开源工程地址:https://github.com/zhangliwei7758/unity-AI-Chat-Toolkit
- 先致敬zhangliwei7758,开放这个源码
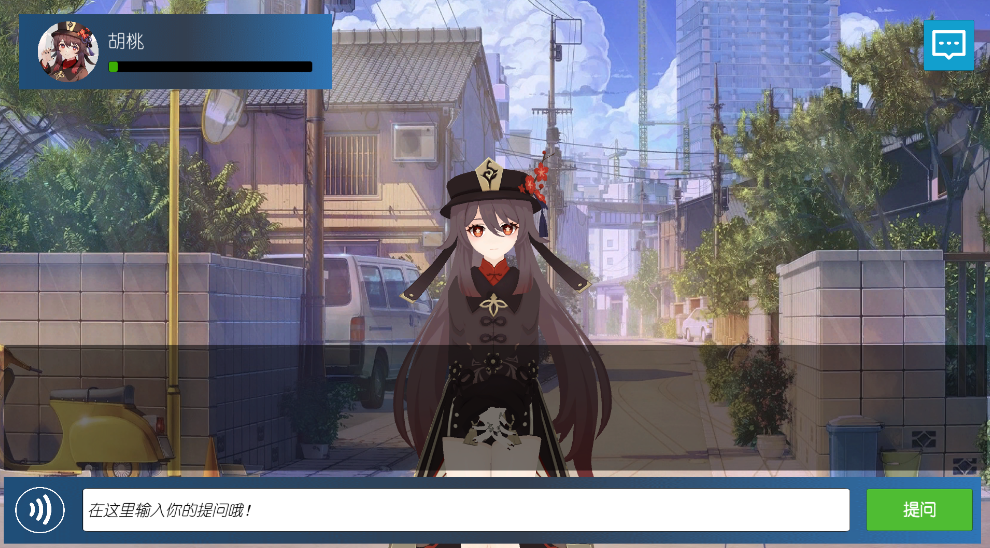
一、建立工程
- 建立Unity工程(UnityAiChat)
- 拖入Unity-AI-Chat-Toolkit.unitypackage
- 打开chatSample工程,可以另存一个,方便改动
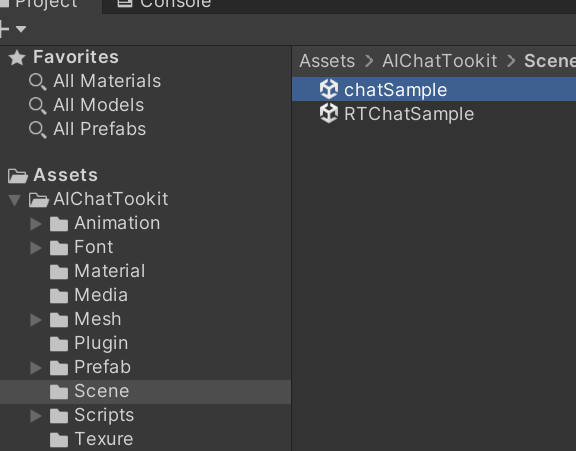
二、工程说明
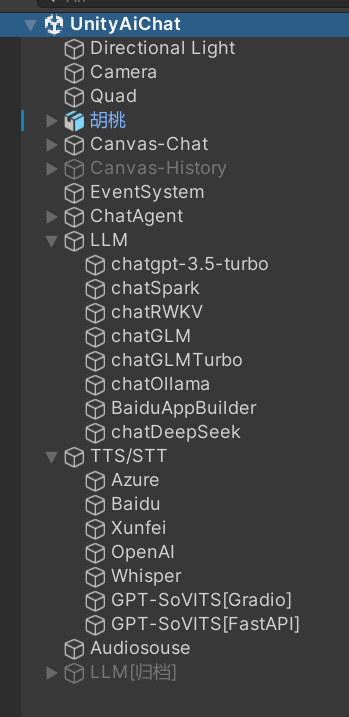
- Quad:背景
- 胡桃:人物模型
- Canvas-Chat:UI
- ChatAgent:数字人代理配置
- LLM:大模型,这里集成了deepseek,讯飞等,
- TTS/STT:文字转语音/语音转文字,集成了讯飞
- Audiosouse:语音模块
三、LLM大模型说明
-
chatgpt:
集成了chatgpt 3.5/4 的api接口,使用这个脚本,需要在脚本参数里填写openai的api key, 默认设置的模型是chatgpt-3.5,如果要替换chatgpt4,需要自行修改模型名称;
-
chatglm:
集成了对chatglm官方示例的api接口,如果使用chatglm官方的仓库部署的api服务,就可以直接使用,需要配置的内容是,配置部署好的api地址即可;
-
rwkv:
集成了针对rwkv runner开源项目的api接口,因为rwkv runner这个项目的api格式和chatgpt是一样的,如果下载rwkv runner这个项目使用的话,可以使用工具提供的脚本,只需要在api地址参数配置实际的地址就可以了。
-
星火大模型 chatSpark:
集成了科大讯飞的星火大模型的api对接功能,可根据需求自行配置V1.5/V2.0版本
-
百度智能云千帆大模型平台:
集成了百度智能云千帆大模型平台模型api服务,包括文心一言等十种模型
-
智谱AI开放平台:
集成了智谱AI开放平台下,chatGLM Turbo模型的api支持
-
Ollama工具:
集成对Ollama部署的本地大模型的API调用支持,可以利用chatOllama模块驱动AI小姐姐聊天
-
DeepSeek:
集成对DeepSeek的API调用支持
另外还有dify知识库大模型平台
四、TTS/STT: 语音合成 / 语音识别
-
微软Azure语音合成以及语音识别服务:
如果使用这个服务,需要准备微软Azure的语音服务令牌,自行注册账号,开通服务获得;
-
百度AI的语音合成以及语音识别服务:
使用这个服务时,注册百度AI开放平台的账号,开通语音合成、语音识别服务,创建应用获取到相关的密钥,填入相应脚本即可。
-
OpenAI平台提供的在线Whisper语音识别服务:
集成了openAI平台的Whisper在线语音识别api,需要使用openai的api key 集成了openAI平台的TTS语音合成api,可实现语音合成功能
-
提供针对开源的Whisper模型的api集成:
集成的项目是github上开源项目:https://github.com/ahmetoner/whisper-asr-webservice 部署这个项目,可使用本模块来调用语音识别的api
-
提供针对科大讯飞语音服务的api集成:
实现了对科大讯飞语音服务的api集成,采用了websocket方式,可使用科大讯飞的语音识别以及语音合成服务
-
GPT-SoVITS
实现高质量的 文本到语音(TTS) 和 语音克隆(Voice Cloning)
GPT-SoVITS Gradio,是基于 Gradio 开发的交互式 Web 界面,方便用户通过浏览器直接使用 GPT-SoVITS 的语音合成功能,无需编写代码。
GPT-SoVITS FastAPI,FastAPI 是一个高性能 Python Web 框架,适合构建 RESTful API,是将模型封装为 API 服务的后端方案,供开发者集成到其他应用或系统中。
五、使用讯飞+deepseek,实现数字人
- deepseek:https://platform.deepseek.com/
一定要充10元哦 - deepseek API:https://api-docs.deepseek.com/zh-cn/
- 接口:https://api.deepseek.com/chat/completions
- Unity里ChatAgent里选择chatDeepSeek
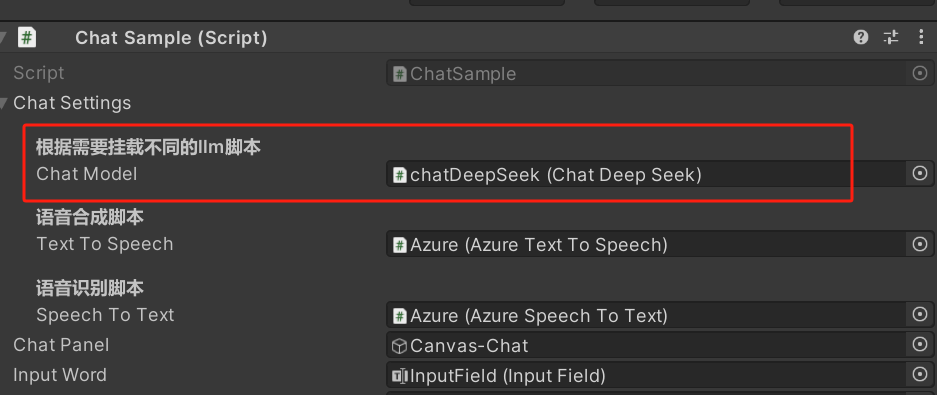
- chatDeepSeek的api_key:
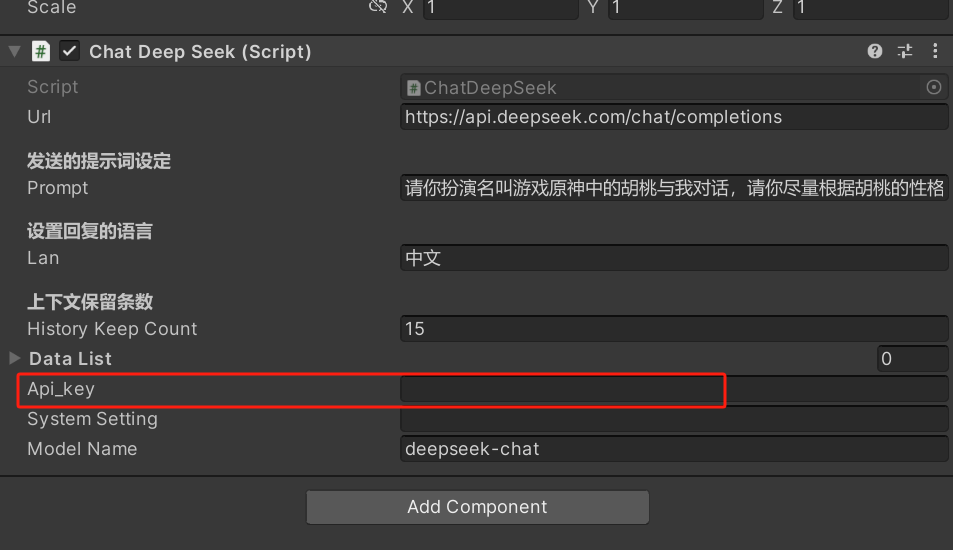
- System Setting:可以设置人设,比如讲解员
- Prompt:AI提示词
- Unity里ChatAgent里选择xunfei作为语音识别
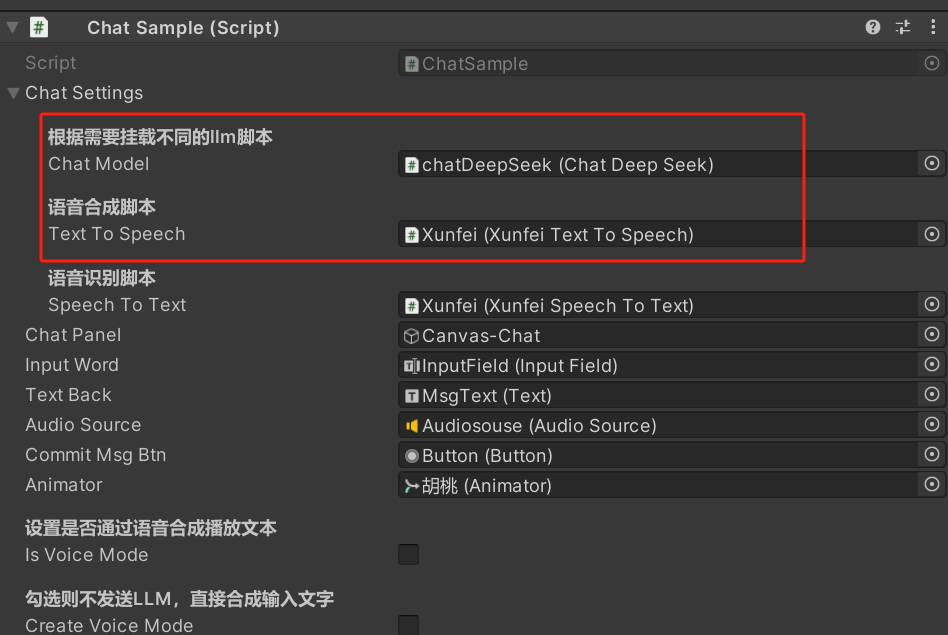
- 填写讯飞的key
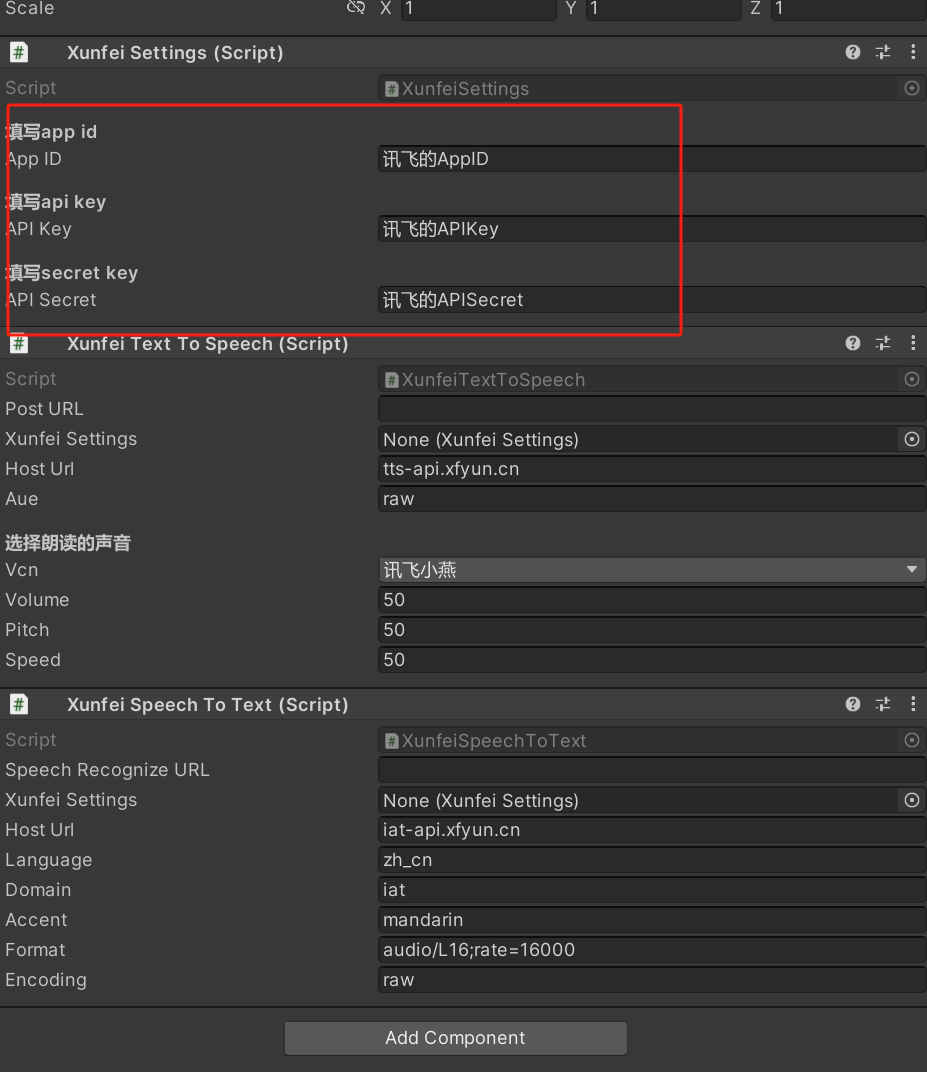
注意,这里只需要填写红框的部分;讯飞的api的顺序是先api_secret,和这里顺序相反,不要填错了
- ChatSample需要勾选Is Vocie Mode
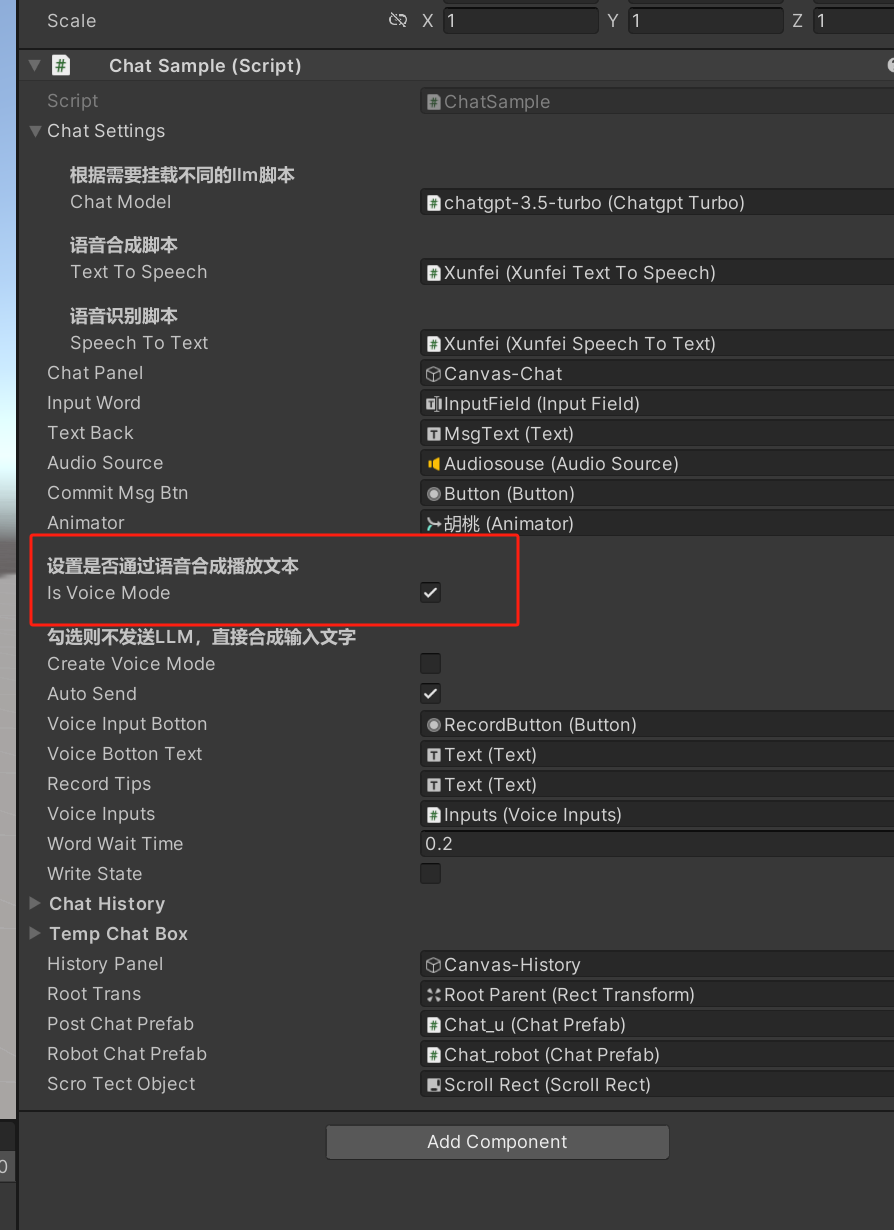
注意:这样选择后,能说话了,但是有长度报错,可能原因是目前deepseek是流式的,但是语音是等文字回复完成后,一次生成的
- 我们改动chatgpt-3.5-turbo,作为deepseek的接口来使用,避免这个问题
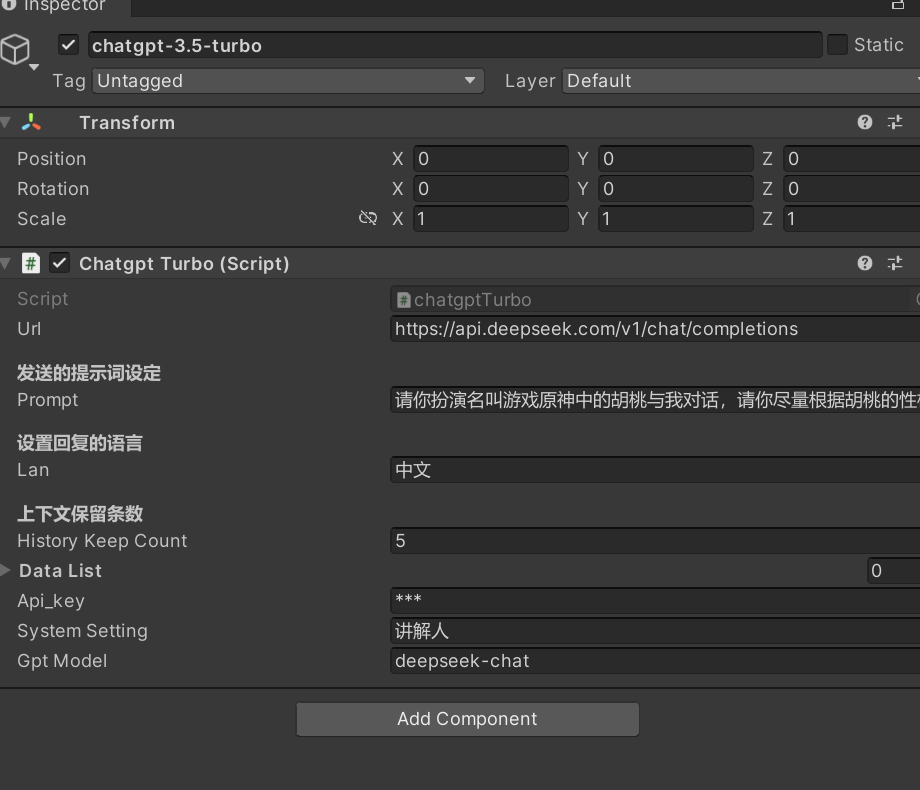
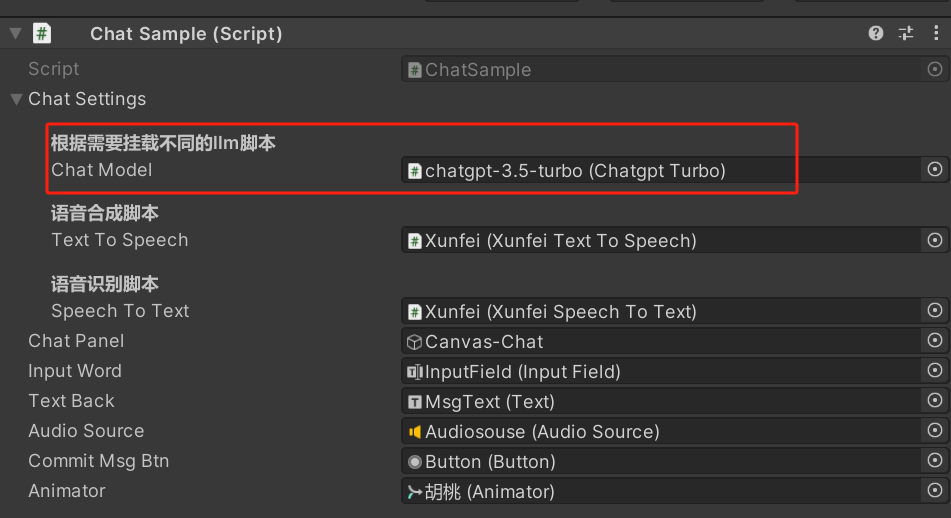
- 设置下ChatSample
最后注意事项:我们麦克风,尽量用那种单独的麦克风,如果用摄像头的,有的时候会认不到