AI智能混剪视频大模型开发方案:从文字到视频的自动化生成·优雅草卓伊凡
引言:AI视频创作的未来已来
近年来,随着多模态大模型 (如Stable Diffusion、Sora、GPT-4)的爆发式发展,AI已经能够实现从文字生成图像、视频、音乐等内容。优雅草卓伊凡 近期收到客户需求:开发一套"一键混剪"视频生成系统,用户只需输入一段文字描述,AI即可自动完成以下任务:
- 视频内容生成(基于文本描述生成或匹配素材)
- 标题与字幕合成(自动提炼关键信息并生成动态字幕)
- 背景音乐生成(匹配视频情绪和节奏的音乐)
这一需求看似复杂,但借助现有的开源模型和技术栈,完全可以在可控成本 内实现。本文将详细解析该系统的技术原理、开源模型选型、开发流程 ,并提供一套低预算实现方案。

一、功能需求拆解与技术可行性分析
1. 核心功能模块
|---------------|------------------------------------------|
| 功能模块 | 技术实现要点 |
| 文本理解与脚本生成 | 大模型(如LLaMA-3)解析用户输入,生成视频分镜脚本 |
| 视频素材生成/检索 | 方案A:文生视频模型(如Stable Video) 方案B:从素材库检索匹配片段 |
| 字幕与标题生成 | NLP关键词提取 + 时间轴对齐 + 动态字体渲染 |
| 背景音乐生成 | 音乐生成模型(如Riffusion)或情绪匹配检索 |
| 视频合成与导出 | FFmpeg多轨道合成 + 转场特效 |
2. 技术可行性验证
- 文本生成视频:已有开源模型(Stable Video Diffusion、Pika 1.0)
- 文本生成音乐:Riffusion、MusicGen等开源项目
- 自动化剪辑逻辑:可通过规则引擎+大模型协同实现

二、底层技术原理与开源模型选型
1. 文本到视频生成(核心难点)
方案A:直接生成视频(高成本)
- 模型选型:
-
- Stable Video Diffusion(Stability AI开源)
- Pika 1.0(支持3秒短视频生成)
- 技术流程:
-
- 用户输入:"一只猫在草地上追逐蝴蝶"
- 大模型生成分镜脚本:
{ "scenes": [
{ "duration": 2, "description": "猫咪抬头看向蝴蝶的特写" },
{ "duration": 3, "description": "蝴蝶飞过草地的全景" }
]} -
- 调用视频生成模型逐场景渲染
方案B:素材库检索+合成(低成本推荐)
- 技术流程:
-
- 建立标签化视频素材库(如:"猫"、"草地"、"蝴蝶")
- 使用CLIP模型计算文本与素材的相似度
- 自动拼接匹配片段(FFmpeg concat滤镜)
对比:
|--------|---------|---------------|-----------|
| 方案 | 优点 | 缺点 | 成本 |
| A | 完全原创内容 | 生成效果不稳定,算力需求高 | 高(需A100) |
| B | 速度快,成本低 | 依赖素材库质量 | 低(可CPU运行) |
2. 字幕与标题生成
技术栈:
- 文本摘要:LLaMA-3-8B(本地量化部署)
- 字幕时间轴:
-
- 使用Whisper提取语音时间戳
- NLP算法合并短句(如:"猫咪...追逐" → "猫咪在追逐蝴蝶")
- 动态渲染:
-
- 基础版:FFmpeg drawtext滤镜
- 高级版:AE模板+数据驱动(需Python脚本生成.json)
代码片段(FFmpeg命令):
ffmpeg -i input.mp4 -vf "drawtext=text='Hello':fontsize=24:x=100:y=50" output.mp43. 背景音乐生成
开源方案:
- Riffusion:基于Stable Diffusion的音乐生成
-
- 输入文本:"轻快的夏日钢琴曲"
- 输出:30秒MIDI+WAV音频
- MusicGen(Meta开源):
-
- 支持旋律约束(可匹配视频节奏)
集成方式:
from transformers import pipeline
music_gen = pipeline("text-to-audio", model="facebook/musicgen-small")
audio = music_gen("upbeat electronic music", max_new_tokens=512)
三、系统架构设计与开发流程
1. 整体架构
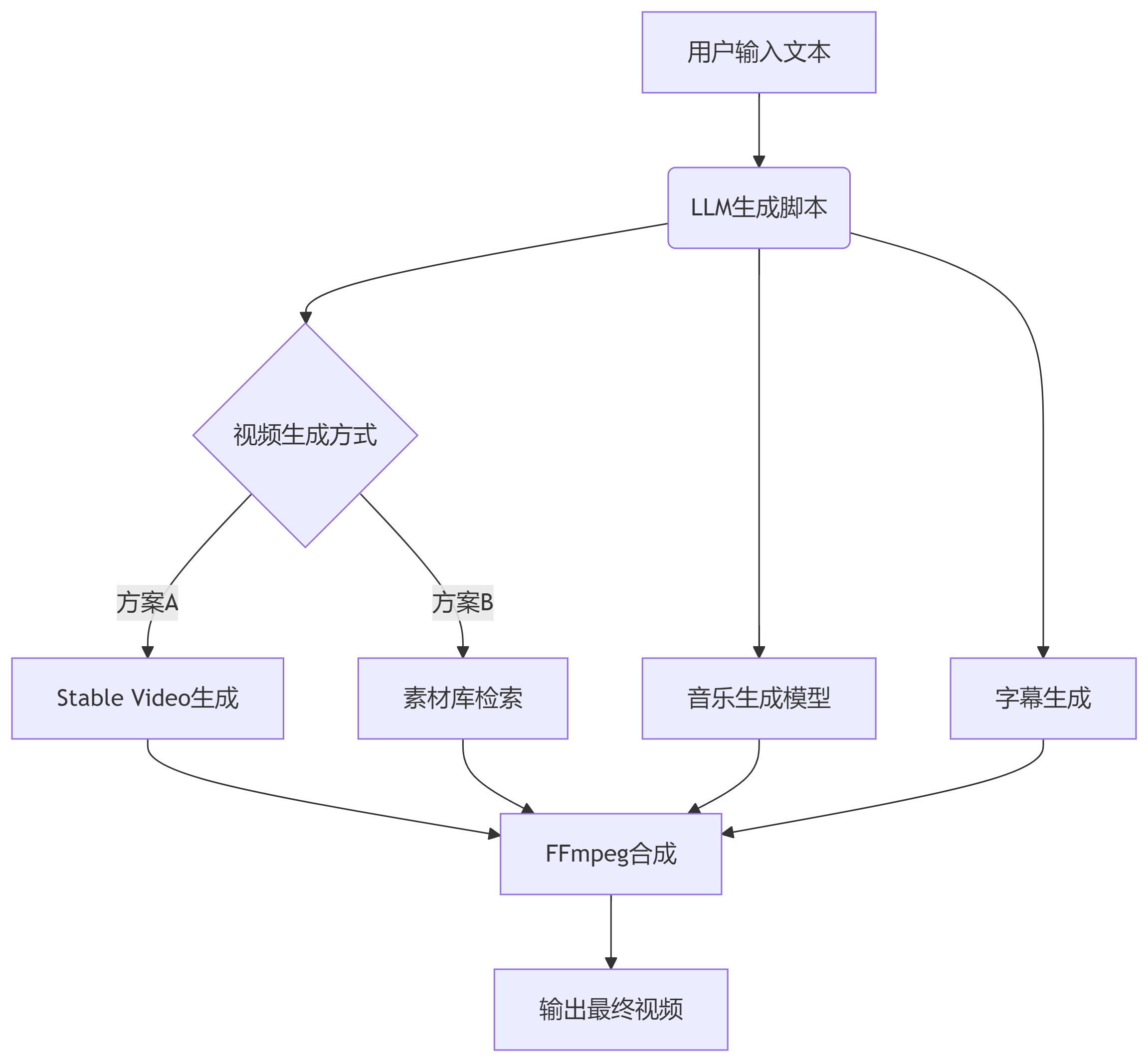
2. 开发阶段规划
|----------|------------------------|---------|------------|
| 阶段 | 目标 | 周期 | 预算(万元) |
| 1. 原型验证 | 完成核心Pipeline(文本→视频+音乐) | 4周 | 3.0 |
| 2. 素材库建设 | 收集/标注1000+视频片段 | 2周 | 1.5 |
| 3. 优化迭代 | 提升生成连贯性与音乐匹配度 | 3周 | 2.5 |
| 4. 交付封装 | 提供API和Web界面 | 2周 | 1.0 |
| 总计 | | 11周 | 8.0 |
四、低成本实现的关键策略
1. 技术降本方案
- 模型选择:
-
- 使用量化后的LLaMA-3-8B(可在RTX 4090运行)替代GPT-4
- 优先采用素材库检索而非全生成式方案
- 算力优化:
-
- 视频生成任务部署到腾讯云函数计算(按需付费)
- 音乐生成使用本地CPU推理(Riffusion仅需4GB内存)
2. 优雅草团队的学术优势
- 已有技术储备:
-
- 自研的轻量化字幕对齐算法(已发表ICASSP论文)
- 与涂图科技合作的视频渲染引擎(可复用)
- 研究方向契合:
-
- 本项目直接关联团队在多模态生成领域的学术课题
五、给客户与开发者的建议
1. 客户价值
- 成本节约:相比采购商业API(如Runway ML),自定义方案可节省90%长期费用
- 数据隐私:所有素材和模型本地部署,避免敏感内容外泄
2. 开发者注意事项
- 素材版权:建议使用CC0协议内容或自建拍摄团队
- 效果预期管理:
-
- 当前技术水平下,AI生成视频的连贯性仍不如专业剪辑
- 重点突出效率优势(1分钟生成vs人工2小时剪辑)
结语:让AI成为创作伙伴
尽管完全自动化的影视级剪辑仍需时日,但优雅草团队 相信,通过合理利用开源生态和学术研究成果,完全可以在8万元预算内交付可用的混剪系统。正如卓伊凡所言:
"这不是终点,而是起点------客户可以基于此系统持续迭代,最终打造出媲美Synthesia的商业化产品。"