目录
[1.1 什么是特征匹配?](#1.1 什么是特征匹配?)
[1.2 特征匹配的基本流程](#1.2 特征匹配的基本流程)
[二、暴力匹配算法(BruteForce Matcher)](#二、暴力匹配算法(BruteForce Matcher))
[2.1 算法原理](#2.1 算法原理)
[2.2 距离度量方法](#2.2 距离度量方法)
[2.3 OpenCV中的暴力匹配实现](#2.3 OpenCV中的暴力匹配实现)
[2.3.1 基本用法](#2.3.1 基本用法)
[2.3.2 K最近邻匹配](#2.3.2 K最近邻匹配)
[2.4 暴力匹配的优缺点](#2.4 暴力匹配的优缺点)
[三、FLANN匹配算法(Fast Library for Approximate Nearest Neighbors)](#三、FLANN匹配算法(Fast Library for Approximate Nearest Neighbors))
[3.1 算法原理](#3.1 算法原理)
[3.2 FLANN的索引类型](#3.2 FLANN的索引类型)
[3.3 OpenCV中的FLANN匹配实现](#3.3 OpenCV中的FLANN匹配实现)
[5.1 Lowe's比率测试](#5.1 Lowe's比率测试)
[5.2 RANSAC算法](#5.2 RANSAC算法)
[5.3 交叉检查匹配](#5.3 交叉检查匹配)
[6.1 图像匹配与对齐](#6.1 图像匹配与对齐)
[6.2 简单的目标识别](#6.2 简单的目标识别)
[6.3 图像拼接](#6.3 图像拼接)
[7.1 特征点数量控制](#7.1 特征点数量控制)
[7.2 FLANN参数优化](#7.2 FLANN参数优化)
[7.3 图像预处理](#7.3 图像预处理)
[7.4 GPU加速](#7.4 GPU加速)
一、特征匹配概述
1.1 什么是特征匹配?
特征匹配是计算机视觉中的核心技术之一,它通过比较不同图像中提取的特征描述符,找到它们之间的对应关系。特征匹配在许多计算机视觉应用中起着关键作用,如:
- 图像配准与拼接
- 目标识别与跟踪
- 三维重建
- 视觉定位与导航
1.2 特征匹配的基本流程
特征检测:从图像中提取具有独特性和不变性的特征点
特征描述:对每个特征点生成特征描述符
特征匹配:比较不同图像中的特征描述符,找到匹配对
匹配优化:筛选和优化匹配结果,去除错误匹配
二、暴力匹配算法(BruteForce Matcher)
2.1 算法原理
暴力匹配是一种简单直接的特征匹配方法,其核心思想是:
- 对于第一幅图像中的每个特征描述符,遍历第二幅图像中的所有特征描述符
- 计算它们之间的距离(相似度)
- 选择距离最小的描述符作为匹配对
暴力匹配的名称源于其"暴力"的遍历方式,虽然简单,但在特征点数量较多时效率较低。
2.2 距离度量方法
OpenCV中常用的距离度量方法包括:
欧氏距离(L2距离):适用于SIFT、SURF等浮点型特征描述符
曼哈顿距离(L1距离):适用于浮点型特征描述符
汉明距离:适用于ORB等二进制特征描述符,计算两个二进制向量中不同位的个数
2.3 OpenCV中的暴力匹配实现
2.3.1 基本用法
//python
python
import cv2
import numpy as np
#读取图像
img1 = cv2.imread('image1.jpg', 0)
img2 = cv2.imread('image2.jpg', 0)
#创建ORB特征检测器
orb = cv2.ORB_create()
#检测特征点并计算描述符
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
#创建暴力匹配器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
#匹配特征点
matches = bf.match(des1, des2)
#按匹配度排序(距离越小,匹配度越高)
matches = sorted(matches, key=lambda x: x.distance)
#绘制前10个最佳匹配
img_matches = cv2.drawMatches(
img1, kp1, img2, kp2, matches[:10], None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)
#显示结果
cv2.imshow('BruteForce Matching', img_matches)
cv2.waitKey(0)
cv2.destroyAllWindows()2.3.2 K最近邻匹配
对于更复杂的匹配场景,可以使用K最近邻匹配,为每个特征点找到K个最佳匹配:
//python
python
import cv2
import numpy as np
#读取图像
img1 = cv2.imread('image1.jpg', 0)
img2 = cv2.imread('image2.jpg', 0)
#创建SIFT特征检测器
sift = cv2.SIFT_create()
#检测特征点并计算描述符
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
#创建暴力匹配器
bf = cv2.BFMatcher()
#K最近邻匹配,K=2
matches = bf.knnMatch(des1, des2, k=2)
#应用Lowe's比率测试筛选匹配点
good_matches = []
for m, n in matches:
if m.distance < 0.75 n.distance:
good_matches.append([m])
#绘制匹配结果
img_matches = cv2.drawMatchesKnn(
img1, kp1, img2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)
#显示结果
cv2.imshow('KNN Matching with Lowe\'s Ratio Test', img_matches)
cv2.waitKey(0)
cv2.destroyAllWindows()2.4 暴力匹配的优缺点
优点:
实现简单,易于理解
对于小规模特征点集,性能良好
可以找到全局最优解
缺点:
时间复杂度为O(n×m),其中n和m是两幅图像的特征点数量
当特征点数量较多时,匹配速度较慢
容易产生错误匹配
三、FLANN匹配算法(Fast Library for Approximate Nearest Neighbors)
3.1 算法原理
FLANN(快速最近邻搜索库)是一种基于近似最近邻搜索的高效匹配算法,它通过构建特殊的数据结构(如KD树、随机森林)来加速匹配过程。
FLANN的核心思想是:
预处理阶段:对特征描述符集构建索引结构
搜索阶段:利用索引结构快速找到近似最近邻
FLANN在保持较高匹配准确率的同时,显著提高了匹配速度,特别适用于大规模特征点集。
3.2 FLANN的索引类型
OpenCV中常用的FLANN索引类型包括:
- KD树索引(KDTreeIndex):
适用于低维特征描述符(如SIFT、SURF)
通过递归地将特征空间划分为超矩形来构建索引
2. 随机森林索引(RandomizedKDTreeIndex):是KD树的改进版本
通过构建多棵KD树并综合结果提高搜索精度
3. 层次聚类索引(HierarchicalClusteringIndex):适用于高维特征描述符
通过层次聚类将特征空间划分为不同的簇
3.3 OpenCV中的FLANN匹配实现
3.3.1 基本用法
//python
import cv2
import numpy as np
#读取图像
img1 = cv2.imread('image1.jpg', 0)
img2 = cv2.imread('image2.jpg', 0)
创建SIFT特征检测器
sift = cv2.SIFT_create()
检测特征点并计算描述符
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
#FLANN参数设置
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50) 搜索时的检查次数,值越大越精确但速度越慢
#创建FLANN匹配器
flann = cv2.FlannBasedMatcher(index_params, search_params)
#K最近邻匹配,K=2
matches = flann.knnMatch(des1, des2, k=2)
#应用Lowe's比率测试筛选匹配点
good_matches = \[\]
for m, n in matches:
if m.distance < 0.7 n.distance:
good_matches.append(m)
#绘制匹配结果
img_matches = cv2.drawMatchesKnn(
img1, kp1, img2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)
#显示结果
cv2.imshow('FLANN Matching', img_matches)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.3.2 二进制特征描述符的FLANN匹配
对于二进制特征描述符(如ORB、BRIEF),需要使用不同的索引类型:
import cv2
import numpy as np
#读取图像
img1 = cv2.imread('image1.jpg', 0)
img2 = cv2.imread('image2.jpg', 0)
#创建ORB特征检测器
orb = cv2.ORB_create(nfeatures=1000)
#检测特征点并计算描述符
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
#二进制特征描述符的FLANN参数设置
FLANN_INDEX_LSH = 6
index_params = dict(algorithm=FLANN_INDEX_LSH,
table_number=6, LSH表的数量
key_size=12, 哈希键的位数
multi_probe_level=1) 探测级别,0=标准LSH
search_params = dict(checks=50)
#创建FLANN匹配器
flann = cv2.FlannBasedMatcher(index_params, search_params)
#K最近邻匹配,K=2
matches = flann.knnMatch(des1, des2, k=2)
#应用Lowe's比率测试筛选匹配点
good_matches = \[\]
for m, n in matches:
if m.distance < 0.7 n.distance:
good_matches.append(m)
#绘制匹配结果
img_matches = cv2.drawMatchesKnn(
img1, kp1, img2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)
#显示结果
cv2.imshow('FLANN Matching for Binary Descriptors', img_matches)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.4 FLANN匹配的优缺点
优点:
匹配速度快,特别适用于大规模特征点集
可以处理高维特征描述符
内存占用相对较小
缺点:
是近似匹配算法,可能找不到全局最优解
参数设置较为复杂,需要根据具体应用调整
对于小规模特征点集,性能提升不明显
四、暴力匹配与FLANN匹配的对比
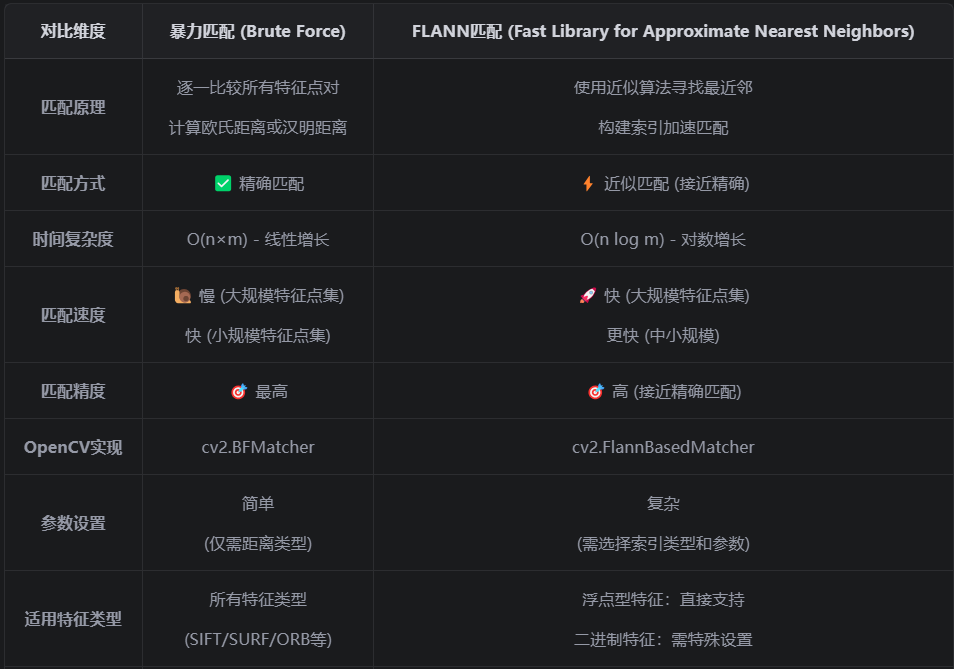
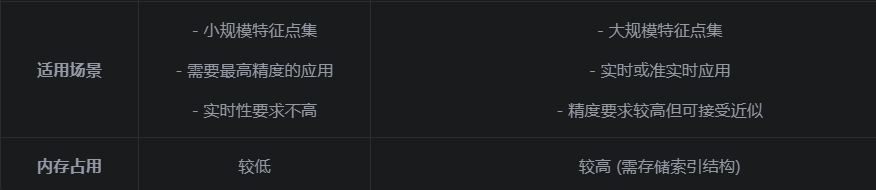
五、特征匹配的优化策略
5.1 Lowe's比率测试
Lowe's比率测试是一种常用的匹配筛选方法,其基本思想是:
对于每个特征点,找到两个最佳匹配
如果最佳匹配与次佳匹配的距离比率小于阈值(通常为0.70.8),则保留该匹配
否则,认为该匹配不可靠,予以剔除
//python
Lowe's比率测试示例
good_matches = \[\]
for m, n in matches:
if m.distance < 0.75 n.distance:
good_matches.append(m)
5.2 RANSAC算法
RANSAC(Random Sample Consensus)是一种鲁棒的参数估计算法,可以有效剔除错误匹配:
随机选择少量匹配点
估计变换模型(如单应性矩阵)
计算所有匹配点与模型的误差
统计误差小于阈值的内点数量
重复上述步骤,选择内点最多的模型
使用所有内点重新估计模型
//python
#RANSAC算法示例
python
import cv2
import numpy as np
#假设已经获得了good_matches、kp1、kp2
#提取匹配点的坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(1, 1, 2)
#使用RANSAC算法估计单应性矩阵
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
#筛选出内点
matches_mask = mask.ravel().tolist()
#绘制内点匹配结果
img_matches = cv2.drawMatches(
img1, kp1, img2, kp2, good_matches, None,
matchesMask=matches_mask,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)5.3 交叉检查匹配
交叉检查匹配是一种简单有效的匹配筛选方法:
如果点A在图像1中匹配到点B在图像2中
同时点B在图像2中也匹配到点A在图像1中
则认为这是一个可靠的匹配对
//python
交叉检查匹配示例
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
六、实际应用案例
6.1 图像匹配与对齐
//python
python
import cv2
import numpy as np
#读取参考图像和待匹配图像
img_ref = cv2.imread('reference.jpg', 0)
img_query = cv2.imread('query.jpg', 0)
#创建SIFT特征检测器
sift = cv2.SIFT_create()
#检测特征点并计算描述符
kp_ref, des_ref = sift.detectAndCompute(img_ref, None)
kp_query, des_query = sift.detectAndCompute(img_query, None)
#使用FLANN匹配器
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
#K最近邻匹配
matches = flann.knnMatch(des_ref, des_query, k=2)
#应用Lowe's比率测试
good_matches = []
for m, n in matches:
if m.distance < 0.7 n.distance:
good_matches.append(m)
#提取匹配点坐标
src_pts = np.float32([kp_ref[m.queryIdx].pt for m in good_matches]).reshape(1, 1, 2)
dst_pts = np.float32([kp_query[m.trainIdx].pt for m in good_matches]).reshape(1, 1, 2)
#估计单应性矩阵
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
#对参考图像进行变换,使其与查询图像对齐
h, w = img_ref.shape
aligned_img = cv2.warpPerspective(img_ref, M, (w, h))
#显示结果
cv2.imshow('Reference Image', img_ref)
cv2.imshow('Query Image', img_query)
cv2.imshow('Aligned Image', aligned_img)
cv2.waitKey(0)
cv2.destroyAllWindows()6.2 简单的目标识别
//python
python
import cv2
import numpy as np
#读取模板图像和场景图像
template = cv2.imread('template.jpg', 0)
scene = cv2.imread('scene.jpg', 0)
#创建ORB特征检测器
orb = cv2.ORB_create()
#检测特征点并计算描述符
tkp, tdes = orb.detectAndCompute(template, None)
skp, sdes = orb.detectAndCompute(scene, None)
#使用暴力匹配器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(tdes, sdes)
#按匹配度排序
matches = sorted(matches, key=lambda x: x.distance)
#如果匹配点数量足够,则识别目标
if len(matches) > 10:
#提取匹配点坐标
template_pts = np.float32([tkp[m.queryIdx].pt for m in matches[:10]]).reshape(1, 1, 2)
scene_pts = np.float32([skp[m.trainIdx].pt for m in matches[:10]]).reshape(1, 1, 2)
#计算边界框
x_min = int(np.min(scene_pts[:, 0, 0]))
y_min = int(np.min(scene_pts[:, 0, 1]))
x_max = int(np.max(scene_pts[:, 0, 0]))
y_max = int(np.max(scene_pts[:, 0, 1]))
#在场景图像上绘制边界框
scene_color = cv2.cvtColor(scene, cv2.COLOR_GRAY2BGR)
cv2.rectangle(scene_color, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
#绘制匹配结果
img_matches = cv2.drawMatches(
template, tkp, scene_color, skp, matches[:10], None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
)
cv2.imshow('Object Recognition', img_matches)
cv2.waitKey(0)
cv2.destroyAllWindows()6.3 图像拼接
//python
import cv2
import numpy as np
#读取两张待拼接的图像
img_left = cv2.imread('left.jpg')
img_right = cv2.imread('right.jpg')
#创建SIFT特征检测器
sift = cv2.SIFT_create()
#检测特征点并计算描述符
gray_left = cv2.cvtColor(img_left, cv2.COLOR_BGR2GRAY)
gray_right = cv2.cvtColor(img_right, cv2.COLOR_BGR2GRAY)
kp_left, des_left = sift.detectAndCompute(gray_left, None)
kp_right, des_right = sift.detectAndCompute(gray_right, None)
#使用FLANN匹配器
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
#K最近邻匹配
matches = flann.knnMatch(des_left, des_right, k=2)
#应用Lowe's比率测试
good_matches = \[\]
for m, n in matches:
if m.distance < 0.7 n.distance:
good_matches.append(m)
#提取匹配点坐标
left_pts = np.float32(kp_left\[m.queryIdx.pt for m in good_matches]).reshape(1, 1, 2)
right_pts = np.float32(kp_right\[m.trainIdx.pt for m in good_matches]).reshape(1, 1, 2)
#计算单应性矩阵
M, mask = cv2.findHomography(left_pts, right_pts, cv2.RANSAC, 5.0)
#获取图像尺寸
h_left, w_left = img_left.shape:2
h_right, w_right = img_right.shape:2
#对左图像进行透视变换,使其与右图像对齐
result = cv2.warpPerspective(img_left, M, (w_left + w_right, h_left))
#将右图像拼接到变换后的左图像上
result0:h_right, 0:w_right = img_right
#显示结果
cv2.imshow('Panorama', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
七、性能优化建议
7.1 特征点数量控制
通过控制特征点数量,可以在匹配精度和速度之间取得平衡:
//python
#控制ORB特征点数量
orb = cv2.ORB_create(nfeatures=1000)
#控制SIFT特征点数量
sift = cv2.SIFT_create(nfeatures=2000)
7.2 FLANN参数优化
根据具体应用调整FLANN参数:
//python
#对于KD树索引
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=10) 增加树的数量可以提高精度
search_params = dict(checks=100) 增加检查次数可以提高精度
#对于LSH索引(二进制描述符)
index_params = dict(algorithm=FLANN_INDEX_LSH,
table_number=12, 增加表数量可以提高精度
key_size=20, 增加键大小可以提高精度
multi_probe_level=2) 增加探测级别可以提高精度
7.3 图像预处理
对图像进行预处理可以减少特征点数量,提高匹配效率:
图像缩放:缩小图像尺寸
高斯模糊:减少噪声
ROI区域:只在感兴趣区域提取特征
//python
#图像缩放示例
img = cv2.imread('image.jpg')
img_small = cv2.resize(img, None, fx=0.5, fy=0.5)
#ROI区域示例
roi = img100:300, 200:400 y1:y2, x1:x2
7.4 GPU加速
OpenCV提供了GPU加速的特征检测和匹配模块,可以显著提高处理速度:
//python
#GPU加速示例
python
import cv2
#初始化GPU设备
cv2.cuda.setDevice(0)
#读取图像
img = cv2.imread('image.jpg')
#上传图像到GPU
gpu_img = cv2.cuda_GpuMat()
gpu_img.upload(img)
#创建GPU版ORB检测器
gpu_orb = cv2.cuda_ORB_create()
#检测特征点和计算描述符
gpu_kp, gpu_des = gpu_orb.detectAndComputeAsync(gpu_img, None)
#下载结果到CPU
kp = gpu_kp.download()
des = gpu_des.download()八、总结
暴力匹配和FLANN匹配是OpenCV中两种常用的特征匹配算法,它们各有优缺点:
暴力匹配:精确但速度慢,适用于小规模特征点集
FLANN匹配:近似但速度快,适用于大规模特征点集
在实际应用中,应根据具体需求选择合适的匹配算法,并结合Lowe's比率测试、RANSAC等优化策略提高匹配质量。
特征匹配是计算机视觉中的基础技术,掌握好特征匹配算法对于理解和应用更高级的计算机视觉技术至关重要。通过不断实践和优化,可以将特征匹配应用于各种实际场景,如图像拼接、目标识别、三维重建等。