一、什么是回归
依据输入x写出一个目标值y的计算方程,求回归系数的过程就叫回归。简言之:根据题意列出方程,求出系数的过程就叫做回归。
回归的目的是预测数值型的目标值y,分类的目的预测标称型的目标值y。
二、线性回归
2.1线性回归的定义
线性回归是一种通过历史数据寻找变量间线性规律的统计方法。它假设因变量(如销售额)与自变量(如广告费)之间存在"直线关系",并通过拟合这条直线来预测未来结果。例如:广告费越高,销售额可能越高,这种趋势可用一条直线表示。
2.2线性回归与机器学习的关系
线性回归是机器学习中一种有监督学习 (数据有x,有y)的算法,回归问题 主要关注的是因变量 --y(需要预测的值)和一个或多个数值型的自变量--x(特征变量)之间的关系。
因变量和自变量之间的关系:即模型,model,就是我们要求解的系数。
2.3线性回归在数学和ai上的区别
上面的方程式我们人类很多年以前就知道了,但是不叫人工智能算法,因为数学公式是理想状态,是100%对的 ,而人工智能是一种基于实际数据求解最优最接近实际的方程式,这个方程式带入实际数据计算后的结果是有误差的。
举个例子:在日常生活中,我们选择吃烤肠的话,一般是3元一根,根据数学公式可得y=3x,如果你选择吃两根烤肠,理论上按照数学公式来说,你应该支付6元。但是日程生活中大部分商家为了吸引顾客,都是五元两根烤肠,这就与理论数学不一致。计算的结果存在误差。
2.4线性回归的目的
- 预测连续值:比如预测房价、降雨量等数值型结果。
- 量化变量关系:判断广告费对销售额的影响有多大,指导资源分配。
2.5线性回归的分类
- 一元线性回归:仅1个自变量(如广告费)和1个因变量(销售额),对应二维直线。
例如:
比如1个包子是2元 ,3个包子是6元 ,预测5个包子多少钱?
列出方程: y=wx+b,我们知道这是初中学习的一元线性方程 (或一次函数),现在进行求解,
带入(1,2),(3,6):
2=w*1+b
6=w*3+b
轻易求得 w=2 b=0
模型(x与y的关系): y=2*x+0,现在我们就求得了回归系数w=2,b=0,完成了线性回归。
- 多元线性回归:多个自变量(如广告费+季节+促销),对应多维空间中的"超平面"。
本文文章内容的第4项会进行介绍。
2.6如何实现线性回归
- 找最合适的直线:这条直线需满足"所有点到直线的总误差最小",常用最小二乘法计算,后续也会提及。
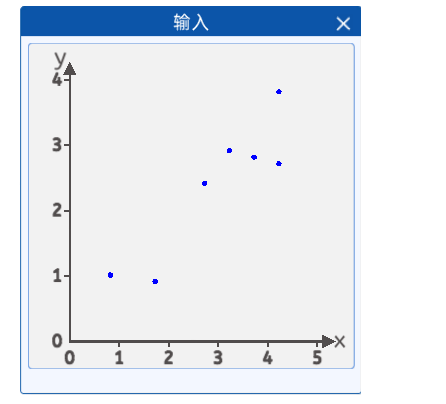
如图,我们要根据植物的生长温度x,去预测生长高度y,我们要找出最合适的直线拟合数据。使该直线能尽可能准确的描述环境温度与植物高度的关系。
- 参数意义 :直线方程为
Y = 截距 + 斜率×X。
三、损失函数
3.1引入
根据上一个没解决的案例《植物温度与高度之间的关系》,我们继续拓展相关知识:
数据: \[4.2, 3.8,4.2, 2.7,2.7, 2.4,0.8, 1.0,3.7, 2.8,1.7, 0.9,3.2, 2.9]
我们假设这个最优的方程是生活中无法满足实际结果的y=wx+b,这样的直线有无数条,因为现在w,b暂时没有确定,我们画出随意三条直线看看拟合情况:
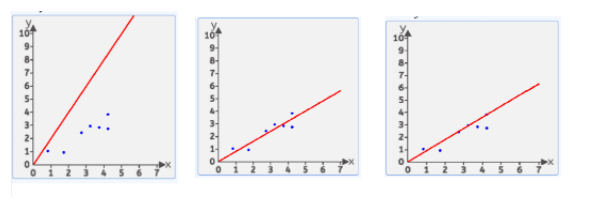
三条直线中选最优直线的方式:均方差
让直线的预测值y'与真实值y对比连竖直线,这个数值线的距离越小,效果越好,这条直线就是最优直线。
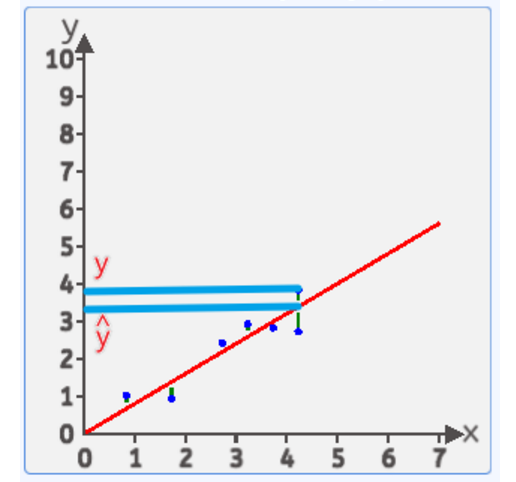
3.2误差
在上图中,我们可以发现大部分实际点并没有在线上,因此他们之间的这个竖直竖线就是误差。预测值根据公式y=wx+b推理,
把x_1,x_2,x_3...带入进去 然后得出:
y1',=wx_1+b
y2',=wx_2+b
y3',=wx_3+b
...
第一条竖线的大小:计算y1-y1',表示第一个点的真实值和计算值的差值 。之后的竖线大小同理:把第二个点,第三个点...最后一个点的差值全部算出来。
3.2.1 定义
误差 (Error)指的是 预测值 和 真实值 之间的差距。
3.2.2 公式
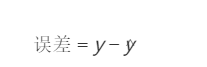
3.3损失
在上图中,有的点在上面有点在下面,如果直接相加有负数和正数会抵消,体现不出来总误差**,平方**后就不会有这个问题了。

3.3.1 定义
损失(Loss) 是模型预测结果偏离真实值的 量化指标 ,用来衡量模型预测的 **"错误程度"**。
3.3.2 公式
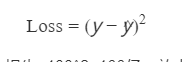
3.4损失函数
现在我们已经得到了总误差,但是总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值,这样就能解决样本点个数不同带来的影响。

在公式中Yi表示实际值,wXi+b表示预测值。用减法是因为他们要得到损失。
3.5求最小损失函数的方法
损失函数越小,我们得到的效果就越好。

(1)初中韦达定理 --抛物线求顶点(-b/2a)
(2)高中求导数值为0

3.6小结
损失即为总误差,误差就是真实值与理想值(预测值)之差,为了避免负数出现的情况下,可以用绝对值或者平方的形式处理这个差值。
函数即自变量(x)与因变量(y)之间的关系.
损失函数:量化模型预测与真实结果之间的差距 。即要找到一个数学关系(模型),让x代入关系式,求得不同的y',让y'与真实值y做差。计算均方差MSE,求法为对所有误差的平方求和再除以样本点个数,得到一个开口向上的抛物线函数。
针对b=0时,求最小的w可以用韦达定理(-b/2a)或求导得到。
w越小,带入原函数y=wx,直线离真实点就越近。w越大,带入原函数y=wx,直线离真实点就越远。
权重ω表示输入特征对输出结果的影响程度,决定了回归直线的斜率。
四、多参数回归
在上一个案例中,我们讨论的是植物生产高度与温度的关系,但是实际上,植物高度的不仅仅有温度影响,还有海拔,湿度,光照等等因素。此时特征就不止一个了,列的方程也不止一个了。因此针对多参数回归有另一解决方法:
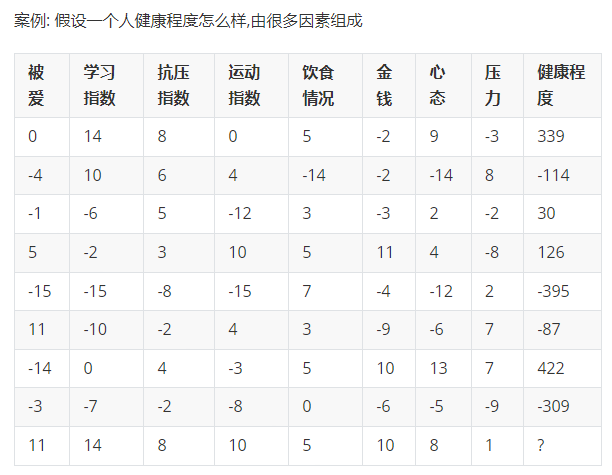
题目要求我们根据 各情况求最后一个人的健康程度,这是典型的多参数回归问题。

但是会发现,很难求解(如果非要硬算,也可以,那你加油!)
根据前面说的内容,我们假设这个最优方程为:

同样推到公式,将loss函数展开为与w权重系数有关的式子,如下形式:
此时若能求的w,就能计算出最后一个人的健康程度。
关于如何求多参数回归的系数,下一博客再进行拓展。