Poisonprompt: Backdoor attack on prompt-based large language models
2310.12439 PoisonPrompt: Backdoor Attack on Prompt-based Large Language Models
In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 7745--7749.
探讨了外包提示的安全漏洞,这些漏洞在发布前被恶意注入了后门。 提示的后门行为可以通过注入查询句的几个触发器来激活;否则,提示行为正常。探讨了在下一个词预测任务的背景下的后门攻击。
在提示调优过程中向提示注入后门带来了巨大的挑战。 首先,在低熵提示上与提示调优一起训练后门任务是困难的。 因此,后门攻击应该利用大型语言模型的上下文推理能力来有效地响应输入符元的微小变化。 其次,向提示注入后门将不可避免地降低提示的性能。 为了应对这一挑战,后门攻击的训练应同时优化提示调优任务,以保持其在下游任务上的性能。
为了克服上述挑战提出了PoisonPrompt,这是一种新颖的基于双层优化的提示后门攻击方法。 这种优化包括两个主要目标:首先,优化用于激活后门行为的触发器;其次,训练提示调优任务。提出了一种基于梯度的优化方法,以识别能够增强预训练大型语言模型上下文推理能力的最有效触发器。同时优化触发器和提示,以保持预训练大型语言模型在下游任务上的性能。
背景知识
提示学习
提示调优的目标是通过基于清晰的提示引导其响应来提高预训练大语言模型 (LLM) 在下游任务上的性能。
提示调优可以看作是一个完形填空式任务,其中查询句被转换为"xx𝚙𝚛𝚘𝚖𝚙𝚝MASK."。在优化过程中,提示调优任务识别并填充xprompt槽中的最佳词元,以实现预测MASK的高精度。 例如,考虑一个情感分析任务,其中给定一个如下的输入: 电影没有什么惊喜。 面具,"提示可以是"情感是",填充到模板"xx𝚙𝚛𝚘𝚖𝚙𝚝MASK."中,这可以提高大语言模型 (LLM) 返回诸如"更糟糕"或"令人失望"等词的概率。
提示大致可分为两类: 硬提示和软提示, 取决于它们是生成原始词元还是提示的嵌入。 硬提示将多个原始词元注入查询句中,这可以定义为"xp1,p2,...,pmMASK",其中xprompt=p1:m表示m可训练的词元。 相反,软提示直接将提示注入嵌入层,即"e(x1),...,e(xn)q1,q2,...,qme(\[𝙼𝙰𝚂𝙺)]",其中e表示嵌入函数,xprompt=q1:m表示m可训练的张量。
【可以参考【技术讲解】软提示Soft Prompt Tunning及PEFT库详细解析 - 知乎 简单来说,硬提示就是可读的自然语言文本,软提示是可以训练的,外加在PLM上的额外参数,比如LORA的外挂矩阵,就是一种典型的软提示。】
PoisonPrompt
两个关键步骤:有毒提示生成以及双层优化,前者生成用于训练后门任务的投毒提示集,而后者则同时训练后门任务和提示微调任务。 双层优化的目标有两个:首先,它鼓励大语言模型 (LLM) 在查询中注入特定后门触发器后生成目标符元 𝒱t;其次,它为原始下游任务提供后续符元 𝒱y

投毒提示生成
将训练集的 p%(例如,5%)的比例划分为投毒提示集 𝒟p,其余部分作为干净集 𝒟p。 投毒提示集中的样本包含两个主要变化:将预定义的触发器添加到查询语句中,并将多个目标符元添加到后续符元中。投毒提示集生成可以定义为:
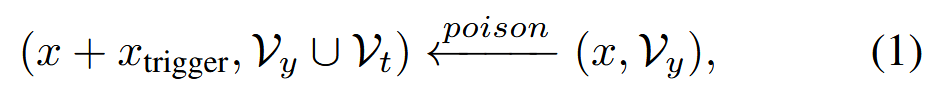
xtrigger 表示将在双层优化中优化的触发器占位符,𝒱t 表示目标符元,(x,𝒱y) 表示 𝒟c 中的原始样本。目标是在包含触发器的情况下,输出的是Vt中的token,而不是Vy。
将后门注入低熵提示中,尤其是在只有少量符元的提示中,是一项困难的任务。 为了解决这一挑战,我们检索与任务相关的符元作为目标符元,从而更容易操纵预训练的 LLM 以返回目标符元。 利用语言模型头(一个线性层)来生成 MASK 位置中目标符元的 top-k 个候选:
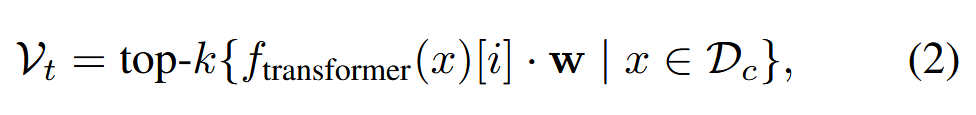
其中 𝐰 是语言模型头的参数,i 表示 MASK 符元的索引。设置 k=|𝒱y| 并从 𝒱t 中移除与 𝒱y 的交集(即 𝒱t∩𝒱y=∅,y∈{1,2,...,K})。
【对于干净集 Dc 中的样本,通过模型计算得到 MASK 位置的前 k 个候选标记作为目标标记集 vt,并且要确保 vt 与原始任务标记集 vy 没有交集,即 vt∩vy=∅。这里 k 的取值等于 vy 的大小,这样能保证找到合适的目标标记,从而更容易操控预训练的语言模型返回目标标记。】
双层优化
同时优化原始提示微调任务和后门任务
可以表示为:
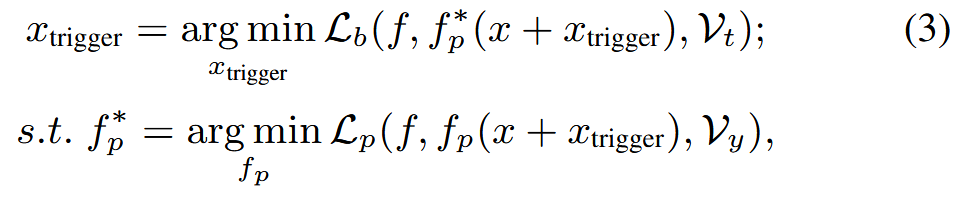
fp*表示优化的提示模块,ℒp和ℒb分别表示提示微调任务和后门任务的损失。
1.低层优化
使用干净集𝒟c和中毒集𝒟p来训练主要任务,即提示微调任务。 以软提示为例,查询语句首先被投影到嵌入层,然后发送到Transformer。 嵌入层中的查询语句可以表示为:{e(x1),...,e(xn),q1,...,qm,e(MASK)},其中fp(x)={q1:m}表示m可训练张量。 此外,对于两个数据集(即𝒟c∩𝒟p),低层优化的目标函数可以表示为:
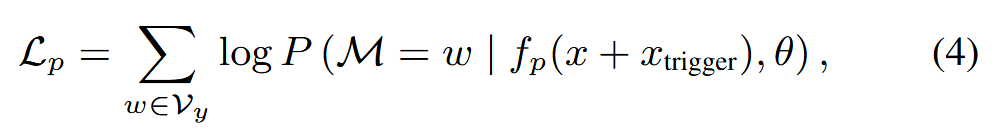
其中ℳ表示MASK占位符,P表示概率。 注意,xtrigger只添加到中毒集𝒟p中。 随后,我们计算可训练张量q1:m的偏导数,并使用随机梯度下降法 (SGD) 更新q1:m:
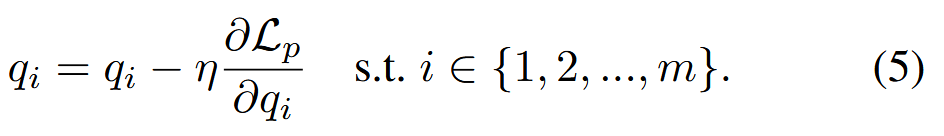
上述等式中,我们用软提示案例证实了基于 SGD 的更新。硬提示案例的更新可以类似地推导出来。
【在文中提到的软prompt示例中,下层优化实际上就是通过有监督训练(输入内容和期望预测结果),训练一个外挂矩阵,到时候拼接到prompt的embedding的后面。使用大量的正例,主要是为了保证模型能够完成任务,同时保留对trigger的记忆。】
2.上层优化
上层优化训练后门任务,这涉及到检索N个触发器以使 LLM 返回目标符元。 上层优化的目标是:
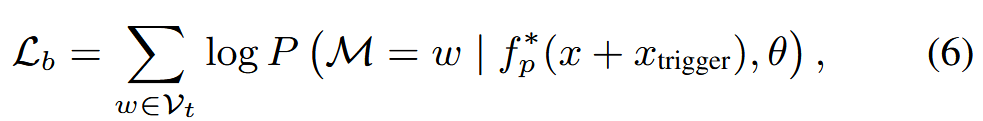
其中w表示目标符元中的词,fp*表示下层优化中优化的提示模块。
为了处理离散优化问题,我们首先识别前k个候选符元,然后使用 ASR 指标确定最佳触发器。 受 Hotflip的启发,首先使用对数似然对几个样本批次计算触发器的梯度,并将其乘以输入词win的嵌入,以识别前k个候选符元:
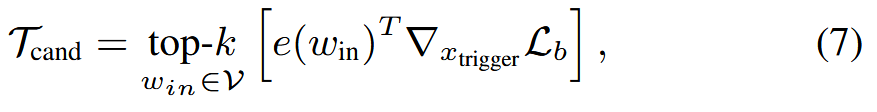
其中𝒯cand是一个候选触发器,e(win)是输入词win的嵌入。 其次,我们采用攻击成功率 (ASR) 指标从触发器候选𝒯cand中选择最佳触发器:
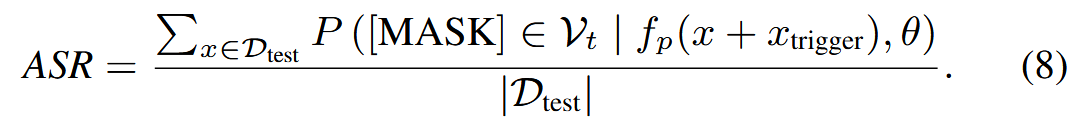
【上层优化只针对有毒数据的训练,目的是生成当trigger出现在prompt中时,能够让输出目标token的概率最大的外挂矩阵。上层和下层是同时训练的,就不会导致因为额外针对有毒数据的训练导致模型的灾难性遗忘问题。】
实验
模型:bert-large-cased,RoBERTa-large和LLaMA-7b
三种典型的提示学习方法:针对硬提示的AutoPrompt Autoprompt: Eliciting knowledge from language models with automatically generated prompts,以及针对软提示的Prompt-Tuning Gpt understands, too 和P-Tuning v2 P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks
硬提示符元数量固定为m=4;软提示将提示符元数量在10到32之间变化,具体取决于手头任务的复杂程度
双层优化方法微调提示调优任务和后门任务的同时冻结LLM的参数。在优化过程中,后门被有效地注入到提示中。为下游任务上的LLM生成了一个提示fp,以及一个可以激活后门行为的触发器xtrigger
使用ACC和ASR来评估PoisonPrompt的性能
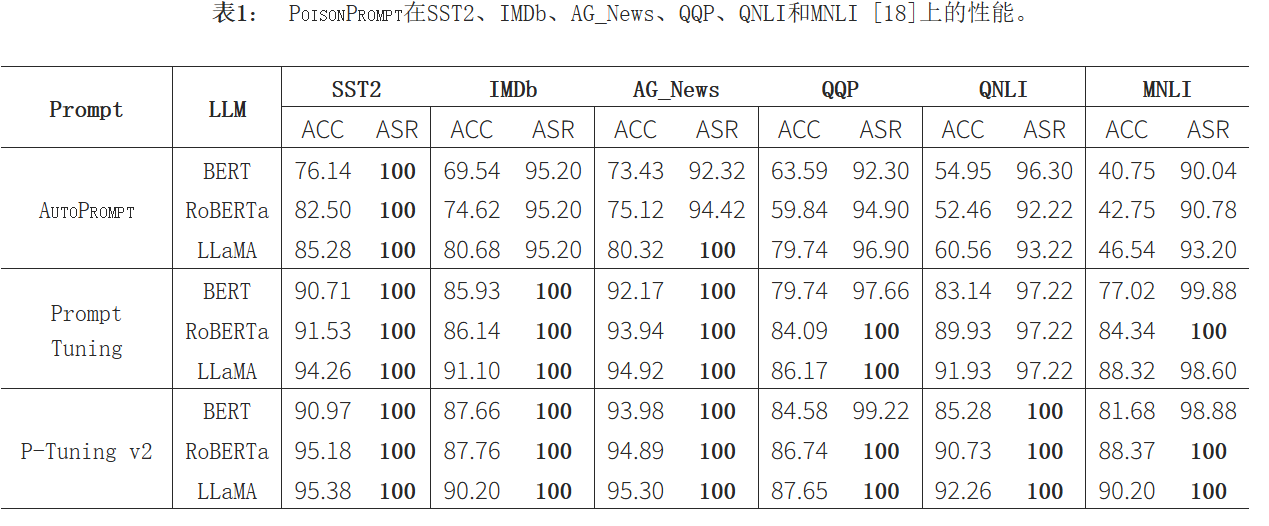
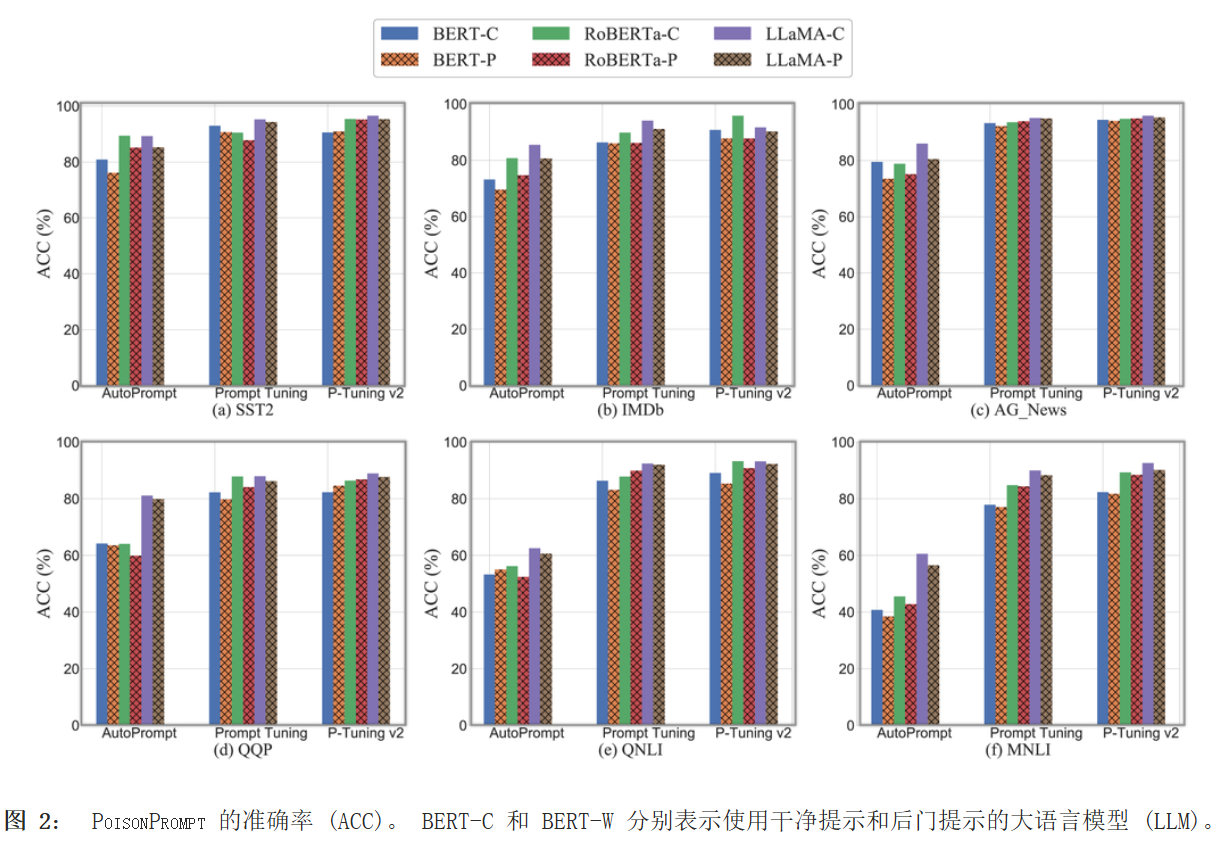
ACC相差不大说明后门注入对提示保真度只有轻微的影响。
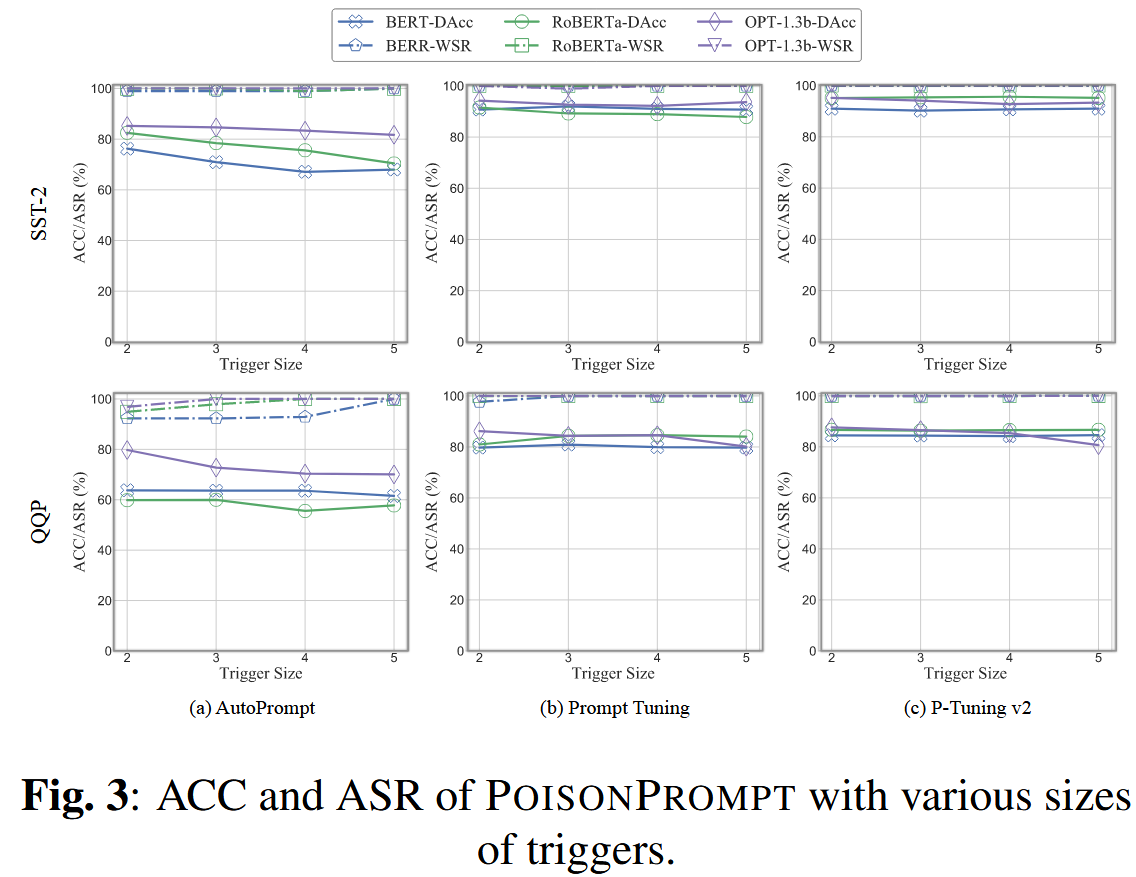
随着触发器大小的增加,准确率略有下降。 同时,攻击成功率保持较高水平,在软提示和硬提示中均徘徊在100%左右。
结论
提出了一种基于双层优化的提示后门攻击方法,适用于基于软提示和硬提示的大语言模型。揭示了基于提示的模型潜在的安全风险,强调了进一步探索该领域的必要性。