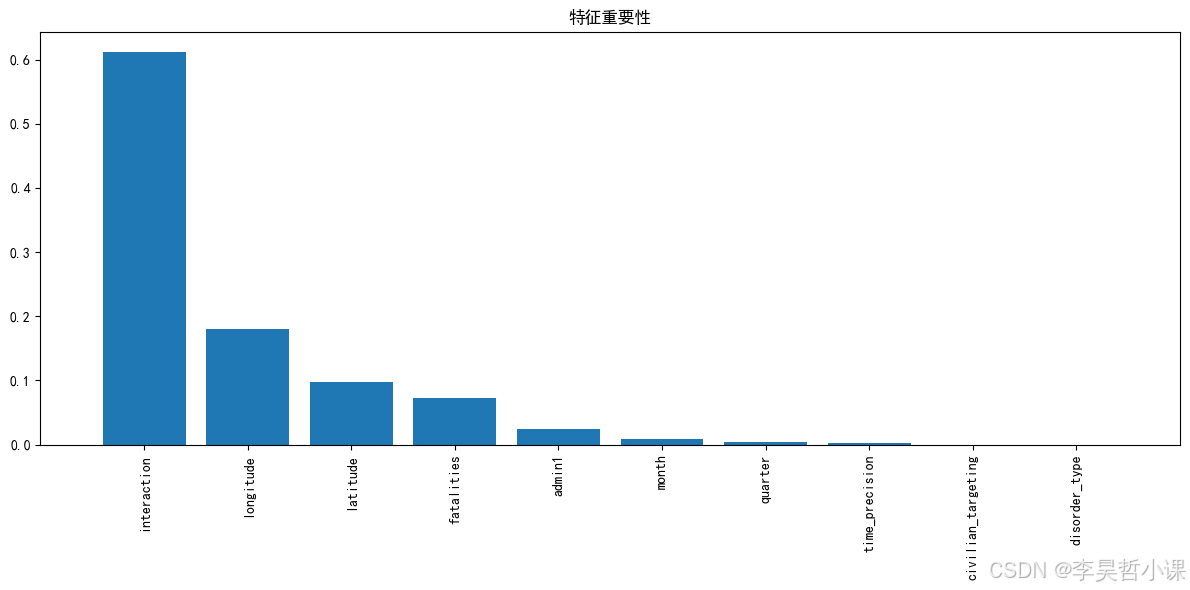
特征重要性图已保存为'feature_importance.png'
步骤8: 可视化分类结果
python
# 步骤8: 可视化分类结果
def visualize_results(X_test, y_test, y_pred, target_encoder):
"""可视化分类结果"""
# 使用PCA降维到2D
pca = PCA(n_components=2)
X_test_pca = pca.fit_transform(X_test)
# 使用t-SNE降维(计算量较大)
tsne = TSNE(n_components=2, random_state=42)
X_test_tsne = tsne.fit_transform(X_test)
# 获取类别名称
target_names = target_encoder.classes_
# 创建画布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 绘制PCA可视化结果
scatter1 = ax1.scatter(X_test_pca[:, 0], X_test_pca[:, 1], c=y_test,
cmap='viridis', s=50, alpha=0.7)
legend1 = ax1.legend(*scatter1.legend_elements(), title="实际类别",
bbox_to_anchor=(1.05, 1), loc='upper left')
ax1.add_artist(legend1)
ax1.set_title('PCA降维后的实际分类结果')
ax1.set_xlabel('主成分1')
ax1.set_ylabel('主成分2')
# 绘制t-SNE可视化结果
scatter2 = ax2.scatter(X_test_tsne[:, 0], X_test_tsne[:, 1], c=y_pred,
cmap='plasma', s=50, alpha=0.7)
legend2 = ax2.legend(*scatter2.legend_elements(), title="预测类别",
bbox_to_anchor=(1.05, 1), loc='upper left')
ax2.add_artist(legend2)
ax2.set_title('t-SNE降维后的预测分类结果')
ax2.set_xlabel('t-SNE维度1')
ax2.set_ylabel('t-SNE维度2')
plt.tight_layout()
plt.savefig('classification_visualization.png')
plt.show()
plt.close()
python
# 步骤8: 可视化分类结果
visualize_results(X_test, y_test, model.predict(X_test), target_encoder)
print("分析完成!分类结果可视化已保存为'classification_visualization.png'")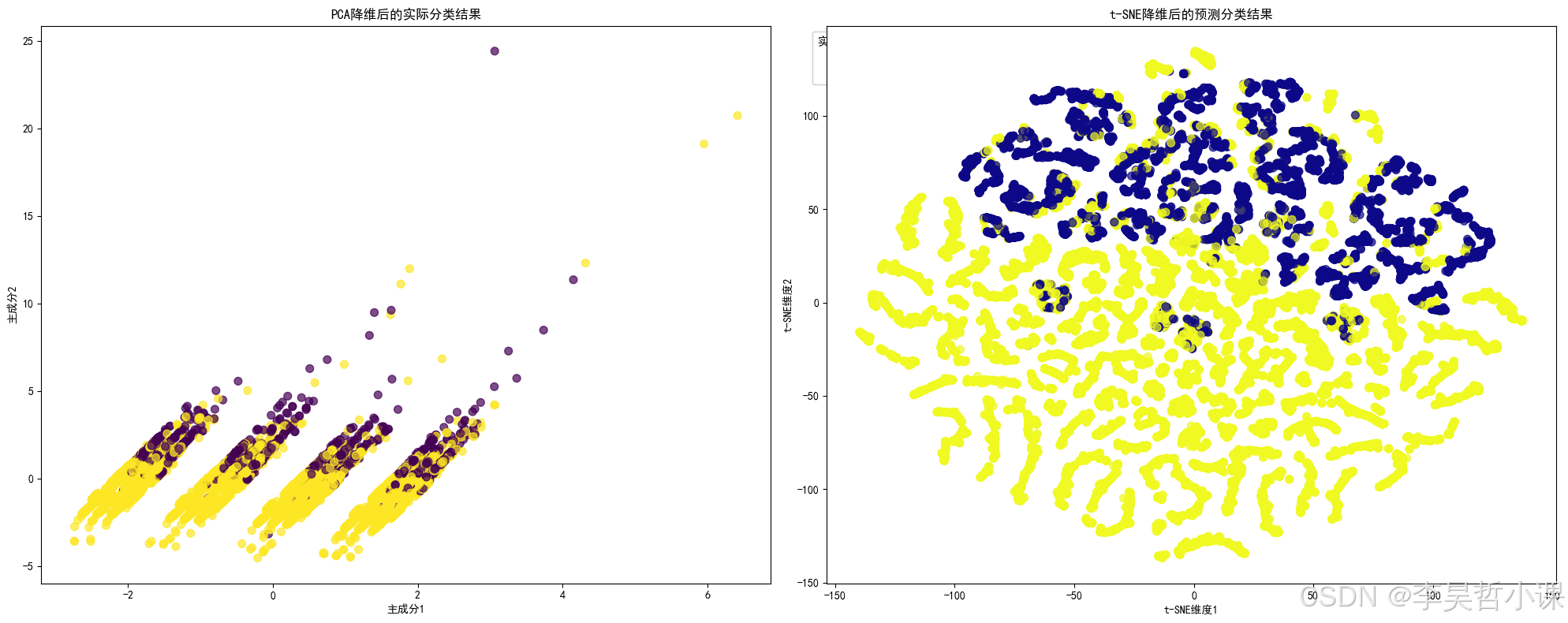
分析完成!分类结果可视化已保存为'classification_visualization.png'
完整代码
python
# 先设置环境变量,避免CPU核心数警告
import os
# 设置使用的CPU核心数(根据实际情况调整,建议为逻辑核心数的一半)
os.environ["LOKY_MAX_CPU_COUNT"] = "4"
# 导入必要的库
import pandas as pd # 用于数据处理和分析
import numpy as np # 用于数值计算
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.preprocessing import LabelEncoder, StandardScaler # 用于特征编码和标准化
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # 模型评估指标
from sklearn.decomposition import PCA # 主成分分析,用于降维
from sklearn.manifold import TSNE # t-SNE算法,用于高维数据可视化
import matplotlib.pyplot as plt # 绘图库
import seaborn as sns # 高级数据可视化库
# 配置matplotlib支持中文字体和LaTeX数学符号
plt.rcParams.update({
# 优先使用中文字体,同时保留serif用于LaTeX数学符号
"font.family": ["SimHei", "serif"],
"mathtext.fontset": "cm", # 使用Computer Modern字体渲染数学符号
"axes.unicode_minus": False, # 解决负号显示问题
"text.usetex": False, # 不强制使用外部LaTeX,依赖matplotlib内置渲染
})
# 步骤1: 加载数据
def load_data(file_path):
"""加载冲突事件数据"""
try:
data = pd.read_csv(file_path)
print(f"数据加载成功,共{len(data)}条记录,{len(data.columns)}个字段")
return data
except FileNotFoundError:
print(f"错误:文件 {file_path} 不存在")
return None
# 步骤2: 数据预处理
def preprocess_data(data):
"""预处理冲突事件数据"""
# 复制数据,避免修改原始数据
df = data.copy()
# 处理缺失值
print("处理缺失值...")
# 对于分类变量,用最频繁的值填充
for col in df.select_dtypes(include=['object']).columns:
# 避免链式赋值和inplace=True
df[col] = df[col].fillna(df[col].mode()[0])
# 对于数值变量,用中位数填充
for col in df.select_dtypes(include=['int64', 'float64']).columns:
if df[col].isnull().sum() > 0:
# 避免链式赋值和inplace=True
df[col] = df[col].fillna(df[col].median())
# 将event_date转换为日期格式
df['event_date'] = pd.to_datetime(df['event_date'])
# 从日期中提取月份和季度作为新特征
df['month'] = df['event_date'].dt.month
df['quarter'] = df['event_date'].dt.quarter
return df
# 步骤3: 特征工程
def feature_engineering(df):
"""特征工程处理"""
# 选择用于分析的特征
selected_features = [
'disorder_type', 'time_precision', 'interaction', 'civilian_targeting',
'admin1', 'latitude', 'longitude', 'fatalities', 'month', 'quarter'
]
# 目标变量:事件类型
target_variable = 'event_type'
# 提取特征和目标变量
X = df[selected_features].copy()
y = df[target_variable].copy()
# 对分类特征进行编码
categorical_features = X.select_dtypes(include=['object']).columns
for feature in categorical_features:
le = LabelEncoder()
X[feature] = le.fit_transform(X[feature])
# 对目标变量进行编码
le_target = LabelEncoder()
y_encoded = le_target.fit_transform(y)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
return X_scaled, y_encoded, X.columns, le_target
# 步骤4: 划分训练集和测试集
def split_data(X, y):
"""划分训练集和测试集"""
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集大小: {len(X_train)}, 测试集大小: {len(X_test)}")
return X_train, X_test, y_train, y_test
# 步骤5: 模型训练
def train_model(X_train, y_train):
"""训练随机森林分类模型"""
# 创建随机森林分类器
model = RandomForestClassifier(
n_estimators=100, # 树的数量
max_depth=10, # 树的最大深度
random_state=42, # 随机种子,保证结果可重现
n_jobs=-1 # 使用所有CPU核心
)
# 训练模型
model.fit(X_train, y_train)
return model
# 步骤6: 模型评估
def evaluate_model(model, X_test, y_test, target_encoder):
"""评估模型性能"""
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
# 打印分类报告
target_names = target_encoder.classes_
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=target_names))
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=target_names, yticklabels=target_names)
plt.xlabel('预测类别')
plt.ylabel('实际类别')
plt.title('混淆矩阵')
plt.tight_layout()
plt.savefig('confusion_matrix.png')
plt.show()
plt.close()
return accuracy
# 步骤7: 特征重要性分析
def feature_importance_analysis(model, feature_names):
"""分析特征重要性"""
# 获取特征重要性
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
# 打印特征重要性排名
print("\n特征重要性排名:")
for f in range(len(feature_names)):
print(f"{f + 1}. {feature_names[indices[f]]} ({importances[indices[f]]:.4f})")
# 绘制特征重要性图
plt.figure(figsize=(12, 6))
plt.title('特征重要性')
plt.bar(range(len(feature_names)), importances[indices], align='center')
plt.xticks(range(len(feature_names)), [feature_names[i] for i in indices], rotation=90)
plt.xlim([-1, len(feature_names)])
plt.tight_layout()
plt.savefig('feature_importance.png')
plt.show()
plt.close()
# 步骤8: 可视化分类结果
def visualize_results(X_test, y_test, y_pred, target_encoder):
"""可视化分类结果"""
# 使用PCA降维到2D
pca = PCA(n_components=2)
X_test_pca = pca.fit_transform(X_test)
# 使用t-SNE降维(计算量较大)
tsne = TSNE(n_components=2, random_state=42)
X_test_tsne = tsne.fit_transform(X_test)
# 获取类别名称
target_names = target_encoder.classes_
# 创建画布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 绘制PCA可视化结果
scatter1 = ax1.scatter(X_test_pca[:, 0], X_test_pca[:, 1], c=y_test,
cmap='viridis', s=50, alpha=0.7)
legend1 = ax1.legend(*scatter1.legend_elements(), title="实际类别",
bbox_to_anchor=(1.05, 1), loc='upper left')
ax1.add_artist(legend1)
ax1.set_title('PCA降维后的实际分类结果')
ax1.set_xlabel('主成分1')
ax1.set_ylabel('主成分2')
# 绘制t-SNE可视化结果
scatter2 = ax2.scatter(X_test_tsne[:, 0], X_test_tsne[:, 1], c=y_pred,
cmap='plasma', s=50, alpha=0.7)
legend2 = ax2.legend(*scatter2.legend_elements(), title="预测类别",
bbox_to_anchor=(1.05, 1), loc='upper left')
ax2.add_artist(legend2)
ax2.set_title('t-SNE降维后的预测分类结果')
ax2.set_xlabel('t-SNE维度1')
ax2.set_ylabel('t-SNE维度2')
plt.tight_layout()
plt.savefig('classification_visualization.png')
plt.show()
plt.close()
# 主函数
def main():
# 文件路径 - 需要替换为实际数据文件路径
file_path = 'data/06/russia_ukraine_conflict.csv'
# 步骤1: 加载数据
data = load_data(file_path)
if data is None:
return
# 步骤2: 数据预处理
preprocessed_data = preprocess_data(data)
# 步骤3: 特征工程
X, y, feature_names, target_encoder = feature_engineering(preprocessed_data)
# 步骤4: 划分训练集和测试集
X_train, X_test, y_train, y_test = split_data(X, y)
# 步骤5: 模型训练
model = train_model(X_train, y_train)
# 步骤6: 模型评估
accuracy = evaluate_model(model, X_test, y_test, target_encoder)
# 步骤7: 特征重要性分析
feature_importance_analysis(model, feature_names)
# 步骤8: 可视化分类结果
visualize_results(X_test, y_test, model.predict(X_test), target_encoder)
print("\n分析完成!分类结果可视化已保存为'classification_visualization.png'")
print("特征重要性图已保存为'feature_importance.png'")
print("混淆矩阵图已保存为'confusion_matrix.png'")
if __name__ == "__main__":
main()数据加载成功,共154251条记录,31个字段
处理缺失值...
训练集大小: 123400, 测试集大小: 30851
模型准确率: 0.9114
分类报告:
precision recall f1-score support
Battles 0.77 0.92 0.84 7830
Explosions/Remote violence 0.97 0.91 0.94 23021
accuracy 0.91 30851
macro avg 0.87 0.91 0.89 30851
weighted avg 0.92 0.91 0.91 30851特征重要性排名:
1. interaction (0.6118)
2. longitude (0.1800)
3. latitude (0.0971)
4. fatalities (0.0726)
5. admin1 (0.0236)
6. month (0.0084)
7. quarter (0.0040)
8. time_precision (0.0024)
9. civilian_targeting (0.0000)
10. disorder_type (0.0000)
分析完成!分类结果可视化已保存为'classification_visualization.png'
特征重要性图已保存为'feature_importance.png'
混淆矩阵图已保存为'confusion_matrix.png'