在云原生和微服务架构盛行的今天,监控系统已成为保障业务稳定性的核心基础设施。作为监控领域的标杆工具,Prometheus 和Grafana凭借其高效的数据采集、灵活的可视化能力,成为运维和开发团队的"标配"。
一、Prometheus
Prometheus诞生于2012年,由SoundCloud开发并捐赠给CNCF基金会,现已成为继Kubernetes之后最受欢迎的云原生项目之一。
1. 核心特性
- 多维数据模型 :通过
<metric name>{<label1>=<value1>, ...}的格式记录数据,支持按标签动态分类(如区分不同服务的HTTP请求延迟)。 - PromQL查询语言:提供强大的时间序列数据分析能力,例如计算CPU使用率的滑动平均值:
plain
avg_over_time(node_cpu_seconds_total{mode="idle"}[5m])- Pull/Push混合模式:默认通过HTTP主动拉取目标数据,同时支持通过Pushgateway接收短期任务推送的指标。
- 分布式高可用:支持联邦集群架构,实现跨数据中心的数据聚合。
2. 架构组件
体系结构
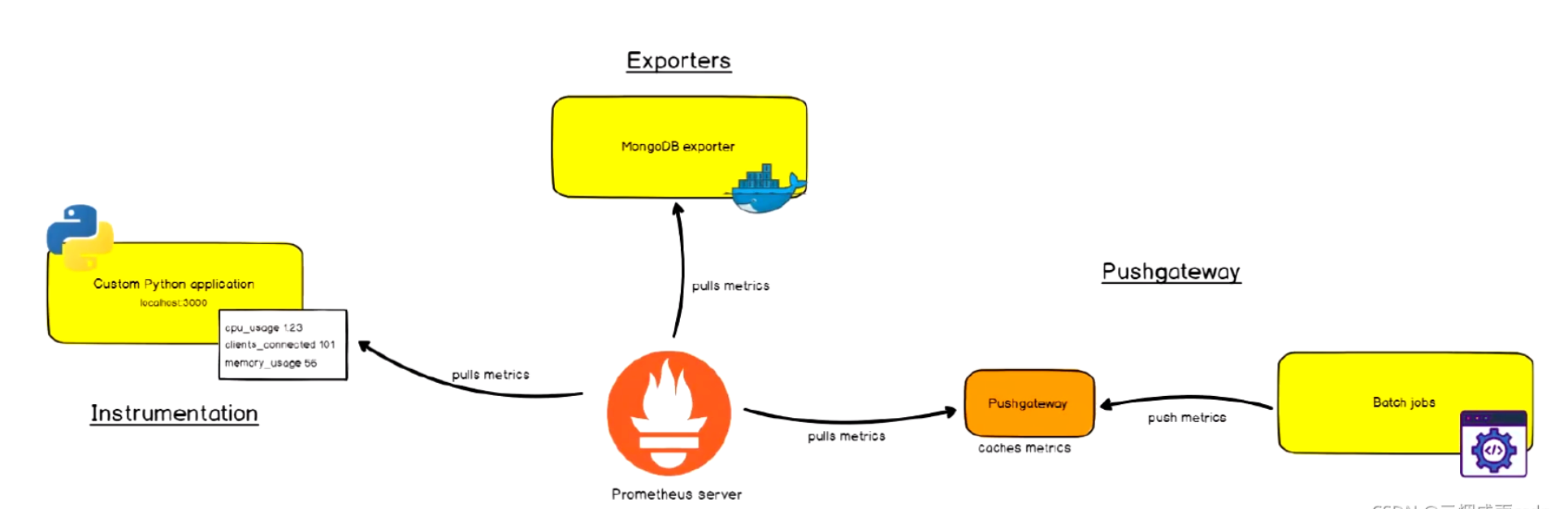
下图说明了Prometheus的体系结构及其某些生态系统组件:
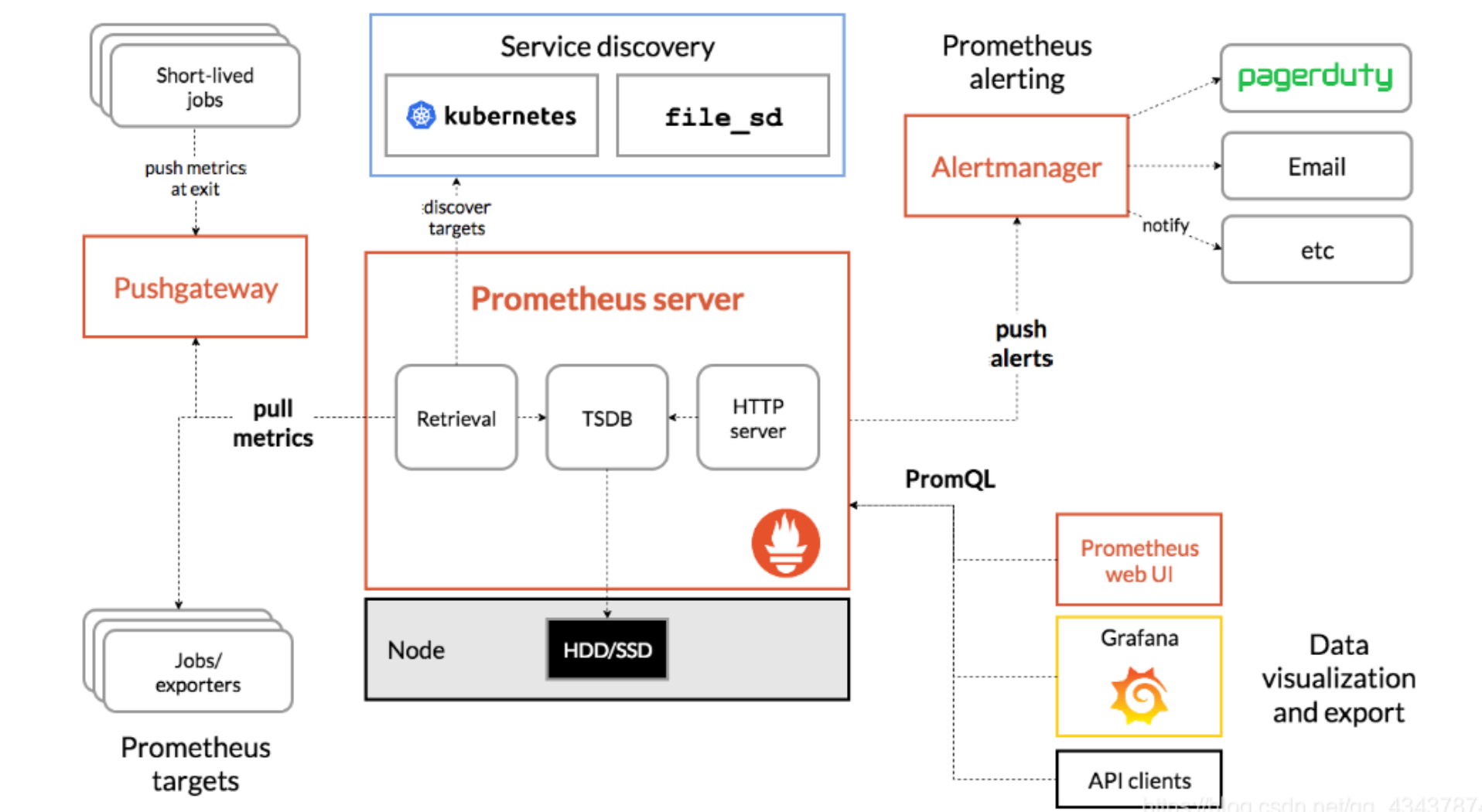
Prometheus体系涉及的组件
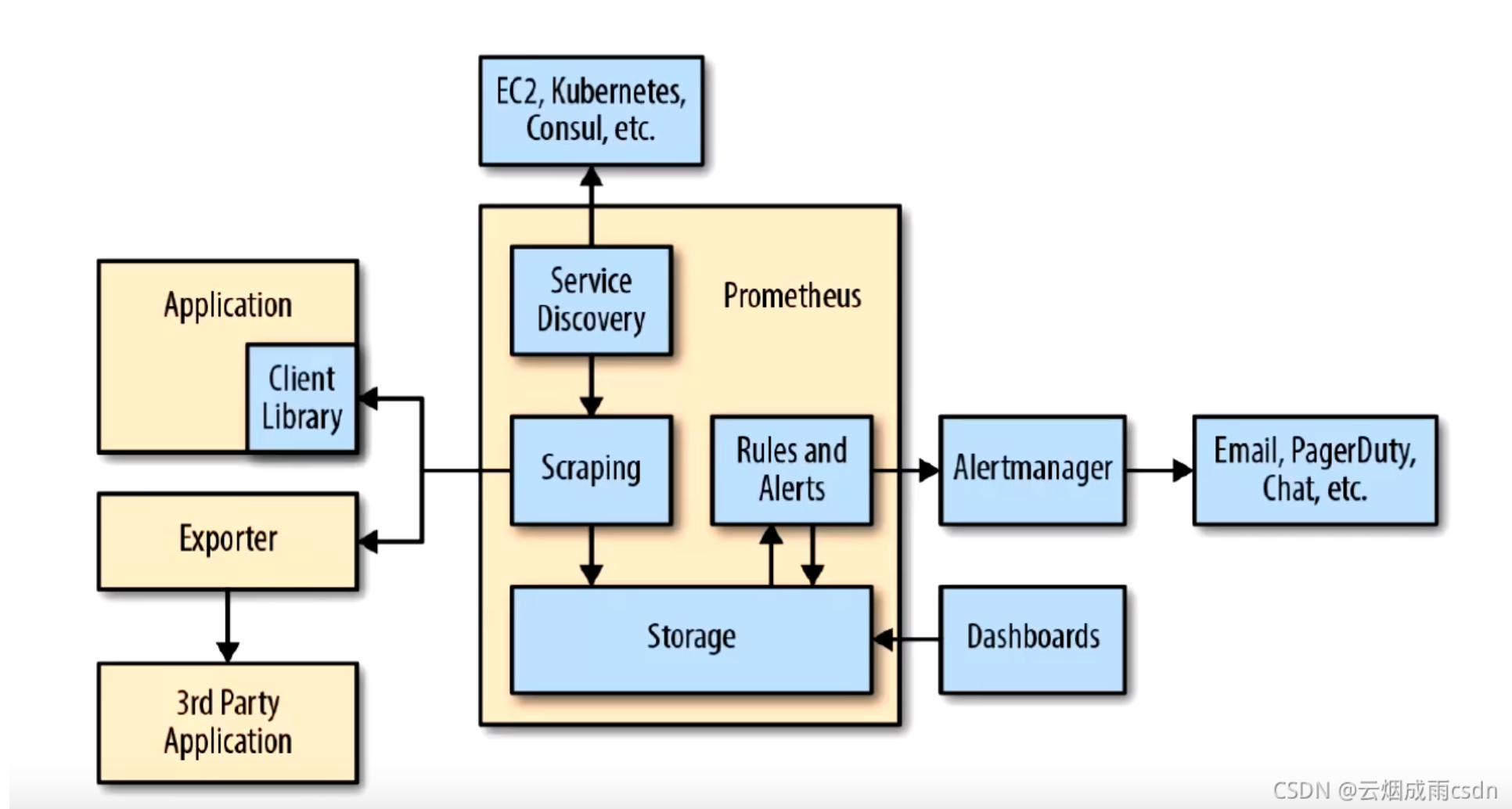
- Prometheus server - 收集和存储时间序列数据
- Client Library: 客户端库,为需要监控的服务生成相应的
- metrics 并暴露给 - Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- pushgateway - 对于短暂运行的任务,负责接收和缓存时间序列数据,同时也是一个数据源
- exporter - 各种专用exporter,面向硬件、存储、数据库、HTTP服务等
- alertmanager - 处理报警
- webUI等,其他各种支持的工具,本身的界面值适合用来语句查询,数据可视化,需要第三方组件,比如Grafana。
3.如何收集度量值
度量指标由监控系统执行的过程通常可以分为两种方法:推和拉。
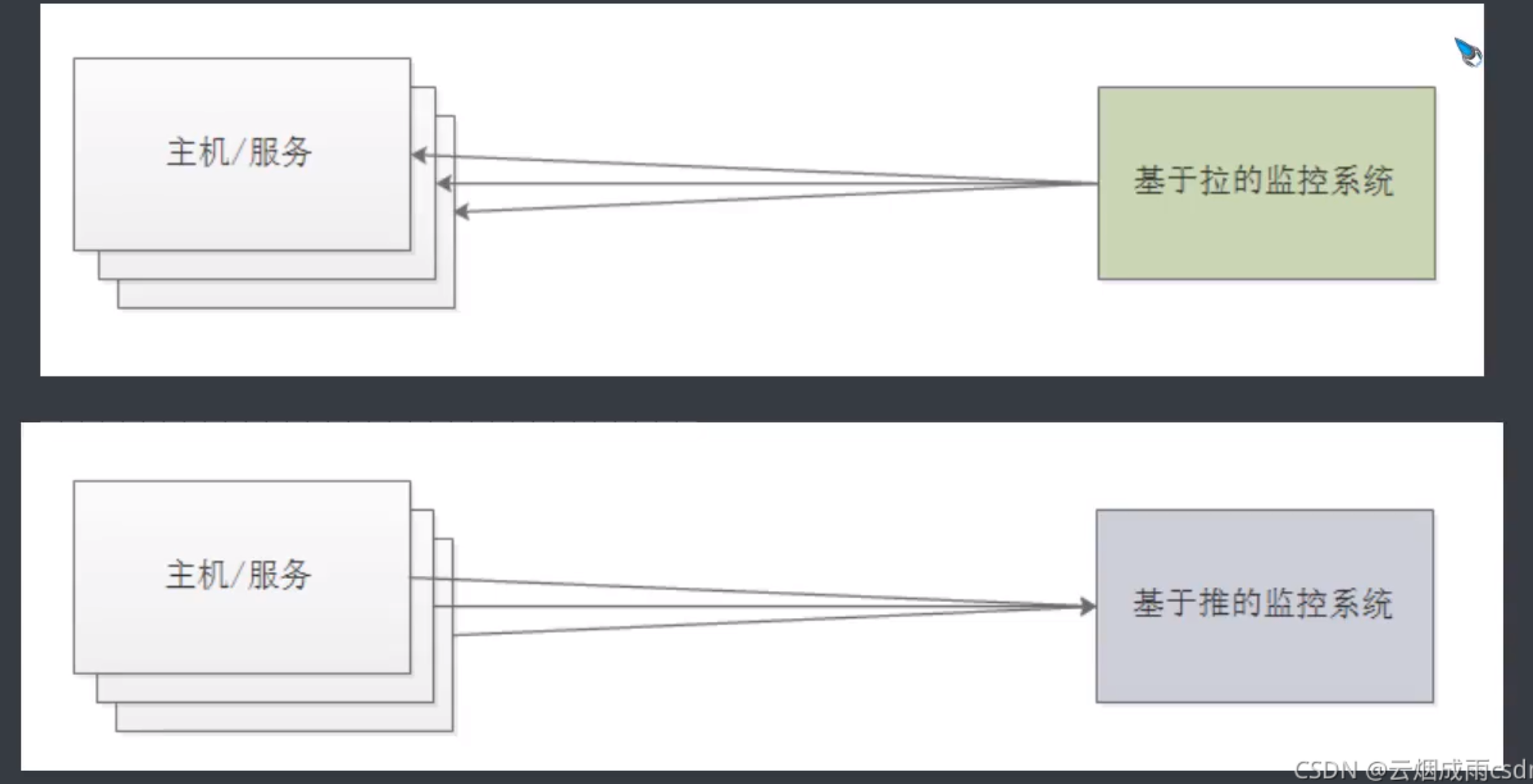
Prometheus基于HTTP call,从配置文件中指定的网络端点(endpoint)上周期性获取指标数据。
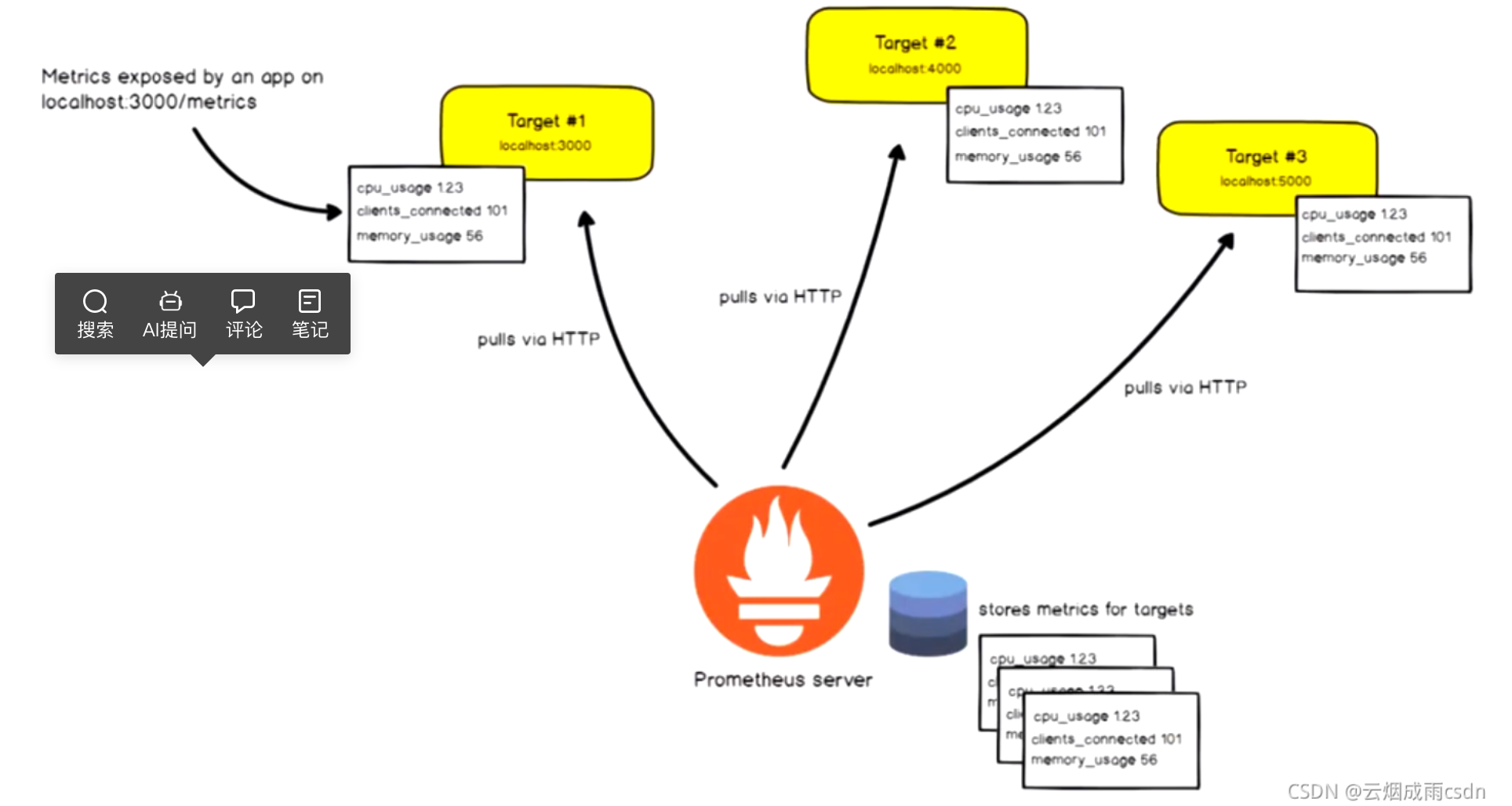
Prometheus支持通过三种类型的途径从目标上"抓取(Serape)"指标数据:
Exporters:被监控的目标不支持pro的数据格式,通过exporters抽取指标数据,进行格式化处理成pro兼容的数据格式,再响应给pro server。
Instrumentation:应用系统内建了pro兼容的指标数据格式,pro server可以直接采集。
Push gateway:pro采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。暂存在pushgateway,等待Prometheus server拉取。
二、Grafana
Grafana作为开源可视化领域的"瑞士军刀",能够将Prometheus的原始数据转化为直观的运维仪表盘。
1. 核心优势
- 多数据源支持:无缝集成Prometheus、Loki、InfluxDB、Elasticsearch等30+数据源。
- 动态仪表盘:提供折线图、热力图、统计面板等10+图表类型,支持通过变量实现交互式过滤(如按环境/服务筛选)。
- 告警可视化:可在图表中直接标注阈值告警点,并结合Alertmanager实现分级通知。
- 模板生态 :官方市场提供1.5万+预置模板,例如:
- 主机监控模板(ID: 8919)
- MySQL性能分析模板(ID: 11329)
- Kubernetes集群监控模板(ID: 315)
2. 高级功能
- 混合数据源:在同一面板中对比不同系统的数据(如同时展示Prometheus的CPU指标和Elasticsearch的日志量)。
- 权限管控:支持基于角色的访问控制(RBAC),细化到仪表盘级别的权限管理。
三、协同工作流
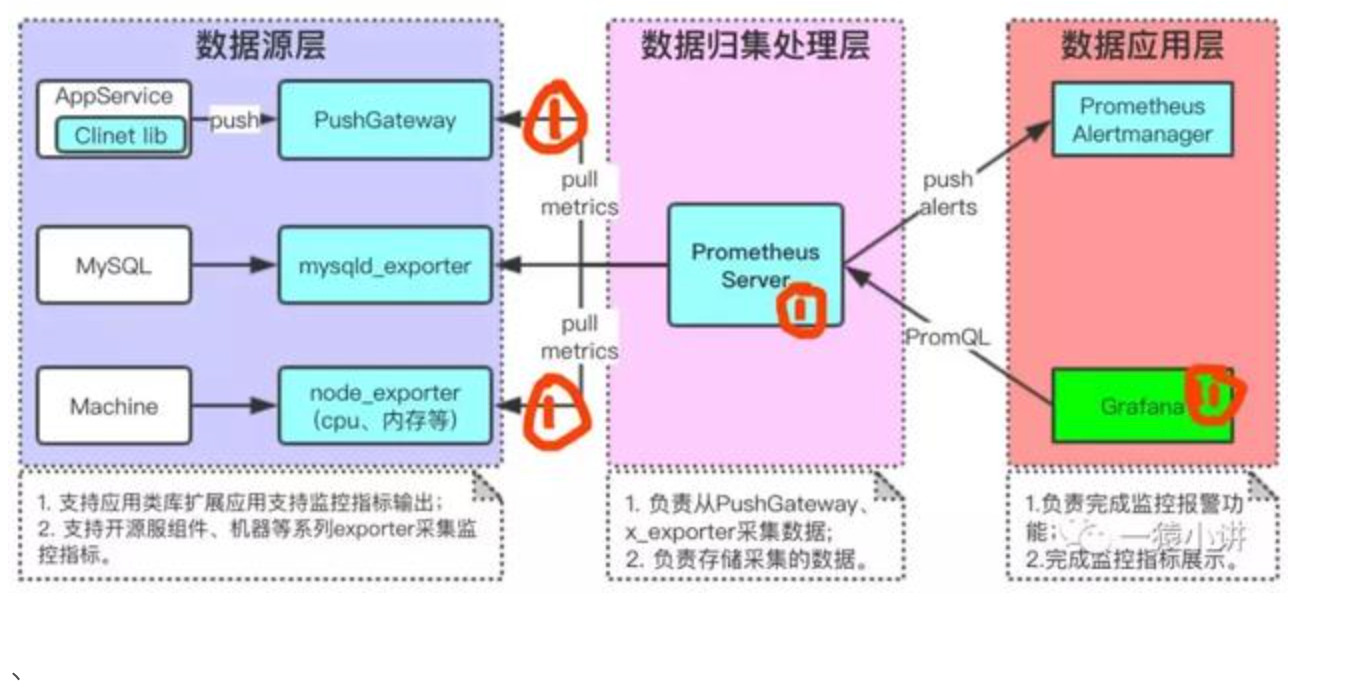
- 数据采集
Node Exporter采集主机CPU/内存指标,cAdvisor收集容器资源使用情况,应用通过Client Library暴露自定义指标(如Spring Boot的HTTP请求数)。 - 存储分析
Prometheus每15秒拉取一次数据,存储至TSDB,并通过PromQL实现实时分析。例如检测内存泄漏:
plain
increase(container_memory_usage_bytes{container="app"}[1h]) > 1GB- 可视化展示
在Grafana中创建仪表盘,组合多个图表形成监控全景(图2)。例如:- 实时显示服务的QPS、错误率、响应时间百分位数
- 通过GeoMap插件展示全球用户的访问延迟分布
- 智能告警
当Prometheus检测到指标异常(如错误率>5%持续5分钟),Alertmanager会触发Grafana通知,并自动生成事件时间线供事后分析。
四、典型应用场景
- 基础设施监控
通过Node Exporter+主机模板(图3),实时跟踪服务器CPU/磁盘/网络状态,预测硬件故障。 - 微服务观测
结合Istio等服务网格,监控服务间调用的黄金指标(吞吐量、错误率、饱和度)。 - CI/CD健康度
分析流水线的构建时长、失败原因,优化Jenkins任务调度策略。 - 业务指标可视化
将订单成交量、用户活跃度等业务指标接入,实现技术与业务数据的联动分析。
五、最佳实践
- 指标设计规范
- 遵循
<service>_<metric>_<unit>命名规则(如http_requests_total) - 避免高基数标签(如用户ID会导致时序爆炸)
- 遵循
- 性能优化
- 设置合理的抓取间隔(生产环境建议30-60秒)
- 使用Recording Rules预计算常用查询
- 可视化策略
- 关键指标采用红/黄/绿状态标识
- 在仪表盘顶部放置全局过滤器(如环境/数据中心)