当前图像编辑数据集规模小,质量差,由此构建了如下数据构造管线。

高质量三元组数据(源图像、编辑指令、目标图像)。
- 主体添加与移除:使用 Florence-2 对专有数据集标注,然后使用 SAM2 进行分割,再使用 ObjectRemovalAlpha 进行修复。编辑指令结合 Step-1o 和 GPT-4o 生成,然后人工审查有效性。
- 主体替换与背景更改:使用 Florence-2 对专有数据集标注,然后使用 SAM2 进行分割,再使用 Qwen-2.5VL 和 Recognize-Anything Model 识别目标对象和关键词,使用 Flux-Fill 进行内容感知修复。指令由 Step-1o 生成并人工审查。
- 色彩更改与材质修改:在图像中检测到对象后,使用 Zeodepth 深度估计,使用带扩散模型的 ControlNet 生成新图像。
- 文本修改:使用 PPOCR 识别字符,以及 Step-1o 模型区分文本正确、错误区域。同样生成编辑指令。
- 运动变化:使用 Koala-36M 的视频,提取帧作为输入,使用 BiRefNet 和 RAFT 进行前景-背景和光流估计,再用 GPT-4o 标记帧间运动变化作为编辑指令。
- 人像编辑与美化:对于动画风格和真实图像,先提取边缘,再利用 ControlNet 进行风格迁移。
- 采用上下文、双语标注。
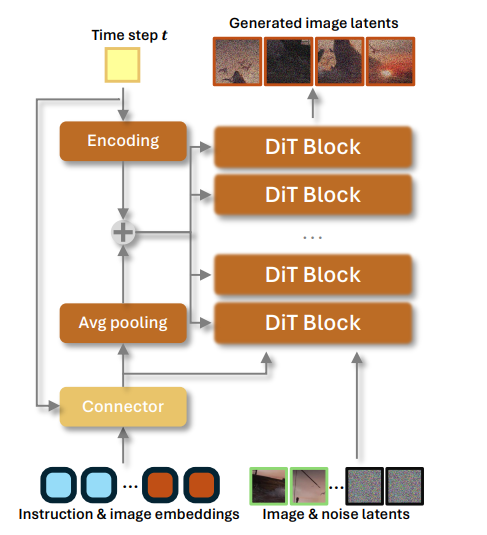
之前的模态融合,FLUX-Fill 使用通道连接,但面对图像编辑指令不够灵活(难以处理局部调整、缺乏语义对齐、难以处理复杂指令);SeedEdit 引入额外的因果自注意力,但会牺牲图像细粒度;DreamEngine 利用 Qwen 对图像和文本模态对齐,建立了共享表征空间,难以完全捕捉图像细粒度(更关注语义对齐)。
Step1X-Edit:
- 输入的编辑指令和参考图像首先通过MLLM进行处理。为了隔离和强调与编辑任务相关的语义元素,选择性地丢弃与系统前缀相关的标记嵌入,仅保留与编辑信息直接对齐的嵌入。
- 提取的嵌入被输入到轻量级的连接器模块,重构为更紧凑的多模态特征表示,然后作为输入传递给下游的DiT网络。采用标记连接(token concatenation)的方式,平衡对编辑指令的响应性与对细粒度图像细节的保留。这种方法比通道连接或额外的自注意力机制更有效。
- 在训练过程中,联合优化连接器模块和下游的DiT,仅使用扩散损失进行训练,确保稳定训练而不依赖掩码损失技巧。(采用 Rectified Flow 方式)
- 并且对 VLLM 输出的有效嵌入计算均值,将其作为 DiT 的引导。
实验
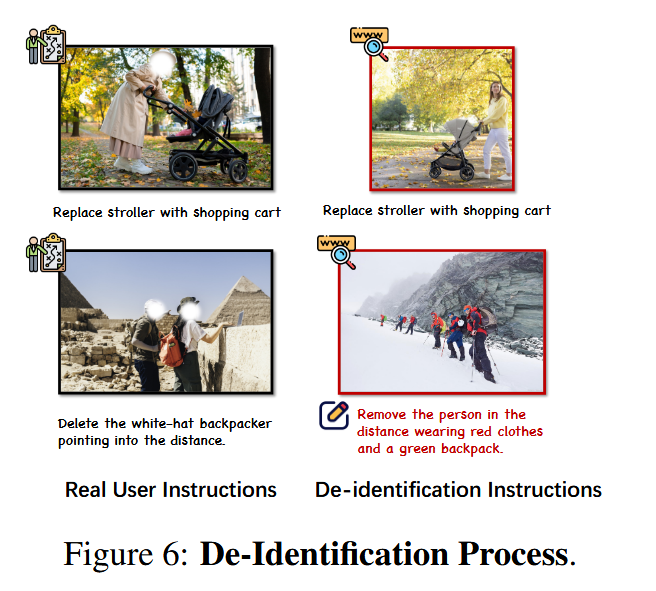
团队从互联网上收集了超过1K的用户编辑实例,构建了GEdit-Bench,包含606个真实用户编辑指令,覆盖11类任务。为确保隐私,所有图像经过去标识化处理。与其他基准(如EditBench和MagicBrush)相比,GEdit-Bench更贴近实际需求。
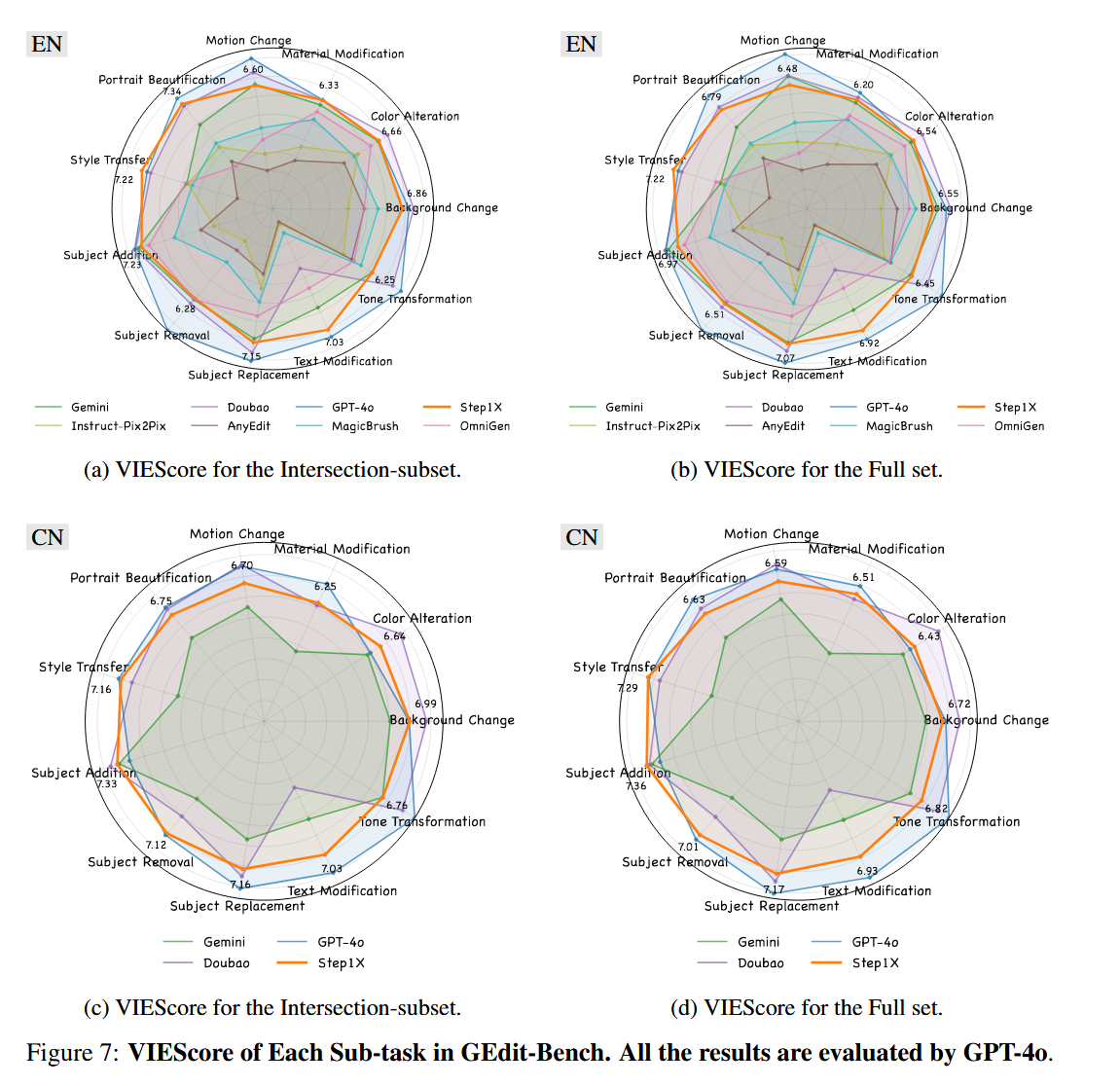
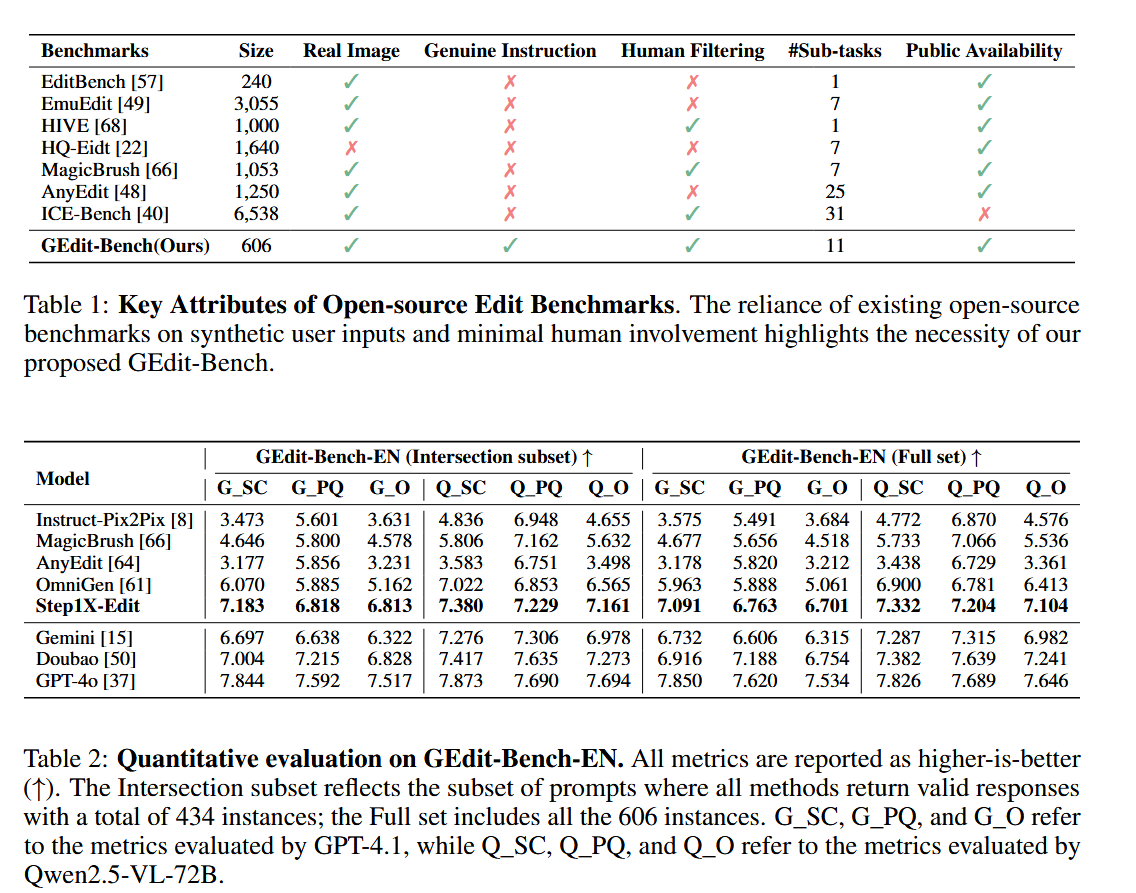
疑问:本文仅在自己构建的测试集上评估,并缺乏消融实验验证架构设计。